Recognition: no theorem link
SERNF: Sample-Efficient Real-World Dexterous Policy Fine-Tuning via Action-Chunked Critics and Normalizing Flows
Pith reviewed 2026-05-16 03:28 UTC · model grok-4.3
The pith
SERNF achieves sample-efficient real-world fine-tuning of multimodal dexterous policies by pairing exact-likelihood normalizing flow policies with action-chunked value critics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
To our knowledge, this is the first demonstration of a likelihood-based, multimodal generative policy combined with chunk-level value learning on real robotic hardware.
Load-bearing premise
That normalizing flows can be trained to produce stable, exact likelihoods for multimodal action chunks under real-world noise and limited samples, and that the action-chunked critic will produce value estimates that align with the policy's temporal execution without introducing bias.
Figures









read the original abstract
Real-world fine-tuning of dexterous manipulation policies remains challenging due to limited real-world interaction budgets and highly multimodal action distributions. Diffusion-based policies, while expressive, do not permit conservative likelihood-based updates during fine-tuning because action probabilities are intractable. In contrast, conventional Gaussian policies collapse under multimodality, particularly when actions are executed in chunks, and standard per-step critics fail to align with chunked execution, leading to poor credit assignment. We present SERFN, a sample-efficient off-policy fine-tuning framework with normalizing flow (NF) to address these challenges. The normalizing flow policy yields exact likelihoods for multimodal action chunks, allowing conservative, stable policy updates through likelihood regularization and thereby improving sample efficiency. An action-chunked critic evaluates entire action sequences, aligning value estimation with the policy's temporal structure and improving long-horizon credit assignment. To our knowledge, this is the first demonstration of a likelihood-based, multimodal generative policy combined with chunk-level value learning on real robotic hardware. We evaluate SERFN on two challenging dexterous manipulation tasks in the real world: cutting tape with scissors retrieved from a case, and in-hand cube rotation with a palm-down grasp -- both of which require precise, dexterous control over long horizons. On these tasks, SERFN achieves stable, sample-efficient adaptation where standard methods struggle.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Normalizing flows yield exact likelihoods for multimodal action distributions in robotic control settings
- domain assumption Action-chunked critics provide better credit assignment than per-step critics for chunked execution
Reference graph
Works this paper leans on
-
[1]
Dmitriy Akimov, Vladislav Kurenkov, Alexander Nikulin, Denis Tarasov, and Sergey Kolesnikov. Let offline rl flow: Training conservative agents in the latent space of normalizing flows.arXiv preprint arXiv:2211.11096, 2022
-
[2]
Policyflow: Policy optimization with con- tinuous normalizing flow in reinforcement learning
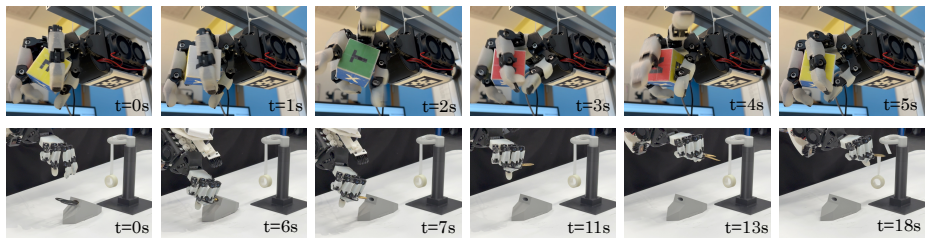
Anonymous. Policyflow: Policy optimization with con- tinuous normalizing flow in reinforcement learning. t=0st=1st=2st=3st=4st=5s t=0st=6st=7st=11st=13st=18s Fig. 6. Qualitative rollouts of SERNF on real hardware. Top: scissors retrieval and tape cutting task, showing grasp acquisition, lifting, and successful cutting. Bottom: in-hand cube rotation task, ...
