Recognition: no theorem link
EgoSound: Benchmarking Sound Understanding in Egocentric Videos
Pith reviewed 2026-05-15 21:42 UTC · model grok-4.3
The pith
Multimodal models show emerging sound reasoning in egocentric videos but lack fine-grained spatial and causal understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
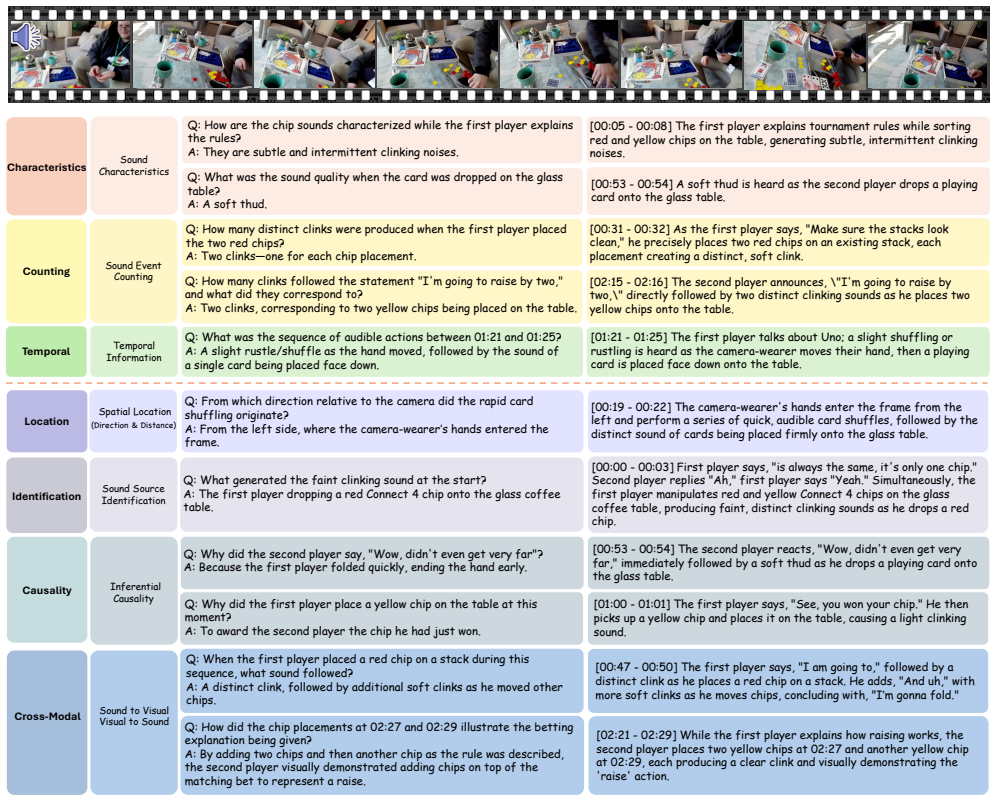
EgoSound unifies data from Ego4D and EgoBlind into a benchmark with a seven-task taxonomy for intrinsic sound perception, spatial localization, causal inference, and cross-modal reasoning, containing 7315 validated QA pairs across 900 videos, and tests reveal that state-of-the-art MLLMs exhibit emerging auditory reasoning abilities but remain limited in fine-grained spatial and causal understanding.
What carries the argument
The seven-task taxonomy and multi-stage auto-generative pipeline for creating validated QA pairs, which systematically measures sound understanding in egocentric settings.
If this is right
- Models will need enhanced audio-visual integration to handle spatial layout from sounds.
- Advancements in causal inference from auditory cues could improve egocentric AI applications.
- The benchmark enables consistent comparison across future multimodal models.
- Development of better sound-dependent reasoning in MLLMs for real-world scenarios.
Where Pith is reading between the lines
- Extending the benchmark to include more diverse environments could highlight domain-specific weaknesses.
- Integration with video action recognition might reveal how sound aids in predicting human behaviors.
- Applying similar benchmarks to non-egocentric videos could show if limitations are specific to first-person perspectives.
Load-bearing premise
The multi-stage auto-generative pipeline produces high-quality, unbiased QA pairs that validly measure sound understanding without introducing artifacts from the generation process.
What would settle it
A study where humans rate the relevance and difficulty of the QA pairs and find significant mismatches with actual sound understanding capabilities would undermine the benchmark's effectiveness.
