Recognition: no theorem link
HLGFA: High-Low Resolution Guided Feature Alignment for Unsupervised Anomaly Detection
Pith reviewed 2026-05-16 02:56 UTC · model grok-4.3
The pith
High-low resolution feature alignment detects anomalies where consistency between detailed and coarse views breaks down.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HLGFA learns normality by modeling cross-resolution feature consistency: high-resolution inputs are decomposed into structure and detail priors that guide refinement of low-resolution features via conditional modulation and gated residual correction, so that anomalies are identified exactly where the alignment between the two resolutions collapses.
What carries the argument
High-low resolution guided feature alignment, which decomposes high-resolution features into structure and detail priors to conditionally modulate and correct low-resolution features.
If this is right
- Anomalies are detected directly as alignment failures rather than reconstruction errors.
- The same frozen backbone serves both resolutions, reducing training overhead.
- Noise-aware augmentation suppresses responses from common industrial background variations.
- The framework outperforms prior reconstruction-based and feature-based methods on standard benchmarks.
Where Pith is reading between the lines
- The same consistency principle could be tested on video sequences where temporal alignment across scales replaces spatial resolution.
- One could replace the fixed dual-resolution split with content-adaptive resolution pairs chosen per image.
- The approach implies that normality may be definable as multi-scale invariance in other domains such as medical imaging.
Load-bearing premise
Anomalies will reliably break the cross-resolution feature alignment that normal samples preserve, and the structure-detail decomposition will transfer to unseen industrial images.
What would settle it
A collection of defective samples in which the high-resolution and low-resolution features remain as aligned as those of normal samples, causing the detector to miss them.
Figures
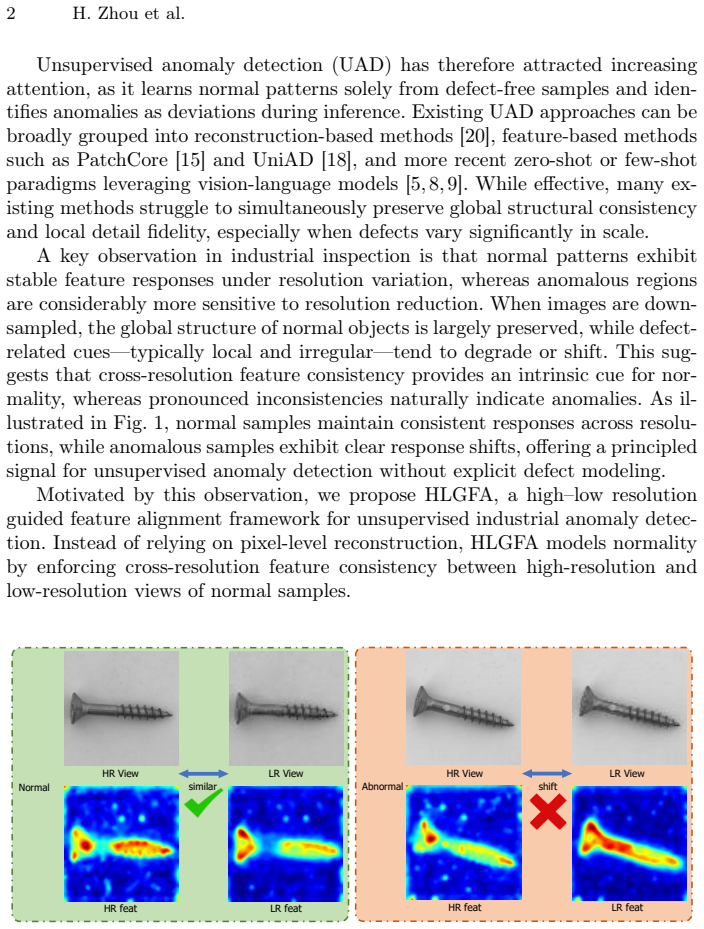




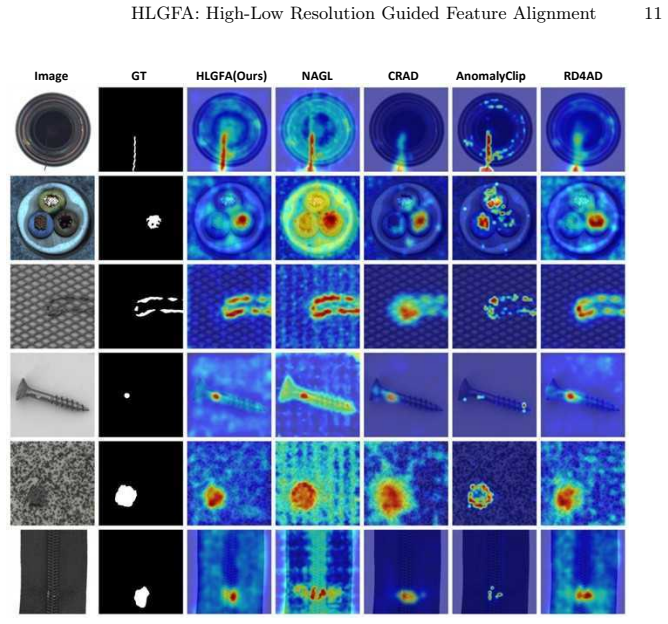
read the original abstract
Unsupervised industrial anomaly detection (UAD) is essential for modern manufacturing inspection, where defect samples are scarce and reliable detection is required. In this paper, we propose HLGFA, a high-low resolution guided feature alignment framework that learns normality by modeling cross-resolution feature consistency between high-resolution and low-resolution representations of normal samples, instead of relying on pixel-level reconstruction. Dual-resolution inputs are processed by a shared frozen backbone to extract multi-level features, and high-resolution representations are decomposed into structure and detail priors to guide the refinement of low-resolution features through conditional modulation and gated residual correction. During inference, anomalies are naturally identified as regions where cross-resolution