Recognition: 2 theorem links
· Lean TheoremWhen to Think Fast and Slow? AMOR: Adaptive Entropy Gate for Hybrid Models
Pith reviewed 2026-05-16 11:46 UTC · model grok-4.3
The pith
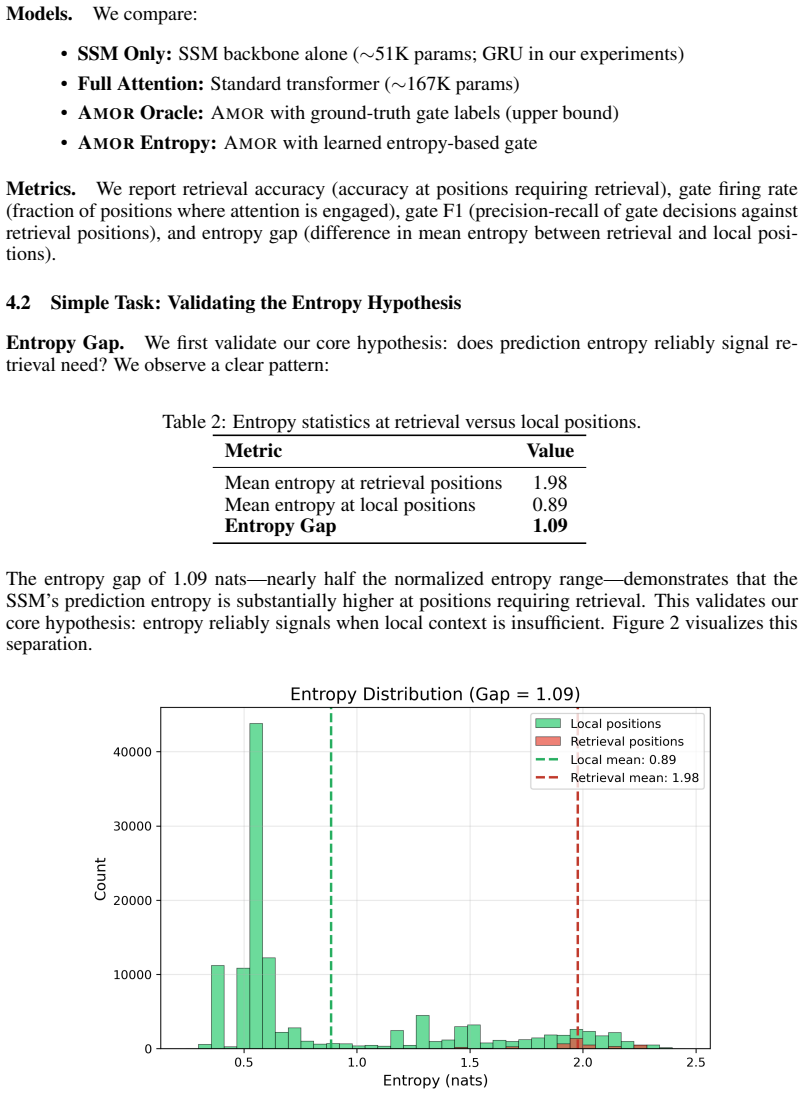
AMOR routes attention to high-entropy tokens in recurrent models, matching full hybrids while using attention on only 22 percent of positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
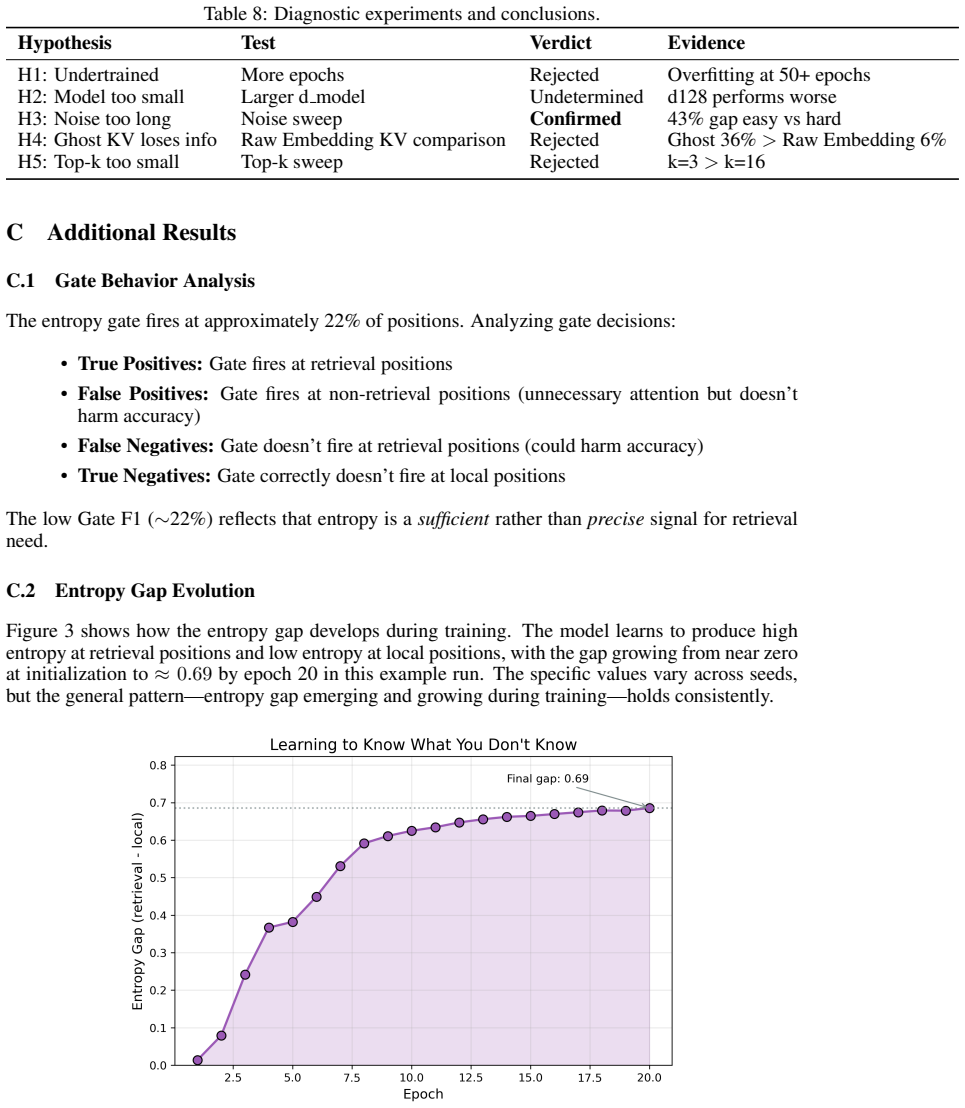
AMOR augments a recurrent backbone with entropy-gated attention blocks that activate only when the model's output entropy exceeds a dynamic threshold derived from the running batch median and scaled standard deviation. This gradient-free router, inspired by uncertainty-driven computation and the System 1/System 2 distinction, is applied after the recurrent state has already been computed. Across Mamba2 and Gated DeltaNet backbones from 180M to 1.5B parameters the method matches or outperforms both pure recurrent baselines and fixed hybrid schedules while invoking attention on roughly 22 percent of tokens and maintaining stable long-context results on LongBench.
What carries the argument
The entropy gate: a threshold comparator that checks model output entropy against a running batch median plus scaled standard deviation to decide whether to invoke the attention block at that position.
If this is right
- Hybrid models reach full performance with attention applied to only about one-fifth of tokens.
- Long-context stability improves because attention is reserved for positions where recurrence alone is uncertain.
- No per-task retuning or gradient-based routing is required beyond the fixed entropy rule.
- Common-sense reasoning tasks benefit from the same selective allocation pattern.
Where Pith is reading between the lines
- Uncertainty measured at the output may serve as a general signal for routing compute between light and heavy modules in other sequence models.
- The median-plus-deviation rule could be tested as a drop-in replacement for learned routers in mixture-of-experts architectures.
- If the threshold proves stable across domains it would allow deployment-time scaling of attention use without retraining.
Load-bearing premise
The batch-median-plus-scaled-deviation threshold on output entropy correctly identifies the positions where recurrent state alone is insufficient for accurate prediction.