Figures














read the original abstract
Multimodal Large Language Models (MLLMs) have recently achieved remarkable progress in vision-language understanding. Yet, human perception is inherently multisensory, integrating sight, sound, and motion to reason about the world. Among these modalities, sound provides indispensable cues about spatial layout, off-screen events, and causal interactions, particularly in egocentric settings where auditory and visual signals are tightly coupled. To this end, we introduce EgoSound, the first benchmark designed to systematically evaluate egocentric sound understanding in MLLMs. EgoSound unifies data from Ego4D and EgoBlind, encompassing both sighted and sound-dependent experiences. It defines a seven-task taxonomy spanning intrinsic sound perception, spatial localization, causal inference, and cross-modal reasoning. Constructed through a multi-stage auto-generative pipeline, EgoSound contains 7315 validated QA pairs across 900 videos. Comprehensive experiments on nine state-of-the-art MLLMs reveal that current models exhibit emerging auditory reasoning abilities but remain limited in fine-grained spatial and causal understanding. EgoSound establishes a challenging foundation for advancing multisensory egocentric intelligence, bridging the gap between seeing and truly hearing the world. Project page: https://groolegend.github.io/EgoSound/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoSound, the first benchmark for egocentric sound understanding in MLLMs. It unifies data from Ego4D and EgoBlind into 7315 validated QA pairs across 900 videos via a multi-stage auto-generative pipeline, defines a seven-task taxonomy covering intrinsic sound perception, spatial localization, causal inference, and cross-modal reasoning, and evaluates nine state-of-the-art MLLMs. The central claim is that current models show emerging auditory reasoning abilities but remain limited in fine-grained spatial and causal understanding.
Significance. If the QA pairs are shown to be free of generation artifacts and representative of real egocentric sound demands, EgoSound would be a useful resource for measuring multisensory integration gaps in vision-language models and guiding future work on audio-visual reasoning.
major comments (2)
- [Section 3 (pipeline description) and experimental setup] The headline results on model limitations rest entirely on performance numbers from the 7315 QA pairs produced by the multi-stage auto-generative pipeline (video captioning, question synthesis, answer generation, filtering). The manuscript provides no quantitative audit—such as human agreement rates on a held-out subset, inter-annotator reliability, or error analysis for label noise and distributional bias—leaving open the possibility that the pipeline introduces model-induced artifacts or spurious correlations that make the reported gaps uninterpretable.
- [Section 4 (experiments) and Table/Figure reporting results] The evaluation section reports results on nine MLLMs but omits details on the exact metrics (e.g., accuracy, F1, or task-specific scores), whether error bars or statistical significance tests were computed, the validation split procedure, and how answers were judged (exact match vs. LLM-as-judge). These omissions make it impossible to assess the reliability of the claim that models are 'limited in fine-grained spatial and causal understanding.'
minor comments (2)
- [Section 2] The seven-task taxonomy is introduced without a clear mapping table showing which tasks correspond to which Ego4D/EgoBlind subsets or how tasks overlap.
- [Abstract and conclusion] The project page URL is given but the manuscript does not state whether the full QA pairs, generation code, and evaluation scripts will be released.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point-by-point below. Where the comments identify gaps in reporting or validation, we have revised the manuscript accordingly to improve transparency and reliability.
read point-by-point responses
-
Referee: [Section 3 (pipeline description) and experimental setup] The headline results on model limitations rest entirely on performance numbers from the 7315 QA pairs produced by the multi-stage auto-generative pipeline (video captioning, question synthesis, answer generation, filtering). The manuscript provides no quantitative audit—such as human agreement rates on a held-out subset, inter-annotator reliability, or error analysis for label noise and distributional bias—leaving open the possibility that the pipeline introduces model-induced artifacts or spurious correlations that make the reported gaps uninterpretable.
Authors: We agree that a quantitative human audit of the auto-generative pipeline is essential to substantiate the benchmark's reliability. In the revised manuscript, we will add a dedicated subsection in Section 3 reporting results from a human evaluation study on a held-out set of 500 QA pairs. This will include inter-annotator agreement rates (targeting Cohen's kappa > 0.8), error analysis categorizing pipeline-induced artifacts (e.g., factual inaccuracies, bias in question phrasing), and distributional checks against the source Ego4D/EgoBlind videos. We will also discuss mitigation steps taken during filtering. These additions directly address the concern about interpretability of model gaps. revision: yes
-
Referee: [Section 4 (experiments) and Table/Figure reporting results] The evaluation section reports results on nine MLLMs but omits details on the exact metrics (e.g., accuracy, F1, or task-specific scores), whether error bars or statistical significance tests were computed, the validation split procedure, and how answers were judged (exact match vs. LLM-as-judge). These omissions make it impossible to assess the reliability of the claim that models are 'limited in fine-grained spatial and causal understanding.'
