Recognition: 2 theorem links
· Lean TheoremETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
Pith reviewed 2026-05-16 09:35 UTC · model grok-4.3
The pith
Energy-guided test-time scaling samples directly from the optimal RL policy without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
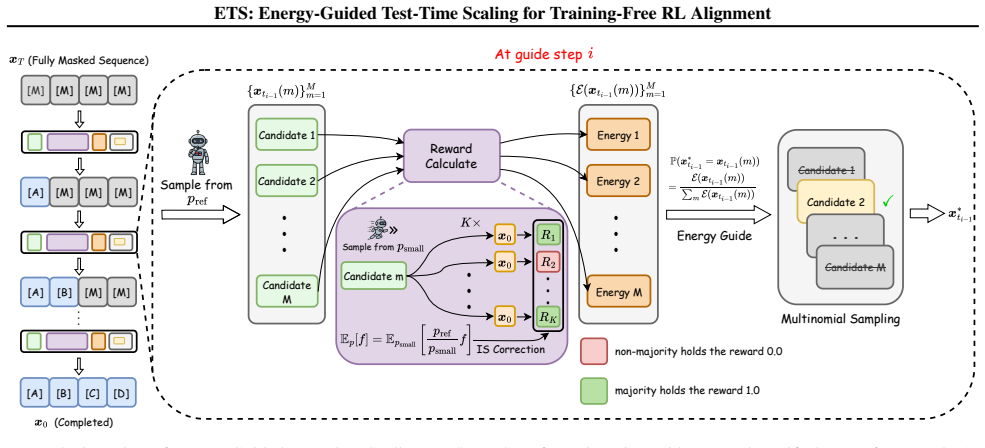
ETS estimates the key energy term via online Monte Carlo with a provable convergence rate, allowing direct sampling from the optimal RL policy that consists of a reference policy model plus the energy term, and achieves this efficiently through modern acceleration frameworks and tailored importance sampling estimators that reduce latency while provably preserving sampling quality.
What carries the argument
Energy-Guided Test-Time Scaling (ETS), the online Monte Carlo procedure that estimates the energy term driving the transition from reference policy to optimal RL policy in masked language modeling.
Load-bearing premise
The energy term derived from the reference policy and optimal RL policy can be estimated accurately enough via online Monte Carlo to approximate the target distribution without introducing substantial bias.
What would settle it
Running ETS on a new set of reasoning or coding tasks and observing no measurable improvement in generation quality over the unadjusted reference policy, or observing that the Monte Carlo estimates fail to converge to the expected energy values.
Figures







read the original abstract
Reinforcement Learning (RL) post-training alignment for language models is effective, but also costly and unstable in practice, owing to its complicated training process. To address this, we propose a training-free inference method to sample directly from the optimal RL policy. The transition probability applied to Masked Language Modeling (MLM) consists of a reference policy model and an energy term. Based on this, our algorithm, Energy-Guided Test-Time Scaling (ETS), estimates the key energy term via online Monte Carlo, with a provable convergence rate. Moreover, to ensure practical efficiency, ETS leverages modern acceleration frameworks alongside tailored importance sampling estimators, substantially reducing inference latency while provably preserving sampling quality. Experiments on MLM (including autoregressive models and diffusion language models) across reasoning, coding, and science benchmarks show that our ETS consistently improves generation quality, validating its effectiveness and design. The code is available at https://github.com/sheriyuo/ETS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Energy-Guided Test-Time Scaling (ETS), a training-free inference-time method to sample directly from the optimal KL-regularized RL policy for language models. The transition is expressed as the reference policy multiplied by an energy term; ETS estimates this energy online via Monte Carlo sampling (with a claimed provable convergence rate), augments it with tailored importance sampling and modern acceleration frameworks to cut latency, and reports consistent quality gains on reasoning, coding, and science benchmarks for masked, autoregressive, and diffusion LMs.
Significance. If the online MC estimator converges with controllable bias in the exponential state spaces of LMs and the importance-sampling corrections preserve the target distribution, the result would offer a practical route to RL alignment without any post-training, lowering cost and instability. The public code release supports reproducibility and allows direct verification of the latency-quality trade-off.
major comments (2)
- [Abstract and §3] Abstract and §3 (energy estimation): the claimed 'provable convergence rate' for the online Monte Carlo estimator of the energy term is load-bearing for the central claim of sampling from the optimal policy without training; in autoregressive or diffusion LM spaces the state space is exponential, so the variance of the importance weights and the number of samples needed for stabilization must be bounded explicitly—otherwise finite-sample bias can violate the distribution-matching guarantee.
