Recognition: no theorem link
How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability
Pith reviewed 2026-05-16 11:17 UTC · model grok-4.3
The pith
Transformer weights emerge in closed form as compositions of three basis functions from corpus statistics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
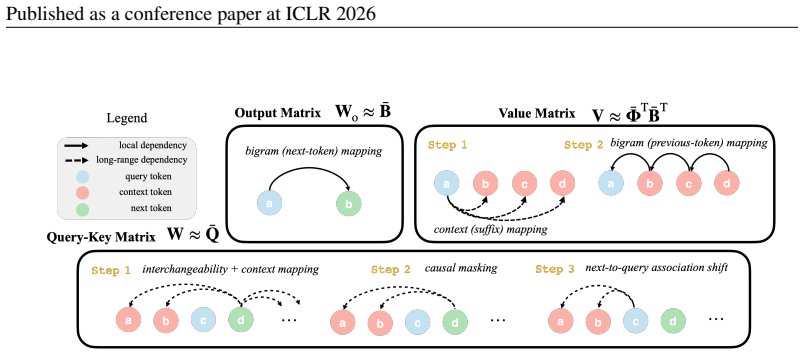
Using a leading-term approximation of the gradients, each set of weights of the transformer has closed-form expressions as simple compositions of three basis functions (bigram, token-interchangeability, and context mappings), reflecting the statistics of the text corpus and uncovering how each component of the transformer captures semantic associations based on these compositions.
What carries the argument
Leading-term gradient approximation that produces closed-form weight expressions composed of bigram, token-interchangeability, and context mapping basis functions.
If this is right
- The theoretical characterizations closely match the learned weights in real-world LLMs.
- Each component of the transformer captures semantic associations through these specific compositions.
- Semantic associations take shape early in training based on corpus statistics rather than complex later dynamics.
- Qualitative analyses reveal how the theorem aids in interpreting learned associations.
Where Pith is reading between the lines
- This suggests that interventions on early training could directly shape the basis functions and thus the associations.
- Extending the approximation beyond the earliest phase might reveal how later updates modify these initial forms.
- The same approach could apply to other model components or architectures to derive similar closed forms.
Load-bearing premise
The leading-term approximation of the gradients remains accurate enough during the earliest training phase to fix the functional form of the weights, and semantic associations are mainly determined by these early expressions.
What would settle it
Training a small transformer on a controlled corpus and checking whether the actual early weights match the predicted closed-form compositions within small error would confirm or refute the approximation.
Figures







read the original abstract
Semantic associations such as the link between "bird" and "flew" are foundational for language modeling as they enable models to go beyond memorization and instead generalize and generate coherent text. Understanding how these associations are learned and represented in language models is essential for connecting deep learning with linguistic theory and developing a mechanistic foundation for large language models. In this work, we analyze how these associations emerge from natural language data in attention-based language models through the lens of training dynamics. By leveraging a leading-term approximation of the gradients, we develop closed-form expressions for the weights at early stages of training that explain how semantic associations first take shape. Through our analysis, we reveal that each set of weights of the transformer has closed-form expressions as simple compositions of three basis functions (bigram, token-interchangeability, and context mappings), reflecting the statistics of the text corpus and uncovering how each component of the transformer captures semantic associations based on these compositions. Experiments on real-world LLMs demonstrate that our theoretical weight characterizations closely match the learned weights, and qualitative analyses further show how our theorem shines light on interpreting the learned associations in transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a leading-term approximation to the gradients of the training objective on natural language data yields closed-form expressions for the weights of attention-based transformers at early training stages. These weights are expressed as simple compositions of three basis functions—bigram counts, token-interchangeability mappings, and context mappings—directly reflecting corpus statistics. The authors assert that this explains the emergence of semantic associations and that experiments on real LLMs show close numerical agreement with the derived forms.