alignment breaks down. In addition, a noise-aware data augmentation strategy is introduced to suppress nuisance-induced responses commonly observed in industrial environments. Extensive experiments on standard benchmarks demonstrate the effectiveness of HLGFA, achieving 97.9% pixel-level AUROC and 97.5% image-level AUROC on the MVTec AD dataset, outperforming representative reconstruction-based and feature-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HLGFA, a high-low resolution guided feature alignment framework for unsupervised anomaly detection in industrial images. Dual-resolution inputs are fed to a shared frozen backbone; high-resolution features are decomposed into structure and detail priors that guide refinement of low-resolution features via conditional modulation and gated residual correction. Anomalies are identified at inference as locations where this cross-resolution consistency breaks down. A noise-aware augmentation is added to suppress nuisance responses. The method reports 97.9% pixel-level AUROC and 97.5% image-level AUROC on MVTec AD, outperforming representative reconstruction- and feature-based baselines.
Significance. If the core mechanism is validated, the approach offers a reconstruction-free consistency signal that could be more stable than pixel-level reconstruction in noisy industrial settings. The reported AUROCs are competitive with current state-of-the-art on MVTec AD, suggesting potential practical impact for manufacturing inspection pipelines.
major comments (2)
- [Abstract] Abstract: the central claim that anomalies are identified because 'cross-resolution alignment breaks down' after structure-detail decomposition and conditional modulation is load-bearing yet unsupported by any equation, derivation, or preliminary visualization; without this, the 97.9/97.5 AUROC could be driven by backbone strength rather than the proposed guidance (see skeptic note on anomaly sensitivity of the priors).
- [Abstract] Abstract (method description): no ablation, error bars, or implementation details are supplied to isolate the contribution of the gated residual correction versus the frozen backbone or the noise-aware augmentation; this prevents verification that the alignment signal is selectively violated by defects rather than by normal texture variation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying the core mechanism and validating component contributions. We will revise the manuscript to strengthen the abstract and method description with additional equations, visualizations, ablations, and implementation details as outlined below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that anomalies are identified because 'cross-resolution alignment breaks down' after structure-detail decomposition and conditional modulation is load-bearing yet unsupported by any equation, derivation, or preliminary visualization; without this, the 97.9/97.5 AUROC could be driven by backbone strength rather than the proposed guidance (see skeptic note on anomaly sensitivity of the priors).
