Predicting New Concept-Object Associations in Astronomy by Mining the Literature
Pith reviewed 2026-05-15 21:28 UTC · model grok-4.3
The pith
A matrix factorization model trained on astronomy literature can predict new concept-object associations more accurately than neighborhood or recency baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
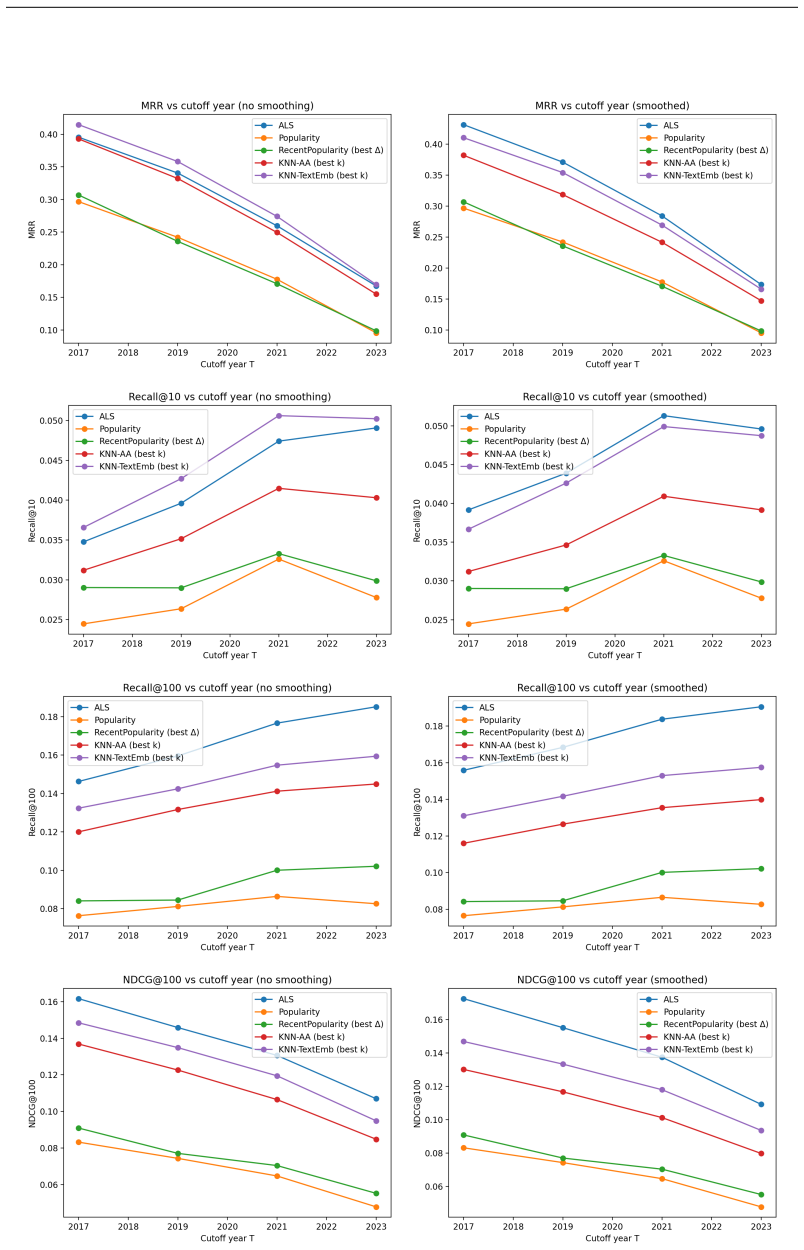
An implicit-feedback matrix factorization model (alternating least squares, ALS) with smoothing outperforms the strongest neighborhood baseline (KNN using text-embedding concept similarity) by 16.8% on NDCG@100 (0.144 vs 0.123) and 19.8% on Recall@100 (0.175 vs 0.146), and exceeds the best recency heuristic by 96% and 88%, respectively, when forecasting new concept-object associations on physically meaningful subsets of concepts across four temporal cutoffs.
What carries the argument
Implicit-feedback matrix factorization via alternating least squares applied to the concept-object incidence matrix, with uniform inference-time smoothing based on text-embedding concept similarity.
If this is right
- Historical edges in the concept-object graph encode predictive structure beyond what global popularity or local neighborhood voting can capture.
