Recognition: 2 theorem links
· Lean TheoremJoint Embedding Variational Bayes
Pith reviewed 2026-05-16 07:00 UTC · model grok-4.3
The pith
Variational Joint Embedding learns non-contrastive representations with direct probabilistic semantics in embedding space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VJE maximizes a symmetric conditional evidence lower bound on paired encoder embeddings by defining a conditional likelihood directly on target representations as a heavy-tailed Student-t distribution on their polar coordinates; the directional factor on the unit sphere yields a valid variational bound for the associated spherical subdensity model, while an amortized diagonal Gaussian posterior shares feature-wise variances with the likelihood to produce structured uncertainty directly in the learned embedding space.
What carries the argument
Symmetric conditional ELBO with Student-t likelihood on polar coordinates of target embeddings, using shared-variance diagonal Gaussian posterior for anisotropic uncertainty without projection heads.
If this is right
- Uncertainty estimates are available directly in representation space for downstream tasks without extra heads.
- Representation-space likelihoods enable strong out-of-distribution detection performance.
- The method remains competitive with non-contrastive baselines on ImageNet-1K, CIFAR-10/100 and STL-10 under linear and k-NN evaluation.
- No reconstruction or contrastive loss is required to obtain probabilistic semantics in the embedding.
Where Pith is reading between the lines
- The polar decomposition may extend naturally to other geometric SSL objectives that separate direction and scale.
- Feature-wise variance sharing could improve calibration when the same embeddings are used in downstream Bayesian models.
- Replacing the Student-t with other heavy-tailed distributions might tighten the bound or alter uncertainty behavior on different datasets.
Load-bearing premise
Instantiating the conditional likelihood as a heavy-tailed Student-t on a polar representation of the target embedding yields a valid variational bound for the spherical subdensity model.
What would settle it
If linear-probe accuracy on ImageNet-1K drops below competitive non-contrastive baselines or if representation-space likelihoods fail to produce competitive AUROC on standard out-of-distribution detection splits.
Figures





read the original abstract
We introduce Variational Joint Embedding (VJE), a reconstruction-free latent-variable framework for non-contrastive self-supervised learning in representation space. VJE maximizes a symmetric conditional evidence lower bound (ELBO) on paired encoder embeddings by defining a conditional likelihood directly on target representations, rather than optimizing a pointwise compatibility objective. The likelihood is instantiated as a heavy-tailed Student--\(t\) distribution on a polar representation of the target embedding, where a directional--radial decomposition separates angular agreement from magnitude consistency and mitigates norm-induced pathologies. The directional factor operates on the unit sphere, yielding a valid variational bound for the associated spherical subdensity model. An amortized inference network parameterizes a diagonal Gaussian posterior whose feature-wise variances are shared with the directional likelihood, yielding anisotropic uncertainty without auxiliary projection heads. Across ImageNet-1K, CIFAR-10/100, and STL-10, VJE is competitive with standard non-contrastive baselines under linear and \(k\)-NN evaluation, while providing probabilistic semantics directly in representation space for downstream uncertainty-aware applications. We validate these semantics through out-of-distribution detection, where representation-space likelihoods yield strong empirical performance. These results position the framework as a principled variational formulation of non-contrastive learning, in which structured feature-wise uncertainty is represented directly in the learned embedding space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Variational Joint Embedding (VJE), a reconstruction-free latent-variable framework for non-contrastive self-supervised learning. It maximizes a symmetric conditional ELBO on paired encoder embeddings by placing a heavy-tailed Student-t conditional likelihood directly on a polar (directional-radial) decomposition of target representations, with an amortized diagonal-Gaussian posterior whose feature-wise variances are shared with the likelihood to produce anisotropic uncertainty. Experiments across ImageNet-1K, CIFAR-10/100 and STL-10 report competitiveness with standard non-contrastive baselines under linear and k-NN evaluation, together with strong OOD detection performance when using representation-space likelihoods.
