Raster2Seq: Polygon Sequence Generation for Floorplan Reconstruction
Pith reviewed 2026-05-16 05:15 UTC · model grok-4.3
The pith
Raster2Seq generates labeled polygon sequences for rooms, windows and doors from floorplan images using an autoregressive decoder guided by learnable anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that representing floorplan elements as labeled polygon sequences and predicting them autoregressively with learnable spatial anchors allows the model to produce complete, non-self-intersecting polygons that faithfully capture the structure and semantics of complex multi-room layouts directly from raster input.
What carries the argument
An autoregressive decoder that predicts the next polygon corner conditioned on image features and previous corners, guided by learnable anchors defined as spatial coordinates in image space to direct attention.
Load-bearing premise
The autoregressive decoder with learnable anchors produces complete, non-self-intersecting polygons for complex multi-room floorplans without accumulating errors that would require structure-altering post-processing.
What would settle it
A test set of complex floorplans containing more than ten rooms where the generated polygons frequently self-intersect, leave rooms incomplete, or require manual correction to match ground-truth topology would falsify the claim of faithful sequence generation.
Figures
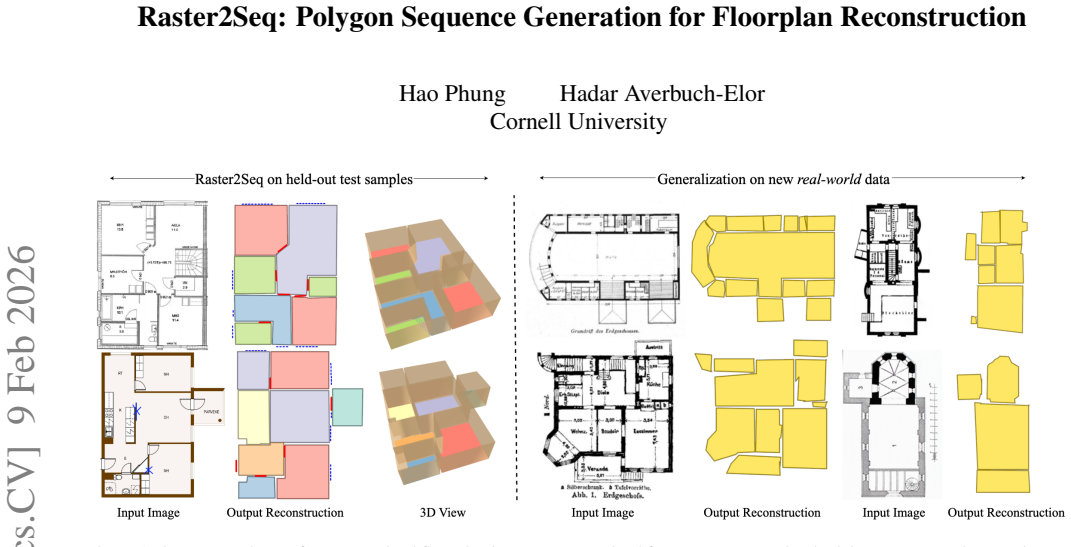




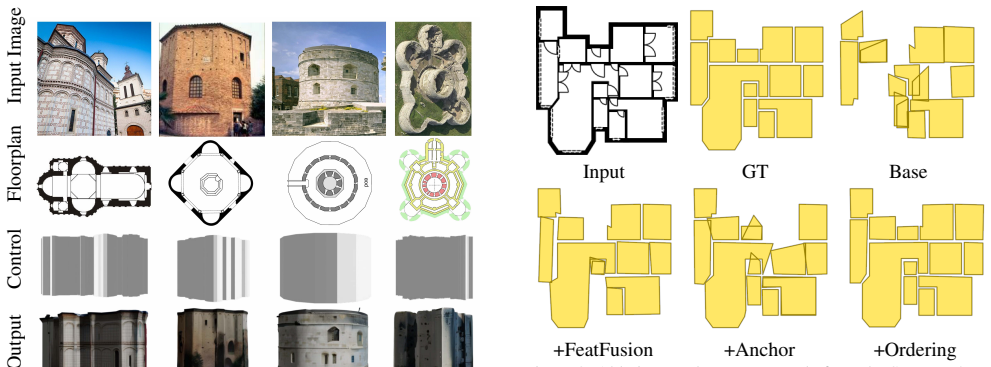



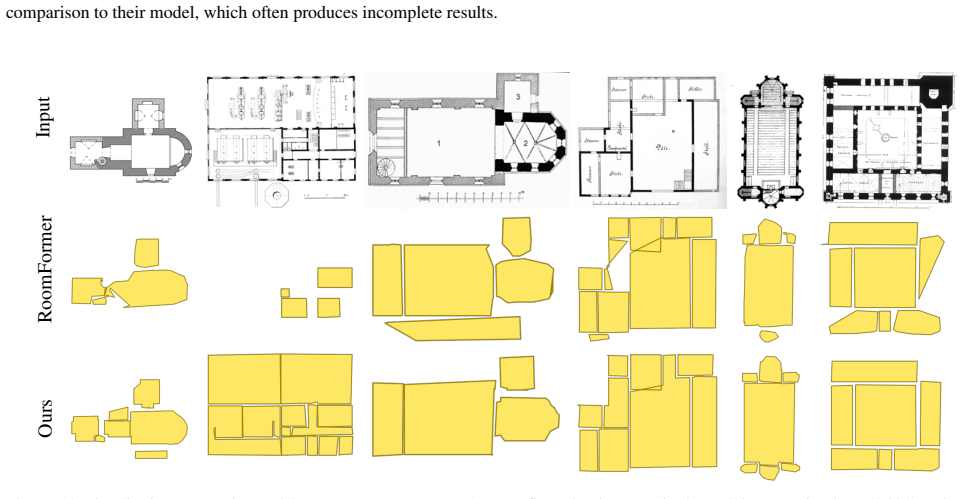




read the original abstract
