Recognition: no theorem link
DistributedEstimator: Distributed Training of Quantum Neural Networks via Circuit Cutting
Pith reviewed 2026-05-15 21:40 UTC · model grok-4.3
The pith
A staged distributed pipeline for circuit-cut quantum neural network training preserves test accuracy and robustness on standard benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
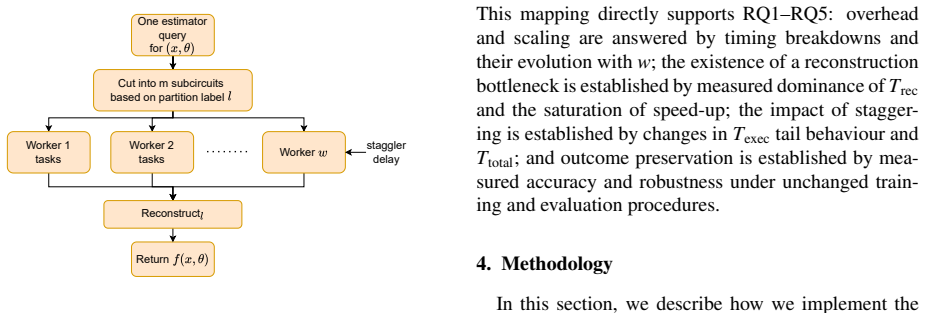
DistributedEstimator treats circuit cutting as a staged distributed workload and measures its impact on iterative QNN training. On Iris and MNIST, test accuracy is preserved without degradation across cut configurations, and robustness under Gaussian noise and FGSM attacks remains comparable or better than the uncut case. Reconstruction dominates runtime, reaching 53 percent median at three cuts, while subexperiment counts grow exponentially as O(9^c) for CNOT-based decomposition, limiting scalability to small qubit numbers.
What carries the argument
DistributedEstimator, a cut-aware estimator pipeline that instruments each query through partitioning, subexperiment generation, parallel execution, and classical reconstruction phases to handle distributed circuit cutting.
Load-bearing premise
The binary classification workloads on Iris and MNIST with the tested cut configurations are representative of general quantum neural network training scenarios.
What would settle it
An experiment on a different dataset or with additional cuts showing significant accuracy loss, or runtime traces that miss major hardware variability, would challenge the claims of preserved accuracy and measured overheads.
Figures





read the original abstract
Circuit cutting decomposes a large quantum circuit into smaller subcircuits whose outputs are classically reconstructed to recover original expectation values. While prior work characterises cutting overhead via subcircuit counts and sampling complexity, its end-to-end impact on iterative, estimator-driven training pipelines remains insufficiently measured from a systems perspective. We propose DistributedEstimator, a cut-aware estimator execution pipeline that treats circuit cutting as a staged distributed workload, instrumenting each query across four phases: partitioning, subexperiment generation, parallel execution, and classical reconstruction. Using logged runtime traces and learning outcomes on two binary classification workloads (Iris and MNIST), we quantify cutting overheads, scaling limits, and sensitivity to injected stragglers, and evaluate whether accuracy and robustness are preserved under matched training budgets. Reconstruction dominates per-query time -- reaching a median of 53% and 95th percentile of 58% at three cuts -- bounding achievable speed-up under parallelism. Despite these overheads, test accuracy is fully preserved on Iris and maintained without systematic degradation on MNIST across all cut configurations. Robustness under Gaussian noise and FGSM perturbations is similarly preserved, with several cut configurations exhibiting comparable or improved robustness relative to the uncut baseline. Exponential growth of subexperiment counts (${O}(9^c)$ for CNOT-based decomposition) is a fundamental barrier limiting practical experimentation to small qubit counts. These results establish that practical scaling for learning workloads requires reducing and overlapping reconstruction, scheduling policies for barrier-dominated critical paths, and computationally efficient reconstruction strategies for larger qubit counts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DistributedEstimator, a cut-aware pipeline for distributed QNN training that decomposes circuits into subcircuits, executes them in parallel, and classically reconstructs expectation values. Using runtime traces and learning outcomes on Iris and MNIST binary classification, it reports that reconstruction dominates per-query time (median 53% at three cuts), yet test accuracy is fully preserved on Iris and shows no systematic degradation on MNIST, with robustness to Gaussian noise and FGSM perturbations also maintained across cut counts.
