Recognition: no theorem link
RAT+: Train Dense, Infer Sparse -- Recurrence Augmented Attention for Dilated Inference
Pith reviewed 2026-05-15 20:56 UTC · model grok-4.3
The pith
RAT+ lets one densely pretrained model switch to dilated sparse attention at inference with only short adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
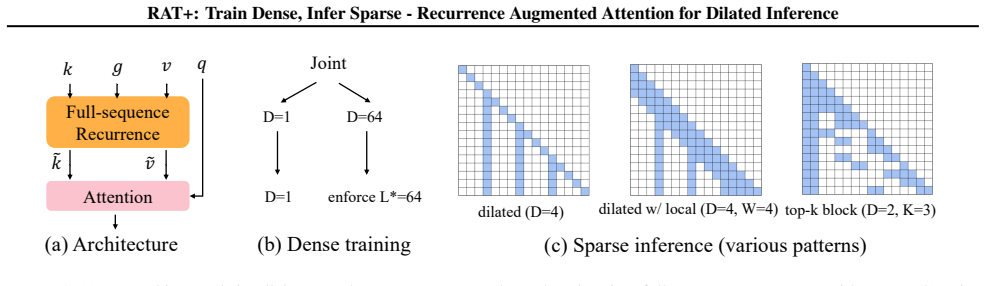
A single RAT+ model is pretrained densely once and can then be flexibly switched at inference time to dilated attention (optionally with local windows) or hybrid layer/head compositions, requiring only a short 1B-token resolution adaptation rather than retraining separate sparse models. At 1.5B parameters trained on 100B tokens, RAT+ closely matches dense accuracy at D=16, and drops by about 2--3 points at D=64 on commonsense reasoning and LongBench tasks. We further scale to 2.6B and 7.6B parameters and observe even more promising performance (e.g., a 1-point average accuracy loss with a 64x reduction in attention FLOPs and KV cache size).
What carries the argument
Recurrence Augmented Attention (RAT+), which augments standard attention with full-sequence recurrence and active recurrence learning during dense pretraining so that the learned representations transfer to dilated sparse patterns after brief adaptation.
If this is right
- Attention FLOPs and KV cache size shrink by the dilation factor D at inference
- Accuracy stays within 1 point of dense at D=16 across tested scales
- At D=64 the accuracy drop stays around 2-3 points on reasoning and long-context tasks for the 1.5B model
- Larger models (up to 7.6B) show even smaller relative drops at high dilation
- Hybrid layer- and head-level dilation patterns are supported without separate pretraining
Where Pith is reading between the lines
- Runtime systems could select dilation on the fly according to current compute budget without reloading weights
- The same recurrence pretraining might ease transfer to other sparse patterns such as local windows or block sparsity
- Training for adaptability rather than a fixed sparsity pattern could reduce the total compute spent on model families
- If adaptation length can be shortened further, zero-shot switching between dense and sparse modes may become feasible
Load-bearing premise
Representations built from dense full-sequence recurrence remain effective when attention is later sparsified by dilation after only short adaptation.
What would settle it
Measuring whether a 7.6B RAT+ model loses more than 4 accuracy points on LongBench after switching to D=64 dilation with only the stated 1B-token adaptation.
Figures






read the original abstract
Structured dilated attention has an appealing inference-time efficiency knob: it reduces the FLOPs of attention and the KV cache size by a factor of the dilation size D, while preserving long-range connectivity. While prior work studies it by training each configuration from scratch, directly sparsifying a pretrained attention model into a dilated pattern leads to severe accuracy degradation, preventing flexible reuse across inference scenarios. We introduce RAT+, a dense-pretraining architecture that augments attention with full-sequence recurrence and active recurrence learning. A single RAT+ model is pretrained densely once and can then be flexibly switched at inference time to dilated attention (optionally with local windows) or hybrid layer/head compositions, requiring only a short 1B-token resolution adaptation rather than retraining separate sparse models. At 1.5B parameters trained on 100B tokens, RAT+ closely matches dense accuracy at D=16, and drops by about 2--3 points at D=64 on commonsense reasoning and LongBench tasks. We further scale to 2.6B and 7.6B parameters and observe even more promising performance (e.g., a 1-point average accuracy loss with a 64x reduction in attention FLOPs and KV cache size). Code is available at https://github.com/wimh966/rat-plus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RAT+, a dense-pretraining architecture that augments attention with full-sequence recurrence and active recurrence learning. A single model is pretrained densely once on 100B tokens and can then be switched at inference to dilated attention patterns (with optional local windows or hybrid layer/head compositions) after only a short 1B-token resolution adaptation, rather than retraining separate sparse models. At 1.5B parameters the method closely matches dense accuracy at D=16 and drops by 2-3 points at D=64 on commonsense reasoning and LongBench; scaling results are also reported for 2.6B and 7.6B models with a claimed 1-point average loss at 64x reduction in attention FLOPs and KV cache.
