Recognition: 2 theorem links
· Lean TheoremAdvSynGNN: Structure-Adaptive Graph Neural Nets via Adversarial Synthesis and Self-Corrective Propagation
Pith reviewed 2026-05-15 21:28 UTC · model grok-4.3
The pith
AdvSynGNN combines adversarial structure synthesis with residual label correction to improve graph neural network accuracy on noisy and heterophilous graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdvSynGNN establishes a framework that uses multi-resolution structural synthesis and contrastive objectives for geometry-sensitive initializations, a transformer backbone modulated by topological signals to handle heterophily, an adversarial propagation engine in which a generative component identifies potential connectivity alterations and a discriminator enforces global coherence, and a residual correction scheme guided by per-node confidence metrics to achieve stable iterative label refinement, resulting in optimized predictive accuracy across diverse graph distributions while preserving computational efficiency.
What carries the argument
The adversarial propagation engine, in which a generative component identifies potential connectivity alterations while a discriminator enforces global coherence, paired with a residual correction scheme guided by per-node confidence metrics.
If this is right
- Higher node classification accuracy holds across graphs with varying levels of structural noise.
- Adaptive attention in the transformer backbone improves handling of non-homophilous topologies.
- The overall architecture maintains computational efficiency suitable for large-scale graphs.
- Implementation protocols support reliable deployment without additional preprocessing steps.
Where Pith is reading between the lines
- The correction scheme could extend to dynamic graphs where edges change over time.
- Similar adversarial and residual mechanisms might reduce sensitivity to input noise in other representation learning models.
- Real-world applications could require less manual graph cleaning before training.
Load-bearing premise
The adversarial propagation engine and residual correction scheme integrate stably without introducing new instabilities or requiring extensive hyperparameter tuning.
What would settle it
A direct comparison on a standard heterophilous graph benchmark showing no accuracy gain over baseline graph neural networks or a measurable increase in training time.
Figures



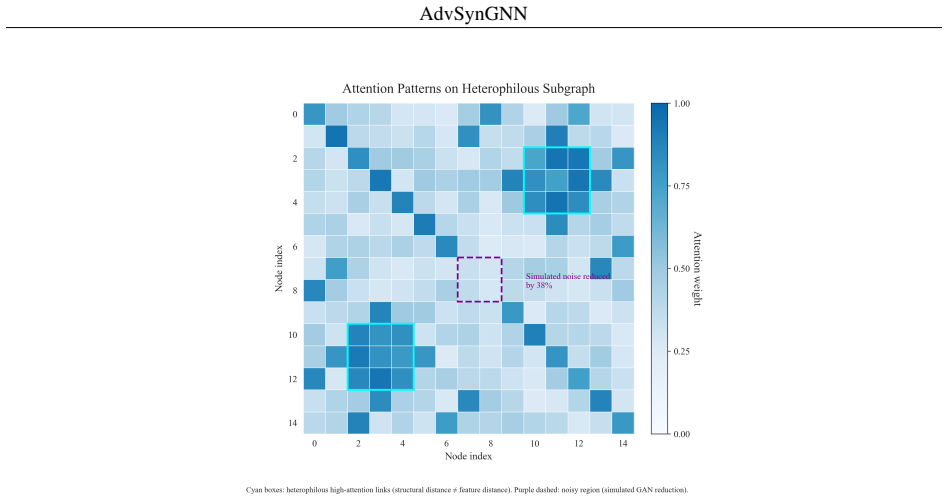
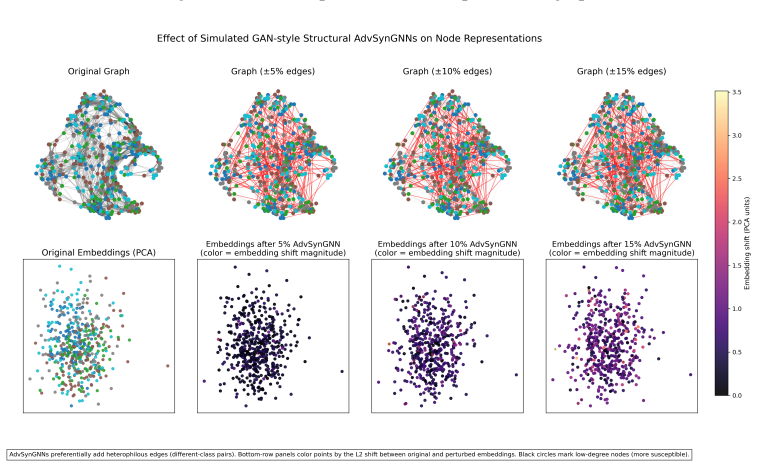
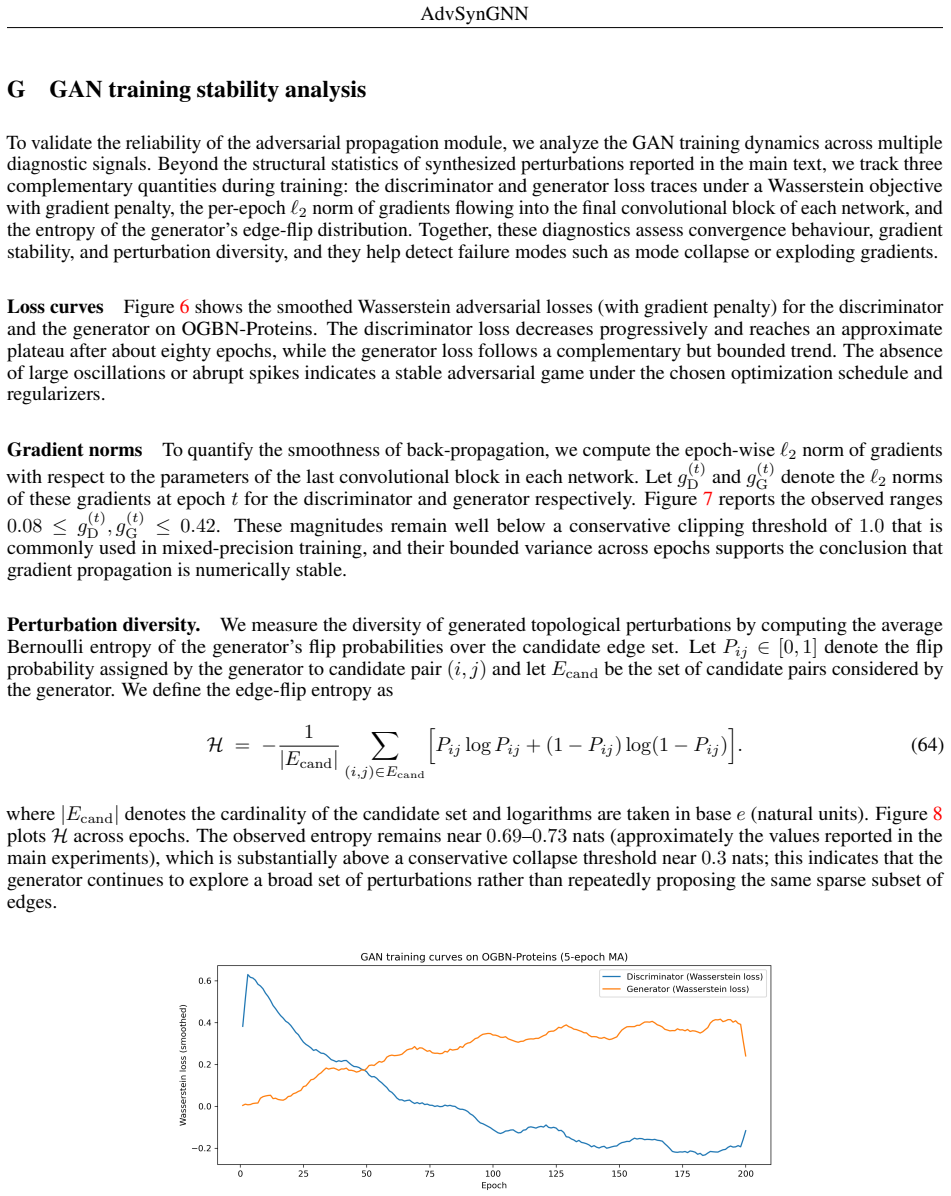

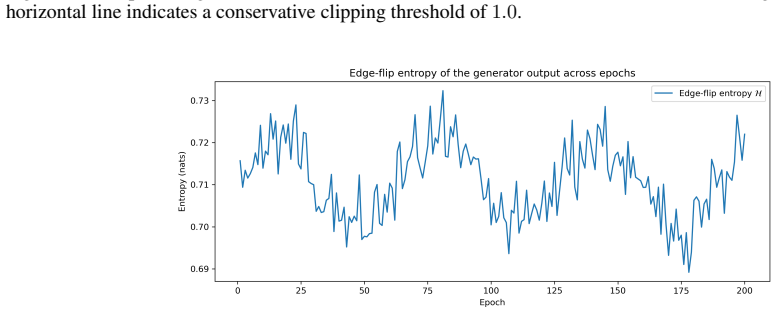
read the original abstract