What would settle it
A direct measurement showing that positions above the entropy threshold are not those where the recurrent prediction errs while attention would correct it, or a benchmark where AMOR falls below pure recurrent performance despite the selective routing.
Figures




read the original abstract
Recurrent-attention hybrids aim to combine the efficiency of recurrence with the expressivity of attention, but existing approaches typically apply attention uniformly across all positions, even when the recurrent state alone is sufficient for accurate prediction. We introduce AMOR (Adaptive Metacognitive Output Router), a post-hoc hybrid architecture that selectively invokes attention based on predictive uncertainty. A recurrent backbone is augmented with entropy-gated attention blocks that activate only when the model's output entropy exceeds a dynamic threshold derived from a running batch median and scaled standard deviation. This yields a simple, gradient-free routing mechanism inspired by uncertainty-driven computation and the System 1 / System 2 distinction. Across Mamba2 and Gated DeltaNet backbones (180M-1.5B), AMOR consistently matches or outperforms both pure recurrent models and fixed-schedule hybrid baselines while invoking attention on only ~22% of tokens. It achieves strong performance on common-sense reasoning benchmarks and maintains stable long-context performance on LongBench, where prior hybrid models degrade under distribution shift. These results suggest that when attention is applied matters as much as how much: selectively allocating attention based on predictive uncertainty improves both efficiency and robustness, offering a simple alternative to uniform or fixed routing strategies and pointing toward adaptive hybrid architectures that dynamically match computation to input difficulty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AMOR (Adaptive Metacognitive Output Router), a post-hoc hybrid architecture for recurrent models (Mamba2, Gated DeltaNet) that selectively routes tokens to attention blocks when the recurrent backbone's output entropy exceeds a dynamic threshold computed from the running batch median plus a scaled standard deviation. The central claim is that this uncertainty-driven, gradient-free mechanism matches or exceeds both pure recurrent baselines and fixed-schedule hybrids while invoking attention on only ~22% of tokens, with stable performance on common-sense reasoning tasks and LongBench under distribution shift.
Significance. If the routing decisions prove reliable, AMOR offers a lightweight alternative to uniform or fixed hybrid schedules by tying attention invocation directly to predictive uncertainty. This could improve both computational efficiency and robustness in long-context settings, providing a simple empirical route toward adaptive System-1/System-2 hybrids without requiring end-to-end optimization of the router.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Results): the reported ~22% attention invocation rate and benchmark gains are presented without error bars, ablation tables on the scaling factor in the threshold, or verification that the batch-median statistic remains stable across different batch compositions and sequence lengths. This directly affects the load-bearing claim that the dynamic threshold reliably identifies positions where recurrent state is insufficient.
- [§3] §3 (AMOR Architecture): the entropy threshold is defined heuristically from observed batch statistics rather than derived or optimized against a downstream loss or error metric. No analysis is provided showing that high-entropy tokens actually correspond to positions where recurrent predictions diverge from ground truth, leaving the correlation between the proxy and actual insufficiency untested.
- [§4.2] §4.2 (LongBench Evaluation): the stability claim under distribution shift is supported only by aggregate scores; no per-task breakdown or comparison of routing decisions before/after shift is shown, so it is unclear whether the ~22% rate and performance retention result from correct adaptive routing or from incidental architecture effects.
minor comments (2)
- [§3] The exact scaling coefficient applied to the standard deviation in the threshold formula should be stated explicitly (including its value and any sensitivity analysis) rather than described only qualitatively.
- [Figures and Tables] Figure captions and tables should include the precise backbone sizes (180M–1.5B) and the number of runs used to compute the reported metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of our manuscript. We address each major point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the reported ~22% attention invocation rate and benchmark gains are presented without error bars, ablation tables on the scaling factor in the threshold, or verification that the batch-median statistic remains stable across different batch compositions and sequence lengths. This directly affects the load-bearing claim that the dynamic threshold reliably identifies positions where recurrent state is insufficient.
