Recognition: no theorem link
JUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion
Pith reviewed 2026-05-16 09:52 UTC · model grok-4.3
The pith
Adapting a pre-trained audio-visual diffusion model with lightweight LoRA enables joint generation of translated audio and synchronized facial motion for video dubbing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that conditioning an audio-visual foundation model on an input video via a LoRA, and training that LoRA on synthetic paired data created by generating language-switched clips then inpainting each half to match the opposite language, produces dubbed videos with higher visual fidelity, more accurate lip synchronization, and greater robustness to complex motion than existing dubbing pipelines.
What carries the argument
The lightweight LoRA that adapts a joint audio-visual diffusion model to condition on an input audio-video clip and generate translated audio together with matching facial animations.
If this is right
- Dubbed videos maintain consistent speaker identity when audio is translated to a new language.
- Lip movements align more closely with the new audio track without separate alignment modules.
- The single model handles complex body motion and real-world lighting better than pipeline approaches.
- No large external collection of paired multilingual video data is required for training.
- Visual quality and robustness improve over methods that treat audio translation and face animation as separate stages.
Where Pith is reading between the lines
- The self-synthesis strategy for creating training pairs could extend to other cross-modal video editing tasks such as emotion transfer.
- If inference speed remains practical, the method could support on-device or live dubbing applications.
- The success of the approach implies that strong generative priors in foundation models can substitute for hand-crafted dubbing architectures in many settings.
- Broader testing across diverse accents and speaking rates would clarify how far the robustness extends beyond the training distribution.
Load-bearing premise
The base generative model can synthesize paired multilingual videos of the same speaker via language switches and inpainting without introducing artifacts that degrade the LoRA adaptation.
What would settle it
A side-by-side evaluation on real-world test videos where the method's outputs show lower lip-synchronization accuracy or more visible visual artifacts than outputs from current multi-stage dubbing systems would falsify the improvement claim.
Figures











read the original abstract
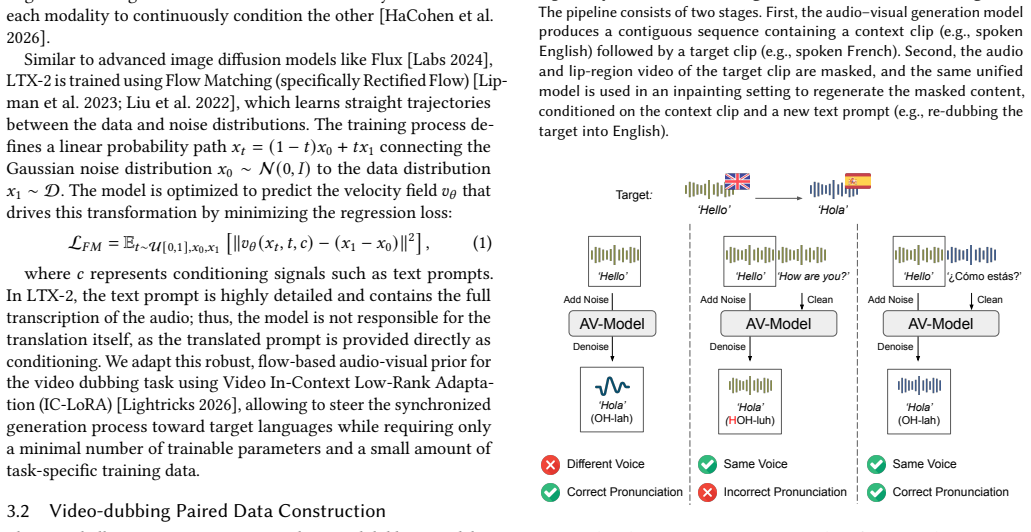
Audio-Visual Foundation Models, which are pretrained to jointly generate sound and visual content, have recently shown an unprecedented ability to model multi-modal generation and editing, opening new opportunities for downstream tasks. Among these tasks, video dubbing could greatly benefit from such priors, yet most existing solutions still rely on complex, task-specific pipelines that struggle in real-world settings. In this work, we introduce a single-model approach that adapts a foundational audio-video diffusion model for video-to-video dubbing via a lightweight LoRA. The LoRA enables the model to condition on an input audio-video while jointly generating translated audio and synchronized facial motion. To train this LoRA, we leverage the generative model itself to synthesize paired multilingual videos of the same speaker. Specifically, we generate multilingual videos with language switches within a single clip, and then inpaint the face and audio in each half to match the language of the other half. By leveraging the rich generative prior of the audio-visual model, our approach preserves speaker identity and lip synchronization while remaining robust to complex motion and real-world dynamics. We demonstrate that our approach produces high-quality dubbed videos with improved visual fidelity, lip synchronization, and robustness compared to existing dubbing pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JUST-DUB-IT, a single-model approach that adapts a pre-trained audio-visual diffusion foundation model via lightweight LoRA for video-to-video dubbing. Training pairs are synthesized by the base model itself: multilingual clips are generated with intra-clip language switches, after which face and audio are inpainted in each half to match the opposite language. The central claim is that the resulting LoRA produces dubbed videos with improved visual fidelity, lip synchronization, and robustness relative to existing multi-stage dubbing pipelines.
