Recognition: 2 theorem links
· Lean TheoremPFGNet: A Fully Convolutional Frequency-Guided Peripheral Gating Network for Efficient Spatiotemporal Predictive Learning
Pith reviewed 2026-05-15 20:28 UTC · model grok-4.3
The pith
Frequency-guided peripheral gating lets pure convolutional networks match video forecasting accuracy with far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Peripheral Frequency Gating block extracts localized spectral cues and adaptively fuses multi-scale large-kernel peripheral responses with learnable center suppression, thereby forming spatially adaptive band-pass filters. These filters enable a pure convolutional stack to capture spatially varying motion patterns in spatiotemporal prediction tasks, delivering SOTA or near-SOTA results on Moving MNIST, TaxiBJ, Human3.6M, and KTH while using substantially fewer parameters and FLOPs than recurrent or hybrid baselines.
What carries the argument
The Peripheral Frequency Gating (PFG) block, which extracts localized spectral cues to form spatially adaptive band-pass filters by modulating multi-scale peripheral responses around a learnable center suppression.
If this is right
- Pure convolutional architectures can reach competitive spatiotemporal forecasting performance without recurrent connections or attention layers.
- Decomposing large kernels into separable 1-by-k and k-by-1 convolutions preserves large receptive fields while reducing per-channel cost from quadratic to linear.
- Spatially varying motion is handled by letting each pixel select its own effective band-pass filter rather than applying a uniform kernel across the frame.
- The resulting model runs with full parallelism and lower memory footprint, suiting real-time or resource-constrained forecasting applications.
- The same gating principle scales across datasets that differ in motion complexity and resolution.
Where Pith is reading between the lines
- The same frequency-guided adaptation could be inserted into other convolutional backbones for tasks that need variable receptive fields, such as action recognition or optical flow.
- If spectral cues prove sufficient for motion selectivity, similar lightweight gating blocks might replace attention in video compression or frame interpolation pipelines.
- Extending the block to operate on longer temporal windows without recurrence would test whether the frequency mechanism alone sustains coherence over many prediction steps.
- A direct comparison on datasets with strong periodic textures versus chaotic motion could isolate when frequency guidance provides the largest gain.