Graph neural networks frequently encounter significant performance degradation when confronted with structural noise or non-homophilous topologies. To address these systemic vulnerabilities, we present AdvSynGNN, a comprehensive architecture designed for resilient node-level representation learning. The proposed framework orchestrates multi-resolution structural synthesis alongside contrastive objectives to establish geometry-sensitive initializations. We develop a transformer backbone that adaptively accommodates heterophily by modulating attention mechanisms through learned topological signals. Central to our contribution is an integrated adversarial propagation engine, where a generative component identifies potential connectivity alterations while a discriminator enforces global coherence. Furthermore, label refinement is achieved through a residual correction scheme guided by per-node confidence metrics, which facilitates precise control over iterative stability. Empirical evaluations demonstrate that this synergistic approach effectively optimizes predictive accuracy across diverse graph distributions while maintaining computational efficiency. The study concludes with practical implementation protocols to ensure the robust deployment of the AdvSynGNN system in large-scale environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AdvSynGNN, a graph neural network architecture for resilient node-level representation learning on graphs with structural noise or non-homophilous topologies. It integrates multi-resolution structural synthesis and contrastive objectives for geometry-sensitive initializations, a transformer backbone that modulates attention via learned topological signals to handle heterophily, an adversarial propagation engine (generator for connectivity alterations paired with a discriminator for global coherence), and a residual correction scheme for label refinement guided by per-node confidence metrics to ensure iterative stability. The central claim is that this synergistic design optimizes predictive accuracy across diverse graph distributions while preserving computational efficiency, with practical implementation protocols provided for large-scale deployment.
Significance. If the empirical claims hold with proper validation, the work could meaningfully advance GNN robustness by providing an integrated framework that simultaneously addresses structural synthesis, heterophily adaptation, and label stability through adversarial and residual mechanisms. This would be valuable for applications on noisy or heterophilous graphs where standard GNNs degrade, potentially improving reliability in domains like social networks or molecular graphs, especially if efficiency gains are demonstrated without hidden tuning costs.
major comments (3)
- [Abstract] Abstract: The central empirical claim that the synergistic approach 'effectively optimizes predictive accuracy across diverse graph distributions while maintaining computational efficiency' is stated without any reported metrics, baselines, ablation studies, error bars, or statistical tests. This absence is load-bearing because the reader's strongest claim and the paper's contribution rest entirely on these unshown evaluations.
