Recognition: no theorem link
RelianceScope: An Analytical Framework for Examining Students' Reliance on Generative AI Chatbots in Problem Solving
Pith reviewed 2026-05-15 21:37 UTC · model grok-4.3
The pith
RelianceScope defines nine patterns of student reliance on AI chatbots by combining modes of help-seeking and response-use within a knowledge context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RelianceScope operationalizes reliance into nine patterns based on combinations of engagement modes in help-seeking and response-use, and situates these patterns within a knowledge-context lens that accounts for students' prior knowledge and the instructional significance of knowledge components. Rather than prescribing optimal AI use, the framework enables fine-grained analysis of reliance in open-ended student-AI interactions.
What carries the argument
RelianceScope, the analytical framework that creates nine reliance patterns from combinations of engagement modes in help-seeking and response-use and overlays them with a knowledge-context lens of prior knowledge and instructional significance.
Load-bearing premise
Engagement modes in help-seeking and response-use can be reliably distinguished from chat and code logs and combined into nine educationally meaningful patterns, with the knowledge-context lens adding independent analytical value beyond the patterns.
What would settle it
Re-coding the same student logs by independent annotators yields low agreement on the nine patterns, or statistical tests show the knowledge-context lens adds no explanatory power beyond the patterns alone when predicting learning behaviors or outcomes.
Figures




read the original abstract
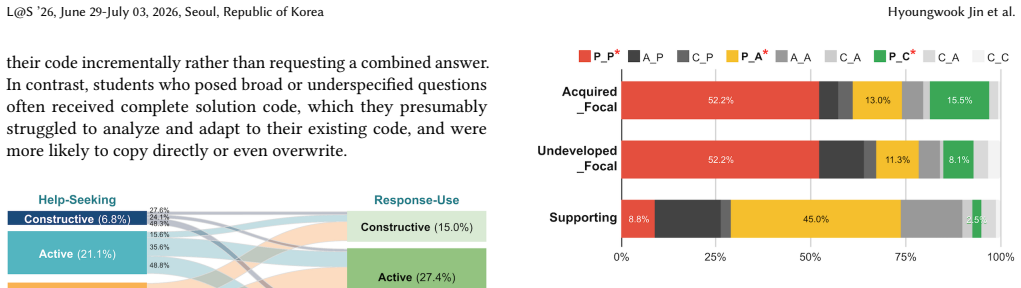
Generative AI chatbots enable personalized problem-solving, but effective learning requires students to self-regulate both how they seek help and how they use AI-generated responses. Considering engagement modes across these two actions reveals nuanced reliance patterns: for example, a student may actively engage in help-seeking by clearly specifying areas of need, yet engage passively in response-use by copying AI outputs, or vice versa. However, existing research lacks systematic tools for jointly capturing engagement across help-seeking and response-use, limiting the analysis of such reliance behaviors. We introduce RelianceScope, an analytical framework that characterizes students' reliance on chatbots during problem-solving. RelianceScope (1) operationalizes reliance into nine patterns based on combinations of engagement modes in help-seeking and response-use, and (2) situates these patterns within a knowledge-context lens that accounts for students' prior knowledge and the instructional significance of knowledge components. Rather than prescribing optimal AI use, the framework enables fine-grained analysis of reliance in open-ended student-AI interactions. As an illustrative application, we applied RelianceScope to analyze chat and code-edit logs from 79 college students in a web programming course. Results show that active help-seeking is associated with active response-use, whereas reliance patterns remain similar across knowledge mastery levels. Students often struggled to articulate their knowledge gaps and to adapt AI responses. Using our annotated dataset as a benchmark, we further demonstrate that large language models can reliably detect reliance during help-seeking and response-use. We conclude by discussing the implications of RelianceScope and the design guidelines for AI-supported educational systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RelianceScope, an analytical framework for characterizing students' reliance on generative AI chatbots in problem-solving. It operationalizes reliance into nine patterns from 3x3 combinations of engagement modes (active/passive/unclear) in help-seeking and response-use, then situates these patterns in a knowledge-context lens incorporating students' prior knowledge and the instructional significance of knowledge components. An illustrative application analyzes chat and code-edit logs from 79 college students in a web programming course, reporting that active help-seeking correlates with active response-use, that patterns are similar across knowledge mastery levels, that students struggle to articulate gaps and adapt responses, and that LLMs can reliably detect the patterns. The framework is positioned as enabling fine-grained analysis rather than prescribing optimal behaviors, with an annotated dataset offered as a benchmark.
