EAGLE: Expert-Augmented Attention Guidance for Tuning-Free Industrial Anomaly Detection in Multimodal Large Language Models
Pith reviewed 2026-05-15 21:00 UTC · model grok-4.3
The pith
EAGLE guides frozen multimodal large language models with expert detector outputs to raise industrial anomaly detection accuracy without any model updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
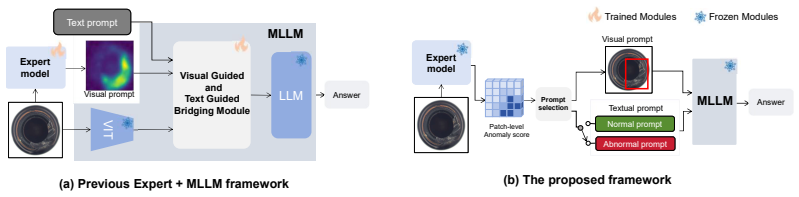
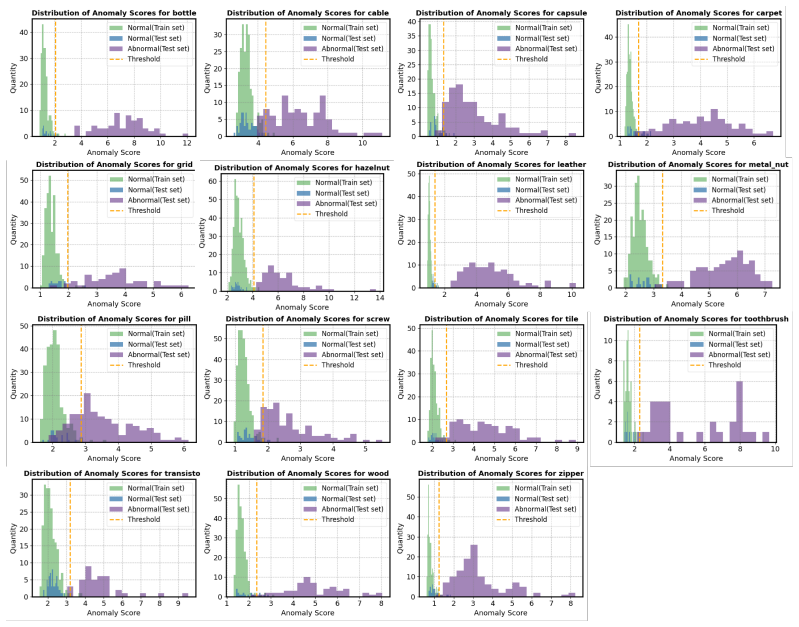
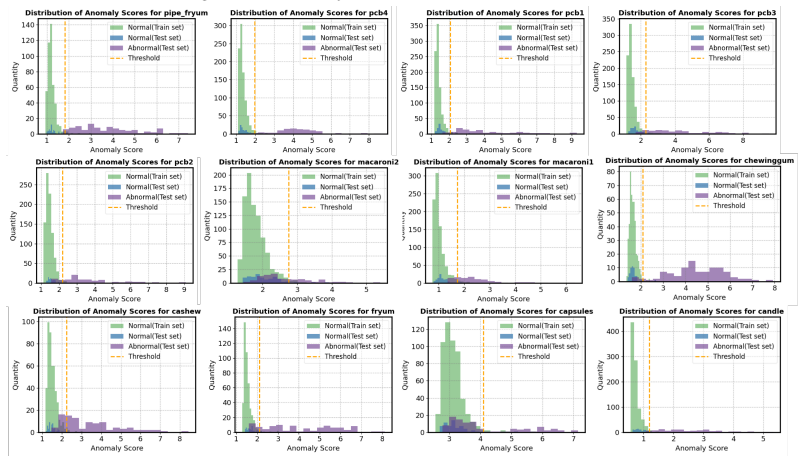
EAGLE integrates an expert anomaly detector with frozen MLLMs through Threshold-Guided Prompt Selection that derives a decision threshold from expert statistics to choose textual and visual prompts, and through Confidence-Aware Attention Sharpening that redirects MLLM attention toward visual evidence when expert confidence is low; this raises anomaly discrimination accuracy to 94.4 percent on MVTec-AD and 88.1 percent on VisA across five MLLM backbones and produces attention maps that align more closely with ground-truth defect regions.
What carries the argument
Threshold-Guided Prompt Selection (TGPS) and Confidence-Aware Attention Sharpening (CAAS), which convert expert statistics into prompts and adjust MLLM attention weights based on expert confidence levels.
If this is right
- Five different MLLM backbones gain accuracy on MVTec-AD and VisA without parameter changes.
- Detection performance becomes competitive with methods that require fine-tuning the MLLM.
- The original semantic reasoning capability of the MLLM remains largely intact.