- keywords:[
Load-bearing premise
Localized spectral cues extracted per pixel can reliably produce spatially adaptive filters that capture varying motion patterns better than fixed-receptive-field convolutions.
What would settle it
A controlled ablation on the same datasets that removes the frequency-extraction path from the PFG block and shows no drop or an increase in forecasting error would falsify the necessity of the spectral guidance.
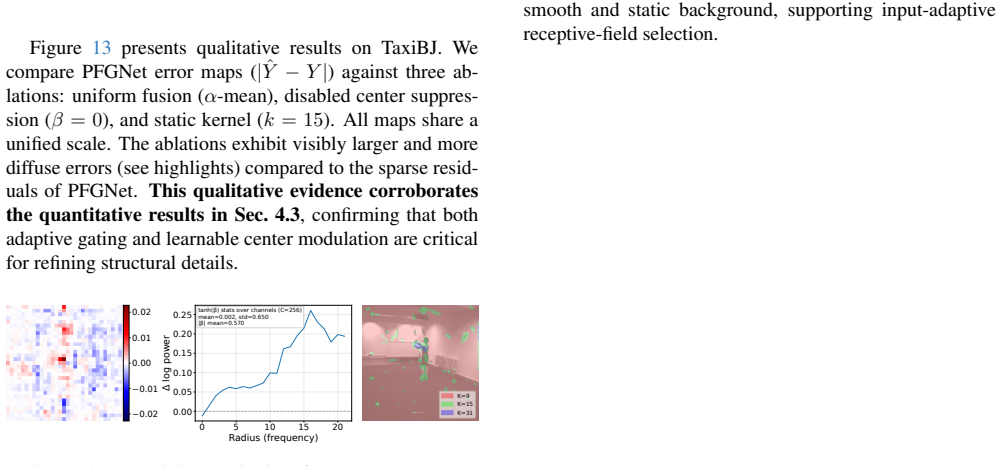
Figures











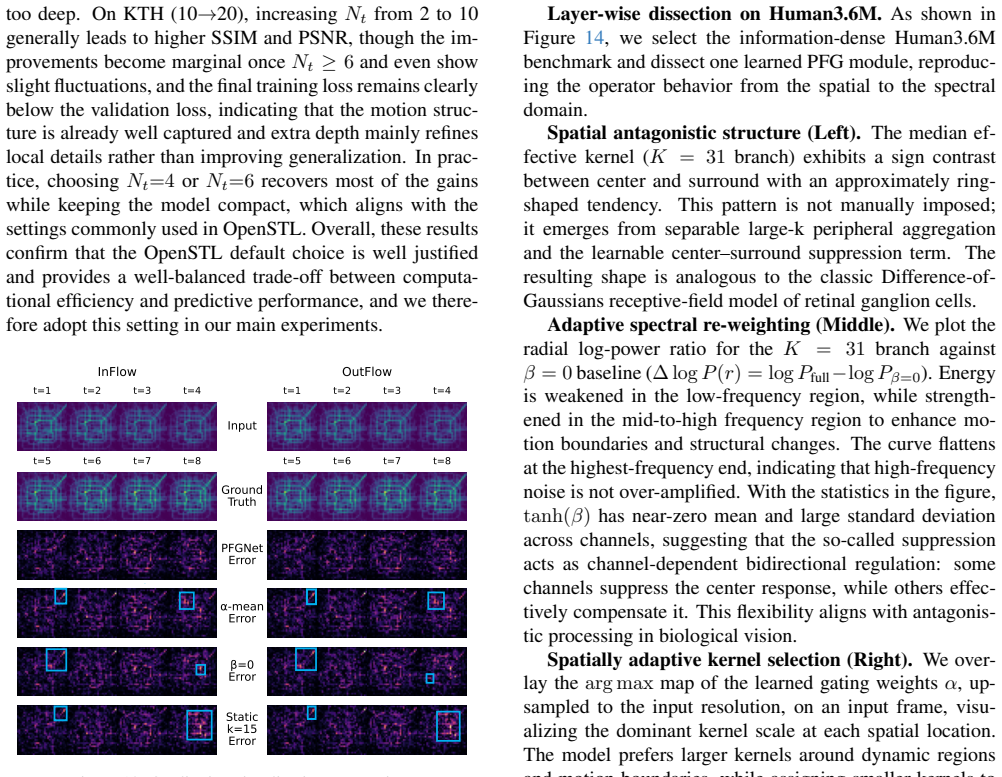
read the original abstract
Spatiotemporal predictive learning (STPL) aims to forecast future frames from past observations and is essential across a wide range of applications. Compared with recurrent or hybrid architectures, pure convolutional models offer superior efficiency and full parallelism, yet their fixed receptive fields limit their ability to adaptively capture spatially varying motion patterns. Inspired by biological center-surround organization and frequency-selective signal processing, we propose PFGNet, a fully convolutional framework that dynamically modulates receptive fields through pixel-wise frequency-guided gating. The core Peripheral Frequency Gating (PFG) block extracts localized spectral cues and adaptively fuses multi-scale large-kernel peripheral responses with learnable center suppression, effectively forming spatially adaptive band-pass filters. To maintain efficiency, all large kernels are decomposed into separable 1D convolutions ($1 \times k$ followed by $k \times 1$), reducing per-channel computational cost from $O(k^2)$ to $O(2k)$. PFGNet enables structure-aware spatiotemporal modeling without recurrence or attention. Experiments on Moving MNIST, TaxiBJ, Human3.6M, and KTH show that PFGNet delivers SOTA or near-SOTA forecasting performance with substantially fewer parameters and FLOPs. Our code is available at https://github.com/fhjdqaq/PFGNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PFGNet, a fully convolutional framework for spatiotemporal predictive learning. Its core Peripheral Frequency Gating (PFG) block extracts localized spectral cues to adaptively fuse multi-scale peripheral responses with learnable center suppression, forming spatially adaptive band-pass filters. All large kernels are decomposed into separable 1×k followed by k×1 convolutions to reduce cost from O(k²) to O(2k). Experiments on Moving MNIST, TaxiBJ, Human3.6M, and KTH report SOTA or near-SOTA forecasting performance with substantially fewer parameters and FLOPs than recurrent or attention-based baselines.