Significance. If the central empirical claim holds under controlled comparisons, the work provides a practical route to inference-time flexibility in attention sparsity without the cost of training multiple dilated models from scratch. The scaling results to 7.6B parameters and the concrete accuracy numbers at multiple dilation factors indicate potential utility for efficient long-context deployment. The public code release supports reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that 'directly sparsifying a pretrained attention model into a dilated pattern leads to severe accuracy degradation' is contrasted with RAT+'s short adaptation, but the abstract does not state whether the direct-sparsification baseline also received the same 1B-token resolution adaptation. This comparison is load-bearing for the central claim that recurrence-augmented pretraining (rather than adaptation itself) enables limited loss and flexible reuse.
- [Experiments] Experiments section: the reported accuracy numbers at 1.5B parameters (close match at D=16, 2-3 point drop at D=64) and the scaling claims at 2.6B/7.6B are presented without detailed ablations isolating the recurrence component or confirming that all baselines received identical adaptation. This leaves the weakest assumption—that recurrence creates representations that transfer to dilated patterns with only short adaptation—only moderately supported.
minor comments (2)
- The description of 'active recurrence learning' during pretraining would benefit from an explicit equation or pseudocode block showing how the recurrence loss is combined with the language-modeling objective.
- Tables reporting accuracy across dilation factors should explicitly label the adaptation procedure (or lack thereof) for every compared method to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments. We address each major comment below and have made revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'directly sparsifying a pretrained attention model into a dilated pattern leads to severe accuracy degradation' is contrasted with RAT+'s short adaptation, but the abstract does not state whether the direct-sparsification baseline also received the same 1B-token resolution adaptation. This comparison is load-bearing for the central claim that recurrence-augmented pretraining (rather than adaptation itself) enables limited loss and flexible reuse.
Authors: We agree this clarification is necessary to support the central claim. In the experiments, the direct-sparsification baseline (a standard dense pretrained model without recurrence) received the identical 1B-token resolution adaptation before dilated evaluation. Severe degradation persists even after adaptation, while RAT+ shows limited loss. We will revise the abstract to explicitly note that both conditions use the same adaptation protocol. revision: yes
-
Referee: [Experiments] Experiments section: the reported accuracy numbers at 1.5B parameters (close match at D=16, 2-3 point drop at D=64) and the scaling claims at 2.6B/7.6B are presented without detailed ablations isolating the recurrence component or confirming that all baselines received identical adaptation. This leaves the weakest assumption—that recurrence creates representations that transfer to dilated patterns with only short adaptation—only moderately supported.
Authors: We acknowledge the value of stronger isolation of the recurrence component. We will add a dedicated ablation subsection comparing RAT+ against a non-recurrent dense model under identical adaptation and dilation settings. We will also add explicit statements confirming that all reported baselines (including direct sparsification) used the same 1B-token adaptation, better supporting the transfer claim. revision: yes
Circularity Check
No circularity: empirical results on benchmarks with no self-referential derivations
full rationale
The paper presents RAT+ as an architectural modification (recurrence-augmented attention) pretrained densely, followed by short adaptation for sparse inference. All reported outcomes are direct empirical measurements of accuracy on commonsense reasoning and LongBench tasks at various dilation factors. No equations, uniqueness theorems, or fitted parameters are shown that reduce the claimed accuracy retention to quantities defined by the inputs themselves. The 1B-token adaptation is an explicit training step whose effect is measured rather than assumed tautological. No self-citation chains are invoked to justify core premises. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- dilation factor D
invented entities (1)
-
RAT+ recurrence augmentation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head check- points
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y ., Lebr´on, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head check- points. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing, pp. 4895–4901,
work page 2023
-