Reconstructing a structured vector-graphics representation from a rasterized floorplan image is typically an important prerequisite for computational tasks involving floorplans such as automated understanding or CAD workflows. However, existing techniques struggle in faithfully generating the structure and semantics conveyed by complex floorplans that depict large indoor spaces with many rooms and a varying numbers of polygon corners. To this end, we propose Raster2Seq, framing floorplan reconstruction as a sequence-to-sequence task in which floorplan elements--such as rooms, windows, and doors--are represented as labeled polygon sequences that jointly encode geometry and semantics. Our approach introduces an autoregressive decoder that learns to predict the next corner conditioned on image features and previously generated corners using guidance from learnable anchors. These anchors represent spatial coordinates in image space, hence allowing for effectively directing the attention mechanism to focus on informative image regions. By embracing the autoregressive mechanism, our method offers flexibility in the output format, enabling for efficiently handling complex floorplans with numerous rooms and diverse polygon structures. Our method achieves state-of-the-art performance on standard benchmarks such as Structure3D, CubiCasa5K, and Raster2Graph, while also demonstrating strong generalization to more challenging datasets like WAFFLE, which contain diverse room structures and complex geometric variations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Raster2Seq, which recasts floorplan reconstruction from raster images as a sequence-to-sequence generation problem. Rooms, windows, and doors are represented as labeled polygon sequences; an autoregressive decoder predicts successive corners conditioned on image features, prior corners, and learnable spatial anchors that guide attention. The method is claimed to achieve state-of-the-art results on Structure3D, CubiCasa5K, and Raster2Graph while generalizing to the more challenging WAFFLE dataset containing diverse room structures.