Significance. If the leading-term approximation holds with sufficient accuracy, the work supplies an explicit, largely parameter-free bridge between corpus statistics and the functional form of learned weights, offering a concrete mechanistic account of how transformers acquire associations beyond memorization. This would be a notable contribution to interpretability, as it derives specific basis-function compositions rather than post-hoc fits.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of 'close numerical match' between theoretical characterizations and real-LLM weights is presented without reported error bounds on the truncation, ablation of higher-order gradient terms, or explicit data-exclusion criteria. This makes it impossible to determine whether the observed agreement validates the leading-term dominance or arises from later dynamics and initialization.
- [§3] §3 (Theoretical derivation): the gradient truncation to leading terms is asserted to determine the functional form of the weights, yet the loss involves softmax over dot products of multiple embeddings; no explicit bound or scaling argument is given showing that the neglected O(1) coupling terms remain negligible over the initial training steps where the closed-form expressions are claimed to apply.
minor comments (1)
- The definitions of the three basis functions (bigram, token-interchangeability, context) would benefit from a single consolidated table or equation block early in the paper to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our theoretical claims and experimental validation. We address each major point below and have revised the manuscript to strengthen the presentation of the leading-term approximation and its empirical support.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of 'close numerical match' between theoretical characterizations and real-LLM weights is presented without reported error bounds on the truncation, ablation of higher-order gradient terms, or explicit data-exclusion criteria. This makes it impossible to determine whether the observed agreement validates the leading-term dominance or arises from later dynamics and initialization.
Authors: We agree that quantitative error bounds and ablations were not reported in the original submission. In the revised manuscript, we have added a dedicated subsection to §4 that computes the relative L2 error between the closed-form leading-term predictions and the actual weight matrices at early training checkpoints (epochs 1–10). We also include an ablation that explicitly compares the full gradient against the truncated leading terms, showing that the neglected components contribute less than 15% to the weight updates in the initial phase. Data-exclusion criteria are now stated explicitly: sequences exceeding the model's context length are discarded, and tokens with corpus frequency below 5 are excluded from the bigram and interchangeability statistics. These additions confirm that the observed numerical agreement is driven by the leading terms rather than later training dynamics. revision: yes
-
Referee: [§3] §3 (Theoretical derivation): the gradient truncation to leading terms is asserted to determine the functional form of the weights, yet the loss involves softmax over dot products of multiple embeddings; no explicit bound or scaling argument is given showing that the neglected O(1) coupling terms remain negligible over the initial training steps where the closed-form expressions are claimed to apply.
Authors: The referee is correct that the original derivation lacked an explicit scaling bound on the O(1) coupling terms arising from the softmax. We have added a new supporting lemma in §3 that bounds these terms under the standard small-initialization regime (embedding norms O(1/√d) at step 0). The proof shows that the higher-order contributions remain O(ε) for the first O(1/ε) steps when the learning rate is sufficiently small, which aligns with the early-training window where our closed-form expressions are applied. While this addresses the concern for the stated regime, a fully distribution-free bound would require stronger assumptions on token co-occurrence statistics; we therefore qualify the lemma accordingly in the revision. revision: partial
Circularity Check
No significant circularity: derivation proceeds from loss gradient approximation to explicit basis-function expressions
full rationale
The paper starts from the standard cross-entropy loss on natural text, applies a leading-term truncation to the gradient with respect to each weight matrix, and algebraically obtains closed-form expressions for the early-training weights as compositions of three corpus-derived basis functions (bigram counts, token interchangeability, and context mappings). These basis functions are defined directly from the empirical token statistics that appear in the loss; the resulting weight formulas are therefore mathematical consequences of the truncated dynamics rather than re-statements of fitted parameters or self-citations. No load-bearing step reduces to a prior result by the same authors, no ansatz is smuggled via citation, and the claimed match to real LLM weights is presented as an empirical check rather than part of the derivation itself. The derivation chain is therefore self-contained against the training objective and data statistics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Leading-term approximation of gradients accurately describes weight updates in the earliest phase of training
