Recognition: 2 theorem links
· Lean TheoremMaskDiME: Adaptive Masked Diffusion for Precise and Efficient Visual Counterfactual Explanations
Pith reviewed 2026-05-15 20:39 UTC · model grok-4.3
The pith
MaskDiME uses adaptive masking to restrict diffusion sampling to decision-relevant image regions, generating visual counterfactual explanations over 30 times faster than baselines while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MaskDiME is a training-free diffusion framework that adaptively restricts sampling to decision-relevant regions through localized masking, thereby achieving both spatial precision in the modified areas and semantic consistency in the generated counterfactual images.
What carries the argument
Adaptive mask that restricts diffusion sampling to decision-relevant regions of the input image.
Load-bearing premise
That adaptively restricting diffusion sampling to decision-relevant regions will reliably produce semantically consistent counterfactuals without introducing artifacts or requiring task-specific tuning.
What would settle it
A side-by-side evaluation on one of the five benchmarks where MaskDiME produces visible artifacts or fails to flip the target prediction while the baseline succeeds with clean edits.
Figures




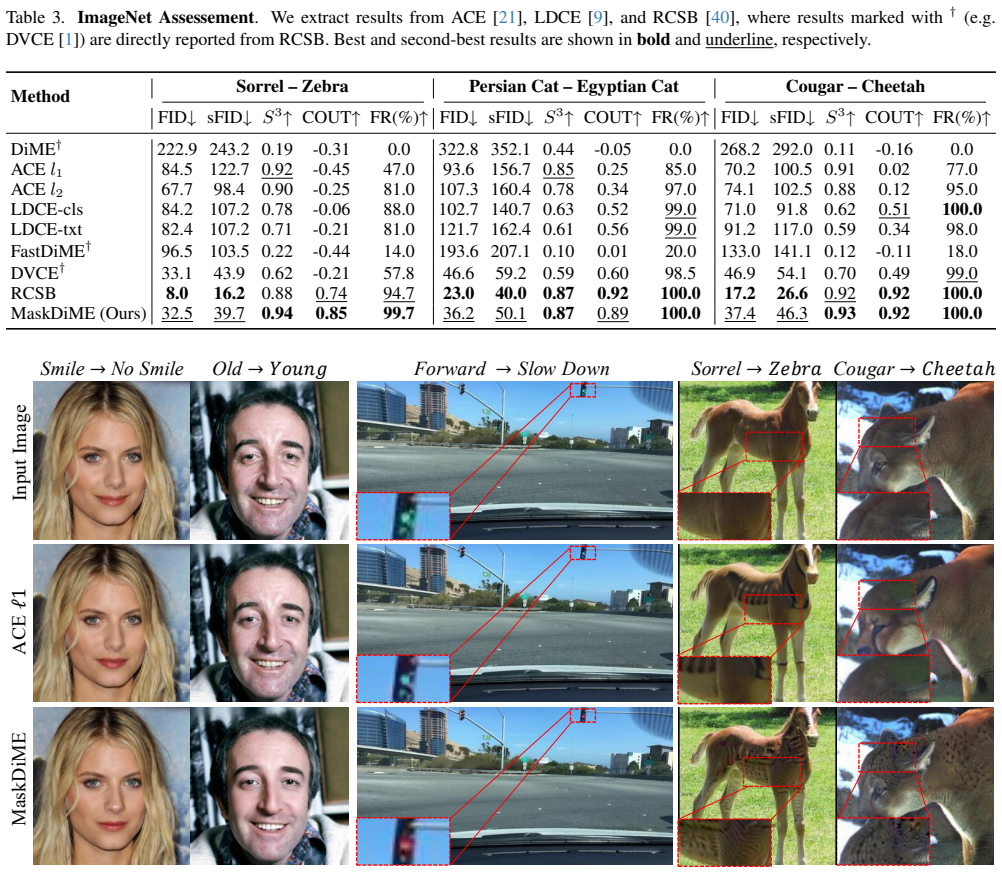

read the original abstract
Visual counterfactual explanations aim to reveal the minimal semantic modifications that can alter a model's prediction, providing causal and interpretable insights into deep neural networks. However, existing diffusion-based counterfactual generation methods are often computationally expensive, slow to sample, and imprecise in localizing the modified regions. To address these limitations, we propose MaskDiME, a simple, fast, yet effective diffusion framework that unifies semantic consistency and spatial precision through localized sampling. Our approach adaptively focuses on decision-relevant regions to achieve localized and semantically consistent counterfactual generation while preserving high image fidelity. Our training-free framework, MaskDiME, performs inference over 30x faster than the baseline and achieves comparable or state-of-the-art performance across five benchmark datasets spanning diverse visual domains, establishing a practical and generalizable solution for efficient counterfactual explanation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MaskDiME, a training-free adaptive masked diffusion framework for visual counterfactual explanations. It adaptively restricts diffusion sampling to decision-relevant image regions (via attributions or attention) to produce localized, semantically consistent counterfactuals while claiming >30x inference speedup over baselines and comparable or SOTA performance on five benchmark datasets spanning diverse visual domains.
Significance. If the empirical claims hold with proper validation, the work would provide a practical efficiency gain for diffusion-based counterfactual methods in computer vision, addressing a key computational barrier without requiring retraining. The training-free nature and focus on spatial precision are notable strengths that could support broader use in interpretability pipelines.
major comments (3)