Significance. If the geometric fidelity of the generated polygons is reliably maintained, the autoregressive formulation with learnable anchors offers a flexible alternative to fixed-topology or graph-based reconstruction pipelines, particularly for floorplans with variable numbers of rooms and corners. The approach could streamline downstream CAD and semantic-understanding tasks, provided the reported benchmark gains are reproducible and the outputs require no topology-altering post-processing.
major comments (3)
- [§3] §3 (Method), autoregressive decoder paragraph: the description of next-corner prediction conditioned on image features and learnable anchors supplies no explicit loss terms, closure regularizers, or non-intersection penalties. Without these, the claim that complete, non-self-intersecting polygons are produced for arbitrary multi-room layouts rests on an unverified assumption that sequential coordinate regression remains geometrically valid over long sequences.
- [§4] §4 (Experiments): the abstract asserts SOTA performance and strong generalization to WAFFLE, yet the provided text contains no quantitative tables, error bars, ablation studies on anchor count or sequence length, or direct baseline comparisons. This absence prevents verification that the reported gains are attributable to the proposed decoder rather than dataset-specific tuning.
- [§3.2] §3.2 (Learnable anchors): the anchors are introduced as spatial coordinates that direct attention, but no analysis is given of how they prevent error accumulation when the number of corners per polygon varies widely (as in WAFFLE). A concrete test—e.g., measuring polygon validity rate versus sequence length—would be required to support the generalization claim.
minor comments (2)
- [§3] Notation for polygon labels (room/window/door) is introduced in the abstract but not consistently defined with respect to the sequence vocabulary in the method section.
- [Figures] Figure captions should explicitly state whether post-processing was applied to close or simplify polygons before metric computation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment below and have revised the paper to incorporate the suggested additions and clarifications.
read point-by-point responses
-
Referee: [§3] §3 (Method), autoregressive decoder paragraph: the description of next-corner prediction conditioned on image features and learnable anchors supplies no explicit loss terms, closure regularizers, or non-intersection penalties. Without these, the claim that complete, non-self-intersecting polygons are produced for arbitrary multi-room layouts rests on an unverified assumption that sequential coordinate regression remains geometrically valid over long sequences.
Authors: We appreciate the referee highlighting this point. The autoregressive decoder is trained with a composite loss consisting of an L2 regression term on the predicted corner coordinates and a cross-entropy term for the semantic labels of each polygon element. While we deliberately avoid hand-crafted closure or non-intersection penalties to preserve the flexibility of the sequence model, the end-to-end training on ground-truth polygon sequences encourages geometrically coherent outputs. Our benchmark evaluations already report high polygon validity rates without topology-altering post-processing. In the revision we have expanded §3 to explicitly state the loss formulation and added a brief discussion of why explicit geometric regularizers were not required. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract asserts SOTA performance and strong generalization to WAFFLE, yet the provided text contains no quantitative tables, error bars, ablation studies on anchor count or sequence length, or direct baseline comparisons. This absence prevents verification that the reported gains are attributable to the proposed decoder rather than dataset-specific tuning.
Authors: The full manuscript already contains quantitative tables in §4 with direct comparisons against prior methods on Structure3D, CubiCasa5K, and Raster2Graph, plus generalization results on WAFFLE. To address the concern, we have now added error bars computed over multiple random seeds, an ablation table varying the number of learnable anchors, and an additional plot of performance versus maximum sequence length. These revisions make the attribution of gains to the anchor-guided decoder explicit and reproducible. revision: yes
-
Referee: [§3.2] §3.2 (Learnable anchors): the anchors are introduced as spatial coordinates that direct attention, but no analysis is given of how they prevent error accumulation when the number of corners per polygon varies widely (as in WAFFLE). A concrete test—e.g., measuring polygon validity rate versus sequence length—would be required to support the generalization claim.
