Recognition: 2 theorem links
· Lean TheoremHow Does the Lagrangian Guide Safe Reinforcement Learning through Diffusion Models?
Pith reviewed 2026-05-16 07:52 UTC · model grok-4.3
The pith
Augmented Lagrangian stabilizes diffusion-based safe reinforcement learning by convexifying its energy landscape.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The instability of primal-dual methods in diffusion-based safe RL arises from the non-convex Lagrangian landscape, which serves as an energy function for the denoising dynamics. Introducing an augmented Lagrangian locally convexifies this energy landscape, stabilizing both policy generation and training without altering the distribution of the optimal policy.
What carries the argument
The augmented Lagrangian that locally convexifies the energy landscape guiding the diffusion denoising dynamics in safe RL.
If this is right
- Stabilized policy generation during diffusion sampling.
- Stabilized training process for the diffusion-based policy.
- Preservation of the distribution of the optimal policy.
- Improved empirical performance across diverse safe RL environments.
- Theoretical grounding via optimization theory and energy-based models.
Where Pith is reading between the lines
- The stabilization technique may transfer to other generative models that rely on energy-guided sampling under constraints.
- Real-world robotics tasks needing multimodal actions could gain from safer online adaptation without retraining from scratch.
- Varying the strength of the augmentation term might reveal trade-offs between stability and sample efficiency in high-dimensional problems.
Load-bearing premise
The augmented Lagrangian locally convexifies the energy landscape for diffusion denoising dynamics without introducing bias or altering the optimal policy distribution.
What would settle it
An experiment that applies the augmented Lagrangian and still records unstable sampling trajectories or a measurable shift away from the original optimal policy distribution.
Figures









read the original abstract
Diffusion policy sampling enables reinforcement learning (RL) to represent multimodal action distributions beyond suboptimal unimodal Gaussian policies. However, existing diffusion-based RL methods primarily focus on offline settings for reward maximization, with limited consideration of safety in online settings. To address this gap, we propose Augmented Lagrangian-Guided Diffusion (ALGD), a novel algorithm for off-policy safe RL. By revisiting optimization theory and energy-based model, we show that the instability of primal-dual methods arises from the non-convex Lagrangian landscape. In diffusion-based safe RL, the Lagrangian can be interpreted as an energy function guiding the denoising dynamics. Counterintuitively, direct usage destabilizes both policy generation and training. ALGD resolves this issue by introducing an augmented Lagrangian that locally convexifies the energy landscape, yielding a stabilized policy generation and training process without altering the distribution of the optimal policy. Theoretical analysis and extensive experiments demonstrate that ALGD is both theoretically grounded and empirically effective, achieving strong and stable performance across diverse environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Augmented Lagrangian-Guided Diffusion (ALGD) for off-policy safe reinforcement learning. It reinterprets the Lagrangian as an energy function guiding diffusion denoising dynamics, identifies instability in primal-dual methods as arising from non-convexity, and introduces an augmented Lagrangian that locally convexifies the landscape. The central claim is that this yields stabilized policy generation and training without altering the distribution of the optimal policy. Theoretical analysis and experiments are presented to support effectiveness across environments.
Significance. If the claim that finite augmentation preserves the exact optimal policy distribution while providing local convexity for the denoising SDE holds, the work would meaningfully advance safe RL by enabling stable online use of multimodal diffusion policies. It would bridge constrained optimization with energy-based diffusion guidance in a way that addresses a recognized instability source.
major comments (1)
- [Abstract] Abstract and theoretical analysis section: the assertion that the augmented Lagrangian stabilizes the process 'without altering the distribution of the optimal policy' is load-bearing for the central contribution. Standard augmented-Lagrangian theory establishes that L(x,λ,ρ)=f(x)+λᵀg(x)+(ρ/2)‖g(x)‖² shares stationary points with the original problem only in the limit ρ→∞; for any finite ρ the minimizer generally shifts. The manuscript must provide an explicit derivation or proof showing that the argmin of the finite-ρ energy function driving the diffusion denoising SDE remains identical to that of the unaugmented Lagrangian, or state the precise conditions under which this invariance holds.
