Recognition: 2 theorem links
· Lean TheoremOpenVO: Open-World Visual Odometry with Temporal Dynamics Awareness
Pith reviewed 2026-05-15 20:49 UTC · model grok-4.3
The pith
OpenVO estimates ego-motion from monocular dashcam videos with arbitrary frame rates and unknown intrinsics by encoding temporal dynamics and using 3D priors from foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
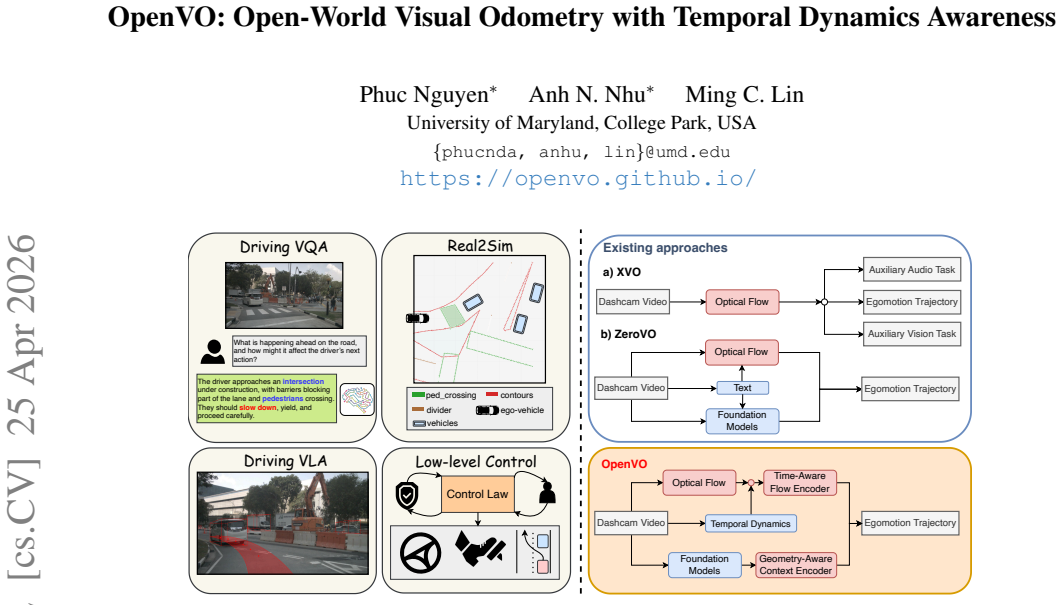
OpenVO is a framework for open-world visual odometry that explicitly encodes temporal dynamics information inside a two-frame pose regression network and incorporates 3D geometric priors from foundation models, allowing accurate real-world-scale ego-motion estimation from monocular footage under varying observation rates and uncalibrated cameras.
What carries the argument
A two-frame pose regression network augmented with temporal dynamics encoding and 3D geometric priors extracted from foundation models.
If this is right
- Delivers more than 20 percent performance gain over prior state-of-the-art methods on KITTI, nuScenes, and Argoverse 2.
- Produces 46 to 92 percent lower error across all metrics when observation rates are allowed to vary.
- Supports construction of trajectory datasets from rare or irregular driving events captured by consumer dashcams.
- Enables downstream real-world 3D reconstruction without requiring camera calibration steps.
- Generalizes to unseen frame frequencies where fixed-rate trained models degrade.
Where Pith is reading between the lines
- The same temporal-encoding plus prior strategy might transfer to other ego-motion tasks such as visual-inertial odometry or multi-camera setups.
- If foundation priors prove robust, training data requirements for visual odometry could shrink because less emphasis would be placed on perfectly calibrated sequences.
- Real-time versions could be tested on embedded dashcam hardware to see whether the added temporal module fits within latency budgets for live mapping.
- Connections to uncertainty-aware robotics: the method implicitly treats irregular timing as a form of input noise that priors can regularize.