Authors: We agree that the abstract requires explicit support for the load-bearing claim. In the revision we will insert a concise equation defining the cross-resolution consistency loss after conditional modulation and gated residual correction, along with a short derivation showing how deviations in the refined low-resolution features quantify anomaly scores. We will also add a preliminary visualization (new Figure 2) comparing alignment maps on normal samples versus defective ones to demonstrate selective breakdown. Since the backbone is frozen and shared, the guidance from high-resolution structure/detail priors is the active mechanism; we will clarify this distinction in Section 3 and reference ablation results showing performance degradation without the priors. revision: yes
-
Referee: [Abstract] Abstract (method description): no ablation, error bars, or implementation details are supplied to isolate the contribution of the gated residual correction versus the frozen backbone or the noise-aware augmentation; this prevents verification that the alignment signal is selectively violated by defects rather than by normal texture variation.
Authors: The full manuscript already contains ablation studies (Section 4.3) and implementation details (Section 4.1), but we acknowledge these are insufficiently highlighted in the abstract and lack error bars. In the revision we will expand the abstract to summarize key ablation outcomes, add standard-error bars to all reported AUROCs, and include a new table isolating the gated residual correction. We will further add quantitative analysis (new subsection 4.4) measuring alignment consistency under controlled normal texture variations versus defects to confirm selectivity. Implementation details will be moved to a dedicated appendix for clarity. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and description outline a method that extracts features via a shared frozen backbone, decomposes high-resolution inputs into structure and detail priors, applies conditional modulation plus gated residual correction to align with low-resolution features, and detects anomalies where cross-resolution consistency breaks. Alignment loss is defined externally rather than fitted to the target metric, and no equations, self-citations, or uniqueness theorems are shown that would reduce any prediction or central claim to its own inputs by construction. The approach is tested on external benchmarks (MVTec AD) with reported AUROC gains over baselines, keeping the derivation self-contained and independent of the evaluated quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Normal samples maintain cross-resolution feature consistency while anomalies disrupt it
Reference graph
Works this paper leans on
-
[1]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad — a comprehen- sive real-world dataset for unsupervised anomaly detection. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9584–9592 (2019).https://doi.org/10.1109/CVPR.2019.00982
- [2]
- [3]
-
[4]
Defard, T., Setkov, A., Loesch, A., Audigier, R.: Padim: a patch distribution mod- eling framework for anomaly detection and localization (2020),https://arxiv. org/abs/2011.08785
- [5]
-
[6]
Gong, D., Liu, L., Le, V., Saha, B., Mansour, M.R., Venkatesh, S., van den Hengel, A.: Memorizing normality to detect anomaly: Memory-augmented deep autoen- coder for unsupervised anomaly detection (2019),https://arxiv.org/abs/1904. 02639
work page 2019
-
[7]
Densely Connected Convolutional Networks
Huang, G., Liu, Z., Weinberger, K.Q.: Densely connected convolutional networks. CoRRabs/1608.06993(2016),http://arxiv.org/abs/1608.06993
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Jeong, J., Zou, Y., Kim, T., Zhang, D., Ravichandran, A., Dabeer, O.: Winclip: Zero-/few-shot anomaly classification and segmentation (2023),https://arxiv. org/abs/2303.14814
- [9]
- [10]
- [11]
- [12]
- [13]
-
[14]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
CoRRabs/2106.08265(2021), https://arxiv.org/abs/2106.08265
Roth, K., Pemula, L., Zepeda, J., Schölkopf, B., Brox, T., Gehler, P.V.: To- wards total recall in industrial anomaly detection. CoRRabs/2106.08265(2021), https://arxiv.org/abs/2106.08265
-
[16]
Schwartz, E., Arbelle, A., Karlinsky, L., Harary, S., Scheidegger, F., Doveh, S., Giryes, R.: Maeday: Mae for few and zero shot anomaly-detection (2024),https: //arxiv.org/abs/2211.14307 16 H. Zhou et al
- [17]
- [18]
-
[19]
Zagoruyko, S., Komodakis, N.: Wide residual networks. CoRRabs/1605.07146 (2016),http://arxiv.org/abs/1605.07146
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Pattern Recognition112, 107706 (2021).https://doi.org/ 10.1016/j.patcog.2020.107706
Zavrtanik, V., Kristan, M., Skočaj, D.: Reconstruction by inpainting for visual anomaly detection. Pattern Recognition112, 107706 (2021).https://doi.org/ 10.1016/j.patcog.2020.107706
- [21]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.