- The same matrix factorization setup continues to outperform baselines when applied to different temporal splits on the same physically meaningful concepts.
- Literature-derived predictions can support practical triage of follow-up targets when telescope time is limited.
- The approach demonstrates that automated literature graphs can surface future associations before they appear in print.
Where Pith is reading between the lines
- Re-running the pipeline on papers published after July 2025 would test whether the observed advantage persists as the graph grows.
- Adding citation or co-authorship signals to the same matrix could be checked to see if they further lift ranking metrics.
- The method could be applied to other literature-rich domains, such as biology, to forecast gene-disease or protein-function links.
- If the model mainly recovers expected links rather than truly novel ones, performance would drop sharply on a manually curated set of surprising future associations.
Load-bearing premise
The automated extraction of objects from OCR-processed papers and their resolution to SIMBAD identifiers produces a sufficiently clean and complete graph that temporal structure in the resulting edges can be treated as a reliable signal for future associations.
What would settle it
Retraining the ALS model on papers up to a chosen cutoff and checking whether its ranking advantage disappears when evaluated on associations that first appear in papers published after that cutoff.
Figures




read the original abstract
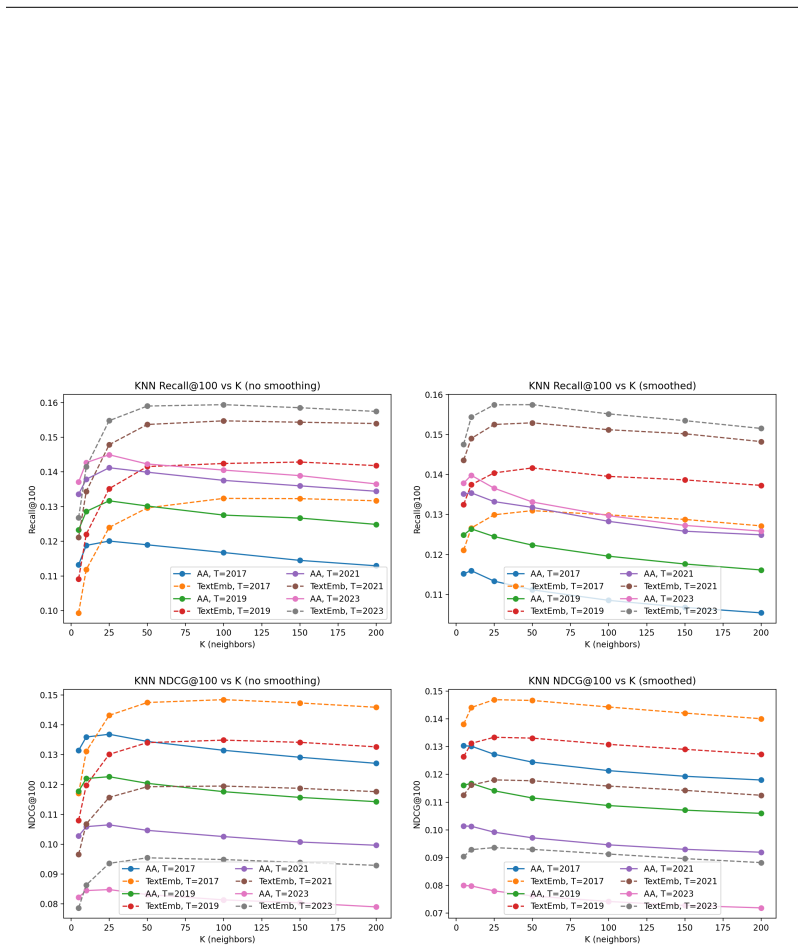
We construct a concept-object knowledge graph from the full astro-ph corpus through July 2025. Using an automated pipeline, we extract named astrophysical objects from OCR-processed papers, resolve them to SIMBAD identifiers, and link them to scientific concepts annotated in the source corpus. We then test whether historical graph structure can forecast new concept-object associations before they appear in print. Because the concepts are derived from clustering and therefore overlap semantically, we apply an inference-time concept-similarity smoothing step uniformly to all methods. Across four temporal cutoffs on a physically meaningful subset of concepts, an implicit-feedback matrix factorization model (alternating least squares, ALS) with smoothing outperforms the strongest neighborhood baseline (KNN using text-embedding concept similarity) by 16.8% on NDCG@100 (0.144 vs 0.123) and 19.8% on Recall@100 (0.175 vs 0.146), and exceeds the best recency heuristic by 96% and 88%, respectively. These results indicate that historical literature encodes predictive structure not captured by global heuristics or local neighborhood voting, suggesting a path toward tools that could help triage follow-up targets for scarce telescope time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a concept-object knowledge graph from the full astro-ph corpus through July 2025 by automatically extracting named objects from OCR-processed papers, resolving them to SIMBAD identifiers, and linking them to clustered scientific concepts. It then evaluates whether historical graph structure can predict future concept-object associations using an implicit-feedback ALS matrix factorization model with inference-time concept-similarity smoothing, reporting that this outperforms the strongest KNN baseline (using text-embedding similarity) by 16.8% on NDCG@100 (0.144 vs 0.123) and 19.8% on Recall@100 (0.175 vs 0.146) across four temporal cutoffs, and exceeds recency heuristics by larger margins.