Significance. If the results hold, the work supplies concrete systems-level measurements of circuit-cutting overheads in iterative estimator-driven training, highlighting reconstruction as the primary bottleneck and the O(9^c) subexperiment scaling barrier. It provides logged-trace data and robustness checks on standard workloads, which are useful for guiding future scheduling and reconstruction optimizations in distributed quantum ML.
major comments (2)
- [MNIST experiments] MNIST experiments section: The central claim that test accuracy is maintained without systematic degradation across cut configurations rests on final test accuracy values alone. No error bars, seed counts, or convergence curves are reported, leaving open whether preservation holds under the elevated estimator variance induced by finite-shot reconstruction (which scales with the number of terms in the O(9^c) sum).
- [Runtime analysis] Runtime and reconstruction analysis: The statement that reconstruction reaches a median of 53% of per-query time is derived from logged traces, but the manuscript does not specify the shot counts used per subcircuit or quantify how the resulting variance propagates into gradient estimates during training, which directly affects the validity of the accuracy-preservation conclusion.
minor comments (2)
- [Abstract] Abstract: The notation ${O}(9^c)$ should be written as O(9^C) for typographic consistency with the surrounding text.
- [Experimental setup] The description of hyperparameter matching between cut and uncut runs could be expanded to confirm identical optimizer settings, learning rates, and total query budgets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the MNIST experiments and runtime analysis sections. We address each major comment below and will revise the manuscript accordingly to provide greater statistical detail and clarifications while preserving the core claims.
read point-by-point responses
-
Referee: [MNIST experiments] MNIST experiments section: The central claim that test accuracy is maintained without systematic degradation across cut configurations rests on final test accuracy values alone. No error bars, seed counts, or convergence curves are reported, leaving open whether preservation holds under the elevated estimator variance induced by finite-shot reconstruction (which scales with the number of terms in the O(9^c) sum).
Authors: We agree that reporting only final accuracies leaves the robustness claim open to the variance concern. In the revised manuscript we will add error bars computed over multiple independent training runs (minimum 5 random seeds per cut configuration) together with representative convergence curves for training loss and test accuracy on MNIST. These additions will directly address whether the O(9^c)-induced variance prevents convergence to comparable minima. All runs used a fixed total shot budget matched to the uncut baseline; shots per subcircuit were scaled proportionally so that the comparison remains fair. The absence of systematic degradation across the reported configurations already suggests that the variance did not dominate training dynamics, but the new plots will make this explicit. revision: yes
-
Referee: [Runtime analysis] Runtime and reconstruction analysis: The statement that reconstruction reaches a median of 53% of per-query time is derived from logged traces, but the manuscript does not specify the shot counts used per subcircuit or quantify how the resulting variance propagates into gradient estimates during training, which directly affects the validity of the accuracy-preservation conclusion.
Authors: We will revise the runtime section to state the exact shot counts: each subcircuit received 1024 shots, with the total sampling budget held constant across cut and uncut cases (8192 shots for the uncut baseline). We will also add a short paragraph on variance propagation, noting that the reconstruction formula yields an unbiased estimator of the original expectation value; consequently the stochastic gradient estimates remain unbiased in expectation, albeit with variance that grows linearly with the number of reconstruction terms. Because the same optimizer and learning-rate schedule were used for all configurations, any effect of this extra variance is already reflected in the observed learning curves. We will reference the standard analysis of shot-noise scaling in variational algorithms to keep the discussion concise. revision: yes
Circularity Check
No circularity: purely empirical systems evaluation
full rationale
The paper describes an instrumentation pipeline for circuit-cut QNN training and reports measured runtime breakdowns plus accuracy/robustness outcomes on Iris and MNIST. All central claims (overhead fractions, accuracy preservation across cut counts, robustness under noise) are obtained directly from logged execution traces and standard training runs rather than from any mathematical derivation, fitted parameter, or self-referential equation. No load-bearing self-citation, uniqueness theorem, or ansatz is invoked to justify the results; the evaluation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Quantum circuits can be decomposed via CNOT-based cuts with reconstruction recovering exact expectation values under ideal conditions.