Significance. If validated with rigorous methods, RelianceScope would offer a structured, reproducible way to analyze nuanced student-AI interaction patterns in open-ended problem-solving contexts, addressing a gap in tools for joint examination of help-seeking and response-use. The provision of an annotated dataset for LLM benchmarking and the demonstration of automated detection are concrete strengths that could support future work in AI-supported education. The knowledge-context lens, if shown to yield differential insights, could help move beyond generic reliance metrics toward educationally situated interpretations.
major comments (2)
- [Abstract / Illustrative application] Abstract and illustrative application: the report that reliance patterns remain similar across knowledge mastery levels directly tests the added value of the knowledge-context lens, yet no interactions, differential interpretations, or enriched analytical outcomes from incorporating prior knowledge and instructional significance are described. If the lens does not modify or extend the nine-pattern classification in observable ways, the framework's second component reduces to descriptive overlay without independent contribution; this requires explicit evidence (e.g., comparative analysis or examples) to support the central claim of a 'nuanced, situated characterization.'
- [Abstract] Abstract: the application to 79 students and the LLM detection claim rest on unshown methods, including coding schemes for engagement modes, inter-rater reliability metrics, data exclusion criteria, statistical tests for associations and cross-level similarity, and validation metrics (precision, recall, agreement) for the LLM detector. These details are load-bearing for reproducibility and for the claim that the framework 'enables fine-grained analysis,' as the nine patterns and their educational meaningfulness cannot be assessed without them.
minor comments (1)
- [Abstract] Abstract: the nine patterns are described as arising from 'combinations of engagement modes' but the exact three modes per dimension (help-seeking and response-use) and how 'unclear' is operationalized from logs are not specified; a brief enumeration or table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in clarifying the contributions of the knowledge-context lens and enhancing methodological transparency. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Illustrative application] Abstract and illustrative application: the report that reliance patterns remain similar across knowledge mastery levels directly tests the added value of the knowledge-context lens, yet no interactions, differential interpretations, or enriched analytical outcomes from incorporating prior knowledge and instructional significance are described. If the lens does not modify or extend the nine-pattern classification in observable ways, the framework's second component reduces to descriptive overlay without independent contribution; this requires explicit evidence (e.g., comparative analysis or examples) to support the central claim of a 'nuanced, situated characterization.'
Authors: We agree that the current illustrative application emphasizes similarity in pattern distributions across mastery levels, which does not fully showcase potential differential insights from the knowledge-context lens. The lens is designed to enable situated interpretations of the patterns rather than to predict changes in their prevalence. In the manuscript, we provide qualitative examples of how prior knowledge and instructional significance inform the interpretation of specific patterns (e.g., active help-seeking on high-significance components). To strengthen this, we will include a new subsection with comparative case studies demonstrating enriched analysis, such as how the same pattern (e.g., passive response-use) has different implications for learning depending on the knowledge component's instructional significance. This will be added in the revised version. revision: partial
-
Referee: [Abstract] Abstract: the application to 79 students and the LLM detection claim rest on unshown methods, including coding schemes for engagement modes, inter-rater reliability metrics, data exclusion criteria, statistical tests for associations and cross-level similarity, and validation metrics (precision, recall, agreement) for the LLM detector. These details are load-bearing for reproducibility and for the claim that the framework 'enables fine-grained analysis,' as the nine patterns and their educational meaningfulness cannot be assessed without them.
Authors: We acknowledge that the abstract, due to length constraints, does not include these methodological details, which are presented in the full manuscript (Sections 4.1-4.3 for coding and reliability, Section 4.4 for statistical analyses, and Section 5 for LLM validation with precision 0.87, recall 0.84, F1 0.85). To address this, we will revise the abstract to concisely incorporate key metrics (e.g., 'with inter-rater reliability κ=0.81 and LLM detection agreement of 0.86') and add a methods overview paragraph early in the paper. This ensures the abstract better supports the claims of fine-grained analysis and reproducibility. revision: yes
Circularity Check
No circularity: RelianceScope is a definitional framework with independent empirical application
full rationale
The paper introduces RelianceScope by explicitly defining nine reliance patterns from 3x3 combinations of help-seeking and response-use engagement modes, then situating them in a separate knowledge-context lens. No equations, fitted parameters, or self-citations reduce any result to its own inputs by construction. The illustrative analysis on 79 students reports observed associations and similarities across mastery levels as empirical findings, not as predictions forced by the framework definitions themselves. The derivation chain remains self-contained: patterns and lens are stipulated tools for analysis rather than outputs derived from data or prior self-referential claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Engagement modes in help-seeking and response-use can be categorized into distinct modes whose combinations form nine educationally relevant reliance patterns.