minor comments (1)
- [Abstract] The abstract refers to 'theoretical analysis' and 'extensive experiments' without indicating the specific environments, metrics, or baseline comparisons; the main text should make these details immediately visible in the introduction or results overview.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comment on the invariance claim. The point is well-taken and we address it directly below with a clarification of stationary points versus global minimizers, an explicit derivation under our assumptions, and a commitment to expand the theoretical section.
read point-by-point responses
-
Referee: [Abstract] Abstract and theoretical analysis section: the assertion that the augmented Lagrangian stabilizes the process 'without altering the distribution of the optimal policy' is load-bearing for the central contribution. Standard augmented-Lagrangian theory establishes that L(x,λ,ρ)=f(x)+λᵀg(x)+(ρ/2)‖g(x)‖² shares stationary points with the original problem only in the limit ρ→∞; for any finite ρ the minimizer generally shifts. The manuscript must provide an explicit derivation or proof showing that the argmin of the finite-ρ energy function driving the diffusion denoising SDE remains identical to that of the unaugmented Lagrangian, or state the precise conditions under which this invariance holds.
Authors: We agree that a rigorous justification is required and thank the referee for identifying this gap. First, we note that stationary points are in fact shared for any finite ρ (not only in the limit): at any feasible point where g(x)=0 and ∇f + λᵀ∇g = 0, the extra term ρ g ∇g vanishes, so ∇L_aug = ∇L_original. The referee's statement on stationary points therefore does not hold in general. For the global argmin, we provide the following derivation in the revised manuscript. Let E(π) = L(π,λ) be the original Lagrangian energy and E_aug(π) = L(π,λ) + (ρ/2)‖g(π)‖² the augmented energy. Let π* be the unique global minimizer of the original constrained problem, so g(π*)=0 and E(π*) ≤ E(π) for all π. For any infeasible π with g(π)≠0, E_aug(π) = E(π) + (ρ/2)‖g(π)‖² > E(π) ≥ E(π*). Hence E_aug(π*) < E_aug(π) for all π≠π*, establishing that π* remains the unique global minimizer of E_aug for any ρ>0. The diffusion denoising SDE is driven by the gradient of this energy; because the mode is unchanged, the sampled policy distribution at convergence is identical. We will insert this derivation (with the uniqueness assumption stated explicitly) into the theoretical analysis section and update the abstract to reference the precise condition (unique feasible optimum). revision: yes
Circularity Check
Derivation chain is self-contained; no reductions to inputs by construction
full rationale
The paper derives the ALGD method by interpreting the Lagrangian as an energy function for diffusion denoising and then introducing an augmented Lagrangian to locally convexify the landscape. This step is presented as following from standard optimization theory and energy-based models rather than from any self-definition, fitted parameter renamed as prediction, or self-citation chain. The claim that the augmentation leaves the optimal policy distribution unchanged is asserted as a theoretical consequence without reducing to a tautology or data-tuned fit inside the paper; the augmentation parameter is introduced as part of the algorithm definition. No load-bearing step collapses to its own inputs, and the central result remains independent of the present paper's fitted values or prior self-citations.