- [Abstract] Abstract: No analysis or isolation is provided for the adversarial propagation engine's computational overhead (FLOPs/memory) versus a plain transformer GNN backbone, nor any stability checks under heterophily (e.g., attention oscillation or divergent refinement). This directly impacts the efficiency claim and the weakest assumption about stable integration without extensive tuning.
- [Abstract] Abstract: The per-node confidence metrics and residual correction scheme are described at a high level with no equations, convergence guarantees, or pseudocode, leaving open the risk of introduced instabilities that could undermine the claimed robustness.
minor comments (1)
- [Abstract] The abstract introduces multiple novel components (e.g., 'adversarial propagation engine', 'self-corrective propagation') without referencing related prior work on adversarial GNNs or residual label propagation, which would aid context.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive comments, which have helped us identify areas for improvement in our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that the synergistic approach 'effectively optimizes predictive accuracy across diverse graph distributions while maintaining computational efficiency' is stated without any reported metrics, baselines, ablation studies, error bars, or statistical tests. This absence is load-bearing because the reader's strongest claim and the paper's contribution rest entirely on these unshown evaluations.
Authors: We thank the referee for this comment. The abstract is a concise summary, but we recognize the need for supporting evidence. We will revise the abstract to include specific quantitative results, such as accuracy metrics on benchmark datasets with comparisons to baselines and error bars, drawn from our experimental evaluations. revision: yes
-
Referee: [Abstract] Abstract: No analysis or isolation is provided for the adversarial propagation engine's computational overhead (FLOPs/memory) versus a plain transformer GNN backbone, nor any stability checks under heterophily (e.g., attention oscillation or divergent refinement). This directly impacts the efficiency claim and the weakest assumption about stable integration without extensive tuning.
Authors: We acknowledge the importance of quantifying the overhead of the adversarial propagation engine. We will add a dedicated analysis in the experimental section of the revised manuscript, including FLOPs and memory comparisons to a plain transformer GNN, as well as stability evaluations under varying heterophily levels to demonstrate stable integration. revision: yes
-
Referee: [Abstract] Abstract: The per-node confidence metrics and residual correction scheme are described at a high level with no equations, convergence guarantees, or pseudocode, leaving open the risk of introduced instabilities that could undermine the claimed robustness.