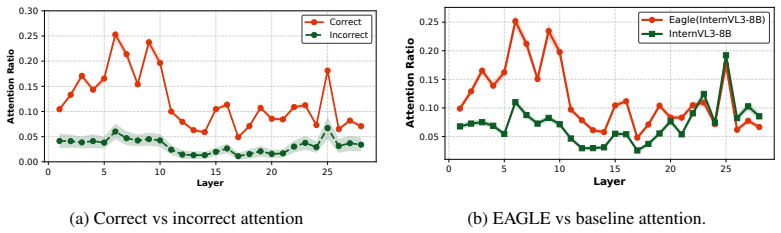
- Correct anomaly predictions show stronger alignment between MLLM attention and actual defect locations.
- The same expert-augmented process works on both MVTec-AD and VisA benchmarks.
Where Pith is reading between the lines
- External expert signals could serve as a general plug-in to make MLLMs more reliable on narrow vision tasks without retraining.
- Measuring attention alignment to ground-truth regions may become a practical way to audit or debug MLLM decisions in industrial settings.
- Similar guidance mechanisms might extend to other domains such as medical image inspection where expert detectors already exist.
- Future versions could close the loop by letting the MLLM's own uncertainty feed back into the prompt selection step.
Load-bearing premise
Expert detector statistics and confidence scores can be mapped into prompts and attention adjustments that improve the MLLM without injecting new errors or biases from the expert.
What would settle it
Apply EAGLE to a new MLLM backbone on a dataset where the expert detector produces inconsistent or biased scores and measure whether accuracy gains and attention alignment both disappear.
Figures











read the original abstract
Multimodal large language models (MLLMs) can enrich industrial anomaly detection with semantic descriptions and anomaly reasoning, but they still lag specialist anomaly detectors in binary detection accuracy. Existing approaches address this gap by fine-tuning MLLMs or training bridging modules to align expert outputs with MLLM inputs, limiting flexibility across backbones. We propose EAGLE, a tuning-free framework that integrates expert anomaly detectors with frozen MLLMs. EAGLE consists of Threshold-Guided Prompt Selection (TGPS), which estimates a decision threshold from expert model statistics and selects textual and visual prompts, and Confidence-Aware Attention Sharpening (CAAS), which shifts MLLM attention toward visual evidence when expert confidence is low. Beyond improving accuracy, we analyze MLLM attention and find that correct anomaly predictions are associated with stronger focus on ground-truth defect regions; EAGLE consistently strengthens this alignment. On MVTec-AD and VisA, EAGLE improves five MLLM backbones without parameter updates, reaching up to 94.4\% and 88.1\% in anomaly discrimination accuracy, respectively, and achieving performance competitive with fine-tuning-based methods while largely preserving MLLM semantic reasoning ability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce EAGLE, a tuning-free framework that augments frozen multimodal large language models (MLLMs) with expert anomaly detectors for industrial anomaly detection. It features Threshold-Guided Prompt Selection (TGPS) to estimate thresholds from expert statistics and select prompts, and Confidence-Aware Attention Sharpening (CAAS) to adjust attention based on low expert confidence. Evaluations on MVTec-AD and VisA show improvements across five MLLM backbones, achieving up to 94.4% and 88.1% anomaly discrimination accuracy, competitive with fine-tuned approaches, while maintaining semantic reasoning and strengthening attention on defect regions.
Significance. Should the empirical results prove robust, the work holds significance in demonstrating a practical, backbone-agnostic method to bridge the performance gap between MLLMs and specialized anomaly detectors without requiring parameter updates or additional training. This flexibility could accelerate the adoption of MLLMs in industrial settings. The accompanying attention analysis offers mechanistic insights that may inform future model improvements. Strengths include the tuning-free design and cross-backbone applicability.
major comments (2)
- Abstract: The reported accuracies of 94.4% on MVTec-AD and 88.1% on VisA are presented without details on the specific baselines used, statistical significance tests, error bars, or exact experimental protocols. This makes it difficult to verify the central performance claims and assess robustness.
- Method (TGPS/CAAS description): The framework assumes expert anomaly scores and confidence can be reliably mapped to prompts and attention adjustments without propagating calibration errors or biases; however, no ablations on threshold sensitivity, confidence noise, or cross-expert transfer are referenced, which is load-bearing for the tuning-free claim.
minor comments (2)
- Define all acronyms (e.g., TGPS, CAAS, MLLM) on first use and ensure consistent notation throughout.
- The attention analysis section would benefit from quantitative metrics (e.g., IoU with ground-truth defect regions) to support the qualitative claim of strengthened alignment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and have revised the manuscript to strengthen the presentation of results and robustness analysis.
read point-by-point responses
-
Referee: Abstract: The reported accuracies of 94.4% on MVTec-AD and 88.1% on VisA are presented without details on the specific baselines used, statistical significance tests, error bars, or exact experimental protocols. This makes it difficult to verify the central performance claims and assess robustness.