Authors: We agree that a targeted analysis of error accumulation would strengthen the generalization argument. In the revised manuscript we have added a new experiment in §4 that measures polygon validity rate as a function of sequence length on the WAFFLE dataset. The results demonstrate that the learnable anchors maintain high validity rates even for longer sequences with highly variable corner counts, supporting the claim that they mitigate attention drift. We have also included a short discussion in §3.2 explaining the mechanism. revision: yes
Circularity Check
No circularity: standard learned sequence model evaluated on external benchmarks
full rationale
The paper presents Raster2Seq as an autoregressive sequence-to-sequence architecture that predicts polygon corners conditioned on image features and learnable anchors. All performance claims (SOTA on Structure3D, CubiCasa5K, Raster2Graph, and generalization to WAFFLE) rest on empirical training and evaluation against independent external datasets rather than any internal equations, fitted parameters renamed as predictions, or self-citation chains. No derivation reduces outputs to inputs by construction; the method is a conventional neural network whose validity is tested outside its own fitted values.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable anchors
axioms (1)
- domain assumption Autoregressive next-corner prediction can produce topologically valid polygons without cumulative drift or self-intersections on complex floorplans
invented entities (1)
-
learnable anchors
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach introduces an autoregressive decoder that learns to predict the next corner conditioned on image features and previously generated corners using guidance from learnable anchors.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By embracing the autoregressive mechanism, our method offers flexibility in the output format, enabling for efficiently handling complex floorplans with numerous rooms and diverse polygon structures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ef- ficient interactive annotation of segmentation datasets with polygon-rnn++
David Acuna, Huan Ling, Amlan Kar, and Sanja Fidler. Ef- ficient interactive annotation of segmentation datasets with polygon-rnn++. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 859–868,
-
[2]
Improved automatic analysis of architectural floor plans
Sheraz Ahmed, Marcus Liwicki, Markus Weber, and Andreas Dengel. Improved automatic analysis of architectural floor plans. In2011 International conference on document analysis and recognition, pages 864–869. IEEE, 2011. 2
work page 2011
-
[3]
Scene- script: Reconstructing scenes with an autoregressive struc- tured language model
Armen Avetisyan, Christopher Xie, Henry Howard-Jenkins, Tsun-Yi Yang, Samir Aroudj, Suvam Patra, Fuyang Zhang, Duncan Frost, Luke Holland, Campbell Orme, et al. Scene- script: Reconstructing scenes with an autoregressive struc- tured language model. InEuropean Conference on Computer Vision, pages 247–263. Springer, 2024. 3
work page 2024
-
[4]
Piecewise planar and compact floorplan reconstruction from images
Ricardo Cabral and Yasutaka Furukawa. Piecewise planar and compact floorplan reconstruction from images. In2014 IEEE Conference on Computer Vision and Pattern Recognition, pages 628–635. IEEE, 2014. 2
work page 2014
-
[5]
Floor-sp: Inverse cad for floorplans by sequential room-wise shortest path
Jiacheng Chen, Chen Liu, Jiaye Wu, and Yasutaka Furukawa. Floor-sp: Inverse cad for floorplans by sequential room-wise shortest path. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2661–2670, 2019. 2
work page 2019
-
[6]
Heat: Holistic edge attention transformer for structured reconstruc- tion
Jiacheng Chen, Yiming Qian, and Yasutaka Furukawa. Heat: Holistic edge attention transformer for structured reconstruc- tion. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 3866–3875, 2022. 2, 3, 6, 18
work page 2022
-
[7]