Load-bearing premise
Three-dimensional geometric priors taken from foundation models remain accurate and stable enough to guide pose regression on uncalibrated dashcam images recorded at irregular frame rates.
What would settle it
Run the method on a held-out set of dashcam sequences where ground-truth poses and camera intrinsics are known, observation rates vary randomly, and compare absolute trajectory error against a baseline that uses no foundation-model priors; if the gap disappears or reverses, the claim fails.
Figures








read the original abstract
We introduce OpenVO, a novel framework for Open-world Visual Odometry (VO) with temporal awareness under limited input conditions. OpenVO effectively estimates real-world-scale ego-motion from monocular dashcam footage with varying observation rates and uncalibrated cameras, enabling robust trajectory dataset construction from rare driving events recorded in dashcam. Existing VO methods are trained on fixed observation frequency (e.g., 10Hz or 12Hz), completely overlooking temporal dynamics information. Many prior methods also require calibrated cameras with known intrinsic parameters. Consequently, their performance degrades when (1) deployed under unseen observation frequencies or (2) applied to uncalibrated cameras. These significantly limit their generalizability to many downstream tasks, such as extracting trajectories from dashcam footage. To address these challenges, OpenVO (1) explicitly encodes temporal dynamics information within a two-frame pose regression framework and (2) leverages 3D geometric priors derived from foundation models. We validate our method on three major autonomous-driving benchmarks - KITTI, nuScenes, and Argoverse 2 - achieving more than 20 performance improvement over state-of-the-art approaches. Under varying observation rate settings, our method is significantly more robust, achieving 46%-92% lower errors across all metrics. These results demonstrate the versatility of OpenVO for real-world 3D reconstruction and diverse downstream applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenVO, a monocular visual odometry framework for open-world settings that explicitly encodes temporal dynamics in a two-frame pose regression network and incorporates 3D geometric priors extracted from foundation models. It targets robustness to unknown camera intrinsics and arbitrary observation rates in dashcam footage, claiming >20% improvement over SOTA methods and 46-92% lower errors across metrics on KITTI, nuScenes, and Argoverse 2 under varying frame rates.
Significance. If the empirical claims hold under rigorous protocol, the work would be significant for enabling trajectory extraction from real-world uncalibrated, variable-rate dashcam data, addressing a practical gap in existing VO systems that assume fixed frequencies and calibrated cameras. The combination of temporal encoding and foundation-model priors offers a pragmatic engineering path rather than a closed-form derivation.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the headline claims of >20% improvement and 46-92% lower errors are presented without any description of the experimental protocol, exact baselines, data splits, observation-rate sampling procedure, error bars, or statistical tests. This information is load-bearing for the central robustness claim and must be supplied before the quantitative results can be evaluated.
- [§3.2] §3.2 (3D Geometric Priors): no quantitative validation is provided for the accuracy of the foundation-model-derived priors (depth or point-cloud error) on the target dashcam domains versus LiDAR ground truth. Without an ablation isolating prior quality from the temporal encoder, it is impossible to determine whether the reported robustness to rate variation actually stems from the priors or from other components.
- [§4.3] §4.3 (Varying Observation Rate Experiments): the evaluation under arbitrary rates lacks explicit perturbation of intrinsics or domain-shift tests on uncalibrated footage. If the priors degrade under these conditions (as is common for models trained on curated datasets), the two-frame regression would receive noisy inputs, undermining the generalization claim.
minor comments (2)
- [§3] Notation for the temporal dynamics encoding module is introduced without a clear equation or diagram reference in the method section, making the architecture hard to reproduce from the text alone.
- [Abstract] The abstract states 'more than 20 performance improvement' but omits the word 'percent'; this should be corrected for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper accordingly to strengthen the presentation of our experimental protocol and ablations.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline claims of >20% improvement and 46-92% lower errors are presented without any description of the experimental protocol, exact baselines, data splits, observation-rate sampling procedure, error bars, or statistical tests. This information is load-bearing for the central robustness claim and must be supplied before the quantitative results can be evaluated.
