Recognition: no theorem link
SynthForensics: Benchmarking and Evaluating People-Centric Synthetic Video Deepfakes
Pith reviewed 2026-05-16 07:29 UTC · model grok-4.3
The pith
A new benchmark of 20,445 synthetic people videos reveals deepfake detectors lose 27 AUC points on average from legacy sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
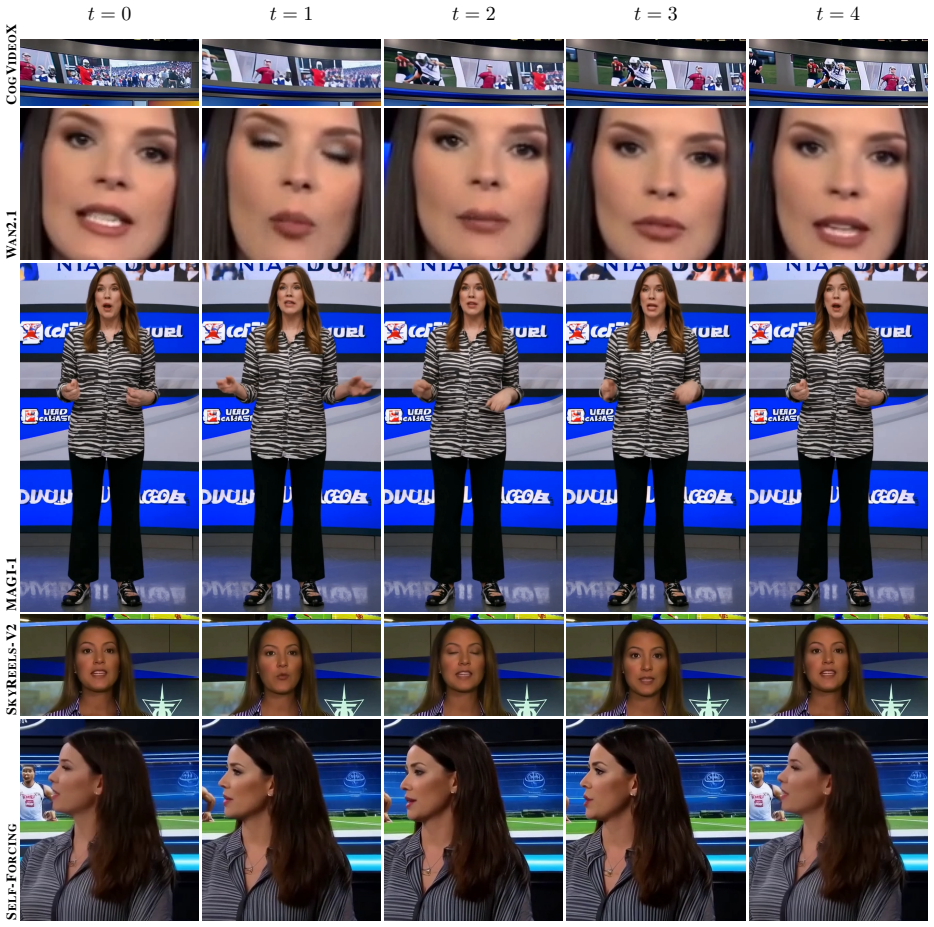
SynthForensics supplies 20,445 videos from eight text-to-video and seven image-to-video open-source generators, each paired with matching real clips from FF++ and DFD, produced through two-stage human validation and delivered in four compression settings with complete metadata. Evaluation on fifteen detectors across three protocols shows face-based methods lose 13 to 55 AUC points, averaging 27, moving from FF++ to SynthForensics, with an additional average drop of 23 points under aggressive compression. Fine-tuning on the new benchmark narrows the gap yet reduces accuracy on legacy sets, while training from scratch indicates that synthetic-generation cues and manipulation cues remain mostly
What carries the argument
The SynthForensics benchmark itself, consisting of paired real-synthetic videos from fifteen specified T2V and I2V generators, two-stage human validation, and four compression variants.
If this is right
- Face-based detectors exhibit AUC drops of 13-55 points (mean 27) when moving from FF++ to SynthForensics.
- Aggressive compression adds a further average 23-point AUC decline on the new videos.
- Fine-tuning on SynthForensics raises performance on synthetic content but lowers it on legacy manipulation benchmarks.
- Training from scratch on synthetic data shows detection features for generation artifacts are largely disjoint from manipulation features.