Jiacheng Chen, Ruizhi Deng, and Yasutaka Furukawa. Poly- diffuse: Polygonal shape reconstruction via guided set dif- fusion models.Advances in Neural Information Processing Systems, 36:1863–1888, 2023. 7, 16, 18
work page 2023
-
[8]
Pix2seq: A language modeling framework for object detection.arXiv preprint arXiv:2109.10852, 2021
Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection.arXiv preprint arXiv:2109.10852, 2021. 3
-
[9]
Ting Chen, Saurabh Saxena, Lala Li, Tsung-Yi Lin, David J Fleet, and Geoffrey E Hinton. A unified sequence interface for vision tasks.Advances in Neural Information Processing Systems, 35:31333–31346, 2022. 3
work page 2022
-
[10]
Meshed-memory transformer for image caption- ing
Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, and Rita Cucchiara. Meshed-memory transformer for image caption- ing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10578–10587, 2020. 3
work page 2020
-
[11]
Lluis-Pere De Las Heras, Sheraz Ahmed, Marcus Liwicki, Ernest Valveny, and Gemma Sánchez. Statistical segmenta- tion and structural recognition for floor plan interpretation: Notation invariant structural element recognition.Interna- tional Journal on Document Analysis and Recognition (IJ- DAR), 17(3):221–237, 2014. 2
work page 2014
-
[12]
Spacecontrol: Intro- ducing test-time spatial control to 3d generative modeling
Elisabetta Fedele, Francis Engelmann, Ian Huang, Or Litany, Marc Pollefeys, and Leonidas Guibas. Spacecontrol: Intro- ducing test-time spatial control to 3d generative modeling. arXiv preprint arXiv:2512.05343, 2025. 7
-
[13]
Waffle: Multimodal floorplan understanding in the wild
Keren Ganon, Morris Alper, Rachel Mikulinsky, and Hadar Averbuch-Elor. Waffle: Multimodal floorplan understanding in the wild. In2025 IEEE/CVF Winter Conference on Appli- cations of Computer Vision (WACV), pages 1488–1497. IEEE,
-
[14]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 14
work page 2016
-
[15]
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE international conference on computer vision, 2017. 14
work page 2017
-
[16]
Sizhe Hu, Wenming Wu, Ruolin Su, Wanni Hou, Liping Zheng, and Benzhu Xu. Raster-to-graph: Floorplan recog- nition via autoregressive graph prediction with an attention transformer. InComputer Graphics Forum, page e15007. Wiley Online Library, 2024. 2, 5, 6, 14, 18
work page 2024
-
[17]
Cubicasa5k: A dataset and an improved multi-task model for floorplan image analysis
Ahti Kalervo, Juha Ylioinas, Markus Häikiö, Antti Karhu, and Juho Kannala. Cubicasa5k: A dataset and an improved multi-task model for floorplan image analysis. InImage Anal- ysis: 21st Scandinavian Conference, SCIA 2019, Norrköping, Sweden, June 11–13, 2019, Proceedings 21, pages 28–40. Springer, 2019. 1, 5, 14, 17
work page 2019
-
[18]
Instance seg- mentation with mask-supervised polygonal boundary trans- formers
Justin Lazarow, Weijian Xu, and Zhuowen Tu. Instance seg- mentation with mask-supervised polygonal boundary trans- formers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4382–4391,
-
[19]
Jun Li, Kai Xu, Siddhartha Chaudhuri, Ersin Yumer, Hao Zhang, and Leonidas Guibas. Grass: Generative recursive autoencoders for shape structures.ACM Transactions on Graphics (TOG), 36(4):1–14, 2017. 3
work page 2017
-
[20]
Manyi Li, Akshay Gadi Patil, Kai Xu, Siddhartha Chaud- huri, Owais Khan, Ariel Shamir, Changhe Tu, Baoquan Chen, Daniel Cohen-Or, and Hao Zhang. Grains: Generative recur- sive autoencoders for indoor scenes.ACM Transactions on Graphics (TOG), 38(2):1–16, 2019. 3
work page 2019
-
[21]
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024. 4
work page 2024
-
[22]
Rent3d: Floor-plan priors for monocular layout estimation
Chenxi Liu, Alexander G Schwing, Kaustav Kundu, Raquel Urtasun, and Sanja Fidler. Rent3d: Floor-plan priors for monocular layout estimation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3413–3421, 2015. 1
work page 2015
-
[23]
Raster-to-vector: Revisiting floorplan transformation