Authors: We appreciate this observation regarding the lack of formal details. In the revision, we will include the mathematical definitions of the per-node confidence metrics and the residual correction scheme, along with pseudocode for the iterative refinement process and a discussion of its convergence properties to support the robustness claims. revision: yes
Circularity Check
No circularity detected; architecture claims rest on empirical evaluation without self-referential derivations or fitted predictions
full rationale
The provided abstract and context describe AdvSynGNN as an integrated framework using adversarial propagation, transformer attention modulation via learned signals, and residual label correction. No equations, fitting procedures, or derivation steps are visible that would reduce any claimed prediction or result to its own inputs by construction. No self-citation chains are invoked to justify uniqueness or ansatzes. The central claims are presented as empirical outcomes across graph distributions, which are independent of any internal circular reduction. This is the expected honest non-finding for a high-level architectural description lacking visible mathematical steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-node confidence thresholds
- attention modulation parameters
axioms (2)
- domain assumption Multi-resolution structural synthesis produces geometry-sensitive initializations that improve downstream learning
- domain assumption Adversarial generation of connectivity alterations can be balanced by a discriminator to enforce global coherence
invented entities (1)
-
adversarial propagation engine
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
adversarial propagation engine... residual correction scheme guided by per-node confidence metrics... heterophily-adaptive attention... spectral clipping and confidence capping
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem B.1 (Residual convergence)... contraction factor κ = max ci · ||eA||2 < 1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Andreea Deac, Marc Lackenby, and Petar Veli ˇckovi´c. Expander graph propagation. InLearning on Graphs Conference, pages 38–1. PMLR, 2022
work page 2022
-
[2]
p-laplacian based graph neural networks
Guoji Fu, Peilin Zhao, and Yatao Bian. p-laplacian based graph neural networks. InInternational conference on machine learning, pages 6878–6917. PMLR, 2022
work page 2022
-
[3]
Nafs: a simple yet tough-to-beat baseline for graph representation learning
Wentao Zhang, Zeang Sheng, Mingyu Yang, Yang Li, Yu Shen, Zhi Yang, and Bin Cui. Nafs: a simple yet tough-to-beat baseline for graph representation learning. InInternational Conference on Machine Learning, pages 26467–26483. PMLR, 2022
work page 2022
-
[4]
Qian Huang, Horace He, Abhay Singh, Ser-Nam Lim, and Austin R Benson. Combining label propagation and simple models out-performs graph neural networks.arXiv preprint arXiv:2010.13993, 2020
-
[5]
Chuxiong Sun, Jie Hu, Hongming Gu, Jinpeng Chen, Wei Liang, and Mingchuan Yang. Scalable and adaptive graph neural networks with self-label-enhanced training.Pattern Recognition, 160:111210, 2025
work page 2025
-
[6]
Xiran Song, Hong Huang, Jianxun Lian, and Hai Jin. Xgcn: a library for large-scale graph neural network recommendations.Frontiers of Computer Science, 18(3):183343, 2024
work page 2024
-
[7]
Yilun Zheng, Sitao Luan, and Lihui Chen. What is missing for graph homophily? disentangling graph homophily for graph neural networks.Advances in Neural Information Processing Systems, 37:68406–68452, 2024
work page 2024
-
[8]
Zhongjian Zhang, Xiao Wang, Huichi Zhou, Yue Yu, Mengmei Zhang, Cheng Yang, and Chuan Shi. Can large language models improve the adversarial robustness of graph neural networks? InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2008–2019, 2025
work page 2008
-
[9]
Hao Qian, Hongting Zhou, Qian Zhao, Hao Chen, Hongxiang Yao, Jingwei Wang, Ziqi Liu, Fei Yu, Zhiqiang Zhang, and Jun Zhou. Mdgnn: Multi-relational dynamic graph neural network for comprehensive and dynamic stock investment prediction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14642–14650, 2024
work page 2024
-
[10]
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering.Advances in neural information processing systems, 29, 2016