- The benchmark supplies a harder, more current test set for assessing detector robustness to realistic people synthesis.
Where Pith is reading between the lines
- Separate training regimes or hybrid models may be needed to cover both generative synthesis and traditional editing artifacts at once.
- Real-world systems for video verification could integrate this benchmark to stay effective against improving generative models.
- The paired-source and validation approach can be reused in other media types to track how new generators evade detectors.
- Benchmark metadata could help generative-model developers create targeted examples that expose current detector weaknesses.
Load-bearing premise
The eight text-to-video and seven image-to-video generators plus the two-stage human validation produce videos that stand in for realistic synthetic people content today and in the near future.
What would settle it
Testing the fifteen detectors on SynthForensics and measuring whether AUC falls by 13-55 points from their FF++ scores, or stays flat, directly checks the reported generalization failure.
Figures









read the original abstract
Modern T2V/I2V generators synthesize people increasingly hard to distinguish from authentic footage, while current evaluation suites lag: legacy benchmarks target manipulation-based forgeries, and recent synthetic-video benchmarks prioritize scale over realistic human depiction. We introduce SynthForensics, a people-centric benchmark of $20{,}445$ videos from 8 T2V and 7 I2V open-source generators, paired-source from FF++/DFD reals, two-stage human-validated, in four compression versions with full metadata. In our paired-comparison human study, raters prefer SynthForensics in $71$--$77\%$ of head-to-head comparisons against each of nine existing synthetic-video benchmarks, while facial-quality metrics fall within the FF++/DFD baseline range. Across 15 detectors and three protocols, face-based methods drop $13$--$55$ AUC points (mean $27$) from FF++ to SynthForensics and a further $23$ under aggressive compression; fine-tuning closes the gap at a backward cost on legacy benchmarks; training from scratch shows synthetic and manipulation features largely disjoint for most detectors. We release dataset, pipeline, and code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SynthForensics, a people-centric benchmark of 20,445 videos generated from 8 T2V and 7 I2V open-source models, paired with real footage from FF++ and DFD. It includes two-stage human validation, four compression levels, and full metadata. Human raters prefer the new videos over nine prior synthetic benchmarks in 71-77% of comparisons. Across 15 detectors and three protocols, face-based detectors show AUC drops of 13-55 points (mean 27) from FF++ to SynthForensics, with an additional 23-point drop under aggressive compression; fine-tuning recovers performance on the new data at the cost of legacy benchmarks, while training from scratch indicates largely disjoint features between synthetic and manipulation detection.
Significance. If the benchmark videos are representative of realistic synthetic people content, the results demonstrate a clear generalization failure in existing detectors and support the claim that synthetic-video and manipulation features are largely disjoint for most models. The public release of the dataset, pipeline, and code is a clear strength that enables future work. The empirical scale (15 detectors, multiple protocols, compression variants) provides concrete evidence of the performance gap, though the magnitude of the reported drops depends on the chosen generators being broadly representative.
major comments (2)
- [Dataset construction] Dataset construction section: the selection of the specific 8 T2V and 7 I2V open-source generators is presented without detailed justification, ablation studies, or comparison to proprietary models. Because the headline AUC drops (13-55 points, mean 27) and the disjoint-features conclusion are only meaningful if these videos lie on the same distribution as current and near-future realistic synthetic people content, the lack of evidence that the observed artifacts are not generator-specific undermines the central generalization claim.
- [Evaluation protocols and results] Evaluation protocols and results sections: the two-stage human validation is described at a high level but lacks exact selection criteria, inter-rater agreement statistics, and full methodology details. In addition, the AUC results are reported without error bars or confidence intervals, so the mean drop of 27 points and the further 23-point compression drop cannot be assessed for statistical reliability.
minor comments (3)
- [Abstract] Abstract: the reported human preference rates (71-77%) and AUC ranges would benefit from explicit error bars or sample sizes to allow readers to gauge precision.
- [Evaluation protocols] The paper should clarify the exact definition of the three evaluation protocols (e.g., train/test splits, whether cross-generator or cross-compression) in a dedicated subsection or table.