[2]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Bai, Y ., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., et al. Longbench: A bilingual, multitask benchmark for long context under- standing.arXiv preprint arXiv:2308.14508,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Command a: An enterprise-ready large language model.arXiv preprint arXiv:2504.00698,
Cohere, T., Ahmadian, A., Ahmed, M., Alammar, J., Al- izadeh, M., Alnumay, Y ., Althammer, S., Arkhangorod- sky, A., Aryabumi, V ., Aumiller, D., et al. Command a: An enterprise-ready large language model.arXiv preprint arXiv:2504.00698,
-
[6]
Cooijmans, T., Ballas, N., Laurent, C., G ¨ulc ¸ehre, C ¸., and Courville, A. Recurrent batch normalization.arXiv preprint arXiv:1603.09025,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Dao, T. and Gu, A. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
De, S., Smith, S. L., Fernando, A., Botev, A., Cristian- Muraru, G., Gu, A., Haroun, R., Berrada, L., Chen, Y ., Srinivasan, S., et al. Griffin: Mixing gated linear recur- rences with local attention for efficient language models. arXiv preprint arXiv:2402.19427,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Longnet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486,
Ding, J., Ma, S., Dong, L., Zhang, X., Huang, S., Wang, W., Zheng, N., and Wei, F. Longnet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486,
-
[10]
Dong, J., Feng, B., Guessous, D., Liang, Y ., and He, H. Flex attention: A programming model for gen- erating optimized attention kernels.arXiv preprint arXiv:2412.05496,
- [11]
-
[12]
Fu, T., Huang, H., Ning, X., Zhang, G., Chen, B., Wu, T., Wang, H., Huang, Z., Li, S., Yan, S., et al. Moa: Mixture of sparse attention for automatic large language model compression.arXiv preprint arXiv:2406.14909,
- [13]
-
[14]
Lm-infinite: Zero-shot extreme length generalization for large language models
Han, C., Wang, Q., Peng, H., Xiong, W., Chen, Y ., Ji, H., and Wang, S. Lm-infinite: Zero-shot extreme length generalization for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3991–4008,
work page 2024
-
[15]
Hassani, A. and Shi, H. Dilated neighborhood attention transformer.arXiv preprint arXiv:2209.15001,
-
[16]
Trans- former language models without positional encodings still learn positional information
Haviv, A., Ram, O., Press, O., Izsak, P., and Levy, O. Trans- former language models without positional encodings still learn positional information. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2022, pp. 1382–1390,
work page 2022
-
[17]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y ., and Ginsburg, B. Ruler: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Katharopoulos, A., Vyas, A., Pappas, N., and Fleuret, F
Accessed: 2026-01-26. Katharopoulos, A., Vyas, A., Pappas, N., and Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on ma- chine learning, pp. 5156–5165. PMLR,
work page 2026
-
[19]
Lai, X., Lu, J., Luo, Y ., Ma, Y ., and Zhou, X. Flex- prefill: A context-aware sparse attention mechanism for efficient long-sequence inference.arXiv preprint arXiv:2502.20766,
-
[20]
Lin, C., Tang, J., Yang, S., Wang, H., Tang, T., Tian, B., Stoica, I., Han, S., and Gao, M. Twilight: Adaptive attention sparsity with hierarchical top-p pruning.arXiv preprint arXiv:2502.02770,
-
[21]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
Lu, E., Jiang, Z., Liu, J., Du, Y ., Jiang, T., Hong, C., Liu, S., He, W., Yuan, E., Wang, Y ., et al. Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
-
[23]
Online normalizer calculation for softmax
Milakov, M. and Gimelshein, N. Online normalizer cal- culation for softmax.arXiv preprint arXiv:1805.02867,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Transformers are multi-state rnns.arXiv preprint arXiv:2401.06104,
Oren, M., Hassid, M., Yarden, N., Adi, Y ., and Schwartz, R. Transformers are multi-state rnns.arXiv preprint arXiv:2401.06104,
-
[25]
RWKV: Reinventing RNNs for the Transformer Era
Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., et al. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048, 2023a. Peng, B., Quesnelle, J., Fan, H., and Shippole, E. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:230...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[27]
Retentive Network: A Successor to Transformer for Large Language Models
Sun, Y ., Dong, L., Huang, S., Ma, S., Xia, Y ., Xue, J., Wang, J., and Wei, F. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Wei, X., Yadav, A., Pascanu, R., and Gulcehre, C. Rat: Bridging rnn efficiency and attention accuracy via chunk-based sequence modeling.arXiv preprint arXiv:2507.04416,
-
[30]
Re- trieval head mechanistically explains long-context factu- ality.arXiv preprint arXiv:2404.15574,
Wu, W., Wang, Y ., Xiao, G., Peng, H., and Fu, Y . Re- trieval head mechanistically explains long-context factu- ality.arXiv preprint arXiv:2404.15574,
-
[31]
Efficient Streaming Language Models with Attention Sinks
Xiao, C., Zhang, P., Han, X., Xiao, G., Lin, Y ., Zhang, Z., Liu, Z., and Sun, M. Infllm: Training-free long-context extrapolation for llms with an efficient context memory. Advances in Neural Information Processing Systems, 37: 119638–119661, 2024a. Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention...
