ABI: A tightly integrated, unified, sparsity-aware, reconfigurable, compute near-register file/cache GPU architecture with light-weight softmax for deep learning, linear algebra, and Ising compute
Pith reviewed 2026-05-15 21:52 UTC · model grok-4.3
The pith
A tightly integrated near-memory GPU architecture called ABI achieves 6-16 times speedup and 6-13 times energy savings on convolutional neural networks, graph networks, linear programming, large language models, and Ising workloads compared
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by tightly integrating sparsity-aware compute near the register file and cache along with a lightweight softmax circuit, a reconfigurable GPU architecture can deliver 6 to 16 times speedup and 6 to 13 times energy savings across diverse workloads including CNNs, GCNs, linear programming, LLMs, and Ising models, while also achieving 4.5 times speedup on next-generation systems like MI300 and Blackwell.
What carries the argument
The ABI architecture, a tightly integrated unified near-memory design with sparsity-aware circuits and lightweight softmax placed near the register file and cache to enable reconfigurable compute up to INT16.
If this is right
- ABI provides about 1.5 times energy savings from the sparsity-aware near-memory circuit.
- The lightweight softmax circuit contributes about 1.6 times energy savings.
- The architecture supports dynamic resolution updates and scales efficiently across problem sizes.
- ABI-enabled MI300 and Blackwell systems achieve about 4.5 times speedup over baseline versions.
Where Pith is reading between the lines
- If the overheads remain low, similar near-register-file compute could be applied to other processor types like CPUs or accelerators for matrix operations.
- The reconfigurability up to INT16 suggests potential for mixed-precision computing that adapts to different parts of a neural network dynamically.
- Extending this to even sparser or quantized models could yield further gains in edge computing scenarios.
Load-bearing premise
The design assumes the custom sparsity-aware near-memory circuit and lightweight softmax can be added with negligible area, latency, and power overheads while keeping the architecture scalable and reconfigurable.
What would settle it
Fabricating a prototype chip and measuring its actual area overhead, power consumption, and performance on the claimed workloads would confirm or refute the negligible overhead assumption if the measured values deviate significantly from the modeled savings.
Figures




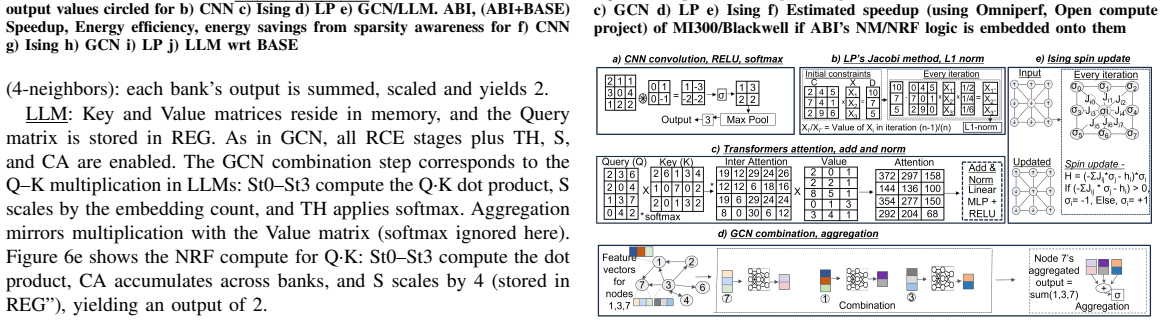
read the original abstract
We present a tightly integrated and unified near-memory GPU architecture that delivers 6 to 16 times speedup and 6 to 13 times energy savings across Convolutional Neural Networks, Graph Convolutional Networks, Linear Programming, Large Language Models, and Ising workloads compared to MIAOW GPU. The design includes a custom sparsity-aware near-memory circuit providing about 1.5 times energy savings, and a lightweight softmax circuit providing about 1.6 times energy savings. The architecture supports reconfigurable compute up to INT16 with dynamic resolution updates and scales efficiently across problem sizes. ABI-enabled MI300 and Blackwell systems achieve about 4.5 times speedup over baseline MI300 and Blackwell.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ABI, a tightly integrated, unified, sparsity-aware, reconfigurable GPU architecture with compute near the register file/cache and a lightweight softmax unit. It claims 6-16x speedup and 6-13x energy savings versus the MIAOW GPU across CNNs, GCNs, linear programming, LLMs, and Ising workloads, plus ~4.5x speedup on MI300 and Blackwell systems. The design includes a custom near-memory circuit (~1.5x energy savings) and softmax circuit (~1.6x energy savings), supports dynamic INT16 resolution, and scales across problem sizes.