Chen Liu, Jiajun Wu, Pushmeet Kohli, and Yasutaka Fu- rukawa. Raster-to-vector: Revisiting floorplan transformation. InProceedings of the IEEE International Conference on Com- puter Vision, pages 2195–2203, 2017. 2
work page 2017
-
[24]
Floornet: A uni- fied framework for floorplan reconstruction from 3d scans
Chen Liu, Jiaye Wu, and Yasutaka Furukawa. Floornet: A uni- fied framework for floorplan reconstruction from 3d scans. In Proceedings of the European conference on computer vision (ECCV), pages 201–217, 2018. 2
work page 2018
-
[25]
Polyformer: Referring image segmentation as sequential polygon gener- ation
Jiang Liu, Hui Ding, Zhaowei Cai, Yuting Zhang, Ravi Kumar Satzoda, Vijay Mahadevan, and R Manmatha. Polyformer: Referring image segmentation as sequential polygon gener- ation. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 18653–18663,
-
[26]
PolyRoom: Room-aware Transformer for Floorplan Reconstruction
Yuzhou Liu, Lingjie Zhu, Xiaodong Ma, Hanqiao Ye, Xi- ang Gao, Xianwei Zheng, and Shuhan Shen. PolyRoom: Room-aware Transformer for Floorplan Reconstruction. In European Conference on Computer Vision, 2024. 2, 14, 18
work page 2024
-
[27]
A system to detect rooms in architectural floor plan images
Sébastien Macé, Hervé Locteau, Ernest Valveny, and Salva- tore Tabbone. A system to detect rooms in architectural floor plan images. InProceedings of the 9th IAPR International Workshop on Document Analysis Systems, pages 167–174,
-
[28]
The 3d jigsaw puzzle: Mapping large indoor spaces
Ricardo Martin-Brualla, Yanling He, Bryan C Russell, and Steven M Seitz. The 3d jigsaw puzzle: Mapping large indoor spaces. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Pro- ceedings, Part III 13, pages 1–16. Springer, 2014. 1
work page 2014
-
[29]
Recurrent neural network based language model
Tomáš Mikolov, Martin Karafiát, Lukáš Burget, JanˇCernocký, and Sanjeev Khudanpur. Recurrent neural network based language model. InInterspeech 2010, pages 1045–1048,
work page 2010
-
[30]
Seeing the un-scene: Learning amodal semantic maps for room navigation
Medhini Narasimhan, Erik Wijmans, Xinlei Chen, Trevor Darrell, Dhruv Batra, Devi Parikh, and Amanpreet Singh. Seeing the un-scene: Learning amodal semantic maps for room navigation. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16, pages 513–529. Springer, 2020. 1
work page 2020
-
[31]
Nguyen, Yiwen Chen, Vikram V oleti, Varun Jam- pani, and Huaizu Jiang
Hieu T Nguyen, Yiwen Chen, Vikram V oleti, Varun Jam- pani, and Huaizu Jiang. Housecrafter: Lifting floorplans to 3d scenes with 2d diffusion model.arXiv preprint arXiv:2406.20077, 2024. 1
-
[32]
Despoina Paschalidou, Amlan Kar, Maria Shugrina, Karsten Kreis, Andreas Geiger, and Sanja Fidler. Atiss: Autoregres- sive transformers for indoor scene synthesis.Advances in Neural Information Processing Systems, 34:12013–12026,
-
[33]
Read: Recursive autoencoders for document layout generation
Akshay Gadi Patil, Omri Ben-Eliezer, Or Perel, and Hadar Averbuch-Elor. Read: Recursive autoencoders for document layout generation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Workshops, pages 544–545, 2020. 3
work page 2020
-
[34]
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shiv- ani Agrawal, and Jeff Dean. Efficiently scaling transformer inference.Proceedings of Machine Learning and Systems, 5: 606–624, 2023. 15
work page 2023
-
[35]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational confer- ence on machine learning, pages 8821–8831. Pmlr, 2021. 3
work page 2021
-
[36]
Conditional 360-degree image synthesis for immersive indoor scene decoration
Ka Chun Shum, Hong-Wing Pang, Binh-Son Hua, Duc Thanh Nguyen, and Sai-Kit Yeung. Conditional 360-degree image synthesis for immersive indoor scene decoration. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 4478–4488, 2023. 1
work page 2023
-
[37]
Montefloor: Extending mcts for reconstruct- ing accurate large-scale floor plans
Sinisa Stekovic, Mahdi Rad, Friedrich Fraundorfer, and Vin- cent Lepetit. Montefloor: Extending mcts for reconstruct- ing accurate large-scale floor plans. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16034–16043, 2021. 2, 3, 6, 14, 18