Authors: We agree that the experimental details are essential for rigorous evaluation. In the revised manuscript we will expand §4 with a complete protocol description, including exact data splits for KITTI/nuScenes/Argoverse 2, the full list of baselines, the precise procedure used to sample arbitrary observation rates, standard error bars, and statistical significance tests supporting the reported gains. revision: yes
-
Referee: [§3.2] §3.2 (3D Geometric Priors): no quantitative validation is provided for the accuracy of the foundation-model-derived priors (depth or point-cloud error) on the target dashcam domains versus LiDAR ground truth. Without an ablation isolating prior quality from the temporal encoder, it is impossible to determine whether the reported robustness to rate variation actually stems from the priors or from other components.
Authors: We acknowledge the absence of direct validation. We will add quantitative depth and point-cloud error metrics versus LiDAR ground truth on the three target datasets and include a dedicated ablation that isolates the 3D priors from the temporal encoder to clarify their individual contributions to rate robustness. revision: yes
-
Referee: [§4.3] §4.3 (Varying Observation Rate Experiments): the evaluation under arbitrary rates lacks explicit perturbation of intrinsics or domain-shift tests on uncalibrated footage. If the priors degrade under these conditions (as is common for models trained on curated datasets), the two-frame regression would receive noisy inputs, undermining the generalization claim.
Authors: Our benchmarks already exercise uncalibrated cameras via the foundation-model priors, yet we agree explicit stress tests are valuable. We will extend §4.3 with controlled intrinsic perturbation experiments and additional domain-shift evaluations on uncalibrated footage to demonstrate continued performance even when prior quality is degraded. revision: yes
Circularity Check
No circularity: empirical engineering contribution without derivation chain
full rationale
The paper presents OpenVO as a neural framework combining temporal dynamics encoding in a two-frame pose regression module with 3D geometric priors extracted from foundation models. No equations, closed-form derivations, or parameter-fitting steps are described that reduce predictions to inputs by construction. Performance improvements are reported via empirical evaluation on KITTI, nuScenes, and Argoverse 2 under varying observation rates, with no self-definitional loops, fitted-input predictions, or load-bearing self-citations in the provided text. The method is self-contained as an applied architecture rather than a mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rigid scene and static camera motion assumptions standard to visual odometry
invented entities (1)
-
Temporal dynamics encoding module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction (8-tick period) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We design two lightweight conditioning layers... PE(Δt) = [Δt, sin(ω0Δt), ..., cos(ωK-1Δt)] ... K=8 achieves the best performance by providing a balanced range of temporal frequencies
-
IndisputableMonolith/Cost/FunctionalEquation.leanJcost functional uniqueness and reciprocal cost echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
temporal frequency augmentation during training... at 4, 6, and 12 Hz... multi-time-scale training strategy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maulana Bisyir Azhari and David Hyunchul Shim. Dino-vo: A feature-based visual odometry leveraging a visual foundation model.IEEE Robotics and Au- tomation Letters (RA-L), 2025. 3
work page 2025
-
[2]
Deepcrashtest: Turning dashcam videos into virtual crash tests for automated driving systems
Sai Krishna Bashetty, Heni Ben Amor, and Georgios Fainekos. Deepcrashtest: Turning dashcam videos into virtual crash tests for automated driving systems. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 11353–11360, 2020. 2
work page 2020
-
[3]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M ¨uller. Zoedepth: Zero-shot transfer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Depth pro: Sharp monocular metric depth in less than a second