work page 2016
-
[11]
Semi-Supervised Classification with Graph Convolutional Networks
TN Kipf. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Sign: Scalable inception graph neural networks.arXiv preprint arXiv:2004.11198, 2020
Fabrizio Frasca, Emanuele Rossi, Davide Eynard, Ben Chamberlain, Michael Bronstein, and Federico Monti. Sign: Scalable inception graph neural networks.arXiv preprint arXiv:2004.11198, 2020
-
[14]
Plain transformers can be powerful graph learners.arXiv preprint arXiv:2504.12588, 2025
Liheng Ma, Soumyasundar Pal, Yingxue Zhang, Philip HS Torr, and Mark Coates. Plain transformers can be powerful graph learners.arXiv preprint arXiv:2504.12588, 2025
-
[15]
Sunil Kumar Maurya, Xin Liu, and Tsuyoshi Murata. Simplifying approach to node classification in graph neural networks.Journal of Computational Science, 62:101695, 2022
work page 2022
-
[16]
Zhiqian Chen, Fanglan Chen, Lei Zhang, Taoran Ji, Kaiqun Fu, Liang Zhao, Feng Chen, Lingfei Wu, Charu Aggarwal, and Chang-Tien Lu. Bridging the gap between spatial and spectral domains: A unified framework for graph neural networks.ACM Computing Surveys, 56(5):1–42, 2023. 11 AdvSynGNN
work page 2023
-
[17]
Derek Lim, Felix Hohne, Xiuyu Li, Sijia Linda Huang, Vaishnavi Gupta, Omkar Bhalerao, and Ser Nam Lim. Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods.Advances in neural information processing systems, 34:20887–20902, 2021
work page 2021
-
[18]
Feature transportation improves graph neural networks
Moshe Eliasof, Eldad Haber, and Eran Treister. Feature transportation improves graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11874–11882, 2024
work page 2024
-
[19]
Dong Li, Aijia Zhang, Huan Xiong, Biqing Qi, and Junqi Gao. Fdphormer: beyond homophily with feature- difference position encoding.ACM Transactions on Knowledge Discovery from Data, 19(5):1–19, 2025
work page 2025
-
[20]
Hgphormer: Heterophilic graph transformer.Knowledge-Based Systems, page 114031, 2025
Jianshe Wu, Yaolin Liu, Yuqian Wang, Lingjie Zhang, and Jingyi Ding. Hgphormer: Heterophilic graph transformer.Knowledge-Based Systems, page 114031, 2025
work page 2025
-
[21]
Chao Li, Zijie Guo, Kun He, et al. Long-range meta-path search on large-scale heterogeneous graphs.Advances in Neural Information Processing Systems, 37:44240–44268, 2024
work page 2024
-
[22]
Yuanhang Shao and Xiuwen Liu. Nonlinear correct and smooth for graph-based semi-supervised learning.ACM Transactions on Knowledge Discovery from Data, 19(3):1–32, 2025
work page 2025
-
[23]
Yuqiang Li, Yi Zhang, and Chun Liu. Mdgcl: Graph contrastive learning framework with multiple graph diffusion methods.Neural Processing Letters, 56(4):213, 2024
work page 2024
-
[24]
Adversarial contrastive graph augmentation with counterfactual regularization
Tao Long, Lei Zhang, Liang Zhang, and Laizhong Cui. Adversarial contrastive graph augmentation with counterfactual regularization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 19086–19094, 2025
work page 2025
-
[25]
Xin Zhang, Jie Liu, Xi Zhang, and Yanglong Lu. Self-supervised graph feature enhancement and scale attention for mechanical signal node-level representation and diagnosis.Advanced Engineering Informatics, 65:103197, 2025
work page 2025
-
[26]
Zixing Song, Xiangli Yang, Zenglin Xu, and Irwin King. Graph-based semi-supervised learning: A comprehensive review.IEEE Transactions on Neural Networks and Learning Systems, 34(11):8174–8194, 2022
work page 2022
-
[27]
Taxonomy of benchmarks in graph representation learning
Renming Liu, Semih Cantürk, Frederik Wenkel, Sarah McGuire, Xinyi Wang, Anna Little, Leslie O’Bray, Michael Perlmutter, Bastian Rieck, Matthew Hirn, et al. Taxonomy of benchmarks in graph representation learning. In Learning on Graphs Conference, pages 6–1. PMLR, 2022
work page 2022
-
[28]
Xingtai Gui, Di Wu, Yang Chang, and Shicai Fan. Constrained adaptive projection with pretrained features for anomaly detection.arXiv preprint arXiv:2112.02597, 2021
-
[29]
Zhaoliang Chen, Zhihao Wu, Ylli Sadikaj, Claudia Plant, Hong-Ning Dai, Shiping Wang, Yiu-Ming Cheung, and Wenzhong Guo. Adedgedrop: Adversarial edge dropping for robust graph neural networks.IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[30]