work page 2021
-
[38]
Jiahui Sun, Wenming Wu, Ligang Liu, Wenjie Min, Gaofeng Zhang, and Liping Zheng. Wallplan: synthesizing floorplans by learning to generate wall graphs.ACM Transactions on Graphics (TOG), 41(4):1–14, 2022. 2, 3
work page 2022
-
[39]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014. 3
work page 2014
-
[40]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 4, 15
work page 2017
-
[41]
Show and tell: A neural image caption generator
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3156–3164, 2015. 3
work page 2015
-
[42]
Lost shopping! monocular localization in large indoor spaces
Shenlong Wang, Sanja Fidler, and Raquel Urtasun. Lost shopping! monocular localization in large indoor spaces. In Proceedings of the IEEE International Conference on Com- puter Vision, pages 2695–2703, 2015. 1
work page 2015
-
[43]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21469–21480, 2025. 7
work page 2025
-
[44]
Fri-net: Floorplan reconstruction via room-wise implicit representation
Honghao Xu, Juzhan Xu, Zeyu Huang, Pengfei Xu, Hui Huang, and Ruizhen Hu. Fri-net: Floorplan reconstruction via room-wise implicit representation. InECCV, 2024. 2, 6, 18
work page 2024
-
[45]
Show, attend and tell: Neural image caption gener- ation with visual attention
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption gener- ation with visual attention. InInternational conference on machine learning, pages 2048–2057. PMLR, 2015. 3
work page 2048
-
[46]
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gun- jan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yin- fei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation.Transactions on Machine Learning Research, 2022. ...
work page 2022
-
[47]
Connecting the dots: Floorplan reconstruction using two-level queries
Yuanwen Yue, Theodora Kontogianni, Konrad Schindler, and Francis Engelmann. Connecting the dots: Floorplan reconstruction using two-level queries. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 845–854, 2023. 2, 5, 6, 14, 18
work page 2023
-
[48]
Deep floor plan recognition using a multi-task network with room-boundary-guided attention
Zhiliang Zeng, Xianzhi Li, Ying Kin Yu, and Chi-Wing Fu. Deep floor plan recognition using a multi-task network with room-boundary-guided attention. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9096–9104, 2019. 2, 3
work page 2019
-
[49]
Sceneex- pander: Real-time scene synthesis for interactive floor plan editing
Shao-Kui Zhang, Junkai Huang, Liang Yue, Jia-Tong Zhang, Jia-Hong Liu, Yu-Kun Lai, and Song-Hai Zhang. Sceneex- pander: Real-time scene synthesis for interactive floor plan editing. InProceedings of the 32nd ACM International Con- ference on Multimedia, pages 6232–6240, 2024. 1 12
work page 2024
-
[50]
Structured3d: A large photo-realistic dataset for structured 3d modeling
Jia Zheng, Junfei Zhang, Jing Li, Rui Tang, Shenghua Gao, and Zihan Zhou. Structured3d: A large photo-realistic dataset for structured 3d modeling. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16, pages 519–535. Springer,
work page 2020
-
[51]
Deformable {detr}: Deformable transformers for end-to-end object detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable {detr}: Deformable transformers for end-to-end object detection. InInternational Conference on Learning Representations, 2021. 2, 4, 14 13 (a) Density map (b) Floorplan map (c) Output binary image Figure 13. Binary image conversion on Structured3D data. Using the annotated ...
work page 2021
-
[52]
The highlighted row for length 512 corresponds to the best-performing configuration, indicating that it strikes a sweet spot for capturing structural and geometric details in floorplans effectively. Coordinate coefficient.Table 16 presents an ablation study on the coordinate loss coefficient. In this experiment, we fix the token loss coefficient at 1 to i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.