Authors: We agree that the abstract would benefit from additional context for verifiability. In the revision, we have expanded the abstract to reference the specific baselines (fine-tuned MLLMs and specialist detectors such as PatchCore and CFA) and to note that full experimental protocols, including 5-run averages with standard deviations, are detailed in Section 4. Error bars have been added to the primary results tables, and we report p-values from Wilcoxon signed-rank tests confirming statistical significance of improvements over baselines. revision: yes
-
Referee: Method (TGPS/CAAS description): The framework assumes expert anomaly scores and confidence can be reliably mapped to prompts and attention adjustments without propagating calibration errors or biases; however, no ablations on threshold sensitivity, confidence noise, or cross-expert transfer are referenced, which is load-bearing for the tuning-free claim.
Authors: We acknowledge that explicit validation of robustness to calibration variations is important for the tuning-free claim. While cross-backbone consistency in the original experiments provides supporting evidence, we have added a dedicated ablation subsection in the revised manuscript. This includes threshold sensitivity tests (varying the expert-derived threshold by ±5% and ±10%, with accuracy drops limited to <2% on MVTec-AD), simulated confidence noise (additive Gaussian noise up to 15% standard deviation, preserving >87% accuracy), and cross-expert transfer results using an alternative detector (e.g., swapping the primary expert for a secondary one on VisA). These confirm stability within practical ranges. revision: yes
Circularity Check
No circularity; external expert detectors supply independent inputs to TGPS/CAAS
full rationale
The derivation chain treats expert anomaly detectors as external black-box sources whose statistics and confidence scores are fed into TGPS (threshold estimation and prompt selection) and CAAS (attention modulation). These steps operate on the experts' outputs without defining or fitting the experts from the MLLM, without renaming fitted parameters as predictions, and without load-bearing self-citations. The claimed accuracy gains on MVTec-AD and VisA are presented as empirical outcomes of the integration rather than tautological consequences of the inputs. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, Qianying Wang, Ping Chen, Xiaoqin Zhang, and Shijian Lu. Mitigating object hallucinations in large vision-language models with assembly of global and local attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 29915–29926, June 2025
work page 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Efficientad: Accurate visual anomaly detection at millisecond-level latencies
Kilian Batzner, Lars Heckler, and Rebecca König. Efficientad: Accurate visual anomaly detection at millisecond-level latencies. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 128–138, 2024
work page 2024
-
[4]
Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9592–9600, 2019
work page 2019
-
[5]
Uninformed students: Student- teacher anomaly detection with discriminative latent embeddings
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Uninformed students: Student- teacher anomaly detection with discriminative latent embeddings. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4183–4192, 2020
work page 2020
-
[6]
Yuhao Chao, Jie Liu, Jie Tang, and Gangshan Wu. Anomalyr1: A grpo-based end-to-end mllm for industrial anomaly detection.arXiv preprint arXiv:2504.11914, 2025
-
[7]
Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas.arXiv preprint arXiv:2503.01773, 2025
-
[8]
Zhiling Chen, Hanning Chen, Mohsen Imani, and Farhad Imani. Can multimodal large language models be guided to improve industrial anomaly detection?arXiv preprint arXiv:2501.15795, 2025
-
[9]
Rad: A comprehensive dataset for benchmarking the robustness of image anomaly detection
Yuqi Cheng, Yunkang Cao, Rui Chen, and Weiming Shen. Rad: A comprehensive dataset for benchmarking the robustness of image anomaly detection. In2024 IEEE 20th International Conference on Automation Science and Engineering (CASE), pages 2123–2128. IEEE, 2024
work page 2024
-
[10]
Limiting forms of the frequency distribution of the largest or smallest member of a sample
Ronald Aylmer Fisher and Leonard Henry Caleb Tippett. Limiting forms of the frequency distribution of the largest or smallest member of a sample. InMathematical proceedings of the Cambridge philosophical society, volume 24, pages 180–190. Cambridge University Press, 1928
work page 1928
-
[11]
Boris Gnedenko. Sur la distribution limite du terme maximum d’une serie aleatoire.Annals of mathematics, 44(3):423–453, 1943
work page 1943
-
[12]
Anomalygpt: Detecting industrial anomalies using large vision-language models
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. Anomalygpt: Detecting industrial anomalies using large vision-language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 1932–1940, 2024
work page 1932
-
[13]
Wei Guan, Jun Lan, Jian Cao, Hao Tan, Huijia Zhu, and Weiqiang Wang. Emit: Enhancing mllms for industrial anomaly detection via difficulty-aware grpo.arXiv preprint arXiv:2507.21619, 2025
