Recognition: 2 theorem links
· Lean TheoremImproving Multimodal Learning with Dispersive and Anchoring Regularization
Pith reviewed 2026-05-16 09:57 UTC · model grok-4.3
The pith
Regularizing multimodal representation geometry mitigates modality trade-offs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that applying an intra-modal dispersive regularizer to promote representation diversity together with an inter-modal anchoring regularizer to limit cross-modal sample drift on intermediate embeddings reduces the geometric pathologies that limit performance, yielding consistent gains in both multimodal and unimodal tasks without architectural modifications.
What carries the argument
The dispersive-and-anchoring regularization framework, which adds an intra-modal dispersive term promoting diversity and an inter-modal anchoring term bounding cross-modal drift to the training objective.
If this is right
- Consistent gains appear in both multimodal accuracy and unimodal robustness on multiple benchmarks.
- Modality trade-offs are reduced because each modality retains useful structure.
- The method works as a lightweight addition compatible with existing training paradigms.
- No architectural changes are needed, so the regularizers can be inserted into current models.
Where Pith is reading between the lines
- The same geometric constraints might transfer to other multi-view or multi-task settings where representation collapse occurs.
- Adaptive weighting of the two regularizer terms could further improve results when modalities have different strengths.
- The approach suggests that explicit geometry control may become a standard add-on comparable to common regularizers like dropout in multimodal pipelines.
Load-bearing premise
That intra-modal collapse and cross-modal inconsistency are the main geometric issues limiting multimodal performance and that the proposed regularizers can be added without new optimization instabilities.
What would settle it
An experiment that applies the regularizers to a well-tuned multimodal model on a standard benchmark and observes no gain or a clear drop in both multimodal and unimodal metrics would falsify the central claim.
Figures



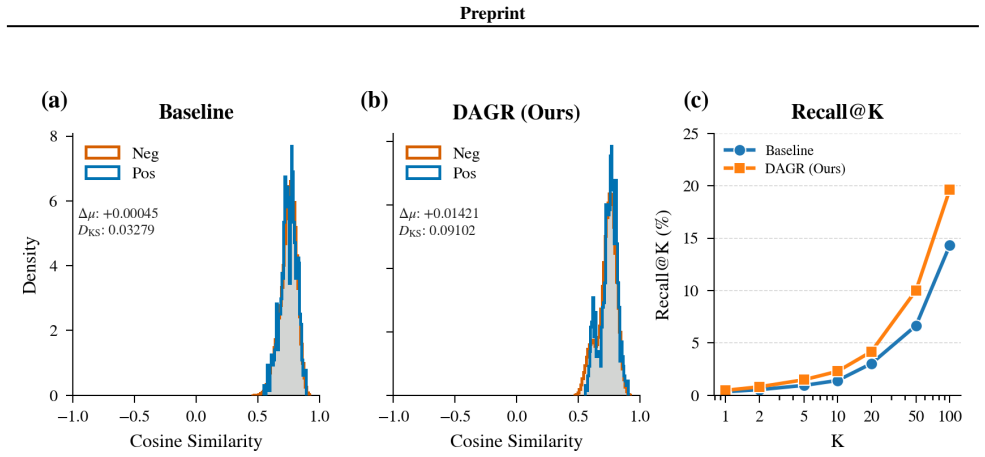
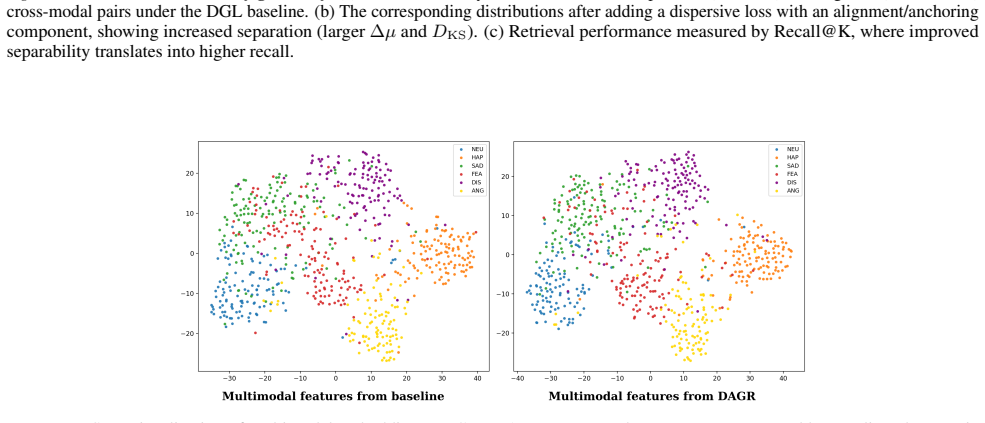
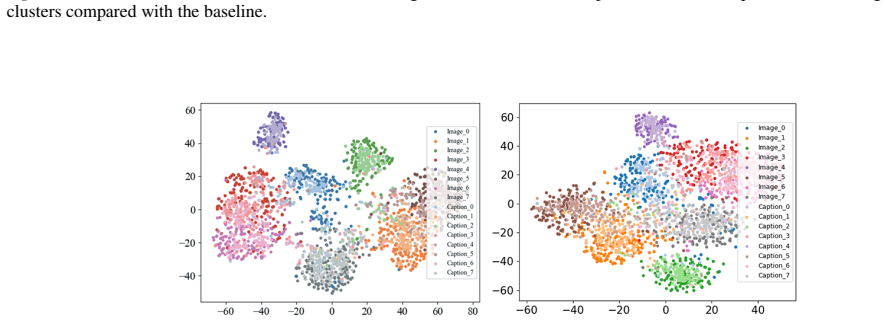





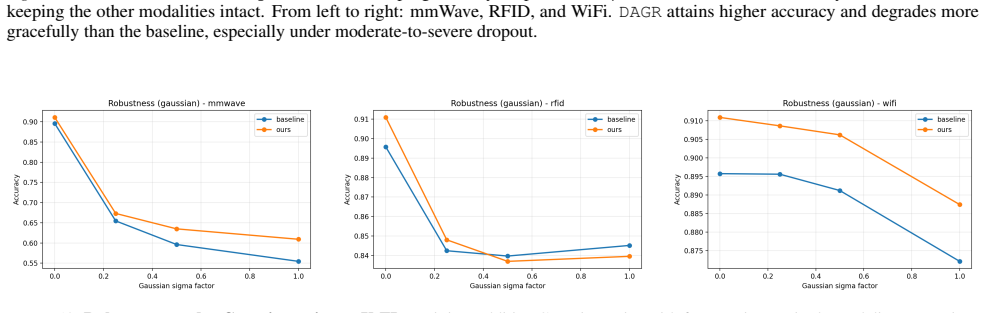

read the original abstract
Multimodal learning aims to integrate complementary information from heterogeneous modalities, yet strong optimization alone does not guaranty well-structured representations. Even under carefully balanced training schemes, multimodal models often exhibit geometric pathologies, including intra-modal representation collapse and sample-level cross-modal inconsistency, which degrade both unimodal robustness and multimodal fusion. We identify representation geometry as a missing control axis in multimodal learning and propose \regName, a lightweight geometry-aware regularization framework. \regName enforces two complementary constraints on intermediate embeddings: an intra-modal dispersive regularization that promotes representation diversity, and an inter-modal anchoring regularization that bounds sample-level cross-modal