Recognition: no theorem link
MePo: Meta Post-Refinement for Rehearsal-Free General Continual Learning
Pith reviewed 2026-05-16 06:17 UTC · model grok-4.3
The pith
Meta Post-Refinement refines pretrained backbones via bi-level meta-learning on pseudo tasks to improve rehearsal-free general continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
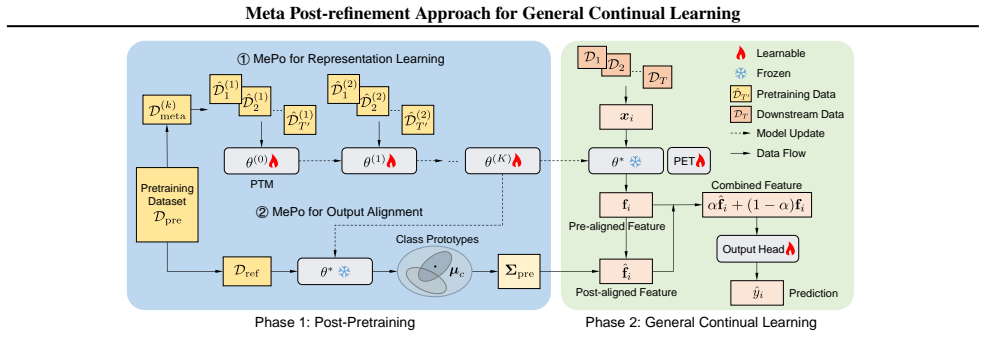
MePo constructs pseudo task sequences from pretraining data and develops a bi-level meta-learning paradigm to refine the pretrained backbone, which serves as a prolonged pretraining phase but greatly facilitates rapid adaptation of representation learning to downstream GCL tasks. MePo further initializes a meta covariance matrix as the reference geometry of pretrained representation space, enabling GCL to exploit second-order statistics for robust output alignment.
What carries the argument
Bi-level meta-learning applied to pseudo task sequences derived from pretraining data, together with an initialized meta covariance matrix that supplies reference geometry for second-order statistics.
If this is right
- Significant performance gains of roughly 12-15 percent on CIFAR-100, ImageNet-R, and CUB-200 under rehearsal-free conditions.
- Compatibility as a plug-in across multiple pretrained checkpoints without changing the downstream continual learning algorithm.
- Better exploitation of second-order statistics through the meta covariance matrix for output alignment during continual updates.
Where Pith is reading between the lines
- The same pseudo-task construction and bi-level refinement could be tested on non-vision continual learning problems such as language modeling or reinforcement learning.
- If the meta covariance reference proves stable, rehearsal buffers might be replaced by this geometry in privacy-sensitive deployments.
- Combining MePo with other lightweight adaptation techniques could further reduce the number of gradient steps needed at test time.
Load-bearing premise
That pseudo task sequences built from pretraining data plus bi-level meta-learning will sufficiently prepare the representation space for the diverse and temporally mixed information found in downstream general continual learning tasks.
What would settle it
Run MePo on a new GCL benchmark whose task distribution differs sharply from the pretraining data distribution and measure whether the reported accuracy gains disappear.
Figures







read the original abstract
To cope with uncertain changes of the external world, intelligent systems must continually learn from complex, evolving environments and respond in real time. This ability, collectively known as general continual learning (GCL), encapsulates practical challenges such as online datastreams and blurry task boundaries. Although leveraging pretrained models (PTMs) has greatly advanced conventional continual learning (CL), these methods remain limited in reconciling the diverse and temporally mixed information along a single pass, resulting in sub-optimal GCL performance. Inspired by meta-plasticity and reconstructive memory in neuroscience, we introduce here an innovative approach named Meta Post-Refinement (MePo) for PTMs-based GCL. This approach constructs pseudo task sequences from pretraining data and develops a bi-level meta-learning paradigm to refine the pretrained backbone, which serves as a prolonged pretraining phase but greatly facilitates rapid adaptation of representation learning to downstream GCL tasks. MePo further initializes a meta covariance matrix as the reference geometry of pretrained representation space, enabling GCL to exploit second-order statistics for robust output alignment. MePo serves as a plug-in strategy that achieves significant performance gains across a variety of GCL benchmarks and pretrained checkpoints in a rehearsal-free manner (e.g., 15.10\%, 13.36\%, and 12.56\% on CIFAR-100, ImageNet-R, and CUB-200 under Sup-21/1K). Our source code is available at \href{https://github.com/SunGL001/MePo}{MePo}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Meta Post-Refinement (MePo), a plug-in method for rehearsal-free general continual learning (GCL) with pretrained models (PTMs). It constructs pseudo task sequences from pretraining data, applies bi-level meta-learning to refine the PTM backbone as an extended pretraining stage, and initializes a meta covariance matrix to provide second-order geometric reference for output alignment during downstream GCL. The central claim is that this yields substantial gains (e.g., +15.10% on CIFAR-100, +13.36% on ImageNet-R, +12.56% on CUB-200 under Sup-21/1K) across benchmarks and checkpoints without rehearsal.