- [§3.2] §3.2 (Adaptive Mask Generation): The central claim that the mask 'precisely delineates regions whose modification suffices to flip the prediction' is load-bearing, yet the manuscript provides no explicit criterion or ablation for the attribution threshold or attention cutoff used to define the mask; without this, it is unclear whether the method reliably avoids the skeptic's concern of incomplete flips or boundary artifacts in the inpainting step.
- [§4.3, Table 3] §4.3, Table 3 (Quantitative Results): The reported 30x speedup and SOTA-comparable metrics lack error bars, run counts, or statistical tests (e.g., paired t-tests across seeds); this undermines assessment of whether the efficiency and performance gains are robust across the five datasets rather than dataset-specific.
- [§4.1] §4.1 (Experimental Setup): The choice of baseline diffusion counterfactual methods and the exact diffusion sampling schedule (e.g., number of steps before/after masking) are not compared in an ablation that isolates the contribution of the adaptive mask versus standard masked diffusion; this makes it difficult to attribute the speedup and precision gains specifically to the proposed mechanism.
minor comments (2)
- [Figure 2] Figure 2 caption: The visual examples would benefit from explicit annotation of the mask boundaries overlaid on the original image to allow readers to assess localization quality directly.
- [§2] §2 (Related Work): The discussion of prior diffusion-based counterfactual methods omits recent works on guided diffusion for editing (e.g., those using classifier-free guidance); adding these would strengthen the positioning of MaskDiME.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and proposed revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Adaptive Mask Generation): The central claim that the mask 'precisely delineates regions whose modification suffices to flip the prediction' is load-bearing, yet the manuscript provides no explicit criterion or ablation for the attribution threshold or attention cutoff used to define the mask; without this, it is unclear whether the method reliably avoids the skeptic's concern of incomplete flips or boundary artifacts in the inpainting step.
Authors: We agree that an explicit criterion and supporting ablation are necessary to substantiate the mask's precision and to mitigate concerns about incomplete flips or inpainting artifacts. In the submitted manuscript, the adaptive mask is generated by computing attribution maps via Integrated Gradients and thresholding at the 75th percentile of positive scores to retain the most decision-relevant regions. To address this comment directly, we will add a new ablation subsection in §3.2 (and corresponding results in §4) that varies the percentile threshold across {50, 65, 75, 85} and reports the resulting prediction-flip success rate, LPIPS semantic consistency, and visual boundary artifacts. This will demonstrate the robustness of the chosen operating point while clarifying the exact procedure. revision: yes
-
Referee: [§4.3, Table 3] §4.3, Table 3 (Quantitative Results): The reported 30x speedup and SOTA-comparable metrics lack error bars, run counts, or statistical tests (e.g., paired t-tests across seeds); this undermines assessment of whether the efficiency and performance gains are robust across the five datasets rather than dataset-specific.