- [Experiments] Figure captions and tables listing the 15 detectors should include the precise model names and any fine-tuning hyperparameters to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address each of the major comments below and plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: the selection of the specific 8 T2V and 7 I2V open-source generators is presented without detailed justification, ablation studies, or comparison to proprietary models. Because the headline AUC drops (13-55 points, mean 27) and the disjoint-features conclusion are only meaningful if these videos lie on the same distribution as current and near-future realistic synthetic people content, the lack of evidence that the observed artifacts are not generator-specific undermines the central generalization claim.
Authors: We selected the 8 T2V and 7 I2V models because they represent leading publicly available generators at the time of dataset creation, chosen for their high adoption in the research community, strong performance on established video quality benchmarks such as VBench, and demonstrated capability for realistic human synthesis. In the revision we will add an explicit selection-criteria subsection that lists model popularity metrics (GitHub stars, citations), qualitative human-preference rankings, and references to prior works that used the same models. We will also include an ablation that recomputes the key AUC drops on random subsets of the generators to demonstrate that the observed gaps are consistent rather than driven by any single model. Regarding proprietary models, our benchmark deliberately targets open-source generators to guarantee full reproducibility and accessibility; closed-source systems are not generally available for large-scale dataset construction by academic researchers. We will add a limitations paragraph acknowledging this scope and noting that the rapid convergence of open and closed model quality makes the reported generalization failure relevant to near-future realistic content. revision: yes
-
Referee: [Evaluation protocols and results] Evaluation protocols and results sections: the two-stage human validation is described at a high level but lacks exact selection criteria, inter-rater agreement statistics, and full methodology details. In addition, the AUC results are reported without error bars or confidence intervals, so the mean drop of 27 points and the further 23-point compression drop cannot be assessed for statistical reliability.
Authors: We will expand the human-validation section with the precise protocol: first-stage filtering required unanimous rejection of obvious artifacts by three raters; second-stage selection retained only clips that received at least three-out-of-five positive votes from a new rater pool. We will report inter-rater agreement using Fleiss’ kappa (target value >0.6) together with the exact rater instructions, compensation, and demographic summary. For all AUC figures we will recompute results with bootstrap resampling (1,000 iterations) over the test videos and add 95 % confidence intervals to every reported drop, including the mean 27-point and 23-point compression drops. These additions will allow direct statistical assessment of the reliability of the performance gaps. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation
full rationale
The paper creates a new dataset (SynthForensics) from open-source T2V/I2V generators, performs human validation, and reports empirical AUC drops for 15 detectors across protocols compared to FF++ and DFD. No equations, derivations, predictions, or first-principles results are claimed. All performance numbers are direct measurements on held-out data; no parameters are fitted and then renamed as predictions. No self-citations are load-bearing for the central claims, and the representativeness of the chosen generators is an explicit modeling choice rather than a derived result. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human raters provide reliable preference judgments in paired comparisons of synthetic versus real videos
Reference graph
Works this paper leans on
-
[1]
MAGI-1: Autoregressive Video Generation at Scale
Sand. ai, Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, et al. MAGI-1: Autoregressive Video Genera- tion at Scale. arXiv preprint arXiv:2505.13211, 2025. 3, 4, 6, 8, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Advance Fake Video Detection via Vision Transformers
Joy Battocchio, Stefano Dell’Anna, Andrea Montibeller, and Giulia Boato. Advance Fake Video Detection via Vision Transformers. In Proceedings of the 2025 ACM Workshop on Information Hiding and Multimedia Security, page 1–11, New York, NY , USA, 2025. Association for Computing Ma- chinery. 3
work page 2025
-
[3]
Human Action CLIPs: Detecting AI-generated Human Motion
Matyas Bohacek and Hany Farid. Human Action CLIPs: Detecting AI-generated Human Motion. arXiv preprint arXiv:2412.00526, 2025. 3
-
[4]