Significance. If the underlying graph accurately reflects real historical associations, the work provides quantitative evidence that literature-derived structure encodes predictive signals for new associations not captured by neighborhood methods or global recency, with the uniform smoothing step enabling a fair comparison across models. The temporal-split evaluation and multi-baseline design are strengths that could support practical tools for prioritizing scarce telescope follow-up if the extraction pipeline is validated.
major comments (2)
- [§3] §3 (graph construction pipeline): No precision, recall, or manual validation metrics are reported for the OCR-based object extraction or the subsequent SIMBAD identifier resolution steps. This is load-bearing for the central claim, as any systematic noise (e.g., broken identifiers, ambiguous catalog matches, or omitted real objects) would propagate into the temporal graph and could artifactually produce the reported 16.8% NDCG@100 and 19.8% Recall@100 gains of ALS over KNN rather than reflecting genuine predictive structure.
- [§4] §4 (evaluation): The manuscript provides no error bars, confidence intervals, or details on the exact data splits and concept clustering procedure used for the four temporal cutoffs. Without these, the statistical robustness of the performance deltas cannot be assessed, and it remains unclear whether the improvements hold under different clustering thresholds or train/test partitions.
minor comments (2)
- [Abstract and §3] The abstract and methods should explicitly state the total number of concepts, objects, and edges in the final graph to provide context for the scale of the prediction task.
- [§4] Notation for NDCG@100 and Recall@100 should be defined on first use in the main text, and the precise formulation of the concept-similarity smoothing (including the value of the free parameter) should be given in an equation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (graph construction pipeline): No precision, recall, or manual validation metrics are reported for the OCR-based object extraction or the subsequent SIMBAD identifier resolution steps. This is load-bearing for the central claim, as any systematic noise (e.g., broken identifiers, ambiguous catalog matches, or omitted real objects) would propagate into the temporal graph and could artifactually produce the reported 16.8% NDCG@100 and 19.8% Recall@100 gains of ALS over KNN rather than reflecting genuine predictive structure.
Authors: We agree that quantitative validation of the extraction and resolution steps is essential to support the central claims. In the revised manuscript we will add a dedicated subsection to §3 reporting precision, recall, and F1 scores obtained from manual annotation of a random sample of 500 extracted objects together with their SIMBAD resolutions. The section will also discuss common error modes and inter-annotator agreement. revision: yes
-
Referee: [§4] §4 (evaluation): The manuscript provides no error bars, confidence intervals, or details on the exact data splits and concept clustering procedure used for the four temporal cutoffs. Without these, the statistical robustness of the performance deltas cannot be assessed, and it remains unclear whether the improvements hold under different clustering thresholds or train/test partitions.