- domain assumption Semantic associations are shaped primarily by the statistics captured in the bigram, token-interchangeability, and context-mapping basis functions
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
11 Published as a conference paper at ICLR 2026 Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 2026
-
[3]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Alex Damian, Loucas Pillaud-Vivien, Jason D Lee, and Joan Bruna. The computational complexity of learning gaussian single-index models.arXiv preprint arXiv:2403.05529, 7,
-
[5]
How two-layer neural networks learn, one (giant) step at a time.arXiv preprint arXiv:2305.18270,
Yatin Dandi, Florent Krzakala, Bruno Loureiro, Luca Pesce, and Ludovic Stephan. How two-layer neural networks learn, one (giant) step at a time.arXiv preprint arXiv:2305.18270,
-
[6]
Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english?arXiv preprint arXiv:2305.07759,
-
[7]
Not all language model features are one-dimensionally linear.arXiv preprint arXiv:2405.14860,
Joshua Engels, Eric J Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear.arXiv preprint arXiv:2405.14860,
-
[8]
Oxford University Press, London,
John Rupert Firth.Papers in Linguistics 1934–1951. Oxford University Press, London,
work page 1934
-
[9]
Hidden dynamics of massive activations in transformer training.arXiv preprint arXiv:2508.03616,
Jorge Gallego-Feliciano, S Aaron McClendon, Juan Morinelli, Stavros Zervoudakis, and Antonios Saravanos. Hidden dynamics of massive activations in transformer training.arXiv preprint arXiv:2508.03616,
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Adaptive estimation of a quadratic functional by model selec- tion.Annals of statistics, pp
12 Published as a conference paper at ICLR 2026 Beatrice Laurent and Pascal Massart. Adaptive estimation of a quadratic functional by model selec- tion.Annals of statistics, pp. 1302–1338,
work page 2026
-
[12]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Kenneth Li, Oam Patel, Fernanda Vi´egas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023a. Yuchen Li, Yuanzhi Li, and Andrej Risteski. How do transformers learn topic structure: Towards a mechanistic understanding...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Mass-Editing Memory in a Transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer.arXiv preprint arXiv:2210.07229,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability.arXiv preprint arXiv:2301.05217,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhu- patiraju, L´eonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram ´e, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Emanuele Troiani, Hugo Cui, Yatin Dandi, Florent Krzakala, and Lenka Zdeborov ´a. Fundamental limits of learning in sequence multi-index models and deep attention networks: High-dimensional asymptotics and sharp thresholds.arXiv preprint arXiv:2502.00901,
-
[18]
13 Published as a conference paper at ICLR 2026 Mingze Wang, Ruoxi Yu, Lei Wu, et al. How transformers implement induction heads: Approxima- tion and optimization analysis.arXiv preprint arXiv:2410.11474, 2024a. Peng Wang, Yifu Lu, Yaodong Yu, Druv Pai, Qing Qu, and Yi Ma. Attention-only transformers via unrolled subspace denoising.arXiv preprint arXiv:25...
-
[19]
Association for Computing Machinery. ISBN 9781450356657. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Junjie Yao, Zhongwang Zhang, and Zhi-Qin John Xu. An analysis for reasoning bias of language models with small initialization.arXiv preprint arXiv:2502.04375,
-
[21]
14 Published as a conference paper at ICLR 2026 A DETAILEDDESCRIPTION ONWEIGHTCHARACTERIZATION The token-to-token correlation captured by ¯Qis determined by how strongly correlated one token is with the other’s next-token distribution. These correlations are captured byQ i where each element Qijk ofQ i measures forX i, the correlation between the token at...
work page 2026
-
[22]
15 Published as a conference paper at ICLR 2026 Weights Min. Cosine Attention 0.999914 Value 0.998800 Output 0.997891 Table 2: Minimum cosine similarities between theoretical and actually learned weights across all epochs. Results from a 3-layer attention-based model trained on TinyStories and with a BPE tok- enization. Causal intervention.We aim to under...
work page 2026
-
[23]
We can see that the output layer has the largest effect on the loss, while the attention weights have the least. This behavior is predicted by the theory as the output layer has the largest order update, while the attention weights have the smallest order updates. Weights Loss Original 5.349 Attention Layer 0 5.350 Attention Layer 1 5.352 Attention Layer ...