Significance. If the performance claims are substantiated with proper controls, MePo would represent a practical advance for PTM-based GCL by addressing online streams and blurry boundaries through meta-plasticity-inspired refinement and covariance alignment. The approach could reduce reliance on rehearsal buffers and provide a reusable initialization strategy, with potential impact on resource-efficient continual adaptation of large models.
major comments (3)
- [Experiments] Experimental section: The headline gains (15.10% on CIFAR-100, 13.36% on ImageNet-R, 12.56% on CUB-200) are reported without specifying the base PTM performance, exact baselines (e.g., standard fine-tuning or other PTM-CL methods), number of runs, variance, or statistical tests. This prevents assessment of whether improvements arise from the bi-level meta-learning and meta covariance or from generic additional optimization.
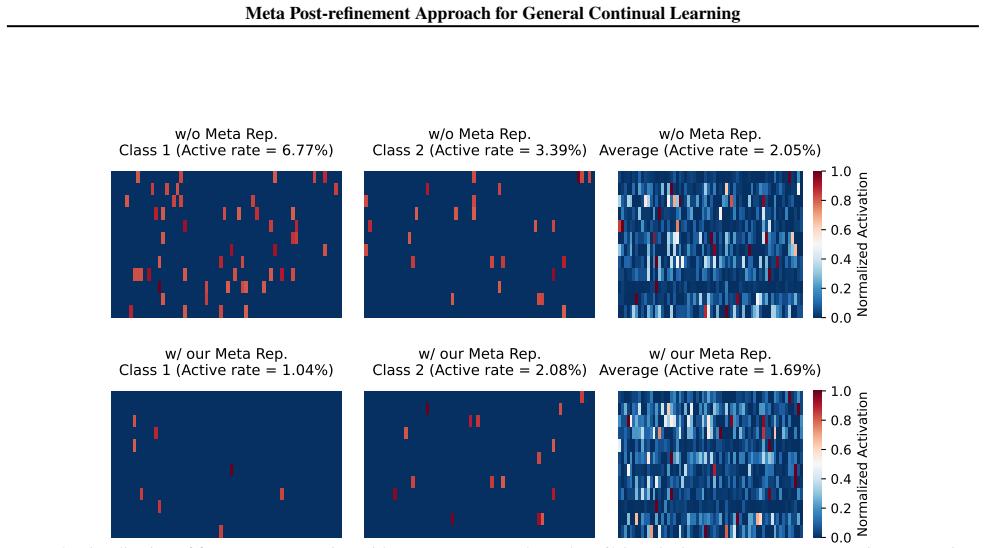
- [Section 3] Section 3 (Method): The core assumption that pseudo task sequences derived from pretraining data (e.g., ImageNet-like) plus bi-level meta-learning sufficiently align the representation space for diverse downstream GCL distributions (CUB-200 class granularity, ImageNet-R domain shifts, temporal mixing) lacks supporting ablations. No analysis shows that these pseudo tasks capture the required statistics or that the meta covariance remains effective without task-specific tuning.
- [Section 4] Section 4 (Ablations): The contribution of the meta covariance matrix versus the bi-level refinement alone is not isolated; without targeted ablations removing or randomizing the covariance initialization, it is unclear whether the second-order geometry is load-bearing for the reported alignment benefits.
minor comments (2)
- [Section 3] Notation for the meta covariance matrix and bi-level objective should be defined more explicitly with equations to clarify how the reference geometry is computed from the refined backbone.
