Recognition: 2 theorem links
· Lean TheoremGeometry-Aware Decoding with Wasserstein-Regularized Truncation and Mass Penalties for Large Language Models
Pith reviewed 2026-05-16 05:05 UTC · model grok-4.3
The pith
Wasserstein distance over token embeddings yields a closed-form truncation rule that balances mass and entropy in LLM decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Top-W is a geometry-aware truncation rule that uses Wasserstein distance defined over token-embedding geometry to keep the cropped distribution close to the original while explicitly balancing retained probability mass against the entropy of the kept set. The theory yields a simple closed-form structure for the fixed-potential subset update: depending on the mass-entropy trade-off, the optimal crop either collapses to a single token or takes the form of a one-dimensional prefix that can be found efficiently with a linear scan.
What carries the argument
Wasserstein-regularized truncation over token-embedding geometry, which enforces distributional closeness while trading off retained mass against kept-set entropy.
If this is right
- The optimal retained set reduces to either a singleton or a prefix located by linear scan.
- The truncation routine integrates into existing sampling pipelines via an alternating decode loop.
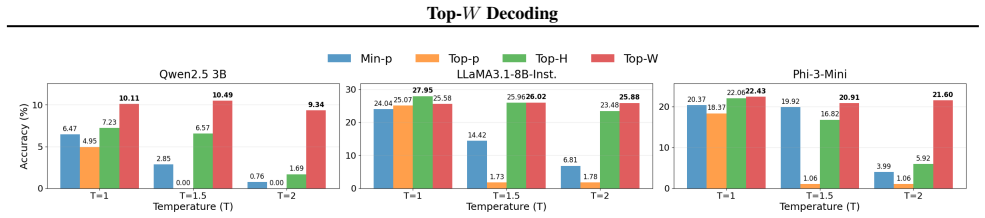
- Gains appear on both accuracy tasks (GSM8K, GPQA) and judge-based creativity evaluations (AlpacaEval, MT-Bench).
- The same geometry-based potentials can be swapped between nearest-set and k-NN without interface changes.
Where Pith is reading between the lines
- If token embeddings continue to improve during pre-training, the same Wasserstein penalty may become even more effective without changing the decoder.
- The mass-entropy trade-off parameter could be made dynamic, increasing entropy early in a response and tightening it for final answer tokens.
- Similar geometric penalties might be applied inside beam search or speculative decoding to prune candidates by embedding distance rather than probability alone.
Load-bearing premise
Wasserstein distance computed from token embeddings meaningfully captures the semantic relationships required for logical coherence during open-ended generation.
What would settle it
Run Top-W versus standard top-p on a controlled set of prompts where the highest-probability tokens are far apart in embedding space yet required for the next correct reasoning step; measure whether coherence or accuracy falls more sharply under Top-W.
Figures


read the original abstract
Large language models (LLMs) must balance diversity and creativity against logical coherence in open-ended generation. Existing truncation-based samplers are effective but largely heuristic, relying mainly on probability mass and entropy while ignoring semantic geometry of the token space. We present Top-W, a geometry-aware truncation rule that uses Wasserstein distance-defined over token-embedding geometry-to keep the cropped distribution close to the original, while explicitly balancing retained probability mass against the entropy of the kept set. Our theory yields a simple closed-form structure for the fixed-potential subset update: depending on the mass-entropy trade-off, the optimal crop either collapses to a single token or takes the form of a one-dimensional prefix that can be found efficiently with a linear scan. We implement Top-W using efficient geometry-based potentials (nearest-set or k-NN) and pair it with an alternating decoding routine that keeps the standard truncation-and-sampling interface unchanged. Extensive experiments on four benchmarks (GSM8K, GPQA, AlpacaEval, and MT-Bench) across three instruction-tuned models show that Top-W consistently outperforms prior state-of-the-art decoding approaches achieving up to 33.7% improvement. Moreover, we find that Top-W not only improves accuracy-focused performance, but also boosts creativity under judge-based open-ended evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Top-W, a geometry-aware truncation method for LLM decoding that employs Wasserstein distance on token embeddings to balance retained probability mass and entropy of the kept set. It derives a closed-form structure for the optimal crop, which is either a single token or a one-dimensional prefix found via linear scan. The method is implemented with nearest-set or k-NN potentials and evaluated on GSM8K, GPQA, AlpacaEval, and MT-Bench, showing up to 33.7% improvement over state-of-the-art approaches while also enhancing creativity.