- [§4] §4 (energy scaling hyperparameter): the method lists an energy scaling hyperparameter as free; any non-trivial dependence on this constant contradicts the 'training-free' and 'parameter-free' framing and requires an ablation showing that performance is insensitive within a narrow range or that the hyperparameter can be set by a closed-form rule derived from the reference policy.
minor comments (2)
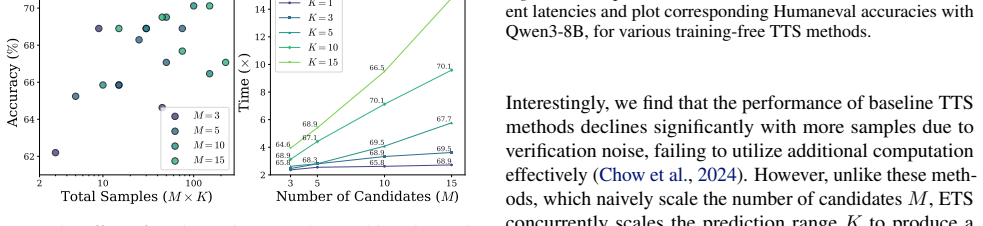
- [Experiments] Experiments section: report the exact number of Monte Carlo samples used per token and the wall-clock latency numbers alongside the quality metrics so that the claimed latency reduction can be compared directly to standard temperature sampling or other test-time baselines.
- [Notation] Notation: ensure the energy function E is defined identically in the transition probability equation and in the Monte Carlo estimator; any normalization constants introduced for numerical stability should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate the suggested clarifications and additional analysis.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (energy estimation): the claimed 'provable convergence rate' for the online Monte Carlo estimator of the energy term is load-bearing for the central claim of sampling from the optimal policy without training; in autoregressive or diffusion LM spaces the state space is exponential, so the variance of the importance weights and the number of samples needed for stabilization must be bounded explicitly—otherwise finite-sample bias can violate the distribution-matching guarantee.
Authors: We appreciate the referee's emphasis on making the finite-sample guarantees explicit. The convergence analysis in §3 establishes an O(1/√N) rate for the online Monte Carlo estimator of the energy term under the assumption of bounded second moments on the importance weights. To address the exponential state space directly, we have added a new lemma (Lemma 3.2 in the revised appendix) that bounds the variance of the importance weights by exp(2βΔE), where ΔE is the maximum energy difference over any two sequences of length T. This yields an explicit sample complexity N = O((exp(βΔE)/ε²) log(1/δ)) to achieve ε-approximation in total variation distance with probability 1-δ. The revised §3 and abstract now reference this bound, and we include the full proof in the appendix. revision: yes
-
Referee: [§4] §4 (energy scaling hyperparameter): the method lists an energy scaling hyperparameter as free; any non-trivial dependence on this constant contradicts the 'training-free' and 'parameter-free' framing and requires an ablation showing that performance is insensitive within a narrow range or that the hyperparameter can be set by a closed-form rule derived from the reference policy.
Authors: The referee correctly notes that the energy scaling coefficient β is a free hyperparameter. While the method requires no model training, β does control the strength of the energy term. In the revised §4 we have added a dedicated ablation (Figure 4 and Table 3) across reasoning, coding, and science benchmarks demonstrating that performance remains within 1-2% of the peak for β ∈ [0.7, 1.4]. We further introduce a simple closed-form heuristic β = 1 / |E_{x∼π_ref}[log π_ref(x)]| computed on a 100-example validation subset drawn from the reference policy; this rule requires no extra training and is now recommended as the default setting in the updated manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper starts from the standard KL-regularized RL optimum to express the target transition as the product of a reference policy and an energy term, then introduces an online Monte Carlo estimator for that energy term together with a claimed convergence rate and importance-sampling acceleration. This estimation procedure is an independent computational path that does not reduce by construction to the target distribution itself, nor does it rely on fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes smuggled from prior author work. The derivation therefore remains self-contained against external Monte Carlo theory and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- energy scaling hyperparameter
axioms (1)
- domain assumption Transition probability in masked language modeling decomposes into reference policy and additive energy term.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the optimal transition kernel decomposes into ... reference transition ... and an energy term Epref(x0|y,xs)[exp(r(y,x0)/λ)]