Significance. If the central variational construction is shown to be a valid lower bound, the work would supply a principled probabilistic formulation of non-contrastive SSL that directly encodes structured, feature-wise uncertainty in the embedding space. This would be a meaningful advance over pointwise objectives, enabling downstream uncertainty-aware applications without auxiliary heads or post-hoc calibration.
major comments (2)
- [Abstract / §3 (ELBO derivation)] Abstract and the ELBO derivation (presumably §3): the claim that the directional factor on the unit sphere 'yields a valid variational bound for the associated spherical subdensity model' is load-bearing for the entire symmetric conditional ELBO and the claimed probabilistic semantics. The manuscript must supply the explicit marginalization over the radial component, the normalization constant of the spherical subdensity, and a proof that the Student-t polar likelihood does not introduce an unaccounted multiplicative factor that would invalidate the bound or render it tautological.
- [§4 (likelihood)] §4 (likelihood definition): the decomposition into directional and radial factors is asserted to mitigate norm-induced pathologies, yet no quantitative verification is provided that the resulting bound remains strictly tighter than a standard Gaussian or von-Mises-Fisher baseline once the shared-variance amortization is introduced. Without this check, the advantage over existing non-contrastive objectives remains unsupported.
minor comments (2)
- [§5 (experiments)] The experimental section should report the precise temperature, degrees-of-freedom, and variance-sharing schedule used for the Student-t; these hyperparameters are currently described only qualitatively.
- [§3] Notation for the polar coordinates (r, u) and the precise definition of the spherical subdensity should be introduced once in a dedicated paragraph rather than inline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on the variational validity and empirical support for our proposed likelihood. We address each point below and will incorporate the requested clarifications and experiments into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / §3 (ELBO derivation)] Abstract and the ELBO derivation (presumably §3): the claim that the directional factor on the unit sphere 'yields a valid variational bound for the associated spherical subdensity model' is load-bearing for the entire symmetric conditional ELBO and the claimed probabilistic semantics. The manuscript must supply the explicit marginalization over the radial component, the normalization constant of the spherical subdensity, and a proof that the Student-t polar likelihood does not introduce an unaccounted multiplicative factor that would invalidate the bound or render it tautological.
Authors: We agree that an explicit derivation is necessary to substantiate the claim. In the revised manuscript we will add a dedicated appendix section that (i) performs the marginalization over the radial component of the Student-t polar likelihood, (ii) derives the closed-form normalization constant of the resulting spherical subdensity, and (iii) proves that the directional factor introduces no extraneous multiplicative term that would invalidate the ELBO. The proof proceeds by showing that the joint density factors cleanly into radial and directional parts under the chosen parameterization, with the radial integral absorbed into the evidence term without affecting the variational bound on the directional subdensity. revision: yes
-
Referee: [§4 (likelihood)] §4 (likelihood definition): the decomposition into directional and radial factors is asserted to mitigate norm-induced pathologies, yet no quantitative verification is provided that the resulting bound remains strictly tighter than a standard Gaussian or von-Mises-Fisher baseline once the shared-variance amortization is introduced. Without this check, the advantage over existing non-contrastive objectives remains unsupported.