Na Chen, Ping Li, Jincheng Huang, and Kai Zhang. Denoising structure against adversarial attacks on graph representation learning.ACM Transactions on Intelligent Systems and Technology, 16(3):1–23, 2025
work page 2025
-
[31]
Tianjun Yao, Haoxuan Li, Yongqiang Chen, Tongliang Liu, Le Song, Eric Xing, and Zhiqiang Shen. Pruning spurious subgraphs for graph out-of-distribtuion generalization.arXiv preprint arXiv:2506.05957, 2025
-
[32]
Xuexin Chen, Ruichu Cai, Kaitao Zheng, Zhifan Jiang, Zhengting Huang, Zhifeng Hao, and Zijian Li. Unifying invariant and variant features for graph out-of-distribution via probability of necessity and sufficiency.Neural Networks, 184:107044, 2025
work page 2025
-
[33]
Yancheng Wang, Changyu Liu, and Yingzhen Yang. Diffusion on graph: Augmentation of graph structure for node classification.arXiv preprint arXiv:2503.12563, 2025
-
[34]
Shiping Wang, Jiacheng Li, Yuhong Chen, Zhihao Wu, Aiping Huang, and Le Zhang. Multi-scale graph diffusion convolutional network for multi-view learning.Artificial Intelligence Review, 58(6):184, 2025
work page 2025
-
[35]
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform badly for graph representation?Advances in neural information processing systems, 34:28877–28888, 2021. 12 AdvSynGNN
work page 2021
-
[36]
Goat: A global transformer on large-scale graphs
Kezhi Kong, Jiuhai Chen, John Kirchenbauer, Renkun Ni, C Bayan Bruss, and Tom Goldstein. Goat: A global transformer on large-scale graphs. InInternational Conference on Machine Learning, pages 17375–17390. PMLR, 2023
work page 2023
-
[37]
Graph positional encoding via random feature propagation
Moshe Eliasof, Fabrizio Frasca, Beatrice Bevilacqua, Eran Treister, Gal Chechik, and Haggai Maron. Graph positional encoding via random feature propagation. InInternational Conference on Machine Learning, pages 9202–9223. PMLR, 2023
work page 2023
-
[38]
Nlgt: Neighborhood-based and label-enhanced graph transformer framework for node classification
Xiaolong Xu, Yibo Zhou, Haolong Xiang, Xiaoyong Li, Xuyun Zhang, Lianyong Qi, and Wanchun Dou. Nlgt: Neighborhood-based and label-enhanced graph transformer framework for node classification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 12954–12962, 2025
work page 2025
-
[39]
Han Zhang, Huan Wang, and Mingjing Han. Hopgat: A multi-hop graph attention network with heterophily and degree awareness.Pattern Recognition, page 112387, 2025
work page 2025
-
[40]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Gins- burg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training.arXiv preprint arXiv:1710.03740, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
Towards scalable and deep graph neural networks via noise masking
Yuxuan Liang, Wentao Zhang, Zeang Sheng, Ling Yang, Quanqing Xu, Jiawei Jiang, Yunhai Tong, and Bin Cui. Towards scalable and deep graph neural networks via noise masking. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18693–18701, 2025
work page 2025
-
[43]
Zheng Qu, Dimin Niu, Shuangchen Li, Hongzhong Zheng, and Yuan Xie. Tt-gnn: Efficient on-chip graph neural network training via embedding reformation and hardware optimization. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, pages 452–464, 2023
work page 2023
-
[44]
Rsc: accelerate graph neural networks training via randomized sparse computations
Zirui Liu, Chen Shengyuan, Kaixiong Zhou, Daochen Zha, Xiao Huang, and Xia Hu. Rsc: accelerate graph neural networks training via randomized sparse computations. InInternational Conference on Machine Learning, pages 21951–21968. PMLR, 2023
work page 2023
-
[45]
Linear-time graph neural networks for scalable recommendations
Jiahao Zhang, Rui Xue, Wenqi Fan, Xin Xu, Qing Li, Jian Pei, and Xiaorui Liu. Linear-time graph neural networks for scalable recommendations. InProceedings of the ACM Web Conference 2024, pages 3533–3544, 2024
work page 2024
-
[46]
Accurate and scalable graph neural networks for billion-scale graphs
Juxiang Zeng, Pinghui Wang, Lin Lan, Junzhou Zhao, Feiyang Sun, Jing Tao, Junlan Feng, Min Hu, and Xiaohong Guan. Accurate and scalable graph neural networks for billion-scale graphs. In2022 IEEE 38th International Conference on Data Engineering (ICDE), pages 110–122. IEEE, 2022
work page 2022
-
[47]
Scgc: Self-supervised contrastive graph clustering.Neurocomputing, 611:128629, 2025