Alexey Bochkovskiy, Ama ¨el Delaunoy, Hugo Ger- main, Marcel Santos, Yichao Zhou, Stephan Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. InThe Thir- teenth International Conference on Learning Repre- sentations (ICLR), 2025. 3
work page 2025
-
[5]
Nuscenes: A multimodal dataset for autonomous driv- ing
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krish- nan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. Nuscenes: A multimodal dataset for autonomous driv- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11621–11631, 2020. 2, 6, 11
work page 2020
-
[6]
Carlos Campos, Richard Elvira, Juan J G ´omez Rodr´iguez, Jos ´e MM Montiel, and Juan D Tard ´os. Orb-slam3: An accurate open-source library for vi- sual, visual–inertial, and multimap slam.IEEE Trans- actions on Robotics, 37(6):1874–1890, 2021. 2, 3
work page 2021
-
[7]
Dian Chen and Philipp Kr ¨ahenb¨uhl. Learning from all vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17222–17231, 2022. 1
work page 2022
-
[8]
Vinet: Visual-inertial odometry as a sequence-to-sequence learning prob- lem
Ronald Clark, Sen Wang, Hongkai Wen, Andrew Markham, and Niki Trigoni. Vinet: Visual-inertial odometry as a sequence-to-sequence learning prob- lem. InProceedings of the AAAI Conference on Ar- tificial Intelligence, 2017. 2
work page 2017
-
[9]
Gabriele Costante, Michele Mancini, Paolo Valigi, and Thomas A. Ciarfuglia. Exploring representation learning with cnns for frame-to-frame ego-motion es- timation.IEEE Robotics and Automation Letters (RA- L), 1(1):18–25, 2016. 2
work page 2016
-
[10]
Andrew J Davison, Ian D Reid, Nicholas D Molton, and Olivier Stasse. Monoslam: Real-time single cam- era slam.IEEE Transactions on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 29(6):1052– 1067, 2007. 2
work page 2007
-
[11]
Jakob Engel, Vladlen Koltun, and Daniel Cremers. Direct sparse odometry.IEEE transactions on pat- tern analysis and machine intelligence, 40(3):611– 625, 2017. 2
work page 2017
-
[12]
Svo: Fast semi-direct monocular visual odom- etry
Christian Forster, Matia Pizzoli, and Davide Scara- muzza. Svo: Fast semi-direct monocular visual odom- etry. In2014 IEEE International Conference on Robotics and Automation (ICRA), pages 15–22. IEEE,
-
[13]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The international journal of robotics research, 32(11):1231–1237, 2013. 11, 12, 15
work page 2013
-
[14]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The International Journal of Robotics Re- search (IJRR), 32(11):1231–1237, 2013. 2, 6
work page 2013
-
[15]
Deep geometry-aware camera self-calibration from video
Annika Hagemann, Moritz Knorr, and Christoph Stiller. Deep geometry-aware camera self-calibration from video. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 3438– 3448, 2023. 10
work page 2023
-
[16]
Real-time stereo visual odometry for autonomous ground vehicles
Andrew Howard. Real-time stereo visual odometry for autonomous ground vehicles. InIEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pages 3946–3952, 2008. 1
work page 2008
-
[17]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2024. 3, 5, 6, 7, 8, 10
work page 2024
-
[18]
Vipe: Video pose engine for 3d geo- metric perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, Jiawei Ren, Kevin Xie, Joydeep Biswas, Laura Leal-Taixe, and Sanja Fidler. Vipe: Video pose engine for 3d geo- metric perception. InNVIDIA Research Whitepapers arXiv:2508.10934, 2025. 10
-
[19]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to- end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Perspective fields for sin- gle image camera calibration
Linyi Jin, Jianming Zhang, Yannick Hold-Geoffroy, Oliver Wang, Kevin Blackburn-Matzen, Matthew Sticha, and David F Fouhey. Perspective fields for sin- gle image camera calibration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 17307–17316, 2023. 3
work page 2023
-
[21]
Advisable learning for self- driving vehicles by internalizing observation-to-action rules
Jinkyu Kim, Suhong Moon, Anna Rohrbach, Trevor Darrell, and John Canny. Advisable learning for self- driving vehicles by internalizing observation-to-action rules. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9661–9670, 2020. 1