- [Introduction] The abstract and introduction would benefit from a concise comparison table of MePo against prior PTM-CL methods to highlight the rehearsal-free and plug-in aspects.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each of the major comments point-by-point below, and we will incorporate the necessary revisions to enhance the manuscript's clarity and experimental rigor.
read point-by-point responses
-
Referee: [Experiments] Experimental section: The headline gains (15.10% on CIFAR-100, 13.36% on ImageNet-R, 12.56% on CUB-200) are reported without specifying the base PTM performance, exact baselines (e.g., standard fine-tuning or other PTM-CL methods), number of runs, variance, or statistical tests. This prevents assessment of whether improvements arise from the bi-level meta-learning and meta covariance or from generic additional optimization.
Authors: We agree that additional details are required to substantiate the claims. In the revised manuscript, we will specify the base PTM performance on each benchmark, list all exact baselines with their descriptions, report mean performance and standard deviation over multiple runs (at least 3), and include statistical significance tests (e.g., t-tests) against the baselines. These changes will allow readers to verify that the gains are due to the proposed bi-level meta-learning and meta covariance rather than generic optimization. revision: yes
-
Referee: [Section 3] Section 3 (Method): The core assumption that pseudo task sequences derived from pretraining data (e.g., ImageNet-like) plus bi-level meta-learning sufficiently align the representation space for diverse downstream GCL distributions (CUB-200 class granularity, ImageNet-R domain shifts, temporal mixing) lacks supporting ablations. No analysis shows that these pseudo tasks capture the required statistics or that the meta covariance remains effective without task-specific tuning.
Authors: We will add supporting ablations and analyses to Section 3 in the revision. This will include experiments demonstrating the alignment of representation spaces via metrics like average cosine similarity between features from pseudo tasks and downstream tasks, covering the mentioned distributions. We will also show results with varying pseudo task constructions to illustrate that the meta covariance does not require task-specific tuning and remains effective across different GCL scenarios. revision: yes
-
Referee: [Section 4] Section 4 (Ablations): The contribution of the meta covariance matrix versus the bi-level refinement alone is not isolated; without targeted ablations removing or randomizing the covariance initialization, it is unclear whether the second-order geometry is load-bearing for the reported alignment benefits.
Authors: We acknowledge this gap and will include targeted ablations in the revised Section 4. Specifically, we will compare the full MePo method against versions with only bi-level refinement (no covariance) and with randomized covariance initialization. Performance results on CIFAR-100, ImageNet-R, and CUB-200 will isolate the contribution of the meta covariance matrix to the alignment benefits. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents MePo as a plug-in method that constructs pseudo task sequences from pretraining data, applies bi-level meta-learning to refine the PTM backbone, and initializes a meta covariance matrix for second-order statistics. No load-bearing step reduces by construction to its inputs: the meta covariance is explicitly an initialization rather than a fitted quantity derived from the target GCL result, and performance claims are framed as empirical outcomes on downstream benchmarks rather than predictions forced by the fitting process itself. No self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work are invoked to justify core choices. The derivation remains self-contained with independent content from the meta-plasticity inspiration and rehearsal-free design.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained models can be effectively refined for GCL via bi-level meta-learning on pseudo task sequences constructed from pretraining data
invented entities (1)
-
meta covariance matrix
no independent evidence
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020a. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., ...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Koh, H., Kim, D., Ha, J.-W., and Choi, J. Online continual learning on class incremental blurry task configuration with anytime inference.arXiv preprint arXiv:2110.10031,
-
[4]
On First-Order Meta-Learning Algorithms
Nichol, A., Achiam, J., and Schulman, J. On first-order meta-learning algorithms.arXiv preprint arXiv:1803.02999,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Imagenet-21k pretraining for the masses
Ridnik, T., Ben-Baruch, E., Noy, A., and Zelnik-Manor, L. Imagenet-21k pretraining for the masses.arXiv preprint arXiv:2104.10972,
-
[6]
Van de Ven, G. M. and Tolias, A. S. Three scenarios for continual learning.arXiv preprint arXiv:1904.07734,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[7]
The caltech-ucsd birds-200-2011 dataset
Wah, C., Branson, S., Welinder, P., et al. The caltech-ucsd birds-200-2011 dataset
work page 2011
-
[8]
Zhang, G., Wang, L., Kang, G., Chen, L., and Wei, Y . Slca: Slow learner with classifier alignment for con- tinual learning on a pre-trained model.arXiv preprint arXiv:2303.05118,
-
[9]
iBOT: Image BERT Pre-Training with Online Tokenizer
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., and Kong, T. ibot: Image bert pre-training with online tokenizer.arXiv preprint arXiv:2111.07832,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
11 Meta Post-refinement Approach for General Continual Learning A. Related Work Continual Learning (CL)aims to overcome catastrophic forgetting when learning sequentially arriving tasks with distinct data distributions (Wang et al., 2024; Van de Ven & Tolias, 2019). Conventional CL settings often assume offline learning of each task with disjoint task bou...
