Recognition: no theorem link
Rate-Distortion Optimization for Transformer Inference
Pith reviewed 2026-05-16 09:59 UTC · model grok-4.3
The pith
A rate-distortion framework lets transformers compress intermediate representations to cut inference bitrate while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By casting the compression of transformer intermediate activations as a rate-distortion problem, the authors demonstrate that learnable codecs can produce compact encodings that trade bitrate for accuracy; the simplest such codec yields substantial rate savings on language tasks, outperforms more elaborate methods, and the observed rates are governed by the derived information-theoretic limits.
What carries the argument
The rate-distortion optimization framework that learns compact encodings of intermediate representations while trading off bitrate against downstream accuracy.
If this is right
- Substantial rate savings on language benchmarks from the simplest codec.
- Outperformance of more complex compression methods.
- Empirical rates for varied architectures and tasks track the derived information-theoretic bounds.
- A unified view of transformer representation coding performance across tasks.
Where Pith is reading between the lines
- The same compression approach could reduce communication costs when splitting transformer layers across edge and cloud devices.
- Bounds derived here might serve as quick predictors of compression feasibility for new models without running full experiments.
- The framework suggests a path to standardize intermediate coding formats for interoperable distributed inference.
Load-bearing premise
That the learned compression of intermediate representations preserves downstream task accuracy sufficiently for the rate-distortion tradeoff to remain useful in practice.
What would settle it
Compress the intermediates of a held-out transformer model on a new task, measure the achieved rate and accuracy drop, and check whether the rate stays within the derived bounds while accuracy degradation stays below the level that breaks the original tradeoff.
Figures




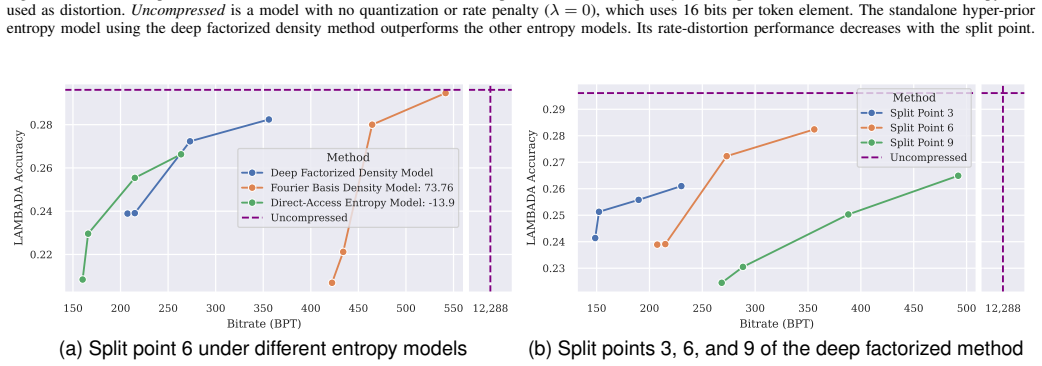

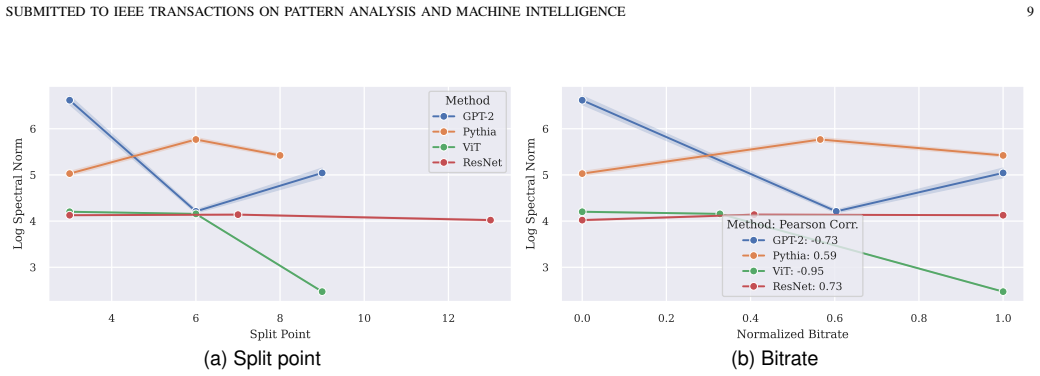
read the original abstract
Transformers achieve superior performance on many tasks, but impose heavy compute and memory requirements during inference. This inference can be made more efficient by partitioning the process across multiple devices, which, in turn, requires compressing its intermediate representations. We introduce a principled rate-distortion-based framework for lossy compression that learns compact encodings that explicitly trade bitrate for accuracy. Experiments on language benchmarks show that the simplest of the proposed codecs achieves substantial rate savings, outperforming more complex methods. We characterize and analyze the rate-distortion behaviour of transformers, offering a unified lens for understanding performance in representation coding. This formulation extends information-theoretic concepts to derive bounds on the achievable rate of learnable codecs. For different architectures and tasks, we empirically demonstrate that their rates are driven by these bounds, adding to the explainability of the formulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a rate-distortion optimization framework for lossy compression of intermediate representations in transformers to support efficient multi-device inference. It derives information-theoretic bounds on achievable rates for learnable codecs, presents experiments on language benchmarks showing that the simplest proposed codec yields substantial rate savings while outperforming more complex methods, and claims that empirical rates across architectures and tasks are driven by these bounds, providing a unified lens for representation coding.