Gayan K Kulatilleke, Marius Portmann, and Shekhar S Chandra. Scgc: Self-supervised contrastive graph clustering.Neurocomputing, 611:128629, 2025
work page 2025
-
[48]
Gongpei Zhao, Tao Wang, Congyan Lang, Yi Jin, Yidong Li, and Haibin Ling. Dfa-gnn: Forward learning of graph neural networks by direct feedback alignment.Advances in Neural Information Processing Systems, 37: 59289–59313, 2024
work page 2024
-
[49]
Brettler Liad, Berman Eden, Bartal Alon, et al. Drugnnosis-moa: Elucidating drug mechanisms as etiological or palliative with graph neural networks employing a large language model.IEEE Journal of Biomedical and Health Informatics, 2025
work page 2025
-
[50]
Label information enhanced fraud detection against low homophily in graphs
Yuchen Wang, Jinghui Zhang, Zhengjie Huang, Weibin Li, Shikun Feng, Ziheng Ma, Yu Sun, Dianhai Yu, Fang Dong, Jiahui Jin, et al. Label information enhanced fraud detection against low homophily in graphs. In Proceedings of the ACM Web Conference 2023, pages 406–416, 2023
work page 2023
-
[51]
Braingb: a benchmark for brain network analysis with graph neural networks
Hejie Cui, Wei Dai, Yanqiao Zhu, Xuan Kan, Antonio Aodong Chen Gu, Joshua Lukemire, Liang Zhan, Lifang He, Ying Guo, and Carl Yang. Braingb: a benchmark for brain network analysis with graph neural networks. IEEE transactions on medical imaging, 42(2):493–506, 2022
work page 2022
-
[52]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020. 13 AdvSynGNN
work page 2020
-
[53]
Ags-gnn: Attribute-guided sampling for graph neural networks
Siddhartha Shankar Das, SM Ferdous, Mahantesh M Halappanavar, Edoardo Serra, and Alex Pothen. Ags-gnn: Attribute-guided sampling for graph neural networks. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 538–549, 2024
work page 2024
-
[54]
Zixing Song, Yifei Zhang, and Irwin King. Optimal block-wise asymmetric graph construction for graph-based semi-supervised learning.Advances in Neural Information Processing Systems, 36:71135–71149, 2023
work page 2023
-
[55]
Toward effective digraph representation learning: A magnetic adaptive propagation based approach
Xunkai Li, Daohan Su, Zhengyu Wu, Guang Zeng, Hongchao Qin, Rong-Hua Li, and Guoren Wang. Toward effective digraph representation learning: A magnetic adaptive propagation based approach. InProceedings of the ACM on Web Conference 2025, pages 2908–2923, 2025
work page 2025
-
[56]
Beyond graph convolution: Multimodal recommendation with topology-aware mlps
Junjie Huang, Jiarui Qin, Yong Yu, and Weinan Zhang. Beyond graph convolution: Multimodal recommendation with topology-aware mlps. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11808–11816, 2025
work page 2025
-
[57]
Kaize Ding. Data-efficient graph learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 22663–22663, 2024
work page 2024
-
[58]
Ogb-lsc: A large-scale challenge for machine learning on graphs.arXiv preprint arXiv:2103.09430,
Weihua Hu, Matthias Fey, Hongyu Ren, Maho Nakata, Yuxiao Dong, and Jure Leskovec. Ogb-lsc: A large-scale challenge for machine learning on graphs.arXiv preprint arXiv:2103.09430, 2021
-
[59]
Graphgan: Graph representation learning with generative adversarial nets
Hongwei Wang, Jia Wang, Jialin Wang, Miao Zhao, Weinan Zhang, Fuzheng Zhang, Xing Xie, and Minyi Guo. Graphgan: Graph representation learning with generative adversarial nets. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[60]
Ladislav Rampášek, Michael Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. Recipe for a general, powerful, scalable graph transformer.Advances in Neural Information Processing Systems, 35:14501–14515, 2022
work page 2022
-
[61]
Junhan Yang, Zheng Liu, Shitao Xiao, Chaozhuo Li, Defu Lian, Sanjay Agrawal, Amit Singh, Guangzhong Sun, and Xing Xie. Graphformers: Gnn-nested transformers for representation learning on textual graph.Advances in Neural Information Processing Systems, 34:28798–28810, 2021
work page 2021
-
[62]
George B Moody and Roger G Mark. The impact of the mit-bih arrhythmia database.IEEE engineering in medicine and biology magazine, 20(3):45–50, 2001
work page 2001
-
[63]
Marco Cuturi. Fast global alignment kernels. InProceedings of the 28th international conference on machine learning (ICML-11), pages 929–936, 2011
work page 2011