Significance. If the synthetic training pairs prove free of systematic artifacts, the method would offer a streamlined alternative to task-specific dubbing pipelines by directly exploiting generative priors from audio-visual foundation models. The self-supervised data-generation strategy is a notable technical contribution that could extend to other cross-lingual audio-visual tasks, provided it supplies unbiased supervision for lip motion and identity preservation.
major comments (2)
- [Method / Training data synthesis] Training-data synthesis (described in the abstract and method): the procedure generates all supervision from the same foundation model via language switches followed by face/audio inpainting. For the performance claims to hold, these pairs must supply clean, unbiased targets that improve phoneme-to-viseme mapping and motion continuity; no quantitative comparison against real multilingual ground-truth recordings or ablation isolating inpainting artifacts is reported, leaving open the possibility that the LoRA merely reproduces base-model failure modes.
- [Results / Experiments] Evaluation (abstract and results): the claim of improved visual fidelity, lip synchronization, and robustness is stated without reference to specific metrics, baseline implementations, dataset sizes, or statistical tests. Because the only adaptation step is the LoRA trained on synthetic pairs, any unmeasured bias in the synthetic distribution directly limits the validity of the cross-method comparison.
minor comments (2)
- [Method] Specify the precise conditioning inputs to the LoRA (e.g., exact audio and visual feature channels) and the chosen LoRA rank and training hyperparameters.
- [Discussion] Add a short discussion of failure cases, such as extreme head motion or background audio interference, to clarify the robustness claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional validation of the synthetic training data and more rigorous reporting of experimental details are necessary to strengthen the claims. The revised manuscript will incorporate clarifications, new ablations, and expanded evaluation sections to address these points directly.
read point-by-point responses
-
Referee: [Method / Training data synthesis] Training-data synthesis (described in the abstract and method): the procedure generates all supervision from the same foundation model via language switches followed by face/audio inpainting. For the performance claims to hold, these pairs must supply clean, unbiased targets that improve phoneme-to-viseme mapping and motion continuity; no quantitative comparison against real multilingual ground-truth recordings or ablation isolating inpainting artifacts is reported, leaving open the possibility that the LoRA merely reproduces base-model failure modes.
Authors: We acknowledge the importance of verifying that the synthetic pairs provide unbiased supervision. The intra-clip language-switch strategy ensures that the two halves share identical speaker identity, pose, and background, with only language-specific audio and lip motion differing; the subsequent inpainting step then uses the base model's joint audio-visual prior to generate the target half. This construction is intended to avoid the domain gaps that arise when mixing real recordings from different sources. In the revision we will add (i) a quantitative assessment of the synthetic pairs against a small set of available real multilingual clips using lip-sync error (LSE) and face-identity cosine similarity, and (ii) an ablation that trains the LoRA on pairs generated with and without the inpainting stage, reporting the resulting differences in downstream dubbing metrics. revision: partial
-
Referee: [Results / Experiments] Evaluation (abstract and results): the claim of improved visual fidelity, lip synchronization, and robustness is stated without reference to specific metrics, baseline implementations, dataset sizes, or statistical tests. Because the only adaptation step is the LoRA trained on synthetic pairs, any unmeasured bias in the synthetic distribution directly limits the validity of the cross-method comparison.