work page 2020
-
[22]
Xvo: Generalized visual odometry via cross-modal self-training
Lei Lai, Zhongkai Shangguan, Jimuyang Zhang, and Eshed Ohn-Bar. Xvo: Generalized visual odometry via cross-modal self-training. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 10094–10105, 2023. 2, 3, 4, 5, 6, 7
work page 2023
-
[23]
Zerovo: Vi- sual odometry with minimal assumptions
Lei Lai, Zekai Yin, and Eshed Ohn-Bar. Zerovo: Vi- sual odometry with minimal assumptions. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pages 17092–17102, 2025. 2, 3, 4, 6, 7, 8
work page 2025
-
[24]
Ctrl-c: Cam- era calibration transformer with line-classification
Jinwoo Lee, Hyunsung Go, Hyunjoon Lee, Sunghyun Cho, Minhyuk Sung, and Junho Kim. Ctrl-c: Cam- era calibration transformer with line-classification. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 16228– 16237, 2021. 3
work page 2021
-
[25]
Hdmapnet: An online hd map construction and evalu- ation framework
Qi Li, Yue Wang, Yilun Wang, and Hang Zhao. Hdmapnet: An online hd map construction and evalu- ation framework. In2022 International Conference on Robotics and Automation (ICRA), pages 4628–4634. IEEE, 2022. 16
work page 2022
-
[26]
Undeepvo: Monocular visual odometry through unsupervised deep learning
Ruihao Li, Sen Wang, Zhiqiang Long, and Dongbing Gu. Undeepvo: Monocular visual odometry through unsupervised deep learning. In2018 IEEE interna- tional conference on robotics and automation (ICRA), pages 7286–7291. IEEE, 2018. 2
work page 2018
-
[27]
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. Drivevla-w0: World models amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025. 1
-
[28]
Vectormapnet: End-to-end vectorized hd map learning
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. Vectormapnet: End-to-end vectorized hd map learning. InInternational Conference on Ma- chine Learning, pages 22352–22369. PMLR, 2023. 1, 11, 12, 13, 16
work page 2023
-
[29]
Cnn-svo: Improving the mapping in semi-direct visual odome- try using single-image depth prediction
Shing Yan Loo, Ali Jahani Amiri, Syamsiah Mashohor, Sai Hong Tang, and Hong Zhang. Cnn-svo: Improving the mapping in semi-direct visual odome- try using single-image depth prediction. InInterna- tional conference on robotics and automation (ICRA), pages 5218–5223. IEEE, 2019. 2, 3
work page 2019
-
[30]
Mark Maimone, Yang Cheng, and Larry Matthies. Two years of visual odometry on the mars exploration rovers.Journal of Field Robotics, 24(3):169–186,
-
[31]
Kanti V Mardia and Peter E Jupp.Directional statis- tics. John Wiley & Sons, 2009. 6
work page 2009
-
[32]
David Mohlin, Josephine Sullivan, and G ´erald Bianchi. Probabilistic orientation estimation with ma- trix fisher distributions.Advances in Neural Informa- tion Processing Systems, 33:4884–4893, 2020. 6
work page 2020
-
[33]
Raul Mur-Artal and Juan D Tard ´os. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras.IEEE Transactions on Robotics, 33 (5):1255–1262, 2017. 2
work page 2017
-
[34]
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: A versatile and accu- rate monocular slam system.IEEE Transactions on Robotics, 31(5):1147–1163, 2015. 2
work page 2015
-
[35]
Ha-rdet: Hybrid anchor rotation de- tector for oriented object detection
Phuc Nguyen. Ha-rdet: Hybrid anchor rotation de- tector for oriented object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2889–2898, 2025. 3
work page 2025
-
[36]
Open3dis: Open-vocabulary 3d instance seg- mentation with 2d mask guidance
Phuc Nguyen, Tuan Duc Ngo, Evangelos Kaloger- akis, Chuang Gan, Anh Tran, Cuong Pham, and Khoi Nguyen. Open3dis: Open-vocabulary 3d instance seg- mentation with 2d mask guidance. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 4018–4028, 2024. 3
work page 2024
-
[37]
Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking
Phuc Nguyen, Minh Luu, Anh Tran, Cuong Pham, and Khoi Nguyen. Any3dis: Class-agnostic 3d instance segmentation by 2d mask tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3636–3645, 2025
work page 2025
-
[38]