A V-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Zhixi Cai, Kartik Kuckreja, Shreya Ghosh, Akanksha Chuchra, Muhammad Haris Khan, Usman Tariq, et al. A V-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations. In Proceedings of the 33rd ACM International Conference on Multimedia , page 13686–13691, New York, NY , USA, 2025. Association for Computing Machinery. 3
work page 2025
-
[5]
End-to-End Reconstruction- Classification Learning for Face Forgery Detection
Junyi Cao, Chao Ma, Taiping Yao, Shen Chen, Shouhong Ding, and Xiaokang Yang. End-to-End Reconstruction- Classification Learning for Face Forgery Detection. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4113–4122, 2022. 3, 5, 7, 8, 11
work page 2022
-
[6]
Mirko Casu, Luca Guarnera, Pasquale Caponnetto, and Se- bastiano Battiato. GenAI mirage: The impostor bias and the deepfake detection challenge in the era of artificial illu- sions. Forensic Science International: Digital Investigation, 50:301795, 2024. 2
work page 2024
-
[7]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, et al. SkyReels-V2: Infinite-length Film Generative Model. arXiv preprint arXiv:2504.13074, 2025. 3, 4, 6, 8, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Trusted Media Challenge Dataset and User Study
Weiling Chen, Sheng Lun Benjamin Chua, Stefan Winkler, and See-Kiong Ng. Trusted Media Challenge Dataset and User Study. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, page 3873–3877, New York, NY , USA, 2022. Association for Computing Machinery. 3, 7
work page 2022
-
[9]
X2-dfd: A framework for ex- plainable and extendable deepfake detection
Yize Chen, Zhiyuan Yan, Guangliang Cheng, Kangran Zhao, Siwei Lyu, and Baoyuan Wu. X2-dfd: A framework for ex- plainable and extendable deepfake detection. arXiv preprint arXiv:2410.06126, 2024. 7
-
[10]
Jikang Cheng, Zhiyuan Yan, Ying Zhang, Yuhao Luo, Zhongyuan Wang, and Chen Li. Can We Leave Deepfake Data Behind in Training Deepfake Detector? In Advances in Neural Information Processing Systems , pages 21979– 21998. Curran Associates, Inc., 2024. 3, 5, 7, 8, 11
work page 2024
-
[11]
GenConViT: Deepfake Video Detection Using Generative Convolutional Vision Transformer
Deressa Wodajo Deressa, Hannes Mareen, Peter Lambert, Solomon Atnafu, Zahid Akhtar, and Glenn Van Wallendael. GenConViT: Deepfake Video Detection Using Generative Convolutional Vision Transformer. Applied Sciences , 15 (12), 2025. 3, 5, 7, 8, 11
work page 2025
-
[12]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, et al. The DeepFake Detection Chal- lenge (DFDC) Dataset. arXiv preprint arXiv:2006.07397 ,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Contributing Data to Deepfake Detection Research
Nick Dufour and Andrew Gully. Contributing Data to Deepfake Detection Research. https : / / ai . googleblog . com / 2019 / 09 / contributing - data - to - deepfake - detection . html , 2019. Accessed: 2025-11-05. 3, 6, 7, 8
work page 2019
-
[15]
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Nets. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2014. 2
work page 2014
-
[16]
New Veo Updates and More AI Progress in Video and Audio
Google. New Veo Updates and More AI Progress in Video and Audio. https://blog.google/technology/ ai/veo-updates-flow/ , 2024. Accessed: 2025-11-
work page 2024
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, et al. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Luca Guarnera, Oliver Giudice, and Sebastiano Battiato. Level up the deepfake detection: a method to effectively dis- criminate images generated by gan architectures and diffu- sion models. In Intelligent Systems Conference, pages 615–
-
[19]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, et al. LTX- Video: Realtime Video Latent Diffusion. arXiv preprint arXiv:2501.00103, 2024. 2, 4, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Yue-Hua Han, Tai-Ming Huang, Kai-Lung Hua, and Jun- Cheng Chen. Towards More General Video-based Deepfake Detection through Facial Component Guided Adaptation for Foundation Model. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 22995–23005, 2025. 3, 5, 7, 8, 11
work page 2025
-
[21]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-Free Diffusion Guidance. arXiv preprint arXiv:2207.12598, 2022. 4 9
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Denoising Dif- fusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Dif- fusion Probabilistic Models. In Advances in Neural Infor- mation Processing Systems, pages 6840–6851. Curran Asso- ciates, Inc., 2020. 2, 4
work page 2020
-
[23]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self Forcing: Bridging the Train- Test Gap in Autoregressive Video Diffusion. arXiv preprint arXiv:2506.08009, 2025. 3, 4, 6, 8, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Self-Forcing: Official Implementa- tion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self-Forcing: Official Implementa- tion. https://github.com/guandeh17/Self- Forcing, 2025. Accessed: 2025-11-09. 2, 3, 5
work page 2025
-
[25]
VBench: Comprehensive Bench- mark Suite for Video Generative Models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, et al. VBench: Comprehensive Bench- mark Suite for Video Generative Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 5, 9