Axiom & Free-Parameter Ledger
free parameters (1)
- augmentation parameter
axioms (2)
- domain assumption Lagrangian can be interpreted as an energy function guiding denoising dynamics in diffusion models
- domain assumption Instability of primal-dual methods arises from non-convex Lagrangian landscape
invented entities (1)
-
Augmented Lagrangian for diffusion guidance
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ALGD resolves this issue by introducing an augmented Lagrangian that locally convexifies the energy landscape, yielding a stabilized policy generation and training process without altering the distribution of the optimal policy. ... LA(s, a, λ) := -Qπ(s, a) + ([λ + ρ(Qπc(s, a) - h)]²+ - λ²)/(2ρ)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
∇²a LA(s, a, λ) = ∇²a L(s, a, λ) + ρ ∇a Qπc ∇a Qπc^T + O(|Qπc - h|)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J., Mittal, S., Lemos, P., Liu, C.-H., Sendera, M., Ravanbakhsh, S., Gidel, G., Bengio, Y ., et al
Akhound-Sadegh, T., Rector-Brooks, J., Bose, A. J., Mittal, S., Lemos, P., Liu, C.-H., Sendera, M., Ravanbakhsh, S., Gidel, G., Bengio, Y ., et al. Iterated denoising energy matching for sampling from boltzmann densities.arXiv preprint arXiv:2402.06121,
-
[2]
Chen, H., Ren, Y ., Min, M. R., Ying, L., and Izzo, Z. Solving inverse problems via diffusion-based priors: An approximation-free ensemble sampling approach.arXiv preprint arXiv:2506.03979,
-
[3]
Safe and stable control via lyapunov-guided diffusion models.arXiv preprint arXiv:2509.25375,
Cheng, X., Tang, X., and Yang, Y . Safe and stable control via lyapunov-guided diffusion models.arXiv preprint arXiv:2509.25375,
-
[4]
Choi, J. J., Strong, C. A., Sreenath, K., Cho, N., and Tom- lin, C. J. Data-driven hamiltonian for direct construc- tion of safe set from trajectory data.arXiv preprint arXiv:2504.03233,
- [5]
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Planning with Diffusion for Flexible Behavior Synthesis
Janner, M., Du, Y ., Tenenbaum, J. B., and Levine, S. Plan- ning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Model-based constrained reinforcement learning using generalized control barrier function
Ma, H., Chen, J., Eben, S., Lin, Z., Guan, Y ., Ren, Y ., and Zheng, S. Model-based constrained reinforcement learning using generalized control barrier function. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 4552–4559. IEEE,
work page 2021
-
[9]
Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361,
Ma, H., Chen, T., Wang, K., Li, N., and Dai, B. Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361,
-
[10]
Flow q-learning.arXiv preprint arXiv:2502.02538,
Park, S., Li, Q., and Levine, S. Flow q-learning.arXiv preprint arXiv:2502.02538,
- [11]
-
[12]
Qin, Z., Sun, D., and Fan, C. Sablas: Learning safe control for black-box dynamical systems.IEEE Robotics and Automation Letters, 7(2):1928–1935,
work page 1928
-
[13]
Diffusion Policy Policy Optimization
Ren, A. Z., Lidard, J., Ankile, L. L., Simeonov, A., Agrawal, P., Majumdar, A., Burchfiel, B., Dai, H., and Simchowitz, M. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588,
work page internal anchor Pith review arXiv
-
[14]
Rigollet, P. and H¨utter, J.-C. High-dimensional statistics. arXiv preprint arXiv:2310.19244,
-
[15]
So, O. and Fan, C. Solving stabilize-avoid optimal control via epigraph form and deep reinforcement learning.arXiv preprint arXiv:2305.14154,
-
[16]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[17]
Tassa, Y ., Doron, Y ., Muldal, A., Erez, T., Li, Y ., Casas, D. d. L., Budden, D., Abdolmaleki, A., Merel, J., Lefrancq, A., et al. Deepmind control suite.arXiv preprint arXiv:1801.00690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Reward Constrained Policy Optimization
Tessler, C., Mankowitz, D. J., and Mannor, S. Re- ward constrained policy optimization.arXiv preprint arXiv:1805.11074,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Thrun, S. and Schwartz, A. Issues in using function approx- imation for reinforcement learning. InProceedings of the 1993 connectionist models summer school, pp. 255–263. Psychology Press,
work page 1993
-
[20]
Uehara, M., Zhao, Y ., Biancalani, T., and Levine, S. Un- derstanding reinforcement learning-based fine-tuning of diffusion models: A tutorial and review.arXiv preprint arXiv:2407.13734,
-
[21]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Wang, Z., Hunt, J. J., and Zhou, M. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Off-policy primal-dual safe reinforcement learning.arXiv preprint arXiv:2401.14758,
Wu, Z., Tang, B., Lin, Q., Yu, C., Mao, S., Xie, Q., Wang, X., and Wang, D. Off-policy primal-dual safe reinforcement learning.arXiv preprint arXiv:2401.14758,
-
[23]
Constrained diffusers for safe planning and control
Zhang, J., Zhao, L., Papachristodoulou, A., and Umenberger, J. Constrained diffusers for safe planning and control. arXiv preprint arXiv:2506.12544, 2025a. Zhang, S. and Fan, C. Learning to stabilize high- dimensional unknown systems using lyapunov-guided exploration. In6th Annual Learning for Dynamics & Control Conference, pp. 52–67. PMLR,
-
[24]
Zhang, S., So, O., Black, M., and Fan, C. Discrete gcbf proximal policy optimization for multi-agent safe optimal control.arXiv preprint arXiv:2502.03640, 2025b. Zhang, S., So, O., Black, M., Serlin, Z., and Fan, C. Solving multi-agent safe optimal control with distributed epigraph form marl.arXiv preprint arXiv:2504.15425, 2025c. Zhang, Y ., Vuong, Q., a...