Authors: We acknowledge that the lack of variance estimates and statistical tests weakens the strength of the efficiency and performance claims. In the revised manuscript we will re-run all experiments on the five datasets using five independent random seeds, report mean ± standard deviation for every metric (including wall-clock inference time), and add paired t-tests (with p-values) comparing MaskDiME against each baseline. These additions will be incorporated into Table 3 and the accompanying text in §4.3. revision: yes
-
Referee: [§4.1] §4.1 (Experimental Setup): The choice of baseline diffusion counterfactual methods and the exact diffusion sampling schedule (e.g., number of steps before/after masking) are not compared in an ablation that isolates the contribution of the adaptive mask versus standard masked diffusion; this makes it difficult to attribute the speedup and precision gains specifically to the proposed mechanism.
Authors: We agree that an explicit ablation isolating the adaptive mask is required to attribute gains precisely. While the current baselines include full diffusion and non-adaptive masked diffusion, we will insert a new controlled ablation in §4.1 that compares three variants on the same sampling schedule (50 total DDIM steps, masking applied after the first 10 steps): (i) standard full diffusion, (ii) masked diffusion with a static (non-adaptive) mask of equivalent area, and (iii) our adaptive masked diffusion. Results will quantify the incremental benefit of adaptivity on both speedup and localization metrics, with the exact schedule parameters stated explicitly. revision: yes
Circularity Check
No significant circularity; empirical method without self-referential derivations
full rationale
The paper introduces MaskDiME as a training-free adaptive masked diffusion framework for visual counterfactuals. Claims of 30x faster inference and comparable/SOTA performance are presented as empirical outcomes from evaluations on five benchmark datasets, not as mathematical reductions or predictions derived from fitted parameters. No equations, self-definitional loops, or load-bearing self-citations appear in the abstract or described method that would make results equivalent to inputs by construction. The adaptive masking for localized sampling is a proposed heuristic unification of semantic consistency and spatial precision, but remains externally falsifiable via image fidelity and prediction-flip metrics without reducing to prior author work by definition. This is the common case of a self-contained applied method paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
adaptive dual-mask mechanism... top-k% of all gradient magnitudes... Mzt and Mxt (ρ shrinkage)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
one-step estimation based on Tweedie’s formula... Jcost not mentioned
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maximilian Augustin, Valentyn Boreiko, Francesco Croce, and Matthias Hein. Diffusion visual counterfactual explana- tions.Advances in Neural Information Processing Systems, 35:364–377, 2022. 2, 7
work page 2022
-
[2]
Vggface2: A dataset for recognising faces across pose and age
Qiong Cao, Li Shen, Weidi Xie, Omkar M Parkhi, and An- drew Zisserman. Vggface2: A dataset for recognising faces across pose and age. In2018 13th IEEE international con- ference on automatic face & gesture recognition (FG 2018), pages 67–74. IEEE, 2018. 5
work page 2018
-
[3]
Explainable saliency: Articulating reasoning with contextual prioritization
Nuo Chen, Ming Jiang, and Qi Zhao. Explainable saliency: Articulating reasoning with contextual prioritization. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 9601–9610, 2025. 2
work page 2025
-
[4]
Exploring simple siamese rep- resentation learning
Xinlei Chen and Kaiming He. Exploring simple siamese rep- resentation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 15750–15758, 2021. 5
work page 2021
-
[5]