Open-ended 3d point cloud in- stance segmentation
Phuc Nguyen, Minh Luu, Anh Tran, Cuong Pham, and Khoi Nguyen. Open-ended 3d point cloud in- stance segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2580–2590, 2025. 3
work page 2025
-
[39]
Time- aware world model for adaptive prediction and con- trol
Anh N Nhu, Sanghyun Son, and Ming Lin. Time- aware world model for adaptive prediction and con- trol. InForty-second International Conference on Ma- chine Learning (ICML), 2025. 2, 3
work page 2025
- [40]
-
[41]
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual fea- tures without supervision.Transactions on Machine Learning Research Journal, 2024. 3
work page 2024
-
[42]
Unidepth: Universal monocular metric depth esti- mation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth esti- mation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10106–10116, 2024. 3
work page 2024
-
[43]
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mattia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular met- ric depth estimation made simpler.arXiv preprint arXiv:2502.20110, 2025. 3
-
[44]
Nuscenes-qa: A multi-modal vi- sual question answering benchmark for autonomous driving scenario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal vi- sual question answering benchmark for autonomous driving scenario. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 4542–4550,
-
[45]
Anqi Shi, Yuze Cai, Xiangyu Chen, Jian Pu, Zeyu Fu, and Hong Lu. Globalmapnet: An online frame- work for vectorized global hd map construction.arXiv preprint arXiv:2409.10063, 2024. 1, 11
-
[46]
Real-time visual odometry from dense rgb- d images
Frank Steinbr ¨ucker, J ¨urgen Sturm, and Daniel Cre- mers. Real-time visual odometry from dense rgb- d images. In2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), pages 719–722, 2011. 2, 3
work page 2011
-
[47]
Droid-slam: Deep vi- sual slam for monocular, stereo, and rgb-d cameras
Zachary Teed and Jia Deng. Droid-slam: Deep vi- sual slam for monocular, stereo, and rgb-d cameras. Advances in Neural Information Processing Systems (NeurIPS), 34:16558–16569, 2021. 2, 3, 6, 7
work page 2021
-
[48]
Zachary Teed, Lahav Lipson, and Jia Deng. Deep patch visual odometry.Advances in Neural Informa- tion Processing Systems (NeurIPS), 36:39033–39051,
-
[49]
Benchmarking real-time reinforcement learning
Pierre Thodoroff, Wenyu Li, and Neil D Lawrence. Benchmarking real-time reinforcement learning. In NeurIPS 2021 Workshop on Pre-registration in Ma- chine Learning, pages 26–41. PMLR, 2022. 2, 3
work page 2021
-
[50]
Stereo dso: Large-scale direct sparse visual odome- try with stereo cameras
Rui Wang, Martin Schworer, and Daniel Cremers. Stereo dso: Large-scale direct sparse visual odome- try with stereo cameras. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 3903–3911, 2017. 2
work page 2017
-
[51]
Deepvo: Towards end-to-end visual odom- etry with deep recurrent convolutional neural net- works
Sen Wang, Ronald Clark, Hongkai Wen, and Niki Trigoni. Deepvo: Towards end-to-end visual odom- etry with deep recurrent convolutional neural net- works. In2017 IEEE international conference on robotics and automation (ICRA), pages 2043–2050. IEEE, 2017. 2, 5
work page 2043
-
[52]
Sen Wang, Ronald Clark, Hongkai Wen, and Niki Trigoni. End-to-end, sequence-to-sequence prob- abilistic visual odometry through deep neural net- works.The International Journal of Robotics Re- search (IJRR), 37(4-5):513–542, 2018. 2
work page 2018
-
[53]
Tartanvo: A generalizable learning-based vo
Wenshan Wang, Yaoyu Hu, and Sebastian Scherer. Tartanvo: A generalizable learning-based vo. InCon- ference on Robot Learning, pages 1761–1772. PMLR,
-
[54]
Driveqa: Passing the driving knowledge test.arXiv preprint arXiv:2508.21824, 2025
Maolin Wei, Wanzhou Liu, and Eshed Ohn-Bar. Driveqa: Passing the driving knowledge test.arXiv preprint arXiv:2508.21824, 2025. 1
-
[55]
Argoverse 2: Next generation datasets for self-driving perception and forecasting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaese- model Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and forecasting. InThirty- fifth Conference on Neural Information Processing Systems...