Authors: We apologize for the insufficient detail in the original submission. The revised version will explicitly list all evaluation metrics (FID for visual quality, LSE for lip synchronization, and mean opinion scores from a user study for perceived robustness), provide implementation details and citations for every baseline, state the exact number of test videos and speakers used, and include statistical significance tests (paired t-tests with p-values) for all reported improvements. We will also add a short discussion of possible synthetic-data biases and how the joint diffusion prior helps mitigate them relative to cascaded pipelines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper adapts an external pre-trained audio-visual diffusion foundation model via lightweight LoRA fine-tuning. Training data consists of synthetic multilingual pairs generated by the same base model through language switches and inpainting, but the central performance claims (improved visual fidelity, lip synchronization, and robustness) are positioned as empirical outcomes measured against existing external dubbing pipelines rather than quantities defined by construction from the training pairs or any fitted parameters. No equations, self-citations, uniqueness theorems, or ansatzes appear in the abstract or description that reduce the claimed results to the inputs by definition; the method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank and training hyperparameters
axioms (1)
- domain assumption Audio-visual foundation models have strong priors for generating synchronized sound and visuals that transfer to dubbing tasks.
Reference graph
Works this paper leans on
-
[1]
Real-time eye blink detection using facial landmarks.Cent. Mach. Perception, Dep. Cybern. Fac. Electr. Eng. Czech Tech. Univ. Prague(2016), 1–8. Shunian Chen, Hejin Huang, Yexin Liu, Zihan Ye, Pengcheng Chen, Chenghao Zhu, Michael Guan, Rongsheng Wang, Junying Chen, Guanbin Li, Ser-Nam Lim, Harry Yang, and Benyou Wang. 2025a. TalkVid: A Large-Scale Divers...
-
[2]
AGrail: A Lifelong Agent Guardrail with Effective and Adaptive Safety Detection
T-foley: A controllable waveform- domain diffusion model for temporal-event-guided foley sound synthesis. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 6820–6824. Chaoqun Cui, Liangbin Huang, Shijing Wang, Zhe Tong, Zhaolong Huang, Xiao Zeng, and Xiaofeng Liu. 2025a. Fine-grained Video Dubbing ...
-
[3]
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens. arXiv:2407.05407 [cs.SD] https://arxiv.org/abs/2407.05407 Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, K...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. arXiv:2403.03206 [cs.CV] https://arxiv.org/abs/2403.03206 Jiazhi Guan, Zhanwang Zhang, Hang Zhou, Tianshu HU, Kaisiyuan Wang, Dongliang He, Haocheng Feng, Jingtuo Liu, Errui Ding, Ziwei Liu, and Jingdong Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LTX-2: Efficient Joint Audio- Visual Foundation Model. arXiv:2601.03233 [cs.CV] https://arxiv.org/abs/2601.03233 Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LTX-Video: Realtime Video Latent Diffusion
LTX-Video: Realtime Video Latent Diffusion.arXiv preprint arXiv:2501.00103(2024). Xu He, Haoxian Zhang, Hejia Chen, Changyuan Zheng, Liyang Chen, Songlin Tang, Jiehui Huang, Xiaoqiang Liu, Pengfei Wan, and Zhiyong Wu
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
From Inpaint- ing to Editing: A Self-Bootstrapping Framework for Context-Rich Visual Dubbing. arXiv:2512.25066 [cs.CV] https://arxiv.org/abs/2512.25066 Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter
-
[8]
HeyGen – AI Video Generator. https://www.heygen.com/. Accessed: 2026-01-07. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
work page 2026
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685 Lianghua Huang, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Huanzhang Dou, Chen Liang, Yutong Feng, Yu Liu, and Jingren Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
In-Context LoRA for Diffusion Transformers.arXiv preprint arxiv:2410.23775(2024). Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiang-Yang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, and Sheng Zhao