work page 2024
-
[26]
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, and Chen Change Loy. DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020. 3
work page 2020
-
[27]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems, 35:26565–26577, 2022. 4
work page 2022
-
[28]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, et al. HunyuanVideo: A Systematic Frame- work For Large Video Generative Models. arXiv preprint arXiv:2412.03603, 2025. 2, 4, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
DeepFakes: a New Threat to Face Recognition? Assessment and Detection
Pavel Korshunov and Sebastien Marcel. DeepFakes: a New Threat to Face Recognition? Assessment and Detection. arXiv preprint arXiv:1812.08685, 2018. 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Kuaishou Technology. Kling. https://klingai.com/ global/, 2024. Accessed: 2025-11-05. 2, 4
work page 2024
-
[31]
Rohit Kundu, Hao Xiong, Vishal Mohanty, Athula Balachan- dran, and Amit K. Roy-Chowdhury. Towards a Universal Synthetic Video Detector: From Face or Background Ma- nipulations to Fully AI-Generated Content. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 28050–28060, 2025. 2
work page 2025
-
[32]
Celeb-DF: A Large-Scale Challenging Dataset for DeepFake Forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-DF: A Large-Scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020. 2, 3, 6, 7
work page 2020
-
[33]
Celeb-DF++: A Large-scale Challenging Video DeepFake Benchmark for Generalizable Forensics
Yuezun Li, Delong Zhu, Xinjie Cui, and Siwei Lyu. Celeb-DF++: A Large-scale Challenging Video DeepFake Benchmark for Generalizable Forensics. arXiv preprint arXiv:2507.18015, 2025. 3
-
[34]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. arXiv preprint arXiv:2210.02747, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Flow matching for generative mod- eling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. In 11th International Conference on Learning Repre- sentations, ICLR 2023, 2023. 2
work page 2023
-
[36]
Videodpo: Omni- preference alignment for video diffusion generation
Runtao Liu, Haoyu Wu, Ziqiang Zheng, Chen Wei, Yingqing He, Renjie Pi, and Qifeng Chen. Videodpo: Omni- preference alignment for video diffusion generation. In Pro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 8009–8019, 2025. 2
work page 2025
-
[37]
Anwei Luo, Chenqi Kong, Jiwu Huang, Yongjian Hu, Xi- angui Kang, and Alex C. Kot. Beyond the Prior Forgery Knowledge: Mining Critical Clues for General Face Forgery Detection. IEEE Transactions on Information Forensics and Security, 19:1168–1182, 2024. 3, 5, 7, 11
work page 2024
-
[38]
Step-Video-T2V Technical Re- port: The Practice, Challenges, and Future of Video Founda- tion Model
Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, et al. Step-Video-T2V Technical Re- port: The Practice, Challenges, and Future of Video Founda- tion Model. arXiv preprint arXiv:2502.10248 , 2025. 2, 4, 3
-
[39]
GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video
Zhenliang Ni, Qiangyu Yan, Mouxiao Huang, Tianning Yuan, Yehui Tang, Hailin Hu, et al. GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video. arXiv preprint arXiv:2501.11340, 2025. 3
-
[40]
OpenAI. Sora 2. https://openai.com/index/ sora-2/, 2024. Accessed: 2025-11-05. 2, 4
work page 2024
-
[41]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable Diffusion Models with Transformers. In Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4195–4205,
-
[42]
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Xiangyu Peng, Zangwei Zheng, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, et al. Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k.arXiv preprint arXiv:2503.09642, 2025. 2, 4, 3
work page internal anchor Pith review arXiv 2025
-
[43]
Andre Rochow, Max Schwarz, and Sven Behnke. FSRT: Facial Scene Representation Transformer for Face Reenact- ment from Factorized Appearance Head-pose and Facial Ex- pression Features. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 7716–7726, 2024. 2
work page 2024
-
[44]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. In International Conference on Medical image com- puting and computer-assisted intervention , pages 234–241. Springer, 2015. 2
work page 2015
-
[45]
FaceForen- sics++: Learning to Detect Manipulated Facial Images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Chris- tian Riess, Justus Thies, and Matthias Niessner. FaceForen- sics++: Learning to Detect Manipulated Facial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019. 2, 3, 6, 7, 8
work page 2019
-
[46]
BlendFace: Re-designing Identity Encoders for Face- Swapping
Kaede Shiohara, Xingchao Yang, and Takafumi Take- tomi. BlendFace: Re-designing Identity Encoders for Face- Swapping. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7634–7644, 2023. 2
work page 2023
-
[47]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020. 4