Authors: We acknowledge the absence of a direct tightness comparison. In the revision we will add a controlled experiment on CIFAR-10 that evaluates the ELBO value (and its gap to the true log-likelihood where computable) for our Student-t polar model against isotropic Gaussian and von-Mises-Fisher baselines under identical shared-variance amortization. The results will be reported in a new table and will quantify whether the directional-radial decomposition yields a strictly tighter bound while preserving the same computational cost. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided manuscript text introduces VJE as maximizing a symmetric conditional ELBO on paired encoder embeddings via a Student-t likelihood on polar representations of target embeddings, with the directional factor asserted to yield a valid variational bound on the spherical subdensity. No equations or derivation steps are exhibited that reduce the bound to a tautology, rename a fitted parameter as a prediction, or rely on a self-citation chain whose load-bearing premise is unverified. The framework adds independent content through amortized diagonal-Gaussian posteriors with shared variances for anisotropic uncertainty and empirical validation on ImageNet-1K, CIFAR, and STL-10 under linear/k-NN protocols. The central claim therefore does not collapse to its inputs by construction and remains externally falsifiable via downstream tasks such as OOD detection.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The directional factor on the unit sphere yields a valid variational bound for the spherical subdensity model
Lean theorems connected to this paper
-
Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
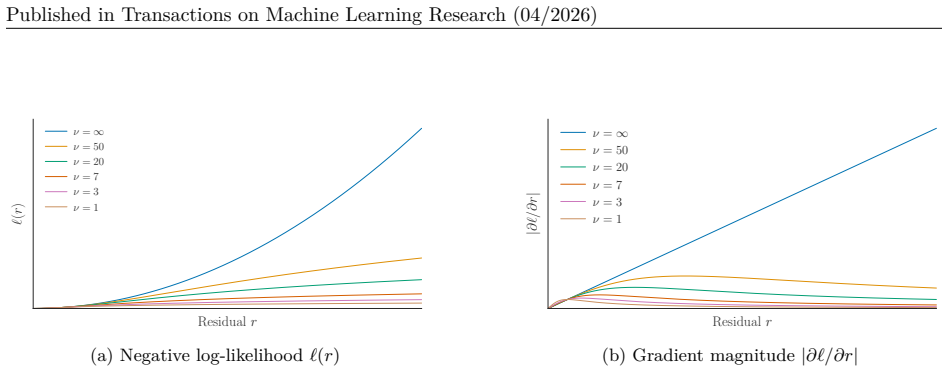
We adopt a heavy-tailed Student–t likelihood... pt,Σψ(z|s) = Cν,D |Σ|−1/2 [1 + 1/ν (z−s)⊤Σ−1(z−s)]−(ν+D)/2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
URLhttps://arxiv.org/abs/2511.08544. Adrien Bardes, Jean Ponce, and Yann LeCun. VICReg: Variance-invariance-covariance regularization for self-supervised learning. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review arXiv
-
[3]
Improved Baselines with Momentum Contrastive Learning
Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. InarXiv preprint arXiv:2003.04297, 2020b. URLhttps://arxiv.org/abs/2003.04297. Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. InAdvances...
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[4]
Deep bayesian active learning with image data
23 Published in Transactions on Machine Learning Research (04/2026) Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. In Proceedings of the 34th International Conference on Machine Learning (ICML), pages 1183–1192. PMLR,
work page 2026
-
[5]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Probabilistic variational contrastive learning.arXiv preprint arXiv:2506.10159,
Minoh Jeong, Seonho Kim, and Alfred Hero. Probabilistic variational contrastive learning.arXiv preprint arXiv:2506.10159,
-
[7]
24 Published in Transactions on Machine Learning Research (04/2026) Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. InInternational Conference on Learning Representations (ICLR),