Significance. If the bounds prove independent of fitted parameters and the empirical operating points are shown to lie close to the derived expressions at matched distortion levels, the work supplies a principled information-theoretic account of transformer compression that could guide codec design and improve explainability of rate-distortion trade-offs in large models.
major comments (3)
- Abstract: the central claim that 'empirical rates ... are driven by these bounds' lacks a direct tightness verification; no indication is given whether the bounds are evaluated at the same distortion operating points as the learned codecs or whether they use the identical task loss employed during training.
- Abstract: the independence of the derived information-theoretic bounds from codec parameters fitted on the same transformer data is not established, creating a circularity risk that undermines the explanatory power of the bounds for the observed rates.
- Abstract: the quantification of distortion (task accuracy degradation) and the fairness of baselines are not detailed, which is load-bearing for the assertion that the simplest codec achieves substantial rate savings while preserving downstream performance.
minor comments (1)
- The abstract would be strengthened by naming the specific language benchmarks and transformer architectures used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We have revised the manuscript to strengthen the abstract and add supporting analysis, addressing each concern directly while preserving the core contributions.
read point-by-point responses
-
Referee: Abstract: the central claim that 'empirical rates ... are driven by these bounds' lacks a direct tightness verification; no indication is given whether the bounds are evaluated at the same distortion operating points as the learned codecs or whether they use the identical task loss employed during training.
Authors: We agree that explicit tightness verification strengthens the claim. In the revised manuscript we added a dedicated subsection and figure that evaluates the information-theoretic bounds at the precise distortion operating points (measured via the same task loss used in codec training) achieved by each learned codec. The updated results show the empirical rates lie close to the bounds across architectures and tasks. revision: yes
-
Referee: Abstract: the independence of the derived information-theoretic bounds from codec parameters fitted on the same transformer data is not established, creating a circularity risk that undermines the explanatory power of the bounds for the observed rates.
Authors: The bounds are derived solely from the rate-distortion function of the transformer representations under the task distortion measure, using only the empirical statistics of the activations; no codec parameters enter the derivation. The learned codec is subsequently optimized to approach this bound. We have clarified this separation in the revised abstract and methods to remove any ambiguity about circularity. revision: yes
-
Referee: Abstract: the quantification of distortion (task accuracy degradation) and the fairness of baselines are not detailed, which is load-bearing for the assertion that the simplest codec achieves substantial rate savings while preserving downstream performance.