Townim Chowdhury, Vu Minh Hieu Phan, Kewen Liao, Nanyu Dong, Minh-Son To, Anton van den Hengel, Johan W Verjans, and Zhibin Liao. Looking in the mirror: A faithful counterfactual explanation method for interpreting deep im- age classification models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2239– 2249, 2025. 2
work page 2025
-
[6]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 5
work page 2009
-
[7]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 2
work page 2021
-
[8]
Bradley Efron. Tweedie’s formula and selection bias.Jour- nal of the American Statistical Association, 106(496):1602– 1614, 2011. 2, 3
work page 2011
-
[9]
Latent diffusion counterfactual explanations.arXiv preprint arXiv:2310.06668, 2023
Karim Farid, Simon Schrodi, Max Argus, and Thomas Brox. Latent diffusion counterfactual explanations.arXiv preprint arXiv:2310.06668, 2023. 1, 2, 5, 6, 7
-
[10]
Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept-based explanations.Ad- vances in neural information processing systems, 32, 2019. 2
work page 2019
-
[11]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InProceed- ings of the 3rd International Conference on Learning Repre- sentations (ICLR), San Diego, CA, USA, 2015. 2
work page 2015
-
[12]
Towards human-understandable multi-dimensional concept discovery
Arne Grobr ¨ugge, Niklas K¨uhl, Gerhard Satzger, and Philipp Spitzer. Towards human-understandable multi-dimensional concept discovery. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20018–20027,
-
[13]
Towards black-box explainability with gaussian discriminant knowledge distillation
Anselm Haselhoff, Jan Kronenberger, Fabian Kuppers, and Jonas Schneider. Towards black-box explainability with gaussian discriminant knowledge distillation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21–28, 2021. 2
work page 2021
-
[14]
Anselm Haselhoff, Kevin Trelenberg, Fabian K ¨uppers, and Jonas Schneider. The gaussian discriminant variational au- toencoder (gdvae): A self-explainable model with counter- factual explanations. InEuropean Conference on Computer Vision, pages 305–322. Springer, 2024. 2
work page 2024
-
[15]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 5
work page 2017
-
[16]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1, 5
work page 2020
-
[17]
Interactive medical image analysis with concept-based simi- larity reasoning
Ta Duc Huy, Sen Kim Tran, Phan Nguyen, Nguyen Hoang Tran, Tran Bao Sam, Anton van den Hengel, Zhibin Liao, Johan W Verjans, Minh-Son To, and Vu Minh Hieu Phan. Interactive medical image analysis with concept-based simi- larity reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30797–30806, 2025. 2
work page 2025
-
[18]
Steex: steering counter- factual explanations with semantics
Paul Jacob, ´Eloi Zablocki, Hedi Ben-Younes, Micka¨el Chen, Patrick P´erez, and Matthieu Cord. Steex: steering counter- factual explanations with semantics. InEuropean Confer- ence on Computer Vision, pages 387–403. Springer, 2022. 2, 6
work page 2022
-
[19]
Cameras: Enhanced reso- lution and sanity preserving class activation mapping for im- age saliency
Mohammad AAK Jalwana, Naveed Akhtar, Mohammed Bennamoun, and Ajmal Mian. Cameras: Enhanced reso- lution and sanity preserving class activation mapping for im- age saliency. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16327– 16336, 2021. 2
work page 2021
-
[20]
Diffu- sion models for counterfactual explanations
Guillaume Jeanneret, Lo ¨ıc Simon, and Fr´ed´eric Jurie. Diffu- sion models for counterfactual explanations. InProceedings of the Asian conference on computer vision, pages 858–876,
-
[21]
Ad- versarial counterfactual visual explanations
Guillaume Jeanneret, Lo ¨ıc Simon, and Fr´ed´eric Jurie. Ad- versarial counterfactual visual explanations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 16425–16435, 2023. 1, 2, 5, 6, 7
work page 2023
-
[22]
Text- to-image models for counterfactual explanations: a black- box approach
Guillaume Jeanneret, Lo ¨ıc Simon, and Fr´ed´eric Jurie. Text- to-image models for counterfactual explanations: a black- box approach. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 4757– 4767, 2024. 1, 2, 5, 6