-
[25]
Zheng, Y ., Li, J., Yu, D., Yang, Y ., Li, S. E., Zhan, X., and Liu, J. Safe offline reinforcement learning with feasibility-guided diffusion model.arXiv preprint arXiv:2401.10700,
-
[26]
11 Augmented Lagrangian-Guided Diffusion Notation Notations Meaning aaction a0|τ the posterior distributionp(a 0|aτ , s) csafety cost d0 initial distribution of state hsafety threshold rreward function sstate ttime step Aaction set Bτ standard Brownian motions Breplay buffer DKL KL divergence of two distributions LLagrangian LA augmented Lagrangian NGauss...
work page 2019
-
[27]
However, these approaches are largely restricted to the offline setting
have revealed fundamental connections between diffusion-based generative modeling and diffusion policies (Janner et al., 2022; Wang et al., 2022; Ren et al., 2024; Chi et al., 2025). However, these approaches are largely restricted to the offline setting. More recently, researchers have begun to explore diffusion policies in online RL settings, enabling c...
work page 2022
-
[28]
treats the reverse diffusion process as a direct policy function and employs a Gaussian-mixture entropy regulator to adaptively balance exploration and exploitation. Despite recent progress, most existing diffusion-based approaches remain confined to the offline reinforcement learning setting. Recent studies have further explored safe offline policy gener...
work page 2023
-
[29]
Then, we have logπ ∗(a|s)∝ − L(s, a, λ) +η β , which yields the Boltzmann-form solution π∗(a|s) = exp − L(s,a,λ) β Z(s) , Z(s) = Z a exp − L(s, a, λ) β da, (18) indicating that the optimal policy follows a Boltzmann distribution, where fluctuations in the Lagrange multiplier λ directly reshape the policy landscape. In the following proposition, we present...
work page 2023
-
[30]
Proof of Proposition 3.1.According to the definition of the VE SDE (Chen et al., 2025), the intermediate distribution πτ(aτ |s)is generated as πτ(aτ |s) = Z π0(a0|s)N aτ;a 0, σ2(τ)I da0 = π0(a0|s)∗ N(0, σ 2(τ)I) (aτ), which follows directly from the forward diffusion as a Gaussian smoothing ofπ 0(a|s). 16 Augmented Lagrangian-Guided Diffusion Differentiat...
work page 2025
-
[31]
Z K 0 q dσ2(τ) dτ −1 × dσ2(τ) dτ ˜ϕA(s, aτ , τ)−ϕ ∗(s, aτ , τ) 2 dτ # = 1 2 Eπ0(a0|s)
= 1 2 Ep2 "Z T 0 ∥σ−1(b2(xτ)−b 1(xτ))∥2 dτ # , which establishes the result. Proof.Returning to our setting, we adopt asame-path constructionfor the reverse-time diffusion process. Specifically, we consider a single stochastic trajectory aτ ∈C([0, K];R d) defined on a common filtered probability space and driven by the same Brownian motion Bτ . Different ...