Authors: We accept that the abstract was insufficiently explicit. The revision now quantifies accuracy degradation at each operating point (reporting exact percentage drops relative to the uncompressed baseline) and includes an expanded experimental section with a comparison table detailing baseline architectures, training protocols, and matched evaluation settings to demonstrate fairness. revision: yes
Circularity Check
No significant circularity detected in derivation of rate-distortion bounds
full rationale
The paper derives information-theoretic bounds on achievable rates for learnable codecs by extending standard rate-distortion concepts, then reports empirical alignment of observed transformer rates with those bounds across architectures and tasks. No equations or self-citations are presented that reduce the bounds themselves to fitted parameters extracted from the same experimental data, nor does the demonstration of 'driven by' reduce to a tautology by construction. The framework is introduced as a principled extension independent of the specific codec training, and the empirical claim is presented as a separate verification step rather than a definitional restatement of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intermediate transformer representations behave as signals amenable to lossy compression under a rate-distortion tradeoff
Reference graph
Works this paper leans on
-
[1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inNeurIPS, 2017
work page 2017
-
[2]
M. A. Maruf, A. Azim, N. Auluck, and M. Sahi, “Optimizing DNN training with pipeline model parallelism for enhanced performance in embedded systems,”JPDC, 2024
work page 2024
-
[3]
PISeL: Pipelining DNN inference for serverless computing,
M. R. Jafari, J. Su, Y . Zhang, O. Wang, and W. Zhang, “PISeL: Pipelining DNN inference for serverless computing,” inACM CIKM, 2024
work page 2024
-
[4]
Split computing and early exiting for deep learning applications: Survey and research challenges,
Y . Matsubara, M. Levorato, and F. Restuccia, “Split computing and early exiting for deep learning applications: Survey and research challenges,” ACM Computing Surveys, 2023
work page 2023
-
[5]
Dynamic split computing framework in distributed serverless edge clouds,
H. Ko, H. Jeong, D. Jung, and S. Pack, “Dynamic split computing framework in distributed serverless edge clouds,”IEEE IoTJ, 2024
work page 2024
-
[6]
Variational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” inICLR, 2018
work page 2018
-
[7]
T. M. Cover and J. A. Thomas,Elements of information theory (Second edition). Wiley, 2006
work page 2006
-
[8]
Scalable image coding for humans and machines,
H. Choi and I. V . Bajic, “Scalable image coding for humans and machines,”IEEE TIP, 2022
work page 2022
-
[9]
A theory of usable information under computational constraints,
Y . Xu, S. Zhao, J. Song, R. Stewart, and S. Ermon, “A theory of usable information under computational constraints,” inICLR, 2020
work page 2020
-
[10]
S. Shalev-Shwartz and S. Ben-David,Understanding machine learning - from theory to algorithms. Cambridge University Press, 2014
work page 2014
-
[11]
Y . Benyamini and J. Lindenstrauss,Geometric Nonlinear Functional Analysis. American Mathematical Society, 2000. SUBMITTED TO IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 11
work page 2000
-
[12]
A survey of resource-efficient LLM and multimodal foundation models,
M. Xu, W. Yin, D. Cai, R. Yi, D. Xu, Q. Wang, B. Wu, Y . Zhao, C. Yang, S. Wang, Q. Zhang, Z. Lu, L. Zhang, S. Wang, Y . Li, Y . Liu, X. Jin, and X. Liu, “A survey of resource-efficient LLM and multimodal foundation models,”ArXiv, vol. 2401.08092, 2024
-
[13]
Orca: A distributed serving system for transformer-based generative models,
G. Yu, J. S. Jeong, G. Kim, S. Kim, and B. Chun, “Orca: A distributed serving system for transformer-based generative models,” inUSENIX OSDI, 2022
work page 2022
-
[14]