work page 2025
-
[3]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
work page 2023
-
[4]
Alex Beeson and Giovanni Montana. Improving td3-bc: Relaxed policy constraint for offline learning and stable online fine-tuning.arXiv preprint arXiv:2211.11802, 2022
-
[5]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi ”Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision- language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Kevin Black, Allen Z Ren, Michael Equi, and Sergey Levine. Training-time action conditioning for efficient real-time chunking.arXiv preprint arXiv:2512.05964, 2025
-
[9]
Chen-Hao Chao, Chien Feng, Wei-Fang Sun, Cheng- Kuang Lee, Simon See, and Chun-Yi Lee. Maximum entropy reinforcement learning via energy-based normal- izing flow.Advances in Neural Information Processing Systems, 37:56136–56165, 2024
work page 2024
-
[11]
Clemens C. Christoph, Maximilian Eberlein, Filippos Katsimalis, Arturo Roberti, Aristotelis Sympetheros, Michel R. V ogt, Davide Liconti, Chenyu Yang, Barn- abas Gavin Cangan, Ronan J. Hinchet, and Robert K. Katzschmann. Orca: An open-source, reliable, cost- effective, anthropomorphic robotic hand for uninter- rupted dexterous task learning, 2025. URL htt...
-
[12]
The ingredients for robotic diffusion transformers
Sudeep Dasari, Oier Mees, Sebastian Zhao, Mohan Ku- mar Srirama, and Sergey Levine. The ingredients for robotic diffusion transformers. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 15617–15625. IEEE, 2025
work page 2025
-
[13]
Density estimation using Real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Ben- gio. Density estimation using real nvp.arXiv preprint arXiv:1605.08803, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
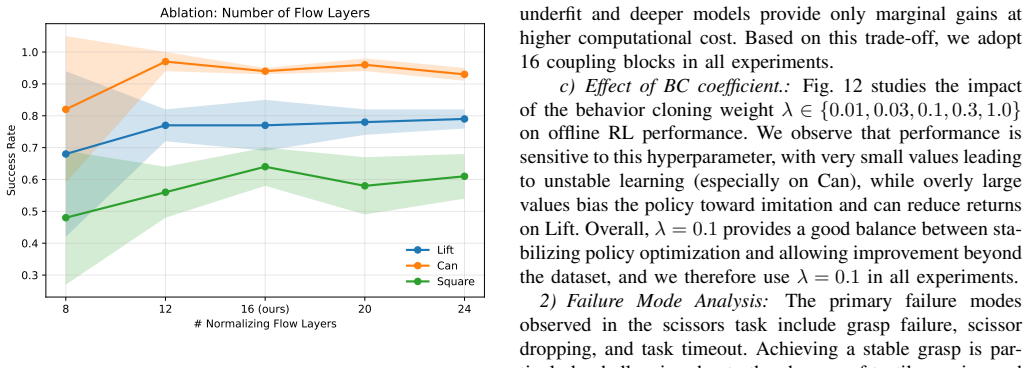
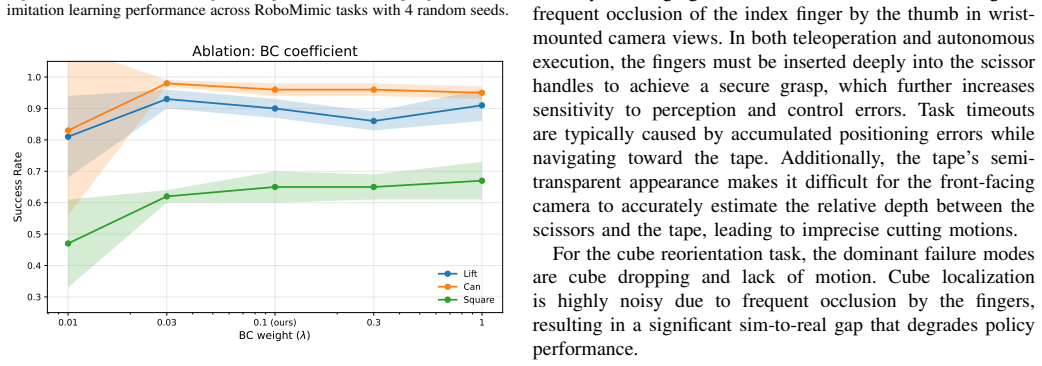
-
[14]
Hyperparameters in reinforcement learning and how to tune them
Theresa Eimer, Marius Lindauer, and Roberta Raileanu. Hyperparameters in reinforcement learning and how to tune them. InInternational conference on machine learning, pages 9104–9149. PMLR, 2023
work page 2023
-
[15]
Jesse Farebrother, Jordi Orbay, Quan Vuong, Adrien Ali Ta¨ıga, Yevgen Chebotar, Ted Xiao, Alex Irpan, Sergey Levine, Pablo Samuel Castro, Aleksandra Faust, et al. Stop regressing: Training value functions via clas- sification for scalable deep rl.arXiv preprint arXiv:2403.03950, 2024
-
[16]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[17]
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021
work page 2021
-
[18]
Normalizing flows are capable models for RL.CoRR, abs/2505.23527,
Raj Ghugare and Benjamin Eysenbach. Normalizing flows are capable models for RL.CoRR, abs/2505.23527,
-
[20]
Dextreme: Transfer of agile in-hand manipulation from simulation to reality
Ankur Handa, Arthur Allshire, Viktor Makoviychuk, Aleksei Petrenko, Ritvik Singh, Jingzhou Liu, Denys Makoviichuk, Karl Van Wyk, Alexander Zhurkevich, Balakumar Sundaralingam, et al. Dextreme: Transfer of agile in-hand manipulation from simulation to reality. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5977–5984. IEEE, 2023
work page 2023