Significance. If the performance gains trace to the frequency-guided adaptive filtering rather than kernel decomposition alone, the work would advance efficient pure-convolutional STPL by supplying a biologically motivated mechanism for dynamic receptive fields without recurrence or attention. Public code release at https://github.com/fhjdqaq/PFGNet is a clear strength that supports reproducibility.
major comments (1)
- [Experiments] The headline SOTA/near-SOTA claims with reduced parameters rest on the assertion that localized spectral cues inside the PFG block produce spatially adaptive band-pass filters superior to fixed-receptive-field convolutions. No ablation isolating the frequency pathway from the 1×k + k×1 decomposition is reported in the experiments on Moving MNIST, TaxiBJ, Human3.6M, or KTH; without such controls the central architectural novelty is not shown to be load-bearing for the accuracy-efficiency tradeoff.
minor comments (1)
- [Experiments] Benchmark tables do not include error bars or run-to-run variance, which would allow readers to assess the statistical reliability of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the opportunity to strengthen the manuscript. We address the single major comment below and will revise accordingly.
read point-by-point responses
-
Referee: The headline SOTA/near-SOTA claims with reduced parameters rest on the assertion that localized spectral cues inside the PFG block produce spatially adaptive band-pass filters superior to fixed-receptive-field convolutions. No ablation isolating the frequency pathway from the 1×k + k×1 decomposition is reported in the experiments on Moving MNIST, TaxiBJ, Human3.6M, or KTH; without such controls the central architectural novelty is not shown to be load-bearing for the accuracy-efficiency tradeoff.
Authors: We agree that an explicit ablation isolating the frequency-guided pathway from the separable-convolution decomposition would more directly substantiate the central claim. In the current experiments the full PFGNet (frequency cues + peripheral fusion + 1×k/k×1 decomposition) is compared against baselines lacking both the adaptive mechanism and the large-kernel paths; the decomposition itself is presented only as an efficiency implementation detail for the peripheral kernels. To address the referee’s concern we will add a controlled ablation in the revision: we replace the spectral-cue extraction inside the PFG block with a non-frequency (standard convolutional) gating module while retaining the identical 1×k + k×1 decomposition and all other hyperparameters, then report results on Moving MNIST and TaxiBJ. This will quantify the incremental contribution of the frequency pathway to the reported accuracy-efficiency tradeoff. revision: yes
Circularity Check
No significant circularity; PFGNet design and claims are self-contained via empirical evaluation
full rationale
The paper introduces PFGNet as a novel fully convolutional architecture with a Peripheral Frequency Gating block that extracts localized spectral cues and fuses multi-scale responses using decomposed separable convolutions. This is framed as an independent design choice drawing from biological inspiration, without any equations, fitted parameters, or predictions that reduce to the inputs by construction. Performance claims on Moving MNIST, TaxiBJ, Human3.6M, and KTH rest on reported experimental results rather than self-referential definitions or load-bearing self-citations. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable center suppression weights
axioms (1)
- domain assumption Convolutional layers with adaptive receptive fields can model spatially varying motion without recurrence
invented entities (1)
-
Peripheral Frequency Gating (PFG) block
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The core Peripheral Frequency Gating (PFG) block extracts localized spectral cues and adaptively fuses multi-scale large-kernel peripheral responses with learnable center suppression, effectively forming spatially adaptive band-pass filters.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