drift without rigid alignment. The proposed regularizer is plug-and-play, requires no architectural modifications, and is compatible with various training paradigms. Extensive experiments across multiple multimodal benchmarks demonstrate consistent improvements in both multimodal and unimodal performance, showing that explicitly regulating representation geometry effectively mitigates modality trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies intra-modal representation collapse and sample-level cross-modal inconsistency as geometric pathologies in multimodal learning that persist even under balanced optimization. It proposes a lightweight, plug-and-play regularization framework (dispersive intra-modal and anchoring inter-modal terms) that enforces representation diversity and bounds cross-modal drift without rigid alignment or architectural changes, claiming consistent gains in both multimodal fusion and unimodal robustness across benchmarks.
Significance. If the central claim holds under proper controls, the work would supply a simple additional axis for controlling embedding geometry in multimodal models, potentially reducing modality trade-offs without extra capacity or retuning. The plug-and-play design and compatibility with existing paradigms would make the contribution broadly usable if the geometry-specific mechanism is isolated from generic regularization effects.
major comments (2)
- [Experiments] Experiments section: the manuscript reports consistent improvements but supplies no ablation replacing the dispersive/anchoring terms with non-geometric regularizers of matched effective strength (e.g., isotropic noise or additional L2 penalty). Without this isolation, gains cannot be attributed specifically to geometry regulation rather than generic auxiliary-loss effects, which directly undermines the central claim that 'explicitly regulating representation geometry' is the operative mechanism.
- [Abstract] Abstract and results: no quantitative numbers, standard deviations, or failure-mode analysis are supplied for the claimed 'consistent improvements,' leaving the magnitude, reliability, and scope of the gains unassessable and making the soundness of the empirical support low.
minor comments (2)
- [Abstract] Abstract: 'guaranty' should be 'guarantee'.
- [Method] Notation: the symbol for the proposed regularizer is introduced as 'regName' without an explicit definition or expansion in the provided text; a clear equation or pseudocode block would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and will revise the manuscript to strengthen the empirical isolation of our geometric mechanism and the quantitative presentation of results.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript reports consistent improvements but supplies no ablation replacing the dispersive/anchoring terms with non-geometric regularizers of matched effective strength (e.g., isotropic noise or additional L2 penalty). Without this isolation, gains cannot be attributed specifically to geometry regulation rather than generic auxiliary-loss effects, which directly undermines the central claim that 'explicitly regulating representation geometry' is the operative mechanism.