Authors: We acknowledge these reporting omissions limit reproducibility and assessment of our claims. In the revised Section 4, we will explicitly state: (i) primary metric is accuracy across all seven tasks, with F1 for any multi-label subtasks; (ii) results include error bars as standard deviation over three runs with fixed seeds; (iii) statistical significance via paired t-tests with p-values reported for key comparisons; (iv) evaluation uses the full 7315 QA pairs (benchmark-style, no held-out validation split for training); and (v) judging procedure combines exact string match for closed-ended questions with LLM-as-judge (GPT-4o, standardized prompt) for open-ended ones, validated by human agreement on 200 samples (92% match rate). These details will support the interpretation of limitations in spatial and causal tasks. revision: yes
Circularity Check
No circularity: benchmark construction and external empirical evaluation
full rationale
The paper constructs the EgoSound benchmark through a multi-stage auto-generative pipeline that produces QA pairs from Ego4D and EgoBlind videos, then reports performance of nine external MLLMs on the resulting 7315 pairs across seven tasks. No equations, parameter fitting, or predictions appear in the described chain; the reported findings are direct empirical measurements against independent models. The pipeline is presented as a construction method rather than a derived result, and no self-citation or ansatz is invoked to justify the central claims. This matches the default case of a self-contained benchmark paper with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The seven-task taxonomy (intrinsic sound perception, spatial localization, causal inference, cross-modal reasoning) comprehensively represents egocentric sound understanding.
- ad hoc to paper The multi-stage auto-generative pipeline followed by validation produces QA pairs that are free of artifacts and representative of real sound understanding demands.
Forward citations
Cited by 1 Pith paper
-
IMPACT-HOI: Supervisory Control for Onset-Anchored Partial HOI Event Construction
IMPACT-HOI introduces a supervisory control framework for constructing partial HOI event graphs in procedural videos via trust-calibrated automation and atomic rollback to reduce manual annotation effort while preserv...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Savvy: Spatial awareness via audio-visual llms through seeing and hearing
Mingfei Chen, Zijun Cui, Xiulong Liu, Jinlin Xiang, Caleb Zheng, Jingyuan Li, and Eli Shlizerman. Savvy: Spatial awareness via audio-visual llms through seeing and hearing. arXiv preprint arXiv:2506.05414, 2025. 3
-
[4]
Egothink: Evalu- ating first-person perspective thinking capability of vision- language models
Sijie Cheng, Zhicheng Guo, Jingwen Wu, Kechen Fang, Peng Li, Huaping Liu, and Yang Liu. Egothink: Evalu- ating first-person perspective thinking capability of vision- language models. InCVPR, 2024. 2, 3
work page 2024
-
[5]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 2, 3, 6, 7, 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Sanjoy Chowdhury, Mohamed Elmoghany, Yohan Abeysinghe, Junjie Fei, Sayan Nag, Salman Khan, Mohamed Elhoseiny, and Dinesh Manocha. Magnet: A multi-agent framework for finding audio-visual needles by reasoning over multi-video haystacks.arXiv preprint arXiv:2506.07016, 2025. 3
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2, 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. In ECCV, 2018. 2
work page 2018
-
[9]
Egovqa - an egocentric video question an- swering benchmark dataset
Chenyou Fan. Egovqa - an egocentric video question an- swering benchmark dataset. InICCV (Workshops), 2019. 2, 3
work page 2019
-
[10]
Yuqian Fu, Runze Wang, Yanwei Fu, Danda Pani Paudel, and Luc Van Gool. Cross-view multi-modal segmentation@ ego- exo4d challenges 2025.arXiv preprint arXiv:2506.05856, 2025
-
[11]
Yuqian Fu, Runze Wang, Bin Ren, Guolei Sun, Biao Gong, Yanwei Fu, Danda Pani Paudel, Xuanjing Huang, and Luc Van Gool. Objectrelator: Enabling cross-view object rela- tion understanding across ego-centric and exo-centric per- spectives. InICCV, 2025