work page 2017
-
[32]
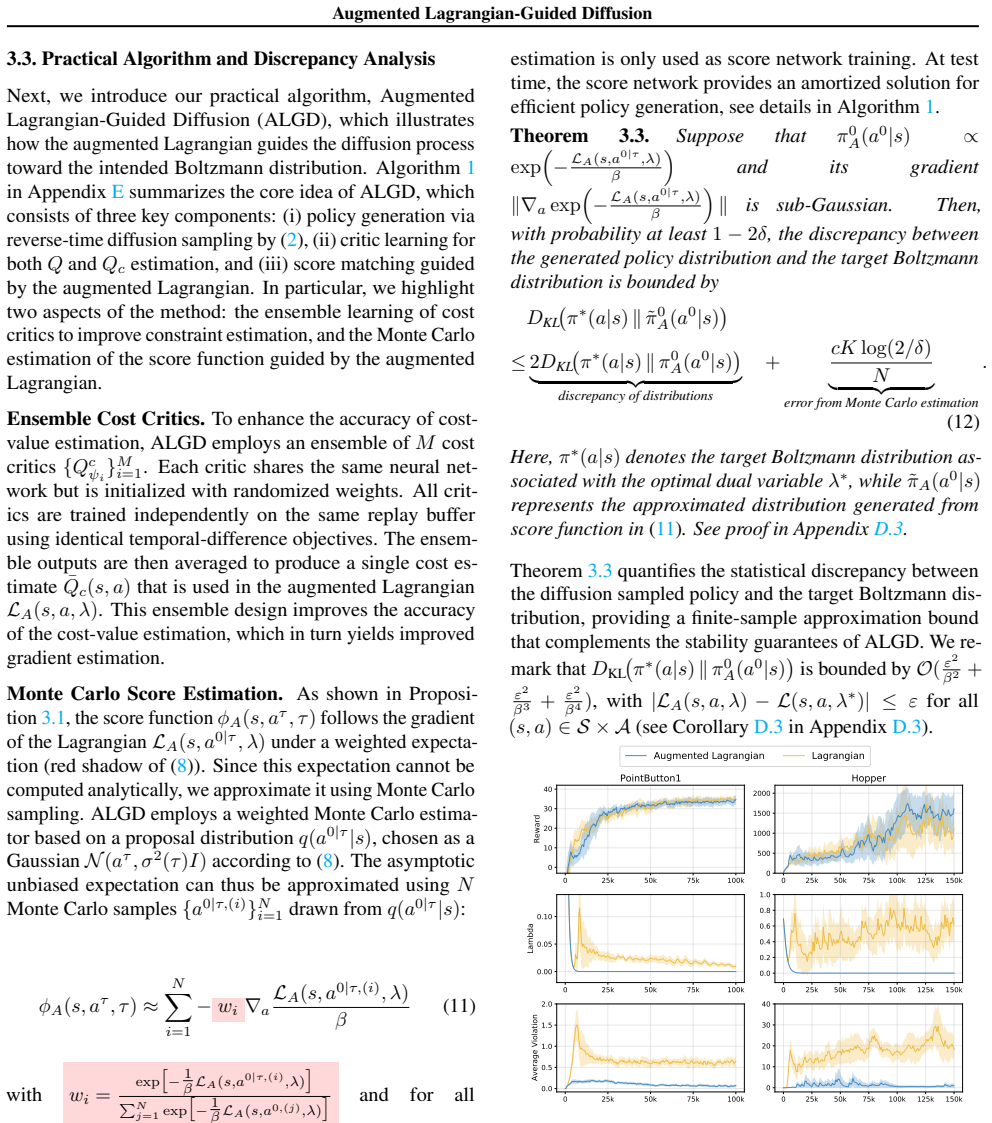
Notably, our algorithm already exhibits stable learning and safe policy behavior even without the ensemble ( M= 1 ); increasing the ensemble size does not alter the underlying energy landscape, but instead strengthens the approach by allowing ¯Qc to provide a more accurate estimate of∇aLA(s, a, λ), thereby improving gradient quality and overall algorithm ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.