work page 2024
-
[11]
(fine-grained dataset, 200-class large-scale images), to construct the evaluation benchmarks. We follow the official implementation of Si-Blurry (Moon et al., 2023; Kang et al., 2025), with the disjoint class ratio m= 50% and the blurry sample ratio n= 10% , and split all classes into 5 learning phases. Following the previous evaluation protocols (Moon et...
work page 2023
-
[12]
that selectively reduces the backbone learning rate, and linear probing of the fixed backbone. (2) PTMs-based CL methods such as L2P (Wang et al., 2022b), DualPrompt (Wang et al., 2022a), and CODA-P (Smith et al., 2023). Here we follow the previous work (Smith et al.,
work page 2023
-
[13]
All PTMs-based methods employ prefix tuning with prompt length 5, inserted into layers 1-5
and MISA (Kang et al., 2025). All PTMs-based methods employ prefix tuning with prompt length 5, inserted into layers 1-5. Training DetailsWe follow the previous implementations (Moon et al., 2023; Kang et al.,
work page 2025
-
[14]
to ensure fairness of the comparison. We adopt a ViT-B/16 backbone and consider three ImageNet-21K pretrained checkpoints with different levels of supervision: Sup-21K (vit-base-patch16-224) performs supervised pretraining on ImageNet-21K, Sup- 21/1K (Ridnik et al., 2021; Dosovitskiy et al., 2020b) performs self-supervised pretraining on ImageNet-21K and ...
work page 2021
-
[15]
To implement MePo, both Dmeta and Dref are constructed from ImageNet-1K (Russakovsky et al., 2015)
performs self-supervised pretraining on ImageNet-21K. To implement MePo, both Dmeta and Dref are constructed from ImageNet-1K (Russakovsky et al., 2015). In MePo Phase I, we construct Dmeta by randomly sampling |Cmeta|= 100 classes with 400 samples per class and training-validation split rate γ 12 Meta Post-refinement Approach for General Continual Learni...
work page 2015
-
[16]
All results are averaged over five runs with different task sequences
as the baseline implementation. All results are averaged over five runs with different task sequences. Setup MVP w/ MePo MISA w/ MePo 0 0.1 0.3 0.5 0.7 1.0 0 0.1 0.3 0.5 0.7 1.0 Sup-21K CIFAR-10071.74±4.1471.86±4.1472.09±4.2672.18±4.5071.63±4.6649.84±5.8281.29±2.2781.59±2.3382.14±2.5682.30±2.8381.56±3.2476.95±4.48 Sup-21K ImageNet-R46.32±1.2946.35±1.3146....
work page 2053
-
[17]
All results are averaged over five runs with different task sequences
as the baseline implementation. All results are averaged over five runs with different task sequences. Setup MVP w/ MePo MISA w/ MePo 0 0.1 0.3 0.5 0.7 1.0 0 0.1 0.3 0.5 0.7 1.0 Sup-21K CIFAR-10065.40±1.9966.05±1.9067.47±1.6868.45±1.5968.82±1.5647.43±2.2481.96±1.1282.31±1.0683.18±1.1183.99±1.3584.22±1.3782.06±1.74 Sup-21K ImageNet-R38.06±3.7738.21±3.6638....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.