Authors: We acknowledge the need for greater statistical transparency. The revised §4 will include bootstrap-derived 95% confidence intervals for all metrics across the four cutoffs, explicit counts of training and test associations per split, and a sensitivity analysis showing how NDCG@100 and Recall@100 change when the concept-clustering threshold is varied by ±10%. revision: yes
Circularity Check
No significant circularity in the predictive modeling chain
full rationale
The paper constructs a concept-object graph via automated extraction and resolution, then applies temporal cutoffs to train an ALS implicit-feedback matrix factorization model on historical associations and evaluate its ability to forecast future edges. This is a standard supervised prediction setup with held-out future data; the reported NDCG@100 and Recall@100 gains are measured against independent baselines (KNN on text embeddings and recency heuristics) rather than being defined from the same fitted parameters. The inference-time concept-similarity smoothing is applied uniformly to every method, preserving relative comparisons without reducing any target metric to a self-defined quantity. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation. The central claim therefore remains self-contained against external benchmarks and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- concept-similarity smoothing strength
axioms (2)
- domain assumption Concepts obtained by clustering the corpus are semantically overlapping and therefore benefit from similarity smoothing
- domain assumption OCR-processed text plus SIMBAD resolution yields a sufficiently accurate bipartite graph for temporal prediction
Reference graph
Works this paper leans on
-
[1]
doi: https://doi.org/10.1016/j.socnet.2005.01.007
ISSN 0378-8733. doi: https://doi.org/10.1016/j.socnet.2005.01.007. URLhttps: //www.sciencedirect.com/science/article/pii/S0378873305000109. Milad Aghajohari, Mohammad Sadegh Akhondzadeh, Saleh Ashkboos, and Kamran Chitsaz. Degree-based feature is all you need: Science4cast report. In2021 IEEE International Conference on Big Data (Big Data), pp. 5791–5794,
-
[2]
doi: 10.1109/BigData52589.2021.9671530. Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for scientific text. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.),Proceedings of the 2019 Con- ference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Proce...
-
[3]
S ci BERT : A Pretrained Language Model for Scientific Text
Association for Computational Linguistics. doi: 10.18653/v1/D19-1371. URLhttps://aclanthology.org/D19-1371/. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya ...
-
[4]
Language Models are Few-Shot Learners
URL https://arxiv.org/abs/2005.14165. Aaron Clauset, Cristopher Moore, and M. E. J. Newman. Hierarchical structure and the prediction of missing links in networks.Nature, 453(7191):98–101, May
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[5]
ISSN 1476-4687. doi: 10.1038/nature06830. URLhttps://doi.org/10.1038/nature06830. Daniel Daza, Michael Cochez, and Paul Groth. Inductive entity representations from text via link prediction. InProceedings of the Web Conference 2021, WWW ’21, pp. 798–808, New York, NY , USA,
-
[6]
Association for Computing Machinery. ISBN 9781450383127. doi: 10.1145/ 3442381.3450141. URLhttps://doi.org/10.1145/3442381.3450141. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.),Proceedings of the...
-
[7]
Association for Com- putational Linguistics. doi: 10.18653/v1/N19-1423. URLhttps://aclanthology.org/ N19-1423/. G. Eichhorn. Linking in the astrophysics data system. In U. Grothkopf, H. Andernach, and S. Stevens-Rayburn (eds.),Library and Information Services in Astronomy III, volume 153 of Astronomical Society of the Pacific Conference Series. Astronomic...
-
[8]
URLhttps://arxiv.org/abs/2112.00590. 11 Xuemei Gu and Mario Krenn. Forecasting high-impact research topics via machine learning on evolving knowledge graphs,
-
[9]
URLhttps://arxiv.org/abs/2402.08640. arXiv preprint. (Journal reference listed on arXiv: Mach. Learn.: Sci. Technol. 6 025041 (2025)). Edwin Henneken. The ADS object search: How to find astronomical objects in the literature. NASA Astrophysics Data System Blog, September
-
[10]