invented entities (1)
-
RelianceScope framework with nine patterns
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Eleni Adamopoulou and Lefteris Moussiades. 2020. An overview of chatbot technology. InIFIP international conference on artificial intelligence applications and innovations. Springer, 373–383
work page 2020
-
[2]
Mehdi Alaimi, Edith Law, Kevin Daniel Pantasdo, Pierre-Yves Oudeyer, and Hélène Sauzeon. 2020. Pedagogical agents for fostering question-asking skills in children. InProceedings of the 2020 CHI conference on human factors in computing systems. 1–13
work page 2020
-
[3]
Vincent Aleven and Kenneth R Koedinger. 2000. Limitations of student control: Do students know when they need help?. InInternational conference on intelligent tutoring systems. Springer, 292–303
work page 2000
-
[4]
Vincent Aleven, Bruce Mclaren, Ido Roll, and Kenneth Koedinger. 2006. To- ward meta-cognitive tutoring: A model of help seeking with a Cognitive Tutor. International journal of artificial intelligence in education16, 2 (2006), 101–128
work page 2006
-
[5]
Vincent Aleven, IDO Roll, Bruce M McLaren, and Kenneth R Koedinger. 2010. Automated, unobtrusive, action-by-action assessment of self-regulation during learning with an intelligent tutoring system.Educational Psychologist45, 4 (2010), 224–233
work page 2010
-
[6]
Vincent Aleven, Ido Roll, Bruce M McLaren, and Kenneth R Koedinger. 2016. Help helps, but only so much: Research on help seeking with intelligent tutoring systems.International Journal of Artificial Intelligence in Education26, 1 (2016), 205–223
work page 2016
-
[7]
Matin Amoozadeh, Daye Nam, Daniel Prol, Ali Alfageeh, James Prather, Michael Hilton, Sruti Srinivasa Ragavan, and Amin Alipour. 2024. Student-ai interaction: A case study of CS1 students. InProceedings of the 24th Koli Calling International Conference on Computing Education Research. 1–13
work page 2024
-
[8]
Roger Azevedo, John T Guthrie, and Diane Seibert. 2004. The role of self-regulated learning in fostering students’ conceptual understanding of complex systems with hypermedia.Journal of Educational Computing Research30, 1-2 (2004), 87–111
work page 2004
-
[9]
1997.Observing interaction: An introduction to sequential analysis
Roger Bakeman and John M Gottman. 1997.Observing interaction: An introduction to sequential analysis. Cambridge university press
work page 1997
-
[10]
Ryan Baker, Jason Walonoski, Neil Heffernan, Ido Roll, Albert Corbett, and Kenneth Koedinger. 2008. Why students engage in “gaming the system” behavior in interactive learning environments.Journal of Interactive Learning Research19, 2 (2008), 185–224
work page 2008
-
[11]
Hamsa Bastani, Osbert Bastani, Alp Sungu, Haosen Ge, Özge Kabakcı, and Rei Mariman. 2024. Generative AI can harm learning.The Wharton School Research Paper(2024)
work page 2024
-
[12]
Conrad Borchers, Kexin Yang, Jionghao Lin, Nikol Rummel, Kenneth R Koedinger, and Vincent Aleven. 2024. Combining dialog acts and skill modeling: What chat interactions enhance learning rates during ai-supported peer tutoring?. InProceedings of the 17th International Conference on Educational Data Mining. 117–130
work page 2024
-
[13]
Jaclyn Broadbent, E Panadero, JM Lodge, and Matthew Fuller-Tyszkiewicz. 2023. The self-regulation for learning online (SRL-O) questionnaire.Metacognition and Learning18, 1 (2023), 135–163
work page 2023
-
[14]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
work page 2020
-
[15]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z Gajos. 2021. To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making.Proceedings of the ACM on Human-computer Interaction5, CSCW1 (2021), 1–21
work page 2021
-
[16]
Seth Chaiklin et al . 2003. The zone of proximal development in Vygotsky’s analysis of learning and instruction.Vygotsky’s educational theory in cultural context1, 2 (2003), 39–64
work page 2003
-
[17]
Binglin Chen, Colleen M Lewis, Matthew West, and Craig Zilles. 2024. Plagiarism in the age of generative ai: cheating method change and learning loss in an intro to CS course. InProceedings of the Eleventh ACM Conference on Learning@ Scale. 75–85
work page 2024
-
[18]
Xinyue Chen, Kunlin Ruan, Kexin Phyllis Ju, Nathan Yap, and Xu Wang. 2025. More ai assistance reduces cognitive engagement: Examining the ai assistance dilemma in ai-supported note-taking.Proceedings of the ACM on Human- Computer Interaction9, 7 (2025), 1–29
work page 2025
-
[19]
Michelene TH Chi and Ruth Wylie. 2014. The ICAP framework: Linking cognitive engagement to active learning outcomes.Educational psychologist49, 4 (2014), 219–243
work page 2014
-
[20]
Dorottya Demszky, Jing Liu, Zid Mancenido, Julie Cohen, Heather Hill, Dan Jurafsky, and Tatsunori B Hashimoto. 2021. Measuring conversational uptake: A case study on student-teacher interactions. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language process...