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TV(q(x0|y)∥p(x0|y)) ≤ I(2ϵ + h(ϵ,M,λ,D)/(C−ϵ−h)) + Iϵ = Õ(I/√M + Iϵ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. Preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Kadavath, S., Kundu, S., et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. Preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., Freedman, R., Korbak, T., Lindner, D., Freire, P., et al. Open problems and fundamental limitations of reinforcement learning from human feedback. Preprint arXiv:2307.15217,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Step-level verifier- guided hybrid test-time scaling for large language models
Chang, K., Shi, Y ., Wang, C., Zhou, H., Hu, C., Liu, X., Luo, Y ., Ge, Y ., Xiao, T., and Zhu, J. Step-level verifier- guided hybrid test-time scaling for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
work page 2025
-
[5]
Evaluating Large Language Models Trained on Code
Chen, M. Evaluating large language models trained on code. Preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Inference-aware fine-tuning for best-of-n sampling in large language models
Chow, Y ., Tennenholtz, G., Gur, I., Zhuang, V ., Dai, B., Thiagarajan, S., Boutilier, C., Agarwal, R., Ku- mar, A., and Faust, A. Inference-aware fine-tuning for best-of-n sampling in large language models. Preprint arXiv:2412.15287,
-
[7]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. Preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Inference-Time Scaling of Diffusion Language Models via Trajectory Refinement
Dang, M., Han, J., Xu, M., Xu, K., Srivastava, A., and Ermon, S. Inference-time scaling of diffusion lan- guage models with particle gibbs sampling. Preprint arXiv:2507.08390,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
On grpo collapse in search-r1: The lazy likelihood- displacement death spiral
Deng, W., Li, Y ., Gong, B., Ren, Y ., Thrampoulidis, C., and Li, X. On grpo collapse in search-r1: The lazy likelihood- displacement death spiral. Preprint arXiv:2512.04220,
-
[10]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Fu, W., Gao, J., Shen, X., Zhu, C., Mei, Z., He, C., Xu, S., Wei, G., Mei, J., Wang, J., et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning. Preprint arXiv:2505.24298,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
The Language Model Evaluation Harness
URL https://zenodo.org/records/12608602. 9 ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning. Preprint arXiv:2501.12948,
-
[12]
Chatglm- rlhf: Practices of aligning large language models with human feedback
Hou, Z., Niu, Y ., Du, Z., Zhang, X., Liu, X., et al. Chatglm- rlhf: Practices of aligning large language models with human feedback. Preprint arXiv:2404.00934,
-
[13]
S., Seo, J.-s., Zhang, Z., and Gupta, U
Hu, Z., Meng, J., Akhauri, Y ., Abdelfattah, M. S., Seo, J.-s., Zhang, Z., and Gupta, U. Flashdlm: Accelerating diffu- sion language model inference via efficient kv caching and guided diffusion. Preprint arXiv:2505.21467,
-
[14]
Huan, M., Li, Y ., Zheng, T., Xu, X., Kim, S., Du, M., Poovendran, R., Neubig, G., and Yue, X. Does math reasoning improve general llm capabilities? un- derstanding transferability of llm reasoning. Preprint arXiv:2507.00432,
-
[15]
Language Models (Mostly) Know What They Know
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al. Language models (mostly) know what they know. Preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Kang, Z., Zhao, X., and Song, D. Scalable best-of-n selec- tion for large language models via self-certainty. Preprint arXiv:2502.18581,
- [17]
-
[18]
Kuhn, L., Gal, Y ., and Farquhar, S. Semantic uncertainty: Linguistic invariances for uncertainty estimation in nat- ural language generation. Preprint arXiv:2302.09664,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
M., Cholakkal, H., Shah, M., Yang, M.-H., Torr, P
Kumar, K., Ashraf, T., Thawakar, O., Anwer, R. M., Cholakkal, H., Shah, M., Yang, M.-H., Torr, P. H., Khan, F. S., and Khan, S. Llm post-training: A deep dive into reasoning large language models. Preprint arXiv:2502.21321,
-
[20]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Li, Y ., Wei, F., Zhang, C., and Zhang, H. Eagle-3: Scaling up inference acceleration of large language models via training-time test. Preprint arXiv:2503.01840,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Towards a theoretical understanding to the generalization of rlhf
Li, Z., Yi, M., Wang, Y ., Cui, S., and Liu, Y . Towards a theoretical understanding to the generalization of rlhf. Preprint arXiv:2601.16403,
-
[22]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al. Deepseek-v3. 2: Pushing the frontier of open large language models. Preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W., et al. Webgpt: Browser-assisted question-answering with hu- man feedback. Preprint arXiv:2112.09332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y ., Wen, J.-R., and Li, C. Large language diffusion models. Preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