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Xiao, G., Tang, J., Zuo, J., Guo, J., Yang, S., Tang, H., Fu, Y ., and Han, S. Duoattention: Efficient long-context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819, 2024b. Yang, B., Venkitesh, B., Talupuru, D., Lin, H., Cairuz, D., Blunsom, P., and Locatelli, A. Rope to nope and back again: A new hybrid attention strategy....
-
[33]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Yang, S., Kautz, J., and Hatamizadeh, A. Gated delta net- works: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
12 RAT+: Train Dense, Infer Sparse - Recurrence Augmented Attention for Dilated Inference A. Appendix A.1. Implementation details Implementation for Table 1.We largely follow the RAT implementation, using the same model architecture and training dataset but also some modifications. RAT shares linear projections for attention queries and keys across heads ...
work page 2048
-
[35]
The RoPE based is set to 10,000
instead of the inter-chunk RoPE used in RAT, for easier management of positional encoding, and put it after the recurrence function. The RoPE based is set to 10,000. Model parameters are initialized from a Gaussian distribution with a standard deviation of 0.02. We adopt the LLaMA2 tokenizer in all experiments. The optimization hyperparameters follow the ...
work page 2024
-
[36]
For the 200B-token training setting, the peak learning rate remains 7.0×10 −4 with a global batch size of 768, following the same rule in Bi et al. (2024). For the 7.6B-parameter model trained on 100B tokens, we adopt a model dimension of 4096, 32 Transformer layers, and a head dimension of
work page 2024
-
[37]
The third row shows the results of the pretrained network
The second row corresponds to the same initialized network but with a non-zero initial cell state provided to the recurrence. The third row shows the results of the pretrained network. We visualize the outputs of our simple recurrence here; a similar phenomenon has also been observed in standard recurrent networks, as reported in Cooijmans et al. (2016). ...
work page 2016
-
[38]
The second and third rows report additional design-choice ablations
The first row shows strong performance across dilation settings. The second and third rows report additional design-choice ablations. As can be seen, removing recurrence over the attention keys leads to a slight increase in perplexity. We think this might because the gated representations on the attention values can still be propagated across layers. In c...
work page 2023
-
[39]
All models perform poorly on MusiQue and exhibit very similar performance on LCC
16 RAT+: Train Dense, Infer Sparse - Recurrence Augmented Attention for Dilated Inference Table 15.Supplementary results on additional LongBench tasks of 1.5B models.We omit these results from the main text as they are less representative. All models perform poorly on MusiQue and exhibit very similar performance on LCC. For the remaining summarization tas...
work page 2024
-
[40]
style top-k block attention, where the critical block is determined by the mean pooling of attention keys within each block. We found that this style performs worse than the Quest in the training-free manner, but RAT+ still outperforms the baseline a lot. MoBA top-k NIAH-S-1 NIAH-S-1 NIAH-S-3 NIAH-MK-1 NIAH-MK-2 NIAH-MK-3 NIAH-MQ NIAH-MV attention D† =1, ...
work page 2024
-
[41]
D† =1 means the attention operator or block without the recurrence
The latency (ms) is tested on 262K sequences of tokens. D† =1 means the attention operator or block without the recurrence. Latency (H=2048) 4K 8K 16K 32K 65K 131K 262K Temporal-mixing operator D† =116.3 28.5 51.8 101.1 197.9 422.3 897.8 D=132.0 43.9 67.8 118.2 218.4 445.3 942.4 D=230.9 37.9 51.9 83.3 144.2 280.1 587.5 D=426.9 30.6 37.7 54.2 87.6 165.4 33...
work page 2048
-
[42]
The latency (ms) is tested on generating batches of tokens withB= 128,B= 256,B= 512at specified positions. Latency (H=2048) 4K 8K 16K 32K 65K 131K 262K Temporal-mixing operator B= 128 D† =11.19 2.33 4.62 9.18 18.34 OOM OOM D=11.24 2.38 4.67 9.24 18.38 OOM OOM D=2(vs.D† =1) 0.69 (1.7×) 1.26 (1.8×) 2.37 (1.9×) 4.66 (2.1×) 9.22 (2.0×) 18.35 OOM D=40.49 0.69 ...
work page 2048
-
[43]
We observe even better speed-up on both operator and block levels compared to H=2048
The latency (ms) is tested on 262K tokens. We observe even better speed-up on both operator and block levels compared to H=2048. Latency (H=4096) 4K 8K 16K 32K 65K 131K 262K Temporal-mixing operator D† =133.23 56.90 106.03 203.94 397.90 839.06 1789.60 D=164.36 88.78 138.34 237.04 429.17 875.68 1839.85 D=261.77 76.53 104.56 165.74 281.48 530.33 1100.72 D=4...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.