work page 2024
-
[23]
Si-mil: Taming deep mil for self-interpretability in gigapixel histopathology
Saarthak Kapse, Pushpak Pati, Srijan Das, Jingwei Zhang, Chao Chen, Maria Vakalopoulou, Joel Saltz, Dimitris Sama- ras, Rajarsi R Gupta, and Prateek Prasanna. Si-mil: Taming deep mil for self-interpretability in gigapixel histopathology. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11226–11237, 2024. 2
work page 2024
-
[24]
Explain- ing in diffusion: Explaining a classifier with diffusion se- mantics
Tahira Kazimi, Ritika Allada, and Pinar Yanardag. Explain- ing in diffusion: Explaining a classifier with diffusion se- mantics. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14799–14809, 2025. 2
work page 2025
-
[25]
Cycle-consistent counter- factuals by latent transformations
Saeed Khorram and Li Fuxin. Cycle-consistent counter- factuals by latent transformations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10203–10212, 2022. 5
work page 2022
-
[26]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability be- yond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on ma- chine learning, pages 2668–2677. PMLR, 2018. 2
work page 2018
-
[27]
Explaining in style: training a gan to explain a classifier in stylespace
Oran Lang, Yossi Gandelsman, Michal Yarom, Yoav Wald, Gal Elidan, Avinatan Hassidim, William T Freeman, Phillip Isola, Amir Globerson, Michal Irani, et al. Explaining in style: training a gan to explain a classifier in stylespace. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 693–702, 2021. 2
work page 2021
-
[28]
Maskgan: Towards diverse and interactive facial image ma- nipulation
Cheng-Han Lee, Ziwei Liu, Lingyun Wu, and Ping Luo. Maskgan: Towards diverse and interactive facial image ma- nipulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5549–5558,
-
[29]
Theodorou, Weili Nie, and Anima Anandkumar
Guan-Horng Liu, Arash Vahdat, De-An Huang, Evange- los A. Theodorou, Weili Nie, and Anima Anandkumar. I2sb: Image-to-image schr ¨odinger bridge.arXiv preprint arXiv:2302.05872, 2023. 2
-
[30]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of the IEEE international conference on computer vision, pages 3730–3738, 2015. 5
work page 2015
-
[31]
Disciple: Learn- ing interpretable programs for scientific visual discovery
Utkarsh Mall, Cheng Perng Phoo, Mia Chiquier, Bharath Hariharan, Kavita Bala, and Carl V ondrick. Disciple: Learn- ing interpretable programs for scientific visual discovery. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29258–29267, 2025. 2
work page 2025
-
[32]
Beyond trivial counterfactual explanations with diverse valuable explanations
Pau Rodriguez, Massimo Caccia, Alexandre Lacoste, Lee Zamparo, Issam Laradji, Laurent Charlin, and David Vazquez. Beyond trivial counterfactual explanations with diverse valuable explanations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1056–1065, 2021. 5, 6
work page 2021
-
[33]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
work page 2022
-
[34]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 2
work page 2015
-
[35]
Cynthia Rudin. Stop explaining black box machine learn- ing models for high stakes decisions and use interpretable models instead.Nature machine intelligence, 1(5):206–215,
-
[36]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE in- ternational conference on computer vision, pages 618–626,
-
[37]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps.arXiv preprint arXiv:1312.6034, 2013. 4
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[38]
Protopatchnet: An interpretable patch-based prototyp- ical network
Mohana Singh, Jayavardhana Gubbi, R Venkatesh Babu, et al. Protopatchnet: An interpretable patch-based prototyp- ical network. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 721–728, 2025. 2
work page 2025
-
[39]
SmoothGrad: removing noise by adding noise
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Vi ´egas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise.arXiv preprint arXiv:1706.03825, 2017. 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Re- thinking visual counterfactual explanations through region constraint