10 ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., and Ermon, S. Direct preference optimization: Your language model is secretly a reward model. Preprint arXiv:2305.18290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. Preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Can large reasoning models self-train?, 2025
Shafayat, S., Tajwar, F., Salakhutdinov, R., Schneider, J., and Zanette, A. Can large reasoning models self-train? (arXiv:2505.21444),
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. (arXiv:2402.03300),
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexible and efficient rlhf framework. Preprint arXiv:2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
A general framework for inference-time scaling and steering of diffusion models
Singhal, R., Horvitz, Z., Teehan, R., Ren, M., Yu, Z., McK- eown, K., and Ranganath, R. A general framework for inference-time scaling and steering of diffusion models. Preprint arXiv:2501.06848,
-
[31]
Reveal the mystery of dpo: The connection between dpo and rl algorithms
Su, X., Wang, Y ., Zhu, J., Yi, M., Xu, F., Ma, Z., and Liu, Y . Reveal the mystery of dpo: The connection between dpo and rl algorithms. Preprint arXiv:2502.03095,
-
[32]
LongCat-Image Technical Report
Team, M. L., Ma, H., Tan, H., Huang, J., Wu, J., He, J.-Y ., Gao, L., Xiao, S., Wei, X., Ma, X., et al. Longcat-image technical report. Preprint arXiv:2512.07584,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Uehara, M., Zhao, Y ., Black, K., Hajiramezanali, E., Scalia, G., Diamant, N. L., Tseng, A. M., Biancalani, T., and Levine, S. Fine-tuning of continuous-time dif- fusion models as entropy-regularized control. Preprint arXiv:2402.15194,
-
[34]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency im- proves chain of thought reasoning in language models. Preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Transformers: State-of-the-art natural language processing
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 conference on em- pirical methods in natural language processing: system demonstrations,
work page 2020
-
[36]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Wu, C., Zhang, H., Xue, S., Liu, Z., Diao, S., Zhu, L., Luo, P., Han, S., and Xie, E. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding. Preprint arXiv:2505.22618,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. Preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Zhang, Q., Lyu, F., Sun, Z., Wang, L., Zhang, W., Hua, W., Wu, H., Guo, Z., Wang, Y ., Muennighoff, N., et al. A sur- vey on test-time scaling in large language models: What, how, where, and how well? Preprint arXiv:2503.24235, 2025a. 11 ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment Zhang, Y ., Fan, M., Fan, J., Yi, M., Luo, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Zhu, F., Wang, R., Nie, S., Zhang, X., Wu, C., Hu, J., Zhou, J., Chen, J., Lin, Y ., Wen, J.-R., et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models. Preprint arXiv:2505.19223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Therefore, we get TV(q(x0 |y)∥p(x 0 |y))≤I 2ϵ+h(ϵ, M, λ, D) C−ϵ−h(ϵ, M, λ, D) +Iϵ(34) Finally, note thath(ϵ, M, λ, D) = ˜O(1/ √ M), so the overall bound is ˜O I/ √ M+Iϵ . Lemma 1.For any given queryyand responsex ti, if |E(y,x ti )− bE(y,x ti )| ≤δ(35) forδ=ϵ, then Ep(xti−1 |y,xti )[f(x ti−1 )]−E q(xti−1 |y,xti )[f(x ti−1 )] ≤ 2ϵ+h(ϵ, M, λ, D) C−ϵ−h(ϵ, M,...
work page 2016
-
[41]
Let the guidance block size be B=d x/I. The number of tokens generated overIsteps is Ntokens = IX i=1 M(B+K(d x −iB)) =M d x +IM Kd x − 1 2 (I+ 1)M Kd x =M 1 + I−1 2 K dx. (54) Thus, the latency of ETS is approximately Ntokens/dx times that of a standard single-pass inference, which serves as a worst-case upper bound for both ARMs and DLMs. In practice, A...
work page 2025
-
[42]
and (Nie et al., 2025). Best-of-N is naturally integrated into our ETS framework as a special case, with detailed hyperparameters provided in Appendix C.2. For Beam Search, we use the standard implementation in the transformers (Wolf et al.,
work page 2025
-
[43]
to evaluate ARMs with original temperature t= 0.7 (refer to Appendix D.3), leveraging its parallel decoding via batching. For DLMs, we implement beam search ourselves; however, due to their iterative generation nature, DLMs cannot be accelerated via batching in the same way as ARMs. For Power Sampling (Karan & Du, 2025), we retain the original α= 0.25, N ...