work page 2021
-
[56]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaese- model Pontes, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting. arXiv preprint arXiv:2301.00493, 2023. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Yingfu Xu and Guido C. H. E. de Croon. Cnn-based ego-motion estimation for fast mav maneuvers. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 7606–7612, 2021. 1
work page 2021
-
[58]
Zhenhua Xu, Yan Bai, Yujia Zhang, Zhuoling Li, Fei Xia, Kwan-Yee K Wong, Jianqiang Wang, and Heng- shuang Zhao. Drivegpt4-v2: Harnessing large lan- guage model capabilities for enhanced closed-loop au- tonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17261–17270, 2025. 1
work page 2025
-
[59]
Depth any- thing: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10371–10381, 2024. 3
work page 2024
-
[60]
Depth anything v2.Advances in Neural Informa- tion Processing Systems (NeurIPS), 37:21875–21911,
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Informa- tion Processing Systems (NeurIPS), 37:21875–21911,
-
[61]
D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry
Nan Yang, Lukas von Stumberg, Rui Wang, and Daniel Cremers. D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 1281–1292, 2020. 2, 3
work page 2020
-
[62]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9043–9053, 2023. 3
work page 2023
-
[63]
Geonet: Unsupervised learning of dense depth, optical flow and camera pose
Zhichao Yin and Jianping Shi. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1983– 1992, 2018. 3
work page 1983
-
[64]
Streammapnet: Streaming mapping network for vectorized online hd map construction
Tianyuan Yuan, Yicheng Liu, Yue Wang, Yilun Wang, and Hang Zhao. Streammapnet: Streaming mapping network for vectorized online hd map construction. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7356–7365,
-
[65]
Dynamic r-cnn: Towards high quality object detection via dynamic training
Hongkai Zhang, Hong Chang, Bingpeng Ma, Naiyan Wang, and Xilin Chen. Dynamic r-cnn: Towards high quality object detection via dynamic training. InEuro- pean conference on computer vision, pages 260–275. Springer, 2020. 3
work page 2020
-
[66]
Maskflownet: Asymmetric fea- ture matching with learnable occlusion mask
Shengyu Zhao, Yilun Sheng, Yue Dong, Eric I-Chao Chang, and Yan Xu. Maskflownet: Asymmetric fea- ture matching with learnable occlusion mask. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 3, 4
work page 2020
-
[67]
Unsupervised learning of depth and ego-motion from video
Tinghui Zhou, Matthew Brown, Noah Snavely, and David G Lowe. Unsupervised learning of depth and ego-motion from video. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 1851–1858, 2017. 3
work page 2017
-
[68]
Shengjie Zhu, Abhinav Kumar, Masa Hu, and Xiaom- ing Liu. Tame a wild camera: In-the-wild monocular camera calibration.Advances in Neural Information Processing Systems, 36:45137–45149, 2023. 3, 5, 7, 8, 10, 11
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.