work page 2025
-
[12]
Amego: Active memory from long egocentric videos
Gabriele Goletto, Tushar Nagarajan, Giuseppe Averta, and Dima Damen. Amego: Active memory from long egocentric videos. InECCV, 2024. 2, 3
work page 2024
-
[13]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In CVPR, 2022. 1, 2, 3, 4, 6
work page 2022
-
[14]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InCVPR, 2024. 2
work page 2024
-
[15]
Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Li- jin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, et al. Egoexolearn: A dataset for bridging asyn- chronous ego-and exo-centric view of procedural activities in real world. InCVPR, 2024. 2
work page 2024
-
[16]
EPIC-SOUNDS: A Large- Scale Dataset of Actions that Sound.TPAMI, 2025
Jaesung Huh, Jacob Chalk, Evangelos Kazakos, Dima Damen, and Andrew Zisserman. EPIC-SOUNDS: A Large- Scale Dataset of Actions that Sound.TPAMI, 2025. 2
work page 2025
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Egotaskqa: Understanding human tasks in egocentric videos
Baoxiong Jia, Ting Lei, Song-Chun Zhu, and Siyuan Huang. Egotaskqa: Understanding human tasks in egocentric videos. NeurIPS, 2022. 2, 3
work page 2022
-
[19]
Kailing Li, Qi’ao Xu, Tianwen Qian, Yuqian Fu, Yang Jiao, and Xiaoling Wang. Clivis: Unleashing cognitive map through linguistic-visual synergy for embodied visual rea- soning.arXiv preprint arXiv:2506.17629, 2025
-
[20]
Yanjun Li, Yuqian Fu, Tianwen Qian, Qi’ao Xu, Silong Dai, Danda Pani Paudel, Luc Van Gool, and Xiaoling Wang. Egocross: Benchmarking multimodal large language models for cross-domain egocentric video question answering.arXiv preprint arXiv:2508.10729, 2025. 2, 3
-
[21]
Ziyang Ma, Ruiyang Xu, Zhenghao Xing, Yunfei Chu, Yux- uan Wang, Jinzheng He, Jin Xu, Pheng-Ann Heng, Kai Yu, Junyang Lin, et al. Omni-captioner: Data pipeline, models, and benchmark for omni detailed perception.arXiv preprint arXiv:2510.12720, 2025. 1
-
[22]
Mohammad Mahdi, Yuqian Fu, Nedko Savov, Jiancheng Pan, Danda Pani Paudel, and Luc Van Gool. Exo2egosyn: Unlocking foundation video generation models for exocentric-to-egocentric video synthesis.arXiv preprint arXiv:2511.20186, 2025. 2
-
[23]
Openeqa: Embodied question answering in the era of foun- dation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foun- dation models. InCVPR, 2024. 2
work page 2024
-
[24]
Egoschema: A diagnostic benchmark for very long- form video language understanding.NeurIPS, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding.NeurIPS, 2023. 1, 2, 3
work page 2023
-
[25]
OpenAI. Gpt-5 system card, 2025. Accessed: 2025-08-10. 6, 2 9
work page 2025
-
[26]
V$^{2}$-SAM: Marrying SAM2 with Multi-Prompt Experts for Cross-View Object Correspondence
Jiancheng Pan, Runze Wang, Tianwen Qian, Mohammad Mahdi, Yanwei Fu, Xiangyang Xue, Xiaomeng Huang, Luc Van Gool, Danda Pani Paudel, and Yuqian Fu. V2-sam: Mar- rying sam2 with multi-prompt experts for cross-view object correspondence.arXiv preprint arXiv:2511.20886, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Hd-epic: A highly-detailed egocentric video dataset
Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Kumar Parida, Kaiting Liu, Pra- jwal Gatti, Siddhant Bansal, Kevin Flanagan, et al. Hd-epic: A highly-detailed egocentric video dataset. InCVPR, 2025. 2
work page 2025
-
[28]
Omnia de egotempo: Benchmarking temporal understanding of multi-modal llms in egocentric videos
Chiara Plizzari, Alessio Tonioni, Yongqin Xian, Achin Kul- shrestha, and Federico Tombari. Omnia de egotempo: Benchmarking temporal understanding of multi-modal llms in egocentric videos. InCVPR, 2025. 1, 2, 3
work page 2025
-
[29]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. InCVPR, 2023. 3
work page 2023
-
[30]
Ivan Rodin, Tz-Ying Wu, Kyle Min, Sharath Nittur Srid- har, Antonino Furnari, Subarna Tripathi, and Giovanni Maria Farinella. Easg-bench: Video q&a benchmark with egocen- tric action scene graphs.arXiv preprint arXiv:2506.05787,
-
[31]