Taming throughput-latency tradeoff in LLM inference with Sarathi-Serve,
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, A. Tumanov, and R. Ramjee, “Taming throughput-latency tradeoff in LLM inference with Sarathi-Serve,” inUSENIX OSDI, 2024
work page 2024
-
[15]
FlexGen: High-throughput generative inference of large language models with a single GPU,
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, P. Liang, C. R ´e, I. Stoica, and C. Zhang, “FlexGen: High-throughput generative inference of large language models with a single GPU,” inICML, 2023
work page 2023
-
[16]
Fastdecode: High-throughput GPU-efficient LLM serving using heterogeneous pipelines,
J. He and J. Zhai, “Fastdecode: High-throughput GPU-efficient LLM serving using heterogeneous pipelines,”ArXiv, vol. 2403.11421, 2024
-
[17]
Splitwise: Efficient generative LLM inference using phase splitting,
P. Patel, E. Choukse, C. Zhang, A. Shah, ´I. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative LLM inference using phase splitting,” inISCA, 2024
work page 2024
-
[18]
LoRAPrune: Structured pruning meets low-rank parameter-efficient fine-tuning,
M. Zhang, H. Chen, C. Shen, Z. Yang, L. Ou, X. Yu, and B. Zhuang, “LoRAPrune: Structured pruning meets low-rank parameter-efficient fine-tuning,” inACL, 2024
work page 2024
-
[19]
AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W. Chen, W. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration,” inMLSys, 2024
work page 2024
-
[20]
LLMLingua: Com- pressing prompts for accelerated inference of large language models,
H. Jiang, Q. Wu, C. Lin, Y . Yang, and L. Qiu, “LLMLingua: Com- pressing prompts for accelerated inference of large language models,” inEMNLP, 2023
work page 2023
-
[21]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long- document transformer,”ArXiv, vol. 2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[22]
End-to-end optimized image compression,
J. Ball ´e, V . Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” inICLR, 2017
work page 2017
-
[23]
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “ELIC: efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,” inCVPR, 2022
work page 2022
-
[24]
The devil is in the details: Window- based attention for image compression,
R. Zou, C. Song, and Z. Zhang, “The devil is in the details: Window- based attention for image compression,” inCVPR, 2022
work page 2022
-
[25]
MLIC++: Linear complexity multi-reference entropy modeling for learned image com- pression,
W. Jiang, J. Yang, Y . Zhai, F. Gao, and R. Wang, “MLIC++: Linear complexity multi-reference entropy modeling for learned image com- pression,”ACM TMCCA, 2025
work page 2025
-
[26]
Rate-distortion in image coding for machines,
A. Harell, A. de Andrade, and I. V . Bajic, “Rate-distortion in image coding for machines,” inPCS, 2022
work page 2022
-
[27]
The information bottleneck method,
N. Tishby, F. C. N. Pereira, and W. Bialek, “The information bottleneck method,” inAllerton Conference, 1999
work page 1999
-
[28]
Multivariate information bottleneck,
N. Friedman, O. Mosenzon, N. Slonim, and N. Tishby, “Multivariate information bottleneck,” inUAI, 2001
work page 2001
-
[29]
Mutual information neural estimation,
M. I. Belghazi, A. Baratin, S. Rajeswar, S. Ozair, Y . Bengio, R. D. Hjelm, and A. C. Courville, “Mutual information neural estimation,” in ICML, 2018
work page 2018
-
[30]
MLIC: Multi- reference entropy model for learned image compression,
W. Jiang, J. Yang, Y . Zhai, P. Ning, F. Gao, and R. Wang, “MLIC: Multi- reference entropy model for learned image compression,” inACM MM, 2023
work page 2023
-
[31]
Frequency-aware transformer for learned image compression,
H. Li, S. Li, W. Dai, C. Li, J. Zou, and H. Xiong, “Frequency-aware transformer for learned image compression,” inICLR, 2024
work page 2024
-
[32]
MambaVC: Learned visual compression with selective state spaces,
S.-Y . Qin, J. Wang, Y . Zhou, B. Chen, T. Luo, B. An, T. Dai, S.-T. Xia, and Y . Wang, “MambaVC: Learned visual compression with selective state spaces,”ArXiv, vol. 2405.15413, 2024