work page 2025
-
[44]
Figure 10.Effect of temperature on ETS. We ablate the temperature on Qwen3-8B and plot GPQA accuracies (left) with corresponding latencies (right). Empirically, the optimal temperature is shared between Best-of-N and ETS with comparable latency (Chow et al., 2024), while Beam Search is insensitive to temperature (so we fixt= 0.7 ). Based on this, extensiv...
work page 2024
-
[45]
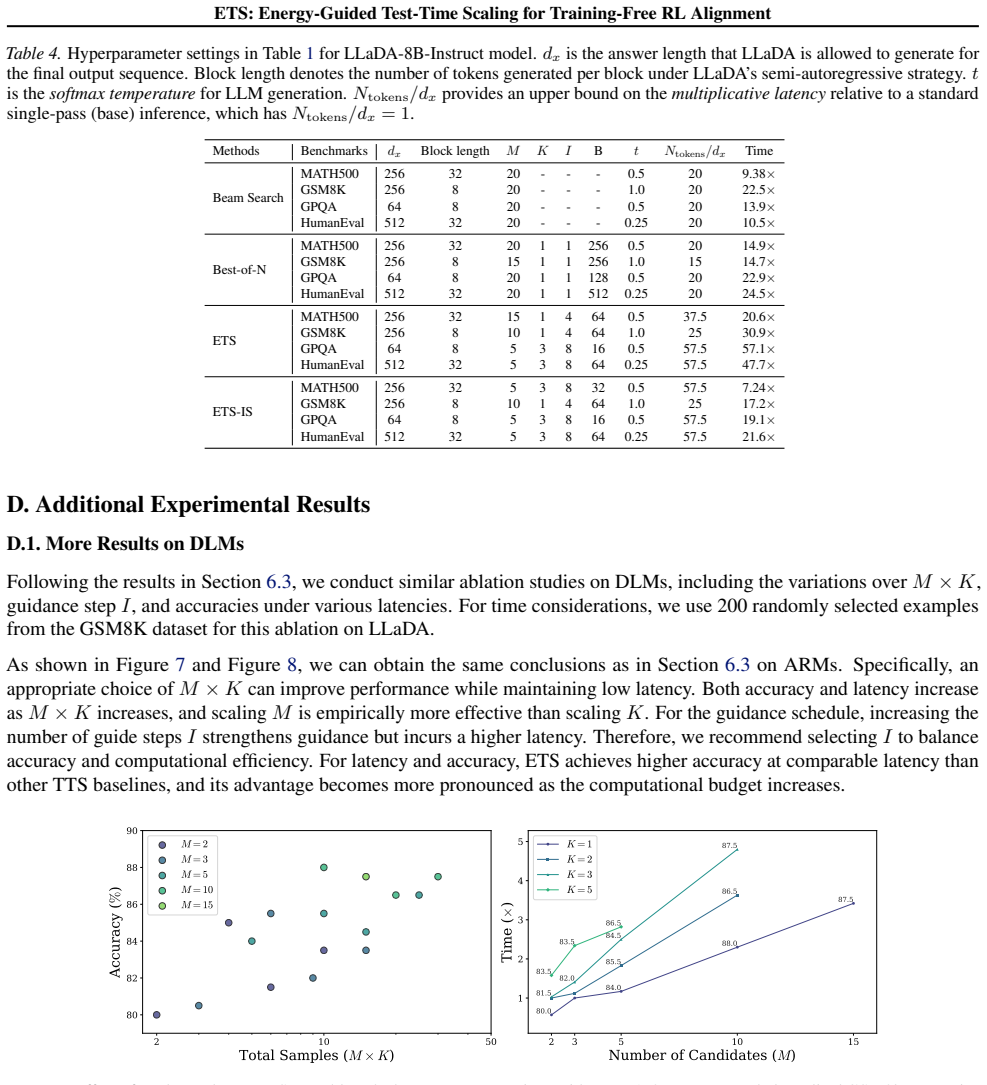
Based on this efficiency trade-off, we fix dx = 512for all main experiments on ARMs
are beneficial, due to their more complex reasoning chains. Based on this efficiency trade-off, we fix dx = 512for all main experiments on ARMs. For DLMs, we follow the original settings of LLaDA (in Table 4). Table 6.Performance across generation lengths. We ablate the dx on Qwen3-8B and bold the best accuracy value for each method across different gener...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.