all large kernels are decomposed into separable 1D convolutions (1×k followed by k×1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Andrea Alfarano, Alberto Alfarano, Linda Friso, Andrea Bacciu, Irene Amerini, and Fabrizio Silvestri. Stlight: A fully convolutional approach for efficient predictive learning by spatio-temporal joint processing. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1090–1100, 2025. 1
work page 2025
-
[2]
Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H. Campbell, and Sergey Levine. Stochastic variational video prediction. InInternational Conference on Learning Representations, 2018. 1
work page 2018
-
[3]
Long-term on-board prediction of people in traffic scenes under uncertainty
Apratim Bhattacharyya, Mario Fritz, and Bernt Schiele. Long-term on-board prediction of people in traffic scenes under uncertainty. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4194– 4202, 2018. 1
work page 2018
-
[4]
Zheng Chang, Xinfeng Zhang, Shanshe Wang, Siwei Ma, Yan Ye, Xiang Xinguang, and Wen Gao. Mau: A motion- aware unit for video prediction and beyond.Advances in Neural Information Processing Systems, 34:26950–26962,
-
[5]
Pelk: Parameter-efficient large kernel convnets with peripheral convolution
Honghao Chen, Xiangxiang Chu, Yongjian Ren, Xin Zhao, and Kaiqi Huang. Pelk: Parameter-efficient large kernel convnets with peripheral convolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5557–5567, 2024. 3
work page 2024
-
[6]
Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution
Yunpeng Chen, Haoqi Fan, Bing Xu, Zhicheng Yan, Yan- nis Kalantidis, Marcus Rohrbach, Shuicheng Yan, and Ji- ashi Feng. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019. 3
work page 2019
-
[7]
Jinguo Cheng, Ke Li, Yuxuan Liang, Lijun Sun, Junchi Yan, and Yuankai Wu. Rethinking urban mobility prediction: A multivariate time series forecasting approach.IEEE Trans- actions on Intelligent Transportation Systems, 26(2):2543– 2557, 2024. 1
work page 2024
-
[8]
Andy Clark.Surfing uncertainty: Prediction, action, and the embodied mind. Oxford University Press, 2015. 1
work page 2015
-
[9]
Language modeling with gated convolutional net- works
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional net- works. InInternational Conference on Machine Learning, pages 933–941. PMLR, 2017. 2, 5
work page 2017
-
[10]
Scaling up your kernels to 31x31: Revisiting large kernel design in cnns
Xiaohan Ding, Xiangyu Zhang, Jungong Han, and Guiguang Ding. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11963–11975, 2022. 2
work page 2022
-
[11]
Xiaohan Ding, Yiyuan Zhang, Yixiao Ge, Sijie Zhao, Lin Song, Xiangyu Yue, and Ying Shan. Unireplknet: A uni- versal perception large-kernel convnet for audio video point cloud time-series and image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5513–5524, 2024. 2, 3
work page 2024
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions, 2021. 2, 7, 4
work page 2021
-
[13]
Gstnet: Global spatial-temporal network for traffic flow prediction
Shen Fang, Qi Zhang, Gaofeng Meng, Shiming Xiang, and Chunhong Pan. Gstnet: Global spatial-temporal network for traffic flow prediction. InProceedings of the 28th In- ternational Joint Conference on Artificial Intelligence, pages 2286–2293, 2019. 1
work page 2019
-
[14]
Zhangyang Gao, Cheng Tan, Lirong Wu, and Stan Z. Li. Simvp: Simpler yet better video prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 3170–3180, 2022. 1, 2, 3, 5, 6, 7, 4
work page 2022
-
[15]
Pearson edu- cation india, 2009
Rafael C Gonzalez.Digital image processing. Pearson edu- cation india, 2009. 2
work page 2009
-
[16]
Disentangling physi- cal dynamics from unknown factors for unsupervised video prediction
Vincent Le Guen and Nicolas Thome. Disentangling physi- cal dynamics from unknown factors for unsupervised video prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11474– 11484, 2020. 2, 6, 7, 4