-
[21]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. corr abs/1512.03385 (2015), 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
Imitation bootstrapped reinforcement learning.arXiv preprint arXiv:2311.02198, 2023
Hengyuan Hu, Suvir Mirchandani, and Dorsa Sadigh. Imitation bootstrapped reinforcement learning.arXiv preprint arXiv:2311.02198, 2023
-
[23]
Improving regres- sion performance with distributional losses
Ehsan Imani and Martha White. Improving regres- sion performance with distributional losses. InInter- national conference on machine learning, pages 2157–
-
[24]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ash- win Balakrishna, Kevin Black, Ken Conley, Grace Con- nors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al.π ∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Learning stable normalizing-flow control for robotic manipulation
Shahbaz Abdul Khader, Hang Yin, Pietro Falco, and Danica Kragic. Learning stable normalizing-flow control for robotic manipulation. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 1644–1650. IEEE, 2021
work page 2021
-
[27]
Jet: A modern transformer-based normalizing flow.arXiv preprint arXiv:2412.15129, 2024
Alexander Kolesnikov, Andr ´e Susano Pinto, and Michael Tschannen. Jet: A modern transformer-based normalizing flow.arXiv preprint arXiv:2412.15129, 2024
-
[28]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[30]
Normalizing flows are capable visuo- motor policy learning models.CoRR, abs/2509.21073,
Simon Kristoffersson Lind, Jialong Li, Maj Stenmark, and V olker Kr¨uger. Normalizing flows are capable visuo- motor policy learning models.CoRR, abs/2509.21073,
-
[32]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
SERL: A software suite for sample-efficient robotic reinforcement learn- ing
Jianlan Luo, Zheyuan Hu, Charles Xu, You Liang Tan, Jacob Berg, Archit Sharma, Stefan Schaal, Chelsea Finn, Abhishek Gupta, and Sergey Levine. SERL: A software suite for sample-efficient robotic reinforcement learn- ing. InIEEE International Conference on Robotics and Automation, ICRA 2024, Yokohama, Japan, May 13-17, 2024, pages 16961–16969. IEEE, 2024. ...
-
[34]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart ´ın-Mart´ın. What matters in learning from offline human demon- strations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Leveraging exploration in off-policy algorithms via normalizing flows
Bogdan Mazoure, Thang Doan, Audrey Durand, Joelle Pineau, and R Devon Hjelm. Leveraging exploration in off-policy algorithms via normalizing flows. InConfer- ence on Robot Learning, pages 430–444. PMLR, 2020
work page 2020
-
[37]
Takahiro Miki, Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning robust perceptive locomotion for quadrupedal robots in the wild.Science robotics, 7(62):eabk2822, 2022
work page 2022
-
[38]
Carlson, Ji Yuan Feng, Ani- mesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren ´e Zurbr ¨ugg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Hei- den, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Ani- mesh Garg, Renato Gasoto, Lionel Gulich, Yijie...