Authors: We agree that isolating the contribution of geometry regulation from generic regularization effects is essential to support our central claim. Although our current results show consistent gains across benchmarks under the proposed terms, the manuscript does not yet contain the requested controls. In the revised version we will add ablations that replace the dispersive and anchoring regularizers with non-geometric alternatives of matched effective strength (isotropic noise injection and additional L2 penalties on the same embeddings). These experiments will quantify whether the geometry-specific constraints yield distinct improvements over generic auxiliary losses, thereby directly addressing the concern. revision: yes
-
Referee: [Abstract] Abstract and results: no quantitative numbers, standard deviations, or failure-mode analysis are supplied for the claimed 'consistent improvements,' leaving the magnitude, reliability, and scope of the gains unassessable and making the soundness of the empirical support low.
Authors: We acknowledge that the abstract currently lacks specific numerical results and that the results section would benefit from explicit reliability measures. In the revision we will update the abstract to report key quantitative gains (average improvements with standard deviations across the main benchmarks) and will add a concise failure-mode analysis in the experiments section to better characterize the scope and limitations of the observed benefits. revision: yes
Circularity Check
No circularity: regularizers imposed as external constraints, not derived from inputs
full rationale
The manuscript introduces dispersive intra-modal and anchoring inter-modal regularization terms as additive, plug-and-play losses on intermediate embeddings. No equations, self-referential definitions, or fitted-parameter predictions appear in the provided text; the geometry constraints are stated as independent controls rather than quantities obtained by construction from the training objective or prior self-citations. Experimental gains are reported on external benchmarks without any reduction of the claimed mechanism to a renaming or tautological fit of the same data. The derivation chain therefore remains self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- dispersive and anchoring regularization coefficients
axioms (1)
- domain assumption Multimodal models exhibit intra-modal representation collapse and sample-level cross-modal inconsistency that degrade performance even under balanced training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
intra-modal dispersive regularization … Ld = log(1/B(B−1) ∑ exp(−t‖z̃mi − z̃mj‖²)) … inter-modal anchoring La = 1/B ∑ (‖z̃mi − z̃ni‖² − τ)²₊
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.2 … Rényi-2 entropy … effective rank reff(Σ) = (tr Σ)² / tr(Σ²)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Bardes, A., Ponce, J., and LeCun, Y . Vicreg: Variance- invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
A closer look at multimodal representation collapse.arXiv preprint arXiv:2505.22483,
Chaudhuri, A., Dutta, A., Bui, T., and Georgescu, S. A closer look at multimodal representation collapse.arXiv preprint arXiv:2505.22483,
-
[3]
Chen, X. and Yang, J. X-fi: A modality-invariant foundation model for multimodal human sensing.arXiv preprint arXiv:2410.10167,
-
[4]
What to align in multimodal contrastive learning? arXiv preprint arXiv:2409.07402,
Dufumier, B., Castillo-Navarro, J., Tuia, D., and Thiran, J.-P. What to align in multimodal contrastive learning? arXiv preprint arXiv:2409.07402,
-
[5]
Fernando, H., Ram, P., Zhou, Y ., Dan, S., Samulowitz, H., Baracaldo, N., and Chen, T. Mitigating modality imbalance in multi-modal learning via multi-objective optimization.arXiv preprint arXiv:2511.06686,
- [6]
-
[7]
Joy, T., Shi, Y ., Torr, P. H., Rainforth, T., Schmon, S. M., and Siddharth, N. Learning multimodal vaes through mutual supervision.arXiv preprint arXiv:2106.12570,
-
[8]
Kwon, J., Kim, M., Lee, E., Choi, J., and Kim, Y . See- saw modality balance: See gradient, and sew impaired vision-language balance to mitigate dominant modality bias.arXiv preprint arXiv:2503.13834,
-
[9]
M., Daunhawer, I., and V ogt, J
9 Preprint Sutter, T. M., Daunhawer, I., and V ogt, J. E. Generalized multimodal elbo.arXiv preprint arXiv:2105.02470,
-
[10]
Xrf55: A radio frequency dataset for human indoor action analysis
Wang, F., Lv, Y ., Zhu, M., Ding, H., and Han, J. Xrf55: A radio frequency dataset for human indoor action analysis. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(1):1–34, 2024a. Wang, H., Luo, S., Hu, G., and Zhang, J. Gradient-guided modality decoupling for missing-modality robustness. In Proceedings of the AAAI ...
- [11]
-
[12]
Yaras, C., Chen, S., Wang, P., and Qu, Q. Explaining and mitigating the modality gap in contrastive multimodal learning.arXiv preprint arXiv:2412.07909,
-
[13]
Yi, L., Douady, R., and Chen, C. Decipher the modality gap in multimodal contrastive learning: From convergent representations to pairwise alignment.arXiv preprint arXiv:2510.03268,
-
[14]
Yin, W., Zhou, P., Xiao, Z., Liu, J., Yu, S., Sonke, J.- J., and Gavves, E. Towards uniformity and alignment for multimodal representation learning.arXiv preprint arXiv:2602.09507,
-
[15]
is an audio–visual dataset constructed by filtering the Kinetics dataset to retain 34 sound-related action classes that are potentially manifested in both visual and auditory channels. It contains approximately 19k 10-second video clips, with 15k samples for training, 1.9k for validation, and 1.9k for testing. Compared to CREMA-D, KS presents a more chall...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.