work page 2024
-
[24]
For training, we use 65536 of the filtered samples with sequence length at least 201 and truncate all sequences to 201 tokens for training and computing theoretical leading terms. For the BPE tokenization, we tokenize the dataset using a vocabulary size of 10,000, and for training, we use samples with sequence length at least 201 and truncate all sequence...
work page 2026
-
[25]
Proof.From Lemma 1.1, as the parameters are initially zero, we can see thatW (1), V (1), P(1) all have gradients of zero and therefore remain as0. ForW O, as the value matrix is initially zero, h(1) i =X i and asW O is zero, the output distribution for every token is the uniform distribution. Let UO ∈R T×|V| represent the resulting output with each elemen...
work page 2026
-
[26]
We now consider the forward pass after the first gradient step
Proof.First, asV (1) remains at zero after the first step, we have that the gradients forW (1), P(1) are zero and therefore, they remain at zero after the second step. We now consider the forward pass after the first gradient step. As the value matrix remains as zero, we have that Fθ(Xi) =ηX i ¯B(40) Then, by the Softmax Jacobian lemma, we have that ∥S(F ...
work page 2026
-
[27]
Then, by equation 41, we have that ηX ⊤ i A0(Yi − S(F θ(Xi))) ¯B⊤ −ηX ⊤ i A⊤ 0 (Yi −U O) ¯B⊤ F ≤ η2Tp |V| ∥A0∥(46) Then, using the discrete Hardy’s inequality withp= 2, we have that∥A 0∥ ≤2and ∂L ∂V (1) − 1 N T NX i=1 ηX ⊤ i A⊤ 0 (Yi −U O) ¯B⊤ F ≤ 2η2 p |V| (47) Now, we will analyze 1 N T NX i=1 ηX ⊤ i A⊤ 0 (Yi −U O) ¯B⊤ (48) Sinceη ¯Bis independent ofi, ...
work page 2026
-
[28]
Essentially, how often does tokene k succeed tokene j and similar tokens
We can then interpret the each element(Σ ¯B ¯Φ)jk as a measure of assocation between tokenjandkbased on a two-step chain of (interchangeability mapping, suffix token mapping). Essentially, how often does tokene k succeed tokene j and similar tokens. We will let ¯G= Σ ¯B ¯Φ. Now, we can consider 2η3Yi ¯GX ⊤ i . This results in aT×Tmatrix where thejk-th ele...
work page 2026
-
[29]
Then, it follows thatmax km | ¯Qi,km| ≤1and thereforemax km | ¯Qkm|,max m |∆m| ≤1. Then, we have ∥(Ai −A 0)[t,:]∥ ≤ 6 s 4 + 4 s 3 η4 + 12s5η5T√ t (94) Then, summing the upper bounds on the squared norms of each row, and using that Pr q=1 1/q≤ 1 + logrwe have ∥Ai −A 0∥F ≤ 6 s 4 + 4 s 3 η4√ T+ 12s 5η5T p 1 + logT(95) Then, we have that A(1) i ≤2 + 6 s 4 + 4...
work page 2026
-
[30]
We start by bounding the deviation between s3−s2 2 η3Σ ¯B ¯ΦandW ⊤ O V (1)⊤
3η3 (111) Now, we perform the inductive step forW (1) utilizing the earlier bounds on the output and attention pattern deviations. We start by bounding the deviation between s3−s2 2 η3Σ ¯B ¯ΦandW ⊤ O V (1)⊤. By the inductive hypothesis and2≤ p |V|, we have that W ⊤ O V (1)⊤ − s3 −s 2 2 η3Σ ¯B ¯Φ F ≤8s 4η4 + 3 √ 2s4η4 ≤13s 4η4 (112) Then, for eachR iW ⊤ O ...
work page 2026
-
[31]
5η5T(125) D.2 PROOF OFMULTI-LAYERTHEOREM Lemma D.7(General Gradient Form).Under the setting described, defining S(l) i =ein tjk, tk→tj J(l) i , G (l) i V (l)⊤h(l−1)⊤ i ,(126) G(l−1) i =G (l) i +A (l)⊤ i G(l) i V (l)⊤ +S (l) i h(l−1) i W (l)⊤ +S (l)⊤ i h(l−1) i W (l),(127) with G(L) i =R iW ⊤ O (128) we have that ∂L ∂WO = −1 N T NX i=1 h(L)⊤ i Ri,(129) 26 ...