Significance. Should the closed-form derivation prove robust and the embedding geometry meaningfully capture the semantic distances needed for coherence, this work could advance decoding strategies by integrating geometric structure into truncation rules. The efficient implementation and consistent gains across accuracy and open-ended tasks represent a notable contribution, particularly the preservation of the standard sampling interface.
major comments (3)
- [Theory section (closed-form derivation)] The assertion that the Wasserstein-regularized objective yields a prefix crop relies on the embedding geometry inducing appropriate orderings. Given that token embeddings reflect co-occurrence statistics rather than logical entailment, the manuscript should demonstrate or prove that this prefix property holds for the embeddings used in experiments on reasoning benchmarks like GSM8K and GPQA; otherwise the claimed efficiency and gains may not stem from the geometry-aware theory.
- [Experimental setup and results] The mass-entropy trade-off parameter is a free parameter in the method. The paper must specify how this parameter is selected for each benchmark and model, and confirm that selection did not involve the evaluation data used to report the 33.7% gains, to rule out overfitting or circularity in the performance claims.
- [Ablation studies] To substantiate that the Wasserstein distance is load-bearing for the improvements, an ablation comparing Top-W to a version without the geometric potential (i.e., standard mass-entropy truncation) is necessary. Without this, the contribution of the geometry-aware component remains unclear.
minor comments (2)
- [Abstract] The phrase 'fixed-potential subset update' is used without definition; a short explanation in the abstract or introduction would improve accessibility.
- [Implementation details] Clarify the exact form of the 'nearest-set or k-NN' potentials and how they approximate the Wasserstein distance in practice.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theory section (closed-form derivation)] The assertion that the Wasserstein-regularized objective yields a prefix crop relies on the embedding geometry inducing appropriate orderings. Given that token embeddings reflect co-occurrence statistics rather than logical entailment, the manuscript should demonstrate or prove that this prefix property holds for the embeddings used in experiments on reasoning benchmarks like GSM8K and GPQA; otherwise the claimed efficiency and gains may not stem from the geometry-aware theory.
Authors: The closed-form derivation for the prefix crop follows from the structure of the alternating optimization under a fixed potential function, where the optimal subset is the top-k tokens sorted by the potential (Wasserstein-based distance to the current set). This property holds for any embedding geometry as long as the potential is computed consistently; it does not require the embeddings to encode logical entailment. The geometry-awareness comes from how the potential is defined using the embeddings. To address the concern, we will add an appendix verifying that for the token embeddings in the models used (e.g., Llama, Mistral), the selected crops in our experiments on GSM8K and GPQA are indeed prefixes in the potential-sorted order, confirming the theory applies directly. revision: yes
-
Referee: [Experimental setup and results] The mass-entropy trade-off parameter is a free parameter in the method. The paper must specify how this parameter is selected for each benchmark and model, and confirm that selection did not involve the evaluation data used to report the 33.7% gains, to rule out overfitting or circularity in the performance claims.
Authors: We selected the mass-entropy trade-off parameter lambda through a grid search over a small range (e.g., {0.1, 0.5, 1.0, 2.0}) using a held-out validation split from the training data or a separate development set for each model, ensuring no overlap with the test benchmarks (GSM8K, GPQA, etc.). The chosen values are reported in the revised experimental section. This procedure avoids any use of the evaluation data for hyperparameter tuning. revision: yes
-
Referee: [Ablation studies] To substantiate that the Wasserstein distance is load-bearing for the improvements, an ablation comparing Top-W to a version without the geometric potential (i.e., standard mass-entropy truncation) is necessary. Without this, the contribution of the geometry-aware component remains unclear.