-
[39]
URL https://arxiv.org/abs/2511.04831
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforce- ment learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[41]
Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning.Advances in Neural Information Processing Systems, 36:62244–62269, 2023
work page 2023
-
[42]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Ogbench: Benchmarking offline goal- conditioned rl.arXiv preprint arXiv:2410.20092, 2024
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal- conditioned rl.arXiv preprint arXiv:2410.20092, 2024
-
[44]
Allen Z. Ren, Justin Lidard, Anthony Simeonov, Lars Lien Ankile, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net, 2025. URL https://openreview.net/for...
work page 2025
-
[45]
Variational infer- ence with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational infer- ence with normalizing flows. InInternational conference on machine learning, pages 1530–1538. PMLR, 2015
work page 2015
-
[46]
Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
Clemens Schwarke, Mayank Mittal, Nikita Rudin, David Hoeller, and Marco Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
-
[47]
Aravind Sivakumar, Kenneth Shaw, and Deepak Pathak. Robotic telekinesis: Learning a robotic hand imita- tor by watching humans on youtube.arXiv preprint arXiv:2202.10448, 2022
-
[48]
Laura Smith, Ilya Kostrikov, and Sergey Levine. A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning.arXiv preprint arXiv:2208.07860, 2022
-
[49]
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist ap- proach to offline reinforcement learning.Advances in Neural Information Processing Systems, 36:11592– 11620, 2023
work page 2023
-
[50]
Denis Tarasov, Alexander Nikulin, Dmitry Akimov, Vladislav Kurenkov, and Sergey Kolesnikov. Corl: Research-oriented deep offline reinforcement learning library.Advances in Neural Information Processing Systems, 36:30997–31020, 2023
work page 2023
-
[51]
Denis Tarasov, Kirill Brilliantov, and Dmitrii Khar- lapenko. Is value functions estimation with classification plug-and-play for offline reinforcement learning?arXiv preprint arXiv:2406.06309, 2024
-
[52]
Denis Tarasov, Anja Surina, and Caglar Gulcehre. The role of deep learning regularizations on actors in offline rl.arXiv preprint arXiv:2409.07606, 2024
-
[53]
Nina: Normalizing flows in action
Denis Tarasov, Alexander Nikulin, Ilya Zisman, Albina Klepach, Nikita Lyubaykin, Andrei Polubarov, Alexander Derevyagin, and Vladislav Kurenkov. Nina: Normalizing flows in action. training vla models with normalizing flows.arXiv preprint arXiv:2508.16845, 2025
-
[54]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy. CoRR, abs/2403.03954, 2024. doi: 10.48550/ARXIV . 2403.03954. URL https://doi.org/10.48550/arXiv.2403. 03954
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[55]
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Re- inflow: Fine-tuning flow matching policy with online re- inforcement learning.arXiv preprint arXiv:2505.22094, 2025
-
[57]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017. 1 2 3 4 5 6 7 8 9 10 11 Obs. Prefix Actions Action Chunks b) in-hand cube rotation 1 2 3 4 5 6 7 8 9 10 11 Next Obs. Next Prefix Actions a) scissor ret...
work page 2017
-
[59]
Experimental Setup Details:We mount the Orca Hand
-
[60]
on a Franka Emika Panda robot using a custom 3D- printed mount with a 60-degree tilt. Two OAK-1 Lite cameras are attached to the mount: one positioned underneath the hand to enable accurate finger placement, and the other facing left to provide visual guidance during scissor manipulation. The third camera is an OAK-D Lite that provides a front view. We us...
-
[61]
Teleoperation and Data Collection:Expert demonstra- tions are collected using Rokoko Smart Gloves in combination with the Rokoko Coil Pro, which together provide finger motion capture and wrist pose estimation in 3D space. Human finger postures are retargeted to the robotic hand joint angles using an energy-based retargeting method [44]. All demonstration...
-
[62]
Action Chunking and Real-Time Inference Implementa- tion:As shown in Fig. 7, the policy uses 1 step of observation and 3 steps of prefix actions following the observation and predicts a subsequent chunk of 10 steps of actions. The observations contain the RGB images, the joint positions of the hand, and the end effector pose of Franka. The actions are rep...