-
[33]
MambaIC: State space models for high-performance learned image compression,
F. Zeng, H. Tang, Y . Shao, S. Chen, L. Shao, and Y . Wang, “MambaIC: State space models for high-performance learned image compression,” inCVPR, 2025
work page 2025
-
[34]
A. D. la Fuente, S. Singh, and J. Ball ´e, “Fourier basis density model,” inPCS, 2024
work page 2024
-
[35]
Rate-accuracy bounds in visual coding for machines,
I. V . Baji ´c, “Rate-accuracy bounds in visual coding for machines,” in IEEE MIPR, 2025
work page 2025
-
[36]
Towards task-compatible compressible representations,
A. de Andrade and I. V . Bajic, “Towards task-compatible compressible representations,” inICME Workshops, 2024
work page 2024
-
[37]
Rate-distortion theory in coding for machines and its applications,
A. Harell, Y . Foroutan, N. A. Ahuja, P. Datta, B. Kanzariya, V . S. Somayazulu, O. Tickoo, A. de Andrade, and I. V . Bajic, “Rate-distortion theory in coding for machines and its applications,”IEEE TPAMI, 2025
work page 2025
- [38]
-
[39]
Generating Wikipedia by summarizing long sequences,
P. J. Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer, “Generating Wikipedia by summarizing long sequences,” in ICLR, 2018
work page 2018
-
[40]
Improving language understand- ing by generative pre-training,
A. Radford and K. Narasimhan, “Improving language understand- ing by generative pre-training,” https://openai.com/index/language- unsupervised, 2018
work page 2018
-
[41]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. R. Stone, P. Albert, A. Almahairi, Y . Babaei, N. lay Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. M. Bikel, L. Blecher, C. tian Cant ´on Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. S. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabs...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,” inUSENIX OSDI, 2024
work page 2024
-
[43]
Universally quantized neural compression,
E. Agustsson and L. Theis, “Universally quantized neural compression,” inNeurIPS, 2020
work page 2020
-
[44]
Lossy image compression with compressive autoencoders,
L. Theis, W. Shi, A. Cunningham, and F. Husz ´ar, “Lossy image compression with compressive autoencoders,” inICLR, 2017
work page 2017
-
[45]
End-to-end optimization of nonlinear transform codes for perceptual quality,
J. Ball ´e, V . Laparra, and E. P. Simoncelli, “End-to-end optimization of nonlinear transform codes for perceptual quality,” inPCS, 2016
work page 2016
- [46]
-
[47]
Release strategies and the social impacts of language models,
I. Solaiman, M. Brundage, J. Clark, A. Askell, A. Herbert-V oss, J. Wu, A. Radford, and J. Wang, “Release strategies and the social impacts of language models,”ArXiv, vol. 1908.09203, 2019
-
[48]
A. Gokaslan, V . Cohen, E. Pavlick, and S. Tellex, “OpenWebText Corpus,” https://Skylion007.github.io/OpenWebTextCorpus, 2019
work page 2019
-
[49]
Calculation of average PSNR differences between RD- curves,
G. Bjontegaard, “Calculation of average PSNR differences between RD- curves,”ITU-T SC16/Q6 VCEG-M33, 2001
work page 2001
-
[50]
The LAMBADA dataset: Word prediction requiring a broad discourse context,
D. Paperno, G. Kruszewski, A. Lazaridou, Q. N. Pham, R. Bernardi, S. Pezzelle, M. Baroni, G. Boleda, and R. Fern ´andez, “The LAMBADA dataset: Word prediction requiring a broad discourse context,” inACL, 2016
work page 2016
-
[51]
DEFLATE compressed data format specification version 1.3,
P. Deutsch, “DEFLATE compressed data format specification version 1.3,”RFC, 1996
work page 1996
-
[52]
Zstandard compression and the application/zstd media type,
Y . Collet and M. S. Kucherawy, “Zstandard compression and the application/zstd media type,”RFC, 2018
work page 2018
-
[53]
Accelerating load times for DirectX games and apps with GDeflate for DirectStorage,