work page 2026
-
[8]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y
URLhttps://arxiv.org/abs/2203.11437. Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning.NIPS Workshop on Deep Learning and Unsupervised Feature Learning,
-
[9]
Variational supervised contrastive learning
Ziwen Wang, Jiajun Fan, Thao Nguyen, Heng Ji, and Ge Liu. Variational supervised contrastive learning. arXiv preprint arXiv:2506.07413,
-
[10]
URLhttps://openreview.net/ forum?id=gT6j4_tskUt. 25 Published in Transactions on Machine Learning Research (04/2026) Mehmet Can Yavuz and Berrin Yanikoglu. Self-supervised variational contrastive learning with applications to face understanding. In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), pages 1–9,
work page 2026
-
[11]
Mehmet Can Yavuz and Berrin Yanikoglu
doi: 10.1109/FG59268.2024.10582001. Mehmet Can Yavuz and Berrin Yanikoglu. Variational self-supervised learning,
-
[12]
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny
arXiv preprint arXiv:2504.04318. Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning via redundancy reduction. InInternational Conference on Machine Learning (ICML), pages 12310–12320. PMLR,
-
[13]
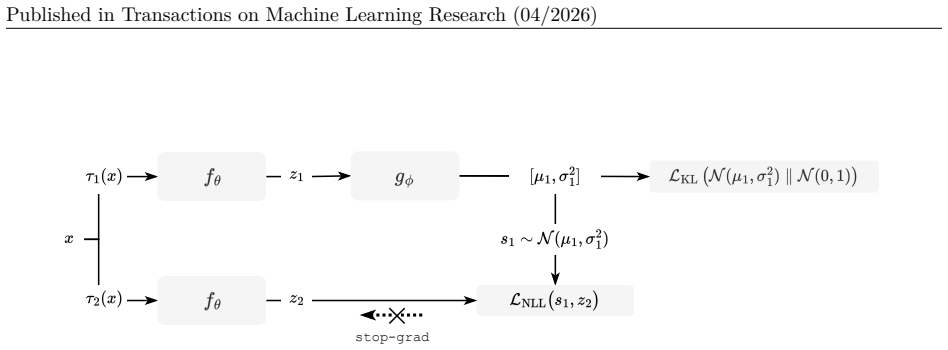
26 Published in Transactions on Machine Learning Research (04/2026) A Pseudocode and implementation details This appendix provides pseudocode for the VJE objective described in Sections 3 and 4, followed by implementation details to assist with reproducibility. The routines implement the symmetric conditional ELBO of Eq.(38) using the factorized direction...
work page 2026
-
[14]
log ( 1 + (∆r) 2/ν ) KL divergence.This routine computes the analytic KL divergence between a diagonal Gaussian posterior and the standard Gaussian prior, as in Eq. (7). Algorithm 3KL divergence (diagonal Gaussian vs. standard Normal) Require:Mean vectorµ, variance vectorσ2 1:return 1 2 ∑ k ( σ2 k +µ2 k−1−logσ2 k ) VJE training step.This routine performs ...
work page 2026
-
[15]
andDv = D for the diagonal (anisotropic) parameterization. All linear layers in the bottleneck usebias=False, since the subsequent Layer Normalization absorbs any bias. The output heads retain bias terms. We use a bottleneck width ratio ofr=0.25, yielding H=128for ResNet–18 (D=512) andH=512for ResNet–50 (D=2048). The Softplus activationσ2 = log(1 +exp(·))...
work page 2048
-
[16]
encoder retains its default random initialization (He et al., 2015). A.2 Additional implementation notes • ELBO structure.Likelihood terms usez j.detach(), implementing the conditional ELBO of Section 4.4 and Eq.(38), where each view predicts the latent representation of the opposite view under fixed-observation semantics. The same semantics can equivalen...
work page 2015
-
[17]
provides a complementary perspective by advocating an isotropic Gaussian target geometry for embeddings and introducing SIGReg as an explicit global regularizer that encourages this structure. The relationship to VJE is geometric rather than a strict reduction, since LeJEPA enforces isotropy through a deterministic regularizer on encoder outputs, whereas ...