work page 2020
-
[17]
Efficient token mix- ing for transformers via adaptive fourier neural operators
John Guibas, Morteza Mardani, Zongyi Li, Andrew Tao, An- ima Anandkumar, and Bryan Catanzaro. Efficient token mix- ing for transformers via adaptive fourier neural operators. 9 InInternational Conference on Learning Representations,
-
[18]
Visual attention network.Compu- tational Visual Media, 9(4):733–752, 2023
Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, and Shi-Min Hu. Visual attention network.Compu- tational Visual Media, 9(4):733–752, 2023. 7, 4
work page 2023
-
[19]
A dynamic multi-scale voxel flow network for video prediction
Xiaotao Hu, Zhewei Huang, Ailin Huang, Jun Xu, and Shuchang Zhou. A dynamic multi-scale voxel flow network for video prediction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6121–6131, 2023. 4
work page 2023
-
[20]
David H Hubel and Torsten N Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex.The Journal of physiology, 160(1):106, 1962. 1
work page 1962
-
[21]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and pre- dictive methods for 3d human sensing in natural environ- ments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(7):1325–1339, 2013. 5
work page 2013
-
[22]
Dynamic filter networks.Advances in Neural Infor- mation Processing Systems, 29, 2016
Xu Jia, Bert De Brabandere, Tinne Tuytelaars, and Luc V Gool. Dynamic filter networks.Advances in Neural Infor- mation Processing Systems, 29, 2016. 6, 7
work page 2016
-
[23]
Varnet: Exploring variations for unsupervised video prediction
Beibei Jin, Yu Hu, Yiming Zeng, Qiankun Tang, Shice Liu, and Jing Ye. Varnet: Exploring variations for unsupervised video prediction. In2018 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS), pages 5801–
-
[24]
Beibei Jin, Yu Hu, Qiankun Tang, Jingyu Niu, Zhip- ing Shi, Yinhe Han, and Xiaowei Li. Exploring spatial- temporal multi-frequency analysis for high-fidelity and temporal-consistency video prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4554–4563, 2020. 7
work page 2020
-
[25]
Nal Kalchbrenner, A ¨aron Oord, Karen Simonyan, Ivo Dani- helka, Oriol Vinyals, Alex Graves, and Koray Kavukcuoglu. Video pixel networks. InInternational Conference on Ma- chine Learning, pages 1771–1779. PMLR, 2017. 6
work page 2017
-
[26]
Stephen W Kuffler. Discharge patterns and functional orga- nization of mammalian retina.Journal of neurophysiology, 16(1):37–68, 1953. 1
work page 1953
-
[27]
Predicting future frames using retrospective cycle gan
Yong-Hoon Kwon and Min-Gyu Park. Predicting future frames using retrospective cycle gan. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019. 1
work page 2019
-
[28]
Stochastic Adversarial Video Prediction
Alex X Lee, Richard Zhang, Frederik Ebert, Pieter Abbeel, Chelsea Finn, and Sergey Levine. Stochastic adversarial video prediction.arXiv preprint arXiv:1804.01523, 2018. 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Video prediction recalling long-term mo- tion context via memory alignment learning
Sangmin Lee, Hak Gu Kim, Dae Hwi Choi, Hyung-Il Kim, and Yong Man Ro. Video prediction recalling long-term mo- tion context via memory alignment learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 3054–3063, 2021. 6
work page 2021
-
[30]
Shiftwiseconv: Small convolutional kernel with large kernel effect
Dachong Li, Li Li, Zhuangzhuang Chen, and Jianqiang Li. Shiftwiseconv: Small convolutional kernel with large kernel effect. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 25281–25291,
-
[31]
Uniformer: Unified transformer for efficient spatial-temporal representation learning
Kunchang Li, Yali Wang, Gao Peng, Guanglu Song, Yu Liu, Hongsheng Li, and Yu Qiao. Uniformer: Unified transformer for efficient spatial-temporal representation learning. InIn- ternational Conference on Learning Representations, 2022. 7, 4
work page 2022
-
[32]
Siyuan Li, Zedong Wang, Zicheng Liu, Cheng Tan, Haitao Lin, Di Wu, Zhiyuan