work page 2021
-
[21]
Yaqi Fan and Fan Ouyang. 2026. Using Learning Analytics to Unveil Human–AI Collaborative Patterns Between High and Low Performance Students in Instruc- tional Design Activities.International Journal of Human–Computer Interaction (2026), 1–19
work page 2026
-
[22]
Yizhou Fan, Luzhen Tang, Huixiao Le, Kejie Shen, Shufang Tan, Yueying Zhao, Yuan Shen, Xinyu Li, and Dragan Gašević. 2025. Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motivation, processes, and performance.British Journal of Educational Technology56, 2 (2025), 489–530
work page 2025
-
[23]
Ben Gomes, Christopher Phillips, James Manyika, Lila Ibrahim, and Yossi Matias
-
[24]
AI and the Future of Learning. (2025)
work page 2025
-
[25]
Arthur C Graesser, Patrick Chipman, Brian C Haynes, and Andrew Olney. 2005. AutoTutor: An intelligent tutoring system with mixed-initiative dialogue.IEEE Transactions on Education48, 4 (2005), 612–618
work page 2005
-
[26]
Arthur C Graesser and Natalie K Person. 1994. Question asking during tutoring. American educational research journal31, 1 (1994), 104–137
work page 1994
-
[27]
Hacer Güner and Erkan Er. 2025. AI in the classroom: Exploring students’ interaction with ChatGPT in programming learning.Education and Information Technologies(2025), 1–27
work page 2025
-
[28]
Jieun Han, Haneul Yoo, Junho Myung, Minsun Kim, Tak Yeon Lee, So-Yeon Ahn, and Alice Oh. 2024. RECIPE4U: Student-ChatGPT interaction dataset in EFL writing education. (2024), 13666–13676
work page 2024
- [29]
-
[30]
Gaole He, Patrick Hemmer, Michael Vössing, Max Schemmer, and Ujwal Gadiraju
- [31]
-
[32]
Liqun He, Manolis Mavrikis, and Mutlu Cukurova. 2025. Towards Mining Ef- fective Pedagogical Strategies from Learner–LLM Educational Dialogues. In International Conference on Artificial Intelligence in Education. Springer, 391–396
work page 2025
-
[33]
Danial Hooshyar, Yeongwook Yang, Gustav Šíř, Tommi Kärkkäinen, Raija Hämäläinen, Mutlu Cukurova, and Roger Azevedo. 2025. Problems With Large Language Models for Learner Modelling: Why LLMs Alone Fall Short for Re- sponsible Tutoring in K–12 Education.arXiv preprint arXiv:2512.23036(2025)
-
[34]
Chenyu Hou, Gaoxia Zhu, Vidya Sudarshan, Fun Siong Lim, and Yew Soon Ong
-
[35]
Measuring undergraduate students’ reliance on Generative AI during problem-solving: Scale development and validation.Computers & Education (2025), 105329
work page 2025
-
[36]
Lujain Ibrahim, Saffron Huang, Lama Ahmad, Umang Bhatt, and Markus An- derljung. 2025. Towards interactive evaluations for interaction harms in human- AI systems. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 8. 1302–1310
work page 2025
-
[37]
Hyoungwook Jin, Seonghee Lee, Hyungyu Shin, and Juho Kim. 2024. Teach ai how to code: Using large language models as teachable agents for program- ming education. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–28
work page 2024
-
[38]
Stuart A Karabenick. 2003. Seeking help in large college classes: A person- centered approach.Contemporary educational psychology28, 1 (2003), 37–58
work page 2003
-
[39]
Majeed Kazemitabaar, Justin Chow, Carl Ka To Ma, Barbara J Ericson, David Weintrop, and Tovi Grossman. 2023. Studying the effect of AI code generators on supporting novice learners in introductory programming. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–23
work page 2023
-
[40]
Alison King. 1994. Guiding knowledge construction in the classroom: Effects of teaching children how to question and how to explain.American educational research journal31, 2 (1994), 338–368
work page 1994
-
[41]