- domain assumption Runtime traces from the four-phase pipeline accurately reflect distributed execution costs on classical hardware.
Reference graph
Works this paper leans on
-
[1]
Preskill, Quantum computing in the NISQ era and beyond, Quantum 2 (2018) 79.doi:10
J. Preskill, Quantum computing in the NISQ era and beyond, Quantum 2 (2018) 79.doi:10. 22331/q-2018-08-06-79
work page 2018
-
[2]
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Ben- jamin, S. Endo, K. Fujii, J. R. McClean, K. Mi- tarai, X. Yuan, L. Cincio, P. J. Coles, Variational quantum algorithms, Nature Reviews Physics 3 (9) (2021) 625–644.doi:10.1038/s42254-021- 00348-9
-
[3]
S. Endo, Z. Cai, S. C. Benjamin, X. Yuan, Hy- brid quantum-classical algorithms and quantum error mitigation, Journal of the Physical Society of Japan 90 (3) (2021) 032001.doi:10.7566/ JPSJ.90.032001
work page 2021
-
[4]
M. Schuld, V . Bergholm, C. Gogolin, J. Izaac, N. Killoran, Evaluating analytic gradients on quantum hardware, Physical Review A 99 (3) (2019) 032331.doi:10.1103/PhysRevA.99. 032331
-
[5]
K. Temme, S. Bravyi, J. M. Gambetta, Error miti- gation for short-depth quantum circuits, Physical Review Letters 119 (18) (2017) 180509.doi: 10.1103/PhysRevLett.119.180509
work page internal anchor Pith review doi:10.1103/physrevlett.119.180509 2017
-
[6]
J. Dean, S. Ghemawat, MapReduce: Simplified data processing on large clusters, in: Proceedings of the 6th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2004, pp. 137–150. URLhttps://research.google.com/ archive/mapreduce-osdi04.pdf
work page 2004
-
[7]
M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, I. Stoica, Improving MapReduce performance in heterogeneous environments, in: Proceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2008. URLhttps://www.usenix.org/event/ osdi08/tech/full_papers/zaharia/
work page 2008
-
[8]
Horovod: fast and easy distributed deep learning in TensorFlow
A. Sergeev, M. Del Balso, Horovod: fast and easy distributed deep learning in TensorFlow, arXiv preprint arXiv:1802.05799 (2018).doi: 10.48550/arXiv.1802.05799
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.05799 2018
-
[9]
T. Peng, A. W. Harrow, M. Ozols, X. Wu, Sim- ulating large quantum circuits on a small quan- tum computer, Physical Review Letters 125 (15) (2020) 150504.doi:10.1103/PhysRevLett. 125.150504
-
[10]
W. Tang, T. Tomesh, M. Suchara, J. Larson, M. Martonosi, CutQC: Using small quantum com- puters for large quantum circuit evaluations, in: Proceedings of the 26th ACM International Con- ference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2021, pp. 473–486.doi:10.1145/3445814. 3446758
-
[11]
C. Piveteau, D. Sutter, Circuit knitting with clas- sical communication, IEEE Transactions on Infor- mation Theory 70 (5) (2024) 3001–3016, preprint: arXiv:2205.00016.doi:10.1109/TIT.2023. 3310797
-
[12]
A. W. Harrow, A. Lowe, Optimal quantum cir- cuit cuts with application to clustered Hamiltonian simulation, PRX Quantum 6 (1) (2025) 010316. doi:10.1103/PRXQuantum.6.010316
-
[13]
A. Lowe, M. Medvidovi ´c, A. Hayes, L. J. Romero, N. M. Tubman, D. Camps, Fast quantum circuit 15 cutting with randomized measurements, Quantum 7 (2023) 934.doi:10.22331/q-2023-03-02- 934
- [14]
- [15]
-
[16]
P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Elibol, Z. Yang, W. Paul, M. I. Jordan, I. Stoica, Ray: A distributed framework for emerging AI applications, in: Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2018. URLhttps://www.usenix.org/system/ files/osdi18-moritz.pdf
work page 2018
-
[17]
Qiskit Machine Learning Contributors, Qiskit machine learning,https://qiskit.org/ ecosystem/machine-learning/, accessed: 2026-04 (2024)