work page 2026
-
[18]
of the representation drops to 3 out of 2048 dimensions. Over the same training run,k–NN accuracy on the encoder outputzdeclines from 8.7% to 6.3%, whilek–NN on the posterior meanµremains at chance level throughout. Under identical conditions, the factorized model trains normally, reaches 71.0%k–NN accuracy, maintains¯σ2≈0.63, and reaches an effective rank of
work page 2048
-
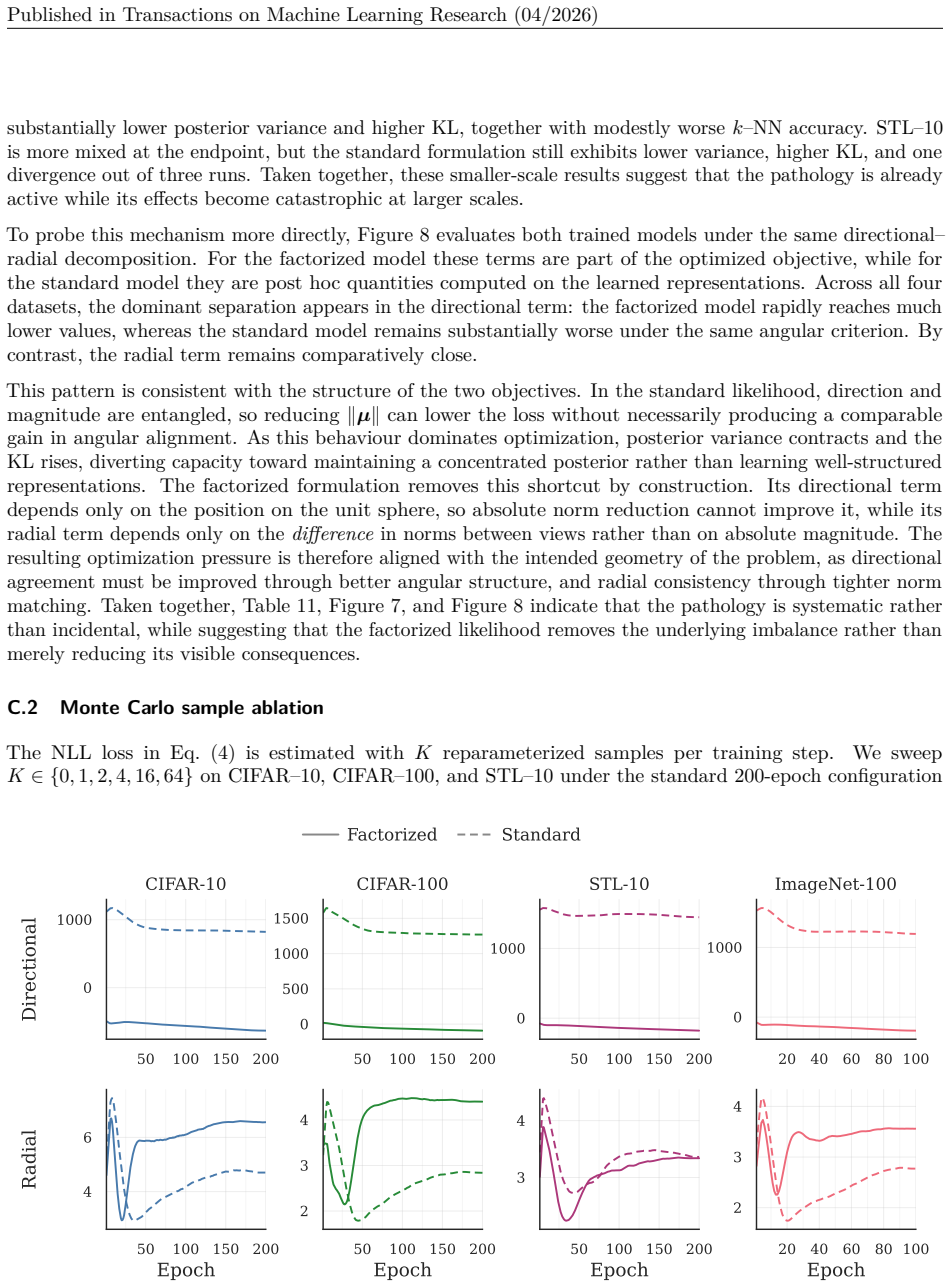
[19]
On the smaller benchmarks, the same mechanism is present but does not yet develop into full collapse. Table 11 shows a consistent pattern on CIFAR–10 and CIFAR–100, where the standard formulation yields 20 40 60 80 100 Epoch 0.1 0.2 0.3 0.4 0.5 0.6σ2 20 40 60 80 100 Epoch 500 750 1000 1250 1500KLD 20 40 60 80 100 Epoch 0 250 500 750 1000Effective rank Fac...
work page 2026
-
[20]
The isotropic posterior therefore does not carry instance-level uncertainty, as it degenerates to a single global scale shared across the batch. Under the same training protocol, anisotropic VJE learns discriminative encoder features and an informative posterior mean, whereas the isotropic variant converges to a constant-variance posterior whose mean is 3...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.