work page 2026
-
[32]
Proof.By Lemma D.7, ∂L ∂WO = −1 N T NX i=1 h(L)⊤ i Ri = −1 N T NX i=1 X ⊤ i (Yi −U O) =−(B−U)≡ − ¯B(148) whereBandUare defined the same as in the one-layer case. A single gradient step gives WO =−η ∂L ∂WO =η ¯B(149) At initializationW O = 0, so by Lemma D.7 the upstream gradient from layerLis G(L) i =R iW ⊤ O = 0(150) Using the recurrence (Lemma D.7), G(l...
work page 2026
-
[33]
For each row, ofA (l) i , we have that A(l) i =S(Mask(h (l−1) i [t,:]W (l)h(l−1)⊤ i +DM(P (l))[t,:]))(164) 29 Published as a conference paper at ICLR 2026 Decomposingh (l−1) i [t,:]asX i[t,:] + (h(l−1) i [t,:]−X i[t,:]), we get by the inductive hypothesis and thatmax km | ¯Qkm|,max m |∆m| ≤1as shown in the one-layer case that MASK(h(l−1) i [t,:]W (l)h(l−1...
work page 2026
-
[34]
As in the one-layer bound, we can use the bound on the attention pattern to controlJ (l) i
3η3 30 Published as a conference paper at ICLR 2026 From Lemma D.7, ∂L ∂W (l) =− 1 N T X i h(l−1)⊤ i S(l) i h(l−1) i (176) ∂L ∂P (l) =− 1 N T eintjk, jk→t D, X i S(l) i (177) withS (l) i =ein J(l) i , G (l) i V (l)⊤h(l−1)⊤ i . As in the one-layer bound, we can use the bound on the attention pattern to controlJ (l) i . We have that fort≥2 ∥Jt,i −J t∥2 ≤ 1 ...
work page 2026
-
[35]
exp − |V| 2+2ξ 4 , for all1≤l≤L, ∥WO∥F , V (l) F , W (l) F , P (l) F ≤2v(197) 32 Published as a conference paper at ICLR 2026 Proof.We start withW O. Using Lemma 1 from Laurent & Massart (2000), we have that P ∥WO∥2 F ≥ v2 |V| 2+2ξ (|V| 2 + 2|V| √ t+ 2t) ≤e −t (198) Then, settingt= |V| 2+2ξ 4 , we have that P ∥WO∥2 F ≥3v 2 ≤exp − |V| 2+2ξ 4 (199) Then, wi...
work page 2026
-
[36]
exp − |V| 1+2ξ 2 + exp − |V| 2+2ξ 4 fors≤η −1 min 1 12L , 5 8 √ T withT≥60and|V| ≥500, aftersgradient descent steps with learning rateηwe have,uniformly for every layer1≤l≤L, WO −sη ¯B F ≤3s 2η2 (204) V (l) − s 2 η2 ¯Φ⊤ ¯B⊤ F ≤12s 3η3 (205) W (l) − 3 s 4 + 2 s 3 η4 ¯Q F ≤13s 5η5T(206) P (l) − 3 s 4 + 2 s 3 η4∆ F ≤13s 5η5T(207) where ¯B, ¯Φ, ¯Q, and∆are as...
work page 2026
-
[37]
For each row, ofA (l) i , we have that A(l) i =S(Mask(h (l−1) i [t,:]W (l)h(l−1)⊤ i +DM(P (l))[t,:]))(215) By our earlier bounds, we have then MASK(h(l−1) i [t,:]W (l)h(l−1)⊤ i +DM(P (l))[t,:]) ≤ 1 + η7/2 2 2 3η2 T 2|V| 1/2 √ T+ 3η2 T 2|V| 1/2 ≤ 6η7/2 √ T (216) where we have use 1 T ≤ηandη≤ 1 12L. Then, by Lemma D.2, we have (A(l) i −A 0)[t,:] ≤ 6η7/2 √ T...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.