work page 2026
-
[18]
io/qiskit-addon-cutting/, accessed: 2026- 04 (2024)
Qiskit Addon Cutting Contributors, Circuit cutting with Qiskit addons,https://qiskit.github. io/qiskit-addon-cutting/, accessed: 2026- 04 (2024)
work page 2026
-
[19]
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, J. L. O’Brien, A variational eigenvalue solver on a pho- tonic quantum processor, Nature Communications 5 (2014) 4213.doi:10.1038/ncomms5213
-
[20]
N. Moll, P. Barkoutsos, L. S. Bishop, J. M. Chow, A. Cross, D. J. Egger, S. Filipp, A. Fuhrer, J. M. Gambetta, M. Ganzhorn, A. Kandala, et al., Quan- tum optimization using variational algorithms on near-term quantum devices, Quantum Science and Technology 3 (3) (2018) 030503.doi:10.1088/ 2058-9565/aab822
work page 2018
-
[21]
A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, J. M. Gambetta, Hardware- efficient variational quantum eigensolver for small molecules and quantum magnets, Nature 549 (7671) (2017) 242–246.doi:10.1038/ nature23879
work page 2017
-
[22]
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, S. Lloyd, Quantum machine learning, Nature 549 (7671) (2017) 195–202.doi:10. 1038/nature23474
work page 2017
-
[23]
K. Mitarai, M. Negoro, M. Kitagawa, K. Fu- jii, Quantum circuit learning, Physical Review A 98 (3) (2018) 032309.doi:10.1103/PhysRevA. 98.032309
-
[24]
V . Havlíˇcek, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, J. M. Gambetta, Supervised learning with quantum-enhanced fea- ture spaces, Nature 567 (7747) (2019) 209–212. doi:10.1038/s41586-019-0980-2
- [25]
-
[26]
J. R. McClean, S. Boixo, V . N. Smelyanskiy, R. Babbush, H. Neven, Barren plateaus in quan- tum neural network training landscapes, Nature Communications 9 (2018) 4812.doi:10.1038/ s41467-018-07090-4
work page 2018
-
[27]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, B. R. John- son, J. M. Gambetta, Quantum computing with Qiskit, arXiv preprint arXiv:2405.08810 (2024). doi:10.48550/arXiv.2405.08810
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.08810 2024
-
[28]
URLhttps://quantum.cloud.ibm.com/ docs/api/qiskit/primitives
IBM Quantum, Qiskit primitives API docu- mentation (Estimator and Sampler), Online documentation, accessed: 2026-04 (2024). URLhttps://quantum.cloud.ibm.com/ docs/api/qiskit/primitives
work page 2026
-
[29]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V . Bergholm, J. Izaac, M. Schuld, C. Gogolin, N. Killoran, et al., PennyLane: Automatic dif- ferentiation of hybrid quantum-classical compu- tations, arXiv preprint arXiv:1811.04968 (2018). doi:10.48550/arXiv.1811.04968. 16
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1811.04968 2018
-
[30]
M. Broughton, G. Verdon, T. McCourt, A. J. Martinez, J. H. Yoo, S. V . Isakov, P. Massey, R. Halavati, M. Y . Niu, A. Zlokapa, et al., TensorFlow Quantum: A software framework for quantum machine learning, arXiv preprint arXiv:2003.02989 (2020).doi:10.48550/ arXiv.2003.02989
-
[31]
M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauley, M. J. Franklin, S. Shenker, I. Stoica, Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing, in: Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2012. URLhttps://www.usenix.org/ conference/nsdi12/
work page 2012
-
[32]
M. Rocklin, Dask: Parallel computation with blocked algorithms and task scheduling, in: Pro- ceedings of the 14th Python in Science Conference (SciPy), 2015, pp. 126–132.doi:10.25080/ Majora-7b98e3ed-013
work page 2015
-
[33]