Kazuki Shimada, Archontis Politis, Parthasaarathy Su- darsanam, Daniel A Krause, Kengo Uchida, Sharath Ada- vanne, Aapo Hakala, Yuichiro Koyama, Naoya Takahashi, Shusuke Takahashi, et al. Starss23: An audio-visual dataset of spatial recordings of real scenes with spatiotemporal an- notations of sound events.NeurIPS, 2023. 3
work page 2023
-
[32]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video- SALMONN 2: Captioning-Enhanced Audio-Visual Large Language Models.arXiv preprint arXiv:2506.15220, 2025. 2, 3, 6, 7, 1
-
[33]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiao- han Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InICCV, 2025. 3
work page 2025
-
[34]
Teaching physical awareness to llms through sounds.arXiv preprint arXiv:2506.08524, 2025
Weiguo Wang, Andy Nie, Wenrui Zhou, Yi Kai, and Chengchen Hu. Teaching physical awareness to llms through sounds.arXiv preprint arXiv:2506.08524, 2025. 3
-
[35]
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bu- gra Tekin, Felipe Vieira Frujeri, et al. Holoassist: an egocen- tric human interaction dataset for interactive ai assistants in the real world. InICCV, 2023. 2
work page 2023
-
[36]
Ai for service: Proactive assistance with ai glasses.arXiv preprint arXiv:2510.14359, 2025
Zichen Wen, Yiyu Wang, Chenfei Liao, Boxue Yang, Junx- ian Li, Weifeng Liu, Haocong He, Bolong Feng, Xuyang Liu, Yuanhuiyi Lyu, et al. Ai for service: Proactive assistance with ai glasses.arXiv preprint arXiv:2510.14359, 2025. 2
-
[37]
Junbin Xiao, Nanxin Huang, Hao Qiu, Zhulin Tao, Xun Yang, Richang Hong, Meng Wang, and Angela Yao. Egob- lind: Towards egocentric visual assistance for the blind peo- ple.arXiv preprint arXiv:2503.08221, 2025. 1, 2, 3, 4, 6
-
[38]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025. 2, 3, 6, 7, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 2, 3, 6, 7, 8, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
ToG-Bench: Task-Oriented Spatio-Temporal Grounding in Egocentric Videos
Qi’ao Xu, Tianwen Qian, Yuqian Fu, Kailing Li, Yang Jiao, Jiacheng Zhang, Xiaoling Wang, and Liang He. Tog- bench: Task-oriented spatio-temporal grounding in egocen- tric videos.arXiv preprint arXiv:2512.03666, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Egolife: Towards ego- centric life assistant
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xi- amengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, et al. Egolife: Towards ego- centric life assistant. InCVPR, 2025. 2, 3, 6, 7
work page 2025
-
[42]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 2, 3, 6, 7, 8, 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Hanrong Ye, Haotian Zhang, Erik Daxberger, Lin Chen, Zongyu Lin, Yanghao Li, Bowen Zhang, Haoxuan You, Dan Xu, Zhe Gan, et al. Mm-ego: Towards building egocentric multimodal llms for video qa.arXiv preprint arXiv:2410.07177, 2024. 2
-
[44]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understand- ing.arXiv preprint arXiv:2501.13106, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Egonight: Towards egocentric vision understanding at night with a challenging benchmark
Deheng Zhang, Yuqian Fu, Runyi Yang, Yang Miao, Tian- wen Qian, Xu Zheng, Guolei Sun, Ajad Chhatkuli, Xuanjing Huang, Yu-Gang Jiang, et al. Egonight: Towards egocentric vision understanding at night with a challenging benchmark. arXiv preprint arXiv:2510.06218, 2025. 2
-
[46]
Zhisheng Zheng, Puyuan Peng, Ziyang Ma, Xie Chen, Eun- sol Choi, and David Harwath. Bat: Learning to reason about spatial sounds with large language models.arXiv preprint arXiv:2402.01591, 2024. 3
-
[47]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding.arXiv preprint arXiv:2406.04264,
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Egotextvqa: Towards egocentric scene-text aware video question answering
Sheng Zhou, Junbin Xiao, Qingyun Li, Yicong Li, Xun Yang, Dan Guo, Meng Wang, Tat-Seng Chua, and Angela Yao. Egotextvqa: Towards egocentric scene-text aware video question answering. InCVPR, 2025. 2
work page 2025
-
[49]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 3 10 EgoSound: Benchmarking Sound Understanding in Egocentric Videos Supplementary Material A. Mo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.