Bartlomiej Sobieski, Jakub Grzywaczewski, Bartłomiej Sadlej, Matthew Tivnan, and Przemyslaw Biecek. Re- thinking visual counterfactual explanations through region constraint. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2, 4, 5, 6, 7
work page 2025
-
[41]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[42]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InInternational conference on machine learning, pages 3319–3328. PMLR, 2017. 4
work page 2017
-
[43]
Sarah Tan, Rich Caruana, Giles Hooker, Paul Koch, and Al- bert Gordo. Learning global additive explanations for neu- ral nets using model distillation.stat, 1050(3):1518–68323,
-
[44]
Coun- terfactual explanations without opening the black box: Au- tomated decisions and the gdpr.Harv
Sandra Wachter, Brent Mittelstadt, and Chris Russell. Coun- terfactual explanations without opening the black box: Au- tomated decisions and the gdpr.Harv. JL & Tech., 31:841,
-
[45]
Fast diffusion-based counterfactuals for shortcut removal and generation
Nina Weng, Paraskevas Pegios, Eike Petersen, Aasa Feragen, and Siavash Bigdeli. Fast diffusion-based counterfactuals for shortcut removal and generation. InEuropean Conference on Computer Vision, pages 338–357. Springer, 2024. 1, 2, 4, 5, 6
work page 2024
-
[46]
Explainable object-induced action decision for autonomous vehicles
Yiran Xu, Xiaoyin Yang, Lihang Gong, Hsuan-Chu Lin, Tz- Ying Wu, Yunsheng Li, and Nuno Vasconcelos. Explainable object-induced action decision for autonomous vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 9523–9532, 2020. 5
work page 2020
-
[47]
Latent drifting in diffusion models for counterfactual medical image synthesis
Yousef Yeganeh, Azade Farshad, Ioannis Charisiadis, Marta Hasny, Martin Hartenberger, Bj”orn Ommer, Nassir Navab, and Ehsan Adeli. Latent drifting in diffusion models for counterfactual medical image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1, 2
work page 2025
-
[48]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Dar- rell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2636–2645, 2020. 5
work page 2020
-
[49]
Wenlong Yu, Qilong Wang, Chuang Liu, Dong Li, and Qinghua Hu. Coe: Chain-of-explanation via automatic vi- sual concept circuit description and polysemanticity quantifi- cation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4364–4374, 2025. 2
work page 2025
-
[50]
Lintong Zhang, Kang Yin, and Seong-Whan Lee. Towards fine-grained interpretability: Counterfactual explanations for misclassification with saliency partition. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30053–30062, 2025. 2
work page 2025
-
[51]
Inter- pretable convolutional neural networks
Quanshi Zhang, Ying Nian Wu, and Song-Chun Zhu. Inter- pretable convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 8827–8836, 2018. 2
work page 2018
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 5
work page 2018
-
[53]
Finer-cam: Spotting the difference reveals finer details for visual explanation
Ziheng Zhang, Jianyang Gu, Arpita Chowdhury, Zheda Mai, David Carlyn, Tanya Berger-Wolf, Yu Su, and Wei-Lun Chao. Finer-cam: Spotting the difference reveals finer details for visual explanation. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 9611–9620,
-
[54]
Shap- cam: Visual explanations for convolutional neural networks based on shapley value
Quan Zheng, Ziwei Wang, Jie Zhou, and Jiwen Lu. Shap- cam: Visual explanations for convolutional neural networks based on shapley value. InEuropean conference on computer vision, pages 459–474. Springer, 2022. 2
work page 2022
-
[55]
In- terpretable image classification via non-parametric part pro- totype learning
Zhijie Zhu, Lei Fan, Maurice Pagnucco, and Yang Song. In- terpretable image classification via non-parametric part pro- totype learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9762–9771, 2025. 2
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.