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[48]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017. 2
work page 2017
-
[49]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, et al. Wan: Open and Advanced Large-Scale 10 Video Generative Models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
AltFreezing for More Gen- eral Video Face Forgery Detection
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, and Houqiang Li. AltFreezing for More Gen- eral Video Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4129–4138, 2023. 3, 5, 7, 8, 11
work page 2023
-
[51]
UCF: Uncovering Common Features for Generalizable Deepfake Detection
Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. UCF: Uncovering Common Features for Generalizable Deepfake Detection. In Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision , pages 22412– 22423, 2023. 3, 5, 7, 8, 11
work page 2023
-
[52]
DeepfakeBench: A Comprehensive Bench- mark of Deepfake Detection
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. DeepfakeBench: A Comprehensive Bench- mark of Deepfake Detection. In Advances in Neural Infor- mation Processing Systems, pages 4534–4565. Curran Asso- ciates, Inc., 2023. 5
work page 2023
-
[53]
Orthogonal Subspace De- composition for Generalizable AI-Generated Image Detec- tion
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, et al. Orthogonal Subspace De- composition for Generalizable AI-Generated Image Detec- tion. In Forty-second International Conference on Machine Learning, 2025. 3, 5, 7, 8, 11
work page 2025
-
[54]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, et al. CogVideoX: Text-to-Video Dif- fusion Models with An Expert Transformer. arXiv preprint arXiv:2408.06072, 2025. 2, 4, 6, 8, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Free- man, Fredo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Free- man, Fredo Durand, Eli Shechtman, and Xun Huang. From Slow Bidirectional to Fast Autoregressive Video Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 22963– 22974, 2025. 2, 4, 3
work page 2025
-
[56]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, et al. VideoLLaMA 3: Fron- tier Multimodal Foundation Models for Image and Video Understanding. arXiv preprint arXiv:2501.13106, 2025. 4, 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, et al. SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 8652–8661, 2023. 2
work page 2023
-
[58]
Exploring Temporal Coherence for More Gen- eral Video Face Forgery Detection
Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. Exploring Temporal Coherence for More Gen- eral Video Face Forgery Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 15044–15054, 2021. 3, 5, 7, 8, 11
work page 2021
-
[59]
WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection
Bojia Zi, Minghao Chang, Jingjing Chen, Xingjun Ma, and Yu-Gang Jiang. WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection. In Proceedings of the 28th ACM International Conference on Multimedia , page 2382–2390, New York, NY , USA, 2020. Association for Computing Machinery. 3, 7 11 SynthForensics: A Multi-Generator Benchmark for Detectin...
work page 2020
-
[60]
Technical Appendices Overview This document presents the technical implementation de- tails and granular experimental analysis supporting the Syn- thForensics benchmark. The document is organized as fol- lows: • Section 8 details the structured prompt generation and adaptation process, including the exact system instruc- tions used for semantic alignment ...
-
[61]
The SynthForensics Benchmark: Extended Details This section presents the technical specifications and pro- tocols governing the construction of the SynthForensics benchmark. We first detail the structured prompt genera- tion pipeline, including the system instructions for semantic alignment and the negative prompt optimization strategies. Subsequently, we...
-
[62]
Prompt Rewriting: For failures in Semantic Coherence or Ethical Compliance, the textual prompt was manually rewritten to reduce ambiguity or enforce stricter safety constraints
-
[63]
Negative Prompt Augmentation: For Anatomical or Ren- dering artifacts, we augmented the model-specific neg- ative prompts with targeted keywords (e.g., adding ”de- formed iris” or ”glitch”) to actively suppress the defect in the next generation pass
-
[64]
Parameter Adjustment: For Temporal Artifacts or weak adherence to instructions, we fine-tuned the generation hyperparameters: • CFG Scale: Adjusted (typically +0.5 to +1.0) to strengthen semantic adherence. • Inference Steps: Increased (e.g., from 50 to 60) to re- solve under-generated details. • Temporal Shift: Modified to stabilize motion trajecto- ries...
-
[65]
Extended Results and Analysis In this section we present the evaluation methodology de- signed to execute a fair comparison across diverse detec- tion architectures. We first outline the preprocessing and output standardization steps required to align frame-level and video-level models, and then define the primary metrics used to measure detection efficac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.