-
[14]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Winclip: Zero-/few-shot anomaly classification and segmentation
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. Winclip: Zero-/few-shot anomaly classification and segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19606–19616, 2023
work page 2023
-
[16]
Xi Jiang, Ying Chen, Qiang Nie, Jianlin Liu, Yong Liu, Chengjie Wang, and Feng Zheng. Toward multi-class anomaly detection: Exploring class-aware unified model against inter-class interference.arXiv preprint arXiv:2403.14213, 2024
-
[17]
Xi Jiang, Jian Li, Hanqiu Deng, Yong Liu, Bin-Bin Gao, Yifeng Zhou, Jialin Li, Chengjie Wang, and Feng Zheng. Mmad: The first-ever comprehensive benchmark for multimodal large language models in industrial anomaly detection.arXiv e-prints, pages arXiv–2410, 2024. 10
work page 2024
-
[18]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321, 2025
-
[19]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872– 13882, 2024
work page 2024
-
[20]
Promptad: Learning prompts with only normal samples for few-shot anomaly detection
Xiaofan Li, Zhizhong Zhang, Xin Tan, Chengwei Chen, Yanyun Qu, Yuan Xie, and Lizhuang Ma. Promptad: Learning prompts with only normal samples for few-shot anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16838–16848, 2024
work page 2024
-
[21]
Xurui Li, Ziming Huang, Feng Xue, and Yu Zhou. Musc: Zero-shot industrial anomaly classification and segmentation with mutual scoring of the unlabeled images. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[22]
Myriad: Large multimodal model by applying vision experts for industrial anomaly detection,
Yuanze Li, Haolin Wang, Shihao Yuan, Ming Liu, Debin Zhao, Yiwen Guo, Chen Xu, Guangming Shi, and Wangmeng Zuo. Myriad: Large multimodal model by applying vision experts for industrial anomaly detection.arXiv preprint arXiv:2310.19070, 2023
-
[23]
Yuanze Li, Shihao Yuan, Haolin Wang, Qizhang Li, Ming Liu, Chen Xu, Guangming Shi, and Wangmeng Zuo. Triad: Empowering lmm-based anomaly detection with expert-guided region-of-interest tokenizer and manufacturing process. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21917–21926, 2025
work page 2025
-
[24]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[25]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024
work page 2024
-
[26]
Towards total recall in industrial anomaly detection
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2022
work page 2022
-
[27]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9568–9578, 2024
work page 2024
-
[28]
Chenxi Wang, Xiang Chen, Ningyu Zhang, Bozhong Tian, Haoming Xu, Shumin Deng, and Huajun Chen. Mllm can see? dynamic correction decoding for hallucination mitigation.arXiv preprint arXiv:2410.11779, 2024
-
[29]
Don’t miss the forest for the trees: Attentional vision calibration for large vision language models
Sangmin Woo, Donguk Kim, Jaehyuk Jang, Yubin Choi, and Changick Kim. Don’t miss the forest for the trees: Attentional vision calibration for large vision language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 1927–1951, 2025
work page 2025
-
[30]
Towards zero-shot anomaly detection and reasoning with multimodal large language models
Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, Vishal M Patel, and Isht Dwivedi. Towards zero-shot anomaly detection and reasoning with multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20370–20382, 2025
work page 2025
-
[31]
Hao Yin, Guangzong Si, and Zilei Wang. Clearsight: Visual signal enhancement for object hallucination mitigation in multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14625–14634, 2025
work page 2025
-
[32]
Draem-a discriminatively trained reconstruction embedding for surface anomaly detection
Vitjan Zavrtanik, Matej Kristan, and Danijel Sko ˇcaj. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8330–8339, 2021
work page 2021
-
[33]
Peijian Zeng, Feiyan Pang, Zhanbo Wang, and Aimin Yang. Lr-iad: Mask-free industrial anomaly detection with logical reasoning.arXiv preprint arXiv:2504.19524, 2025
-
[34]
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. Mllms know where to look: Training-free perception of small visual details with multimodal llms.arXiv preprint arXiv:2502.17422, 2025
-
[35]
Shifang Zhao, Yiheng Lin, Lu Han, Yao Zhao, and Yunchao Wei. Omniad: Detect and understand industrial anomaly via multimodal reasoning.arXiv preprint arXiv:2505.22039, 2025. 11
-
[36]
Anomalyclip: Object-agnostic prompt learn- ing for zero-shot anomaly detection
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection.arXiv preprint arXiv:2310.18961, 2023
-
[37]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
The image is predict as normal by expert model
Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, and Onkar Dabeer. Spot-the-difference self-supervised pre-training for anomaly detection and segmentation. InEuropean conference on computer vision, pages 392–408. Springer, 2022. 12 A Preliminary on MLLMs A.0.1 Multimodal Large Language Models In MLLMs, visual tokens extracted by a vision encoder an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.