ISSN 1532-0464. doi: https://doi. org/10.1016/j.jbi.2017.08.011. URLhttps://www.sciencedirect.com/science/ article/pii/S1532046417301909. Yifan Hu, Yehuda Koren, and Chris V olinsky. Collaborative filtering for implicit feedback datasets. In2008 Eighth IEEE International Conference on Data Mining, pp. 263–272,
-
[11]
Kalervo J¨arvelin and Jaana Kek ¨al¨ainen
1109/ICDM.2008.22. Kalervo J¨arvelin and Jaana Kek ¨al¨ainen. Cumulated gain-based evaluation of ir techniques.ACM Trans. Inf. Syst., 20(4):422–446, October
work page 2008
-
[12]
Cumulated gain-based evaluation of IR techniques.ACM Trans
ISSN 1046-8188. doi: 10.1145/582415.582418. URLhttps://doi.org/10.1145/582415.582418. Mario Krenn and Anton Zeilinger. Predicting research trends with semantic and neural networks with an application in quantum physics.Proceedings of the National Academy of Sciences, 117(4): 1910–1916,
-
[13]
URLhttps://www.pnas.org/doi/ abs/10.1073/pnas.1914370116
doi: 10.1073/pnas.1914370116. URLhttps://www.pnas.org/doi/ abs/10.1073/pnas.1914370116. David Liben-Nowell and Jon Kleinberg. The link-prediction problem for social networks.Journal of the American Society for Information Science and Technology, 58(7):1019–1031,
-
[14]
doi: https://doi.org/10.1002/asi.20591. URLhttps://onlinelibrary.wiley.com/doi/ abs/10.1002/asi.20591. Linyuan L¨u and Tao Zhou. Link prediction in complex networks: A survey.Physica A: Statistical Mechanics and its Applications, 390(6):1150–1170,
-
[15]
ISSN 0378-4371. doi: https://doi. org/10.1016/j.physa.2010.11.027. URLhttps://www.sciencedirect.com/science/ article/pii/S037843711000991X. Yiyuan Pu, Daniel Beck, and Karin Verspoor. Graph embedding-based link prediction for literature- based discovery in Alzheimer’s Disease.Journal of Biomedical Informatics, 145:104464,
-
[16]
Zechang Sun, Yuan-Sen Ting, Yaobo Liang, Nan Duan, Song Huang, and Zheng Cai
doi: 10.1016/j.jbi.2023.104464. Zechang Sun, Yuan-Sen Ting, Yaobo Liang, Nan Duan, Song Huang, and Zheng Cai. Knowledge graph in astronomical research with large language models: Quantifying driving forces in in- terdisciplinary scientific discovery,
-
[17]
Accepted to IJCAI 2024 AI4Research Workshop
URLhttps://arxiv.org/abs/2406.01391. Accepted to IJCAI 2024 AI4Research Workshop. Don R. Swanson. Undiscovered public knowledge.The Library Quarterly: Information, Commu- nity, Policy, 56(2):103–118,
-
[18]
ISSN 00242519, 1549652X. URLhttp://www.jstor. org/stable/4307965. Yuan-Sen Ting, Alberto Accomazzi, Tirthankar Ghosal, Tuan Dung Nguyen, Rui Pan, Zechang Sun, and Tijmen de Haan. Astromlab 5: Structured summaries and concept extraction for 400,000 astrophysics papers,
-
[19]
Accepted to AACL-IJCNLP 2025 W ASP Workshop
URLhttps://arxiv.org/abs/2511.12353. Accepted to AACL-IJCNLP 2025 W ASP Workshop. M. Wenger, F. Ochsenbein, D. Egret, P. Dubois, F. Bonnarel, S. Borde, F. Genova, G. Jasniewicz, S. Lalo¨e, S. Lesteven, and R. Monier. The SIMBAD astronomical database. The CDS reference database for astronomical objects.A&AS, 143:9–22, April
-
[20]
2000, A&AS, 143, 9, doi: 10.1051/aas:2000332
doi: 10.1051/aas:2000332. Liang Yao, Chengsheng Mao, and Yuan Luo. KG-BERT: BERT for knowledge graph completion,
work page internal anchor Pith review doi:10.1051/aas:2000332
-
[21]
doi:10.48550/arXiv.1909.03193 , abstract =
URLhttp://arxiv.org/abs/1909.03193. 12 A OBJECTEXTRACTIONOVERVIEW Astrophysical object mentions are extracted from each paper using GPT-5-mini, prompted with the paper’s arXiv ID, title, abstract, and full OCR text. The model is instructed to extract only named astrophysical objects suitable for SIMBAD-style resolution (e.g., standard stellar, galaxy, or ...
-
[22]
andγ σ is a study-mode multiplier capturing the nature of the analysis (Table 4). The role weight ranges from 3.0 for an object that is the primary subject of a study down to 0.25 for one mentioned only for calibration or comparison. The study- mode multiplier upweights new observations (1.25) and downweights theory-only mentions (0.90); a study mode of “...
-
[23]
Bold marks the best method per metric. The 9,999 concepts in our vocabulary span a wide range of topics, from core astrophysical phe- nomena (e.g., stellar evolution, galaxy mergers) to statistical methods, numerical techniques, and instrumental designs. These non-physical concepts can distort evaluation: a concept describing a specific telescope tends to...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.