M. Li, D. G. Andersen, J. W. Park, A. J. Smola, A. Ahmed, V . Josifovski, J. Long, E. J. Shekita, B.-Y . Su, Scaling distributed machine learning with the parameter server, in: Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2014, pp. 583–598. URLhttps://www.usenix.org/ conference/osdi14/
work page 2014
-
[34]
Q. Ho, J. Cipar, H. Cui, J. K. Kim, S. Lee, P. B. Gibbons, G. Gibson, G. R. Ganger, E. P. Xing, More effective distributed ML via a stale synchronous parallel parameter server, in: Ad- vances in Neural Information Processing Systems (NeurIPS), 2013. URLhttps://papers.neurips.cc/paper/ 4894
work page 2013
- [35]
-
[36]
M. Cho, et al., BlueConnect: Decomposing all-reduce for deep learning on heterogeneous network hierarchy, in: Proceedings of Machine Learning and Systems (MLSys), 2019. URLhttps://mlsys.org/Conferences/ 2019/doc/2019/130.pdf
work page 2019
-
[37]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
P. Goyal, P. Dollár, R. B. Girshick, P. No- ordhuis, L. Wesolowski, A. Kyrola, A. Tul- loch, Y . Jia, K. He, Accurate, large mini- batch SGD: Training ImageNet in 1 hour, arXiv preprint arXiv:1706.02677 (2017).doi:10. 48550/arXiv.1706.02677
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
R. D. Blumofe, C. E. Leiserson, Scheduling mul- tithreaded computations by work stealing, Jour- nal of the ACM 46 (5) (1999) 720–748.doi: 10.1145/324133.324234
-
[39]
A. Carrera Vazquez, C. Tornow, D. Ristè, S. Wo- erner, M. Takita, D. J. Egger, Combining quan- tum processors with real-time classical communi- cation, Nature 636 (2024) 75–79.doi:10.1038/ s41586-024-08178-2
work page 2024
-
[40]
Garrison, et al., Circuit cutting with Quantum Serverless, IBM Research, accessed: 2026-04 (2023)
J. Garrison, et al., Circuit cutting with Quantum Serverless, IBM Research, accessed: 2026-04 (2023). URLhttps://research.ibm.com/ publications/circuit-cutting-with- quantum-serverless
work page 2026
-
[41]
I. Sitdikov, et al., Circuit knitting toolbox and quantum serverless, IBM Research, accessed: 2026-04 (2023). URLhttps://research.ibm.com/ publications/circuit-knitting- toolbox-and-quantum-serverless
work page 2026
-
[42]
C. Johnson, et al., Simulating larger quantum circuits with circuit cutting and Quantum Server- less, SC 2023 Poster, IBM Research, accessed: 2026-04 (2023). URLhttps://research.ibm.com/ publications/simulating-larger- quantum-circuits-with-circuit- cutting-and-quantum-serverless
work page 2023
-
[43]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, R. Fergus, In- triguing properties of neural networks, arXiv preprint arXiv:1312.6199 (2013).doi:10. 48550/arXiv.1312.6199
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[44]
I. J. Goodfellow, J. Shlens, C. Szegedy, Explain- ing and harnessing adversarial examples, in: Inter- national Conference on Learning Representations 17 (ICLR), 2015. URLhttps://arxiv.org/abs/1412.6572
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
Qiskit Contributors, Qiskit: An open-source framework for quantum computing,https:// qiskit.org, accessed: 2026-04 (2024)
work page 2026
-
[46]
Y . LeCun, L. Bottou, Y . Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE 86 (11) (1998) 2278–2324.doi:10.1109/5.726791
-
[47]
R. A. Fisher, The use of multiple measurements in taxonomic problems, Annals of Eugenics 7 (2) (1936) 179–188.doi:10.1111/j.1469-1809. 1936.tb02137.x
-
[48]
H. T. Nguyen, M. Usman, R. Buyya, Qfaas: A serverless function-as-a-service framework for quantum computing, Future Generation Computer Systems 154 (2024) 281–300.doi:https:// doi.org/10.1016/j.future.2024.01.018. URLhttps://www.sciencedirect.com/ science/article/pii/S0167739X24000189 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.