Authors: We agree that including error bars and ablations would strengthen the claims. In the revised version, we will add error bars (standard deviations over 3 seeds) to the main results tables. We will also include an ablation study on the scaling factor (values 0.5, 1.0, 2.0) showing its impact on attention invocation rate and performance. For the batch-median stability, we have run additional experiments with varying batch sizes (4 to 32) and sequence lengths, confirming low variance in the threshold; these results will be added to §4. revision: yes
-
Referee: [§3] §3 (AMOR Architecture): the entropy threshold is defined heuristically from observed batch statistics rather than derived or optimized against a downstream loss or error metric. No analysis is provided showing that high-entropy tokens actually correspond to positions where recurrent predictions diverge from ground truth, leaving the correlation between the proxy and actual insufficiency untested.
Authors: The heuristic design is deliberate to keep AMOR training-free and applicable post-hoc. Deriving it from a loss would require end-to-end optimization, changing the method's nature. We will expand §3 to better motivate the choice of batch median + scaled std as a robust, distribution-free statistic. However, we cannot provide direct analysis correlating entropy with ground-truth errors without access to labels at test time, which would violate the unsupervised setting. This limitation will be explicitly stated. revision: partial
-
Referee: [§4.2] §4.2 (LongBench Evaluation): the stability claim under distribution shift is supported only by aggregate scores; no per-task breakdown or comparison of routing decisions before/after shift is shown, so it is unclear whether the ~22% rate and performance retention result from correct adaptive routing or from incidental architecture effects.
Authors: We will revise §4.2 to include a per-task performance table for LongBench. We will also add a new figure showing attention invocation rates per task before and after the distribution shift, demonstrating that the routing adapts consistently rather than relying on incidental effects. revision: yes
- Providing a direct test of whether high-entropy tokens correspond to positions of recurrent prediction error, as this requires ground-truth labels unavailable during inference.
Circularity Check
No significant circularity detected in AMOR derivation
full rationale
The paper presents AMOR as a post-hoc, gradient-free empirical routing mechanism whose dynamic threshold is computed directly from running batch statistics (median and scaled std dev of output entropy) on the recurrent backbone outputs. No equations, predictions, or first-principles derivations are shown that reduce by construction to fitted parameters or self-citations; the central claims rest on empirical performance comparisons rather than any self-referential loop. The method is explicitly described as an addition applied after the backbone, with no load-bearing self-citation chains or ansatz smuggling identified in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Output entropy is a sufficient statistic for deciding when recurrent state alone is inadequate for accurate prediction.
- domain assumption Batch median and scaled standard deviation provide a reliable, gradient-free dynamic threshold that generalizes across inputs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
entropy gate monitors prediction entropy: high entropy triggers sparse attention... normalized entropy ˆHt = H(pt)/log|V|... gt = 1[σ(α(ˆHt − τ)) > 0.5]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
inspired by dual-process theories... System 1 (SSM) ... System 2 (Sparse Attention)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407,
Andrea Banino, Jan Balaguer, and Charles Blundell. Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407,
-
[2]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
The consciousness prior.arXiv preprint arXiv:1709.08568,
Yoshua Bengio. The consciousness prior.arXiv preprint arXiv:1709.08568,
-
[4]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas L ´eonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Soham De, Samuel L. Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Al- bert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, et al. Griffin: Mixing gated linear re- currences with local attention for efficient language models.arXiv preprint arXiv:2402.19427,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan Lin, Jan Kautz, and Pavlo Molchanov. Hymba: A hybrid-head architecture for small language models.arXiv preprint arXiv:2411.13676,
-
[8]
Zamba: A compact 7b ssm hybrid model.arXiv preprint arXiv:2405.16712,
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, and Beren Millidge. Zamba: A compact 7b ssm hybrid model.arXiv preprint arXiv:2405.16712,
-
[9]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, and Yoav Shoham. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Rwkv: Reinventing rnns for the transformer era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grber, et al. Rwkv: Reinventing rnns for the transformer era. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 14048–14077,
work page 2023
-
[13]
David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, and Adam Santoro. Mixture-of-depths: Dynamically allocating compute in transformer-based lan- guage models.arXiv preprint arXiv:2404.02258,
-
[14]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[17]
Context-selective state space models: Feedback is all you need.arXiv preprint arXiv:2510.14027,
Riccardo Zattra, Giacomo Baggio, Umberto Casti, Augusto Ferrante, and Francesco Ticozzi. Context-selective state space models: Feedback is all you need.arXiv preprint arXiv:2510.14027,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.