Y . Uralsky, “Accelerating load times for DirectX games and apps with GDeflate for DirectStorage,” https://developer.nvidia.com/blog/ accelerating-load-times-for-directx-games-and-apps-with-gdeflate-for- directstorage, 2022
work page 2022
-
[54]
J. Duda, “Asymmetric numeral systems: entropy coding combining speed of huffman coding with compression rate of arithmetic coding,” ArXiv, vol. 1311.2540, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[55]
Protocol overhead in IP/ATM networks,
J. D. Cavanaugh, “Protocol overhead in IP/ATM networks,” inMinnesota Supercomputer Center, 1994
work page 1994
-
[56]
Pythia: A suite for analyzing large language models across training and scaling,
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raffet al., “Pythia: A suite for analyzing large language models across training and scaling,” inICML, 2023
work page 2023
-
[57]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inICLR, 2021
work page 2021
-
[58]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inCVPR, 2016
work page 2016
-
[59]
A Krylov-Schur algorithm for large eigenproblems,
G. W. Stewart, “A Krylov-Schur algorithm for large eigenproblems,” SIAM JMAA, 2002
work page 2002
-
[60]
R. B. Lehoucq, D. C. Sorensen, and C. Yang,ARPACK users’ guide: solution of large-scale eigenvalue problems with implicitly restarted Arnoldi methods. SIAM, 1998
work page 1998
- [61]
-
[62]
C. R. Johnson and R. A. Horn,Matrix analysis. Cambridge university press Cambridge, 1985
work page 1985
-
[63]
Localized Rademacher complexities,
P. L. Bartlett, O. Bousquet, and S. Mendelson, “Localized Rademacher complexities,” inCOLT, 2002
work page 2002
-
[64]
Training transformers with enforced lipschitz constants,
L. Newhouse, M. Csail, R. P. Hess, M. Bcs, F. L. Cesista, I. A. Zahorodnii, J. Bernstein, and P. Isola, “Training transformers with enforced lipschitz constants,”ArXiv, vol. 2507.13338, 2025
-
[65]
J.-B. Hiriart-Urruty and C. Lemar ´echal,Convex analysis and minimiza- tion algorithms II: Advanced theory and bundle methods. Springer Berlin, Heidelberg, 1993
work page 1993
-
[66]
On the Information Loss in Memoryless Systems: The Multivariate Case
B. C. Geiger and G. Kubin, “On the information loss in memoryless systems: The multivariate case,”ArXiv, vol. 1109.4856, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[67]
Lecture notes in Rademacher composition and linear prediction,
S. Kakade and A. Tewari, “Lecture notes in Rademacher composition and linear prediction,” 2008. SUBMITTED TO IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 12
work page 2008
-
[68]
M. Ledoux and M. Talagrand,Probability in Banach Spaces: Isoperime- try and Processes. Springer Berlin Heidelberg, 2013
work page 2013
-
[69]
Rademacher and gaussian complexi- ties: Risk bounds and structural results,
P. L. Bartlett and S. Mendelson, “Rademacher and gaussian complexi- ties: Risk bounds and structural results,”JMLR, 2002
work page 2002
-
[70]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inICLR, 2019
work page 2019
-
[71]
ImageNet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet large scale visual recognition challenge,”IJCV, 2015
work page 2015
-
[72]
TorchVision: PyTorch’s com- puter vision library,
TorchVision maintainers and contributors, “TorchVision: PyTorch’s com- puter vision library,”GitHub repository, 2016
work page 2016
-
[73]
Loss- less compression on the GPU,
A. Subramaniam, B. Karsin, D. LaSalle, G. Thomas-Collignon, M. Nicely, M. Milakov, M. Fan, N. Sakharnykh, and O. Lapicque, “Loss- less compression on the GPU,” https://developer.nvidia.com/nvcomp, 2021
work page 2021
-
[74]
worldlife123, “torch ans,” https://github.com/worldlife123/torch ans, 2026. Anderson de Andrade(S’22) received his M.Sc. in Applied Computing from the University of Toronto in 2015 and obtained a B.Eng. degree in Networks and Communications in 2007 from Universidad Tec- nol´ogica del Centro. He is currently an Engineering Science Ph.D. student at Simon Fr...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.