Kenneth R Koedinger and Vincent Aleven. 2007. Exploring the assistance dilemma in experiments with cognitive tutors.Educational psychology review19, 3 (2007), 239–264
work page 2007
-
[42]
Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, and Pattie Maes. 2025. Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task.arXiv preprint arXiv:2506.088724 (2025)
work page internal anchor Pith review arXiv 2025
-
[43]
Tiffany Wenting Li, Yifan Song, Hari Sundaram, and Karrie Karahalios. 2025. Can Learners Navigate Imperfect Generative Pedagogical Chatbots? An Analysis of Chatbot Errors on Learning. InProceedings of the Twelfth ACM Conference on Learning@ Scale. 151–163
work page 2025
-
[44]
Benjamin Lira, Todd Rogers, Daniel G Goldstein, Lyle Ungar, and Angela L Duckworth. 2025. Learning not cheating: AI assistance can enhance rather than hinder skill development.Computers and Society15, 1 (2025), 14–30
work page 2025
-
[45]
Wenhan Lyu, Yimeng Wang, Tingting Chung, Yifan Sun, and Yixuan Zhang. 2024. Evaluating the effectiveness of llms in introductory computer science education: A semester-long field study. InProceedings of the eleventh ACM conference on learning@ scale. 63–74
work page 2024
-
[46]
Josep A Martín-Fernández, Carles Barceló-Vidal, and Vera Pawlowsky-Glahn
-
[47]
Dealing with zeros and missing values in compositional data sets using nonparametric imputation.Mathematical Geology35, 3 (2003), 253–278
work page 2003
-
[48]
Santosh A Mathan and Kenneth R Koedinger. 2018. Fostering the intelligent novice: Learning from errors with metacognitive tutoring. InComputers as Metacognitive Tools for Enhancing Learning. Routledge, 257–265
work page 2018
- [49]
-
[50]
Junho Myung, Hyunseung Lim, Hana Oh, Hyoungwook Jin, Nayeon Kang, So- Yeon Ahn, Hwajung Hong, Alice Oh, and Juho Kim. 2026. When Scaffolding Breaks: Investigating Student Interaction with LLM-Based Writing Support in Real-Time K-12 EFL Classrooms. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–18
work page 2026
- [51]
-
[52]
Sharon Nelson-Le Gall. 1981. Help-seeking: An understudied problem-solving skill in children.Developmental review1, 3 (1981), 224–246
work page 1981
-
[53]
2013.The design of everyday things: Revised and expanded edition
Don Norman. 2013.The design of everyday things: Revised and expanded edition. Basic books
work page 2013
-
[54]
OpenAI. 2025. Introducing study mode: A new way to learn in ChatGPT that offers step by step guidance instead of quick answers. https://openai.com/index/chatgpt- study-mode/. Accessed: 2026-01-19
work page 2025
-
[55]
Griffin Pitts, Neha Rani, Weedguet Mildort, and Eva-Marie Cook. 2025. Stu- dents’ reliance on ai in higher education: identifying contributing factors. In International Conference on Human-Computer Interaction. Springer, 86–97
work page 2025
-
[56]
James Prather, Brent N Reeves, Juho Leinonen, Stephen MacNeil, Arisoa S Randri- anasolo, Brett A Becker, Bailey Kimmel, Jared Wright, and Ben Briggs. 2024. The widening gap: The benefits and harms of generative ai for novice programmers. InProceedings of the 2024 ACM Conference on International Computing Education Research-Volume 1. 469–486
work page 2024
-
[57]
Johnmarshall Reeve and Ching-Mei Tseng. 2011. Agency as a fourth aspect of students’ engagement during learning activities.Contemporary educational psychology36, 4 (2011), 257–267
work page 2011
-
[58]
Steven Ritter, John R Anderson, Kenneth R Koedinger, and Albert Corbett. 2007. Cognitive tutor: Applied research in mathematics education.Psychonomic bulletin & review14, 2 (2007), 249–255
work page 2007
-
[59]