-
[11]
arXiv:2403.03100 [eess.AS] https://arxiv.org/abs/2403.03100 Black Forest Labs
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models. arXiv:2403.03100 [eess.AS] https://arxiv.org/abs/2403.03100 Black Forest Labs
-
[12]
LatentSync: Taming Audio-Conditioned Latent Diffusion Models for Lip Sync with SyncNet Supervision.arXiv preprint arXiv:2412.09262(2024). Lightricks. 2026.LTX-2: Official repository for LTX-2 audio-video foundation model. https://github.com/Lightricks/LTX-2 Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[13]
Flow Matching for Generative Modeling
Flow Matching for Generative Modeling. arXiv:2210.02747 [cs.LG] https: //arxiv.org/abs/2210.02747 Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models.arXiv preprint arXiv:2301.12503(2023). Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D. Plumbley
-
[15]
AudioLDM 2: Learning Holistic Audio Generation With Self-Supervised Pretraining.IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 2871–2883. doi:10.1109/TASLP. 2024.3399607 Xingchao Liu, Chengyue Gong, and Qiang Liu
-
[16]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. arXiv:2209.03003 [cs.LG] https: //arxiv.org/abs/2209.03003 Chetwin Low, Weimin Wang, and Calder Katyal
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
arXiv:2510.01284 William Peebles and Saining Xie
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation. arXiv:2510.01284 William Peebles and Saining Xie
-
[18]
Scalable Diffusion Models with Transformers
Scalable Diffusion Models with Transformers. arXiv preprint arXiv:2212.09748(2022). Ziqiao Peng, Jiwen Liu, Haoxian Zhang, Xiaoqiang Liu, Songlin Tang, Pengfei Wan, Di Zhang, Hongyan Liu, and Jun He
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar
OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers.arXiv preprint arXiv:2505.21448(2025). KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar
-
[20]
MM-Sonate: Multimodal Controllable Audio-Video Generation with Zero-Shot Voice Cloning. arXiv:2601.01568 [cs.SD] https://arxiv.org/abs/2601.01568 Zengyi Qin, Wenliang Zhao, Xumin Yu, and Xin Sun
-
[21]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever
OpenVoice: Versatile Instant Voice Cloning.arXiv preprint arXiv:2312.01479(2023). Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever
-
[22]
Robust Speech Recognition via Large-Scale Weak Supervision
Robust Speech Recognition via Large-Scale Weak Supervision. arXiv:2212.04356 [eess.AS] https://arxiv.org/abs/2212.04356 Jibin Song, Mingi Kwon, Jaeseok Jeong, and Youngjung Uh
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv:2509.21893 ByteDance Seed Team
Syncphony: Synchro- nized Audio-to-Video Generation with Diffusion Transformers. arXiv:2509.21893 ByteDance Seed Team
-
[24]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models.arXiv preprint arXiv:2503.20314(2025). Dogucan Yaman, Fevziye Irem Eyiokur, Leonard Barmann, Hazim Kemal Ekenel, and Alexander Waibel
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
In- finiteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing. 12•Anthony Chen, Naomi Ken Korem, Tavi Halperin, Matan Ben Yosef, Urska Jelercic, Ofir Bibi, Or Patashnik, and Daniel Cohen-Or arXiv:2508.14033 [cs.CV] https://arxiv.org/abs/2508.14033 Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu ...
-
[26]
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis. arXiv:2502.04128 [eess.AS] https://arxiv.org/abs/2502.04128 Guozhen Zhang, Zixiang Zhou, Teng Hu, Ziqiao Peng, Youliang Zhang, Yi Chen, Yuan Zhou, Qinglin Lu, and Limin Wang. 2025c. UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions. a...
-
[27]
La situation est devenue bien trop dangereuse pour que nous puissions rester ici
IndexTTS2: A Breakthrough in Emotionally Expressive and Duration- Controlled Auto-Regressive Zero-Shot Text-to-Speech. arXiv:2506.21619 [cs.CL] https://arxiv.org/abs/2506.21619 Supplementary Material A Implementation Details A.1 Training Data We use Gemini to generate 100 structured multilingual prompts spanning seven languages: English, Spanish, Russian,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.