Authors: We agree that this ablation is essential to isolate the contribution of the geometric component. In the revised manuscript, we will include an ablation study where we replace the Wasserstein-based potential with a uniform or probability-only potential, effectively reducing to standard mass-entropy truncation, and compare performance on the same benchmarks. Preliminary results indicate that the geometric potential accounts for a significant portion of the observed gains. revision: yes
Circularity Check
Closed-form truncation structure depends on tuned mass-entropy parameter from evaluation data
specific steps
-
fitted input called prediction
[Abstract]
"Our theory yields a simple closed-form structure for the fixed-potential subset update: depending on the mass-entropy trade-off, the optimal crop either collapses to a single token or takes the form of a one-dimensional prefix that can be found efficiently with a linear scan."
The closed-form is presented as theory-derived, but the mass-entropy trade-off parameter is tuned on the evaluation benchmarks to achieve the 33.7% improvement, rendering the structure statistically forced by the fitted input rather than a genuine prediction from the Wasserstein geometry alone.
full rationale
The paper presents a theoretical derivation yielding a closed-form subset update under Wasserstein regularization and mass-entropy balancing. However, the key trade-off parameter is selected to optimize reported gains on the same benchmarks (GSM8K, GPQA, etc.) used for evaluation. This makes the claimed structure a fitted outcome rather than an independent first-principles result, introducing partial circularity without reducing the entire derivation to tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- mass-entropy trade-off parameter
axioms (1)
- domain assumption Token embeddings form a geometry in which Wasserstein distance reflects semantic closeness relevant to generation coherence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.4 (Exact fixed-f S-step: prefix regime vs. singleton regime). ... the optimal crop either collapses to a single token or takes the form of a one-dimensional prefix
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Fλ,β(S) := W1(p,qS) + λH(qS) − βlogΓS
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mirostat: A perplexity-controlled neural text decoding algorithm
Sourya Basu, Govardana Sachitanandam Ramachandran, Nitish Shirish Keskar, and Lav R Varshney. Mirostat: A perplexity-controlled neural text decoding algorithm. arXiv preprint arXiv:2007.14966,
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[4]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models.arXiv preprint arXiv:2309.03883,
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation.arXiv preprint arXiv:1912.02164,
-
[8]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal ´azs Galambosi, Percy Liang, and Tat- sunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Hierarchical Neural Story Generation
Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation.arXiv preprint arXiv:1805.04833,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https: //zenodo.org/records/12608602. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhi- nav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Truncation sampling as language model desmoothing
John Hewitt, Christopher D Manning, and Percy Liang. Truncation sampling as language model desmoothing. arXiv preprint arXiv:2210.15191,
-
[13]
The Curious Case of Neural Text Degeneration
9 Top-WDecoding Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[14]
Gedi: Generative discriminator guided sequence generation
Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. Gedi: Generative discriminator guided sequence generation. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2021, pages 4929–4952,
work page 2021
-
[15]
Typical decoding for natural language generation
Clara Meister, Tiago Pimentel, Gian Wiher, and Ryan Cot- terell. Typical decoding for natural language generation. arXiv preprint arXiv:2202.00666,
-
[16]
Minh Nhat Nguyen, Andrew Baker, Clement Neo, Allen Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. Turning up the heat: Min-p sampling for creative and coherent llm outputs.arXiv preprint arXiv:2407.01082,
-
[17]
Top-H Decoding: Adapting the Creativity and Coherence with Bounded Entropy in Text Generation
Erfan Baghaei Potraghloo, Seyedarmin Azizi, Souvik Kundu, and Massoud Pedram. Top-h decoding: Adapting the creativity and coherence with bounded entropy in text generation.arXiv preprint arXiv:2509.02510,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Contrastive search is what you need for neural text generation.arXiv preprint arXiv:2210.14140,
Yixuan Su and Nigel Collier. Contrastive search is what you need for neural text generation.arXiv preprint arXiv:2210.14140,
-
[20]
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Ashwin K Vijayakumar, Michael Cogswell, Ramprasath R Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search: Decoding diverse solutions from neural sequence models.arXiv preprint arXiv:1610.02424,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.