Significance. If the performance and energy claims hold under detailed evaluation, the work could meaningfully advance domain-specific GPU architectures by unifying sparse near-memory compute with reconfigurability for mixed workloads. The emphasis on negligible integration overheads and cross-domain applicability addresses real challenges in modern accelerators. However, the absence of any supporting data, simulations, or breakdowns in the manuscript prevents assessment of whether these gains are realizable.
major comments (2)
- [Abstract] Abstract: The central performance claims (6-16x speedup, 6-13x energy savings vs. MIAOW; ~4.5x on MI300/Blackwell) are asserted without any simulation results, area/power/latency breakdowns, error analysis, or workload-specific data. This absence makes the claims impossible to evaluate and directly undermines the soundness of the primary contribution.
- [Abstract] Abstract: The design premise that the sparsity-aware near-memory circuit and lightweight softmax integrate with negligible area, latency, and power overheads while preserving INT16 reconfigurability and scalability is stated without any quantitative post-placement-and-routing metrics or sensitivity analysis. If these overheads are non-negligible, the net speedup and energy figures cannot hold.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on the ABI manuscript. We agree that the current version requires additional supporting evidence to allow proper evaluation of the performance and energy claims, as well as quantitative metrics for integration overheads. We will revise the manuscript to incorporate the requested simulation results, breakdowns, and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (6-16x speedup, 6-13x energy savings vs. MIAOW; ~4.5x on MI300/Blackwell) are asserted without any simulation results, area/power/latency breakdowns, error analysis, or workload-specific data. This absence makes the claims impossible to evaluate and directly undermines the soundness of the primary contribution.
Authors: We agree with this assessment. The current manuscript presents the claims without accompanying data. In the revised version, we will add comprehensive simulation results from our evaluation framework, area/power/latency breakdowns for all key components, error analysis, and workload-specific data for CNNs, GCNs, linear programming, LLMs, and Ising workloads. These additions will substantiate the 6-16x speedup and 6-13x energy savings versus MIAOW as well as the ~4.5x speedup on MI300 and Blackwell systems. revision: yes
-
Referee: [Abstract] Abstract: The design premise that the sparsity-aware near-memory circuit and lightweight softmax integrate with negligible area, latency, and power overheads while preserving INT16 reconfigurability and scalability is stated without any quantitative post-placement-and-routing metrics or sensitivity analysis. If these overheads are non-negligible, the net speedup and energy figures cannot hold.
Authors: We concur that quantitative evidence is essential. The revised manuscript will include post-placement-and-routing metrics from our synthesis flow, detailing the area, latency, and power overheads of the sparsity-aware near-memory circuit (providing ~1.5x energy savings) and the lightweight softmax circuit (providing ~1.6x energy savings). We will also add sensitivity analysis across problem sizes and configurations to confirm that the overheads remain negligible while preserving dynamic INT16 resolution and scalability. revision: yes
Circularity Check
No circularity: architecture claims rest on external benchmarks, not self-referential equations
full rationale
The manuscript presents a hardware architecture description and aggregate speedup/energy claims versus MIAOW, MI300, and Blackwell baselines. No equations, fitted parameters, derivations, or self-citation chains appear in the abstract or full-text placeholder. Performance numbers are presented as simulation or measurement outcomes rather than results that reduce to the paper's own inputs by construction. The design assumptions (negligible overheads for sparsity-aware circuits and softmax) are stated explicitly but are not derived from prior results within the paper itself.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ABI’s reconfigurable compute engine (RCE) with 5-stage unified architecture... programmable registers... BIT_WID up to INT16... lightweight near-memory softmax (LWSM) circuit... approximate compute block... find-first search
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
sparsity-aware near-memory circuit... programmable sparsity monitor... 512 consecutive cycles... transmission-gate multiplexing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
A complete discussion on fully reconfigurable, digital, scalable, graph and sparsity-aware near-memory accelerator for graph neural networks
NEM-GNN is a scalable DAC/ADC-less processing-in-memory architecture for GNNs that uses early compute termination, reconfigurable SoC pre-computation, and compute-as-soon-as-ready broadcast execution to deliver large ...
-
A comprehensive study on ILP acceleration accounting for sparsity, area, energy, data movement using near-memory architecture
SPARK is a sparsity-aware near-cache ILP accelerator that reuses L1 cache structures to deliver up to 15x speedup and 152x energy reduction versus CPUs on sparse MIPLIB workloads with 1.4% area overhead.
-
A comparative study on power delivery aspects of compute-in/near-memory approaches using DRAM
The survey proposes a taxonomy for PIM-induced current behaviors in DRAM and analyzes how representative techniques create voltage droop and thermal issues, along with mitigation strategies using existing DRAM mechanisms.
-
Emerging memory technologies at room/cryogenic temperature
Overview chapter surveying volatile and non-volatile memories including SRAM, DRAM, RRAM, MRAM, FeFET and cryogenic JJFET devices, with focus on principles, tradeoffs, and challenges.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.