Ido Roll, Vincent Aleven, Bruce M McLaren, Eunjeong Ryu, Ryan SJ d Baker, and Kenneth R Koedinger. 2006. The help tutor: Does metacognitive feedback improve students’ help-seeking actions, skills and learning?. InInternational conference on intelligent tutoring systems. Springer, 360–369
work page 2006
-
[60]
Arvind Satyanarayan and Graham M Jones. 2024. Intelligence as agency: Eval- uating the capacity of generative AI to empower or constrain human action. (2024)
work page 2024
-
[61]
Brad Sheese, Mark Liffiton, Jaromir Savelka, and Paul Denny. 2024. Patterns of student help-seeking when using a large language model-powered programming assistant. InProceedings of the 26th Australasian computing education conference. 49–57
work page 2024
- [62]
-
[63]
Abdulhadi Shoufan. 2023. Exploring students’ perceptions of ChatGPT: Thematic analysis and follow-up survey.IEEE access11 (2023), 38805–38818
work page 2023
-
[64]
Ana Stojanov, Qian Liu, and Joyce Hwee Ling Koh. 2024. University students’ self- reported reliance on ChatGPT for learning: A latent profile analysis.Computers and Education: Artificial Intelligence6, 4 (2024), 100243
work page 2024
-
[65]
Dan Sun, Azzeddine Boudouaia, Chengcong Zhu, and Yan Li. 2024. Would ChatGPT-facilitated programming mode impact college students’ programming behaviors, performances, and perceptions? An empirical study.International Journal of Educational Technology in Higher Education21, 1 (2024), 14
work page 2024
-
[66]
Kodi Weatherholtz, Kelli Millwood Hill, Kristen DiCerbo, Walt Wells, Phillip Grimaldi, Maya Miller-Vedam, Charles Hogg, and Bogdan Yamkovenko. 2025. Cognitive Engagement in GenAI Tutor Conversations: At-scale Measurement and Impact on Learning. InProceedings of the Artificial Intelligence in Measurement and Education Conference (AIME-Con): Works in Progre...
work page 2025
-
[67]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
work page 2022
- [68]
-
[69]
Stephanie Yang, Hanzhang Zhao, Yudian Xu, Karen Brennan, and Bertrand Schnei- der. 2024. Debugging with an AI tutor: Investigating novice help-seeking be- haviors and perceived learning. InProceedings of the 2024 ACM Conference on International Computing Education Research-Volume 1. 84–94
work page 2024
-
[70]
Nesra Yannier, Scott E Hudson, and Kenneth R Koedinger. 2020. Active learning is about more than hands-on: A mixed-reality AI system to support STEM education. International Journal of Artificial Intelligence in Education30, 1 (2020), 74–96
work page 2020
-
[71]
Chunpeng Zhai, Santoso Wibowo, and Lily D Li. 2024. The effects of over-reliance on AI dialogue systems on students’ cognitive abilities: a systematic review.Smart Learning Environments11, 1 (2024), 28
work page 2024
-
[72]
Jiayi Zhang, Conrad Borchers, Vincent Aleven, and Ryan S Baker. 2024. Using large language models to detect self-regulated learning in think-aloud protocols. InProceedings of the 17th international conference on educational data mining. 157–168
work page 2024
-
[73]
Jiayu Zheng, Lingxin Hao, Kelun Lu, Ashi Garg, Mike Reese, Melo-Jean Yap, I-Jeng Wang, Xingyun Wu, Wenrui Huang, Jenna Hoffman, et al . 2025. Do Students Rely on AI? Analysis of Student-ChatGPT Conversations from a Field Study. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 8. 2796–2807
work page 2025
-
[74]
Yiqiu Zhou, Maciej Pankiewicz, Luc Paquette, and Ryan Baker. 2025. Impact of LLM Feedback on Learner Persistence in Programming. InInternational Confer- ence on Computers in Education
work page 2025
-
[75]
Barry J Zimmerman. 2002. Becoming a self-regulated learner: An overview. Theory into practice41, 2 (2002), 64–70
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.