-
[63]
Test Configurations:We evaluate all policies under a fixed set of predefined test configurations. Specifically, we define 2 distinct test positions for the scissors and 5 distinct test positions for the tape holder. A total of 10 combinations can be seen in Fig. 8. For each evaluation episode, a test configuration is sampled from the predefined set. The l...
-
[64]
Both the training and the inference runs on a desktop with NVIDIA RTX 4090 GPU
Experimental Setup Details:We mount the Orca Hand [11] horizontally with an OAK-D Lite camera providing the view from the bottom. Both the training and the inference runs on a desktop with NVIDIA RTX 4090 GPU
-
[65]
Cube Pose Estimation:We use an OAK-D Lite camera mounted approximately 30 cm below the hand holding the cube. To estimate the cube pose, which is provided as input to the policy, we follow the same approach as in [19]. We Fig. 9. Examples of synthetic training samples. Images are rendered during parallelized IsaacLab training with randomized camera poses,...
-
[66]
Action Chunking and Real-Time Inference Implementa- tion:As shown in Fig. 7, at each decision step, the policy receives as input a history of four timesteps of joint posi- tions, cube position, and cube orientation (represented as a quaternion), as well as one timestep of the previous action and the previous joint position command. The goal command is als...
-
[67]
Teacher Policy Training:We train the teacher policy fully in simulation using IsaacLab, in an environment that models single-axis spinning of a 45 mm cube with the Orca hand. a) Simulation setup.:Each environment instance con- tains an Orca hand and a rigid cube object placed above a small kinematic platform. The platform provides support for the first 6 ...
-
[68]
We follow the principle as in [35], with adaptation to chunked actions
Policy Distillation Procedure:We distill a PPO-trained teacher policy into the SERNF model using IsaacLab. We follow the principle as in [35], with adaptation to chunked actions. During distillation, we applied strong observation noise to the student to improve the robustness. This noise consists of additive Gaussian noise and a random offset that is rese...
-
[69]
Network Architectures: Visual Encoders •ResNet-18 (Robomimic).Two separate ResNet-18 back- bones are used forimg0andimg1. Each encoder follows the standard torchvision ResNet-18 up to the last convolutional stage (no global average pooling and no FC classifier). Activation: ReLU. Normalization: Batch- Norm2d. Image normalization uses ImageNet mean/std ins...
-
[70]
Additional hyperparameters values:We apply dropout forπ θ regularization, using a rate of 0.5 during policy initial- ization (reduced to 0.2 for real-world experiments to accelerate convergence under limited compute). During reinforcement learning, the dropout rate is reduced to 0.1, as higher values were found to degrade offline RL performance, while a s...
-
[71]
Baseline Implementation Details:We compare SERNF against strong baseline methods to evaluate the expressiveness and accuracy of our approach in the imitation learning setting. To ensure a fair comparison, the dataset, optimizer settings, data augmentation strategies, and image encoders are kept identical across all methods. a) Action Chunking Transformer:...
work page 2048
-
[72]
Ablation Studies:We conduct ablation studies to analyze the sensitivity of SERNF to key architectural and algorithmic design choices. The ablations in this subsection are per- formed on simulated RoboMimic environments (Lift, Can, and Square). a) Effect of action chunk length.:Fig. 10 shows the effect of varying the action chunk lengthH∈ {6,8,10,12,14}. A...
-
[73]
Failure Mode Analysis:The primary failure modes observed in the scissors task include grasp failure, scissor dropping, and task timeout. Achieving a stable grasp is par- ticularly challenging due to the absence of tactile sensing and frequent occlusion of the index finger by the thumb in wrist- mounted camera views. In both teleoperation and autonomous ex...
-
[74]
Simulation experiments were carried out on NVIDIA TITAN RTX GPUs. GPUs were utilized at full capacity to accelerate training and inference; however, all stages can be executed on less powerful hardware by reducing batch sizes or the number of sampled candidate actions during policy evaluation. For the scissors task, imitation learning pretraining required...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.