-
[64]
Aline Elly Treml, R Andrade Flauzino, Marcelo Suetake, NA Ravazzoli Maciejewski, and N Afonso. Experimental database for detecting and diagnosing rotor broken bar in a three-phase induction motor.IEEE DataPort, 2020
work page 2020
-
[65]
Jinsung Yoon, Daniel Jarrett, and Mihaela Van der Schaar. Time-series generative adversarial networks.Advances in neural information processing systems, 32, 2019
work page 2019
-
[66]
Conditional sig-wasserstein gans for time series generation.arXiv preprint arXiv:2006.05421, 2020
Shujian Liao, Hao Ni, Lukasz Szpruch, Magnus Wiese, Marc Sabate-Vidales, and Baoren Xiao. Conditional sig-wasserstein gans for time series generation.arXiv preprint arXiv:2006.05421, 2020
-
[67]
Generative moment matching networks
Yujia Li, Kevin Swersky, and Rich Zemel. Generative moment matching networks. InInternational conference on machine learning, pages 1718–1727. PMLR, 2015
work page 2015
-
[68]
Rcgan: learning a generative model for arbitrary size image generation
Renato B Arantes, George V ogiatzis, and Diego R Faria. Rcgan: learning a generative model for arbitrary size image generation. InInternational Symposium on Visual Computing, pages 80–94. Springer, 2020
work page 2020
-
[69]
Gat-gan: A graph-attention-based time-series generative adversarial network
Srikrishna Iyer and Teng Teck Hou. Gat-gan: A graph-attention-based time-series generative adversarial network. arXiv preprint arXiv:2306.01999, 2023
-
[70]
Ming Zhao and Yinglong Zhang. Gan-based deep neural networks for graph representation learning.Engineering Reports, 4(11):e12517, 2022
work page 2022
-
[71]
Gan-based self-supervised message passing graph representation learning
Yining Yang, Ke Xu, and Ying Tang. Gan-based self-supervised message passing graph representation learning. Expert Systems with Applications, 251:124012, 2024. 14 AdvSynGNN
work page 2024
-
[72]
Att-gan: A deep learning model for dynamic network weighted link prediction
Shun Tang and Xiaoqiang Xiao. Att-gan: A deep learning model for dynamic network weighted link prediction. In2021 IEEE 3rd International Conference on Frontiers Technology of Information and Computer (ICFTIC), pages 15–20. IEEE, 2021
work page 2021
-
[73]
Tengan: Pure transformer encoders make an efficient discrete gan for de novo molecular generation
Chen Li and Yoshihiro Yamanishi. Tengan: Pure transformer encoders make an efficient discrete gan for de novo molecular generation. InInternational Conference on Artificial Intelligence and Statistics, pages 361–369. PMLR, 2024
work page 2024
-
[74]
Graph transformer gans for graph-constrained house generation
Hao Tang, Zhenyu Zhang, Humphrey Shi, Bo Li, Ling Shao, Nicu Sebe, Radu Timofte, and Luc Van Gool. Graph transformer gans for graph-constrained house generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2173–2182, 2023
work page 2023
-
[75]
Graph transformers for large graphs.arXiv preprint arXiv:2312.11109, 2023
Vijay Prakash Dwivedi, Yozen Liu, Anh Tuan Luu, Xavier Bresson, Neil Shah, and Tong Zhao. Graph transformers for large graphs.arXiv preprint arXiv:2312.11109, 2023
-
[76]
Qitian Wu, Wentao Zhao, Chenxiao Yang, Hengrui Zhang, Fan Nie, Haitian Jiang, Yatao Bian, and Junchi Yan. Sgformer: Simplifying and empowering transformers for large-graph representations.Advances in Neural Information Processing Systems, 36:64753–64773, 2023
work page 2023
-
[77]
Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
Péter Mernyei and C˘at˘alina Cangea. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
-
[78]
Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks
Wei-Lin Chiang, Xuanqing Liu, Si Si, Yang Li, Samy Bengio, and Cho-Jui Hsieh. Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 257–266, 2019
work page 2019
-
[79]
Qi Zhang, Mengmeng Si, Yanfeng Sun, Shaofan Wang, Junbin Gao, and Baocai Yin. Gfformer: A graph transformer for extracting all frequency information from large-scale graphs.ACM Transactions on Knowledge Discovery from Data, 2024
work page 2024
-
[80]
Dongqi Fu, Zhigang Hua, Yan Xie, Jin Fang, Si Zhang, Kaan Sancak, Hao Wu, Andrey Malevich, Jingrui He, and Bo Long. Vcr-graphormer: A mini-batch graph transformer via virtual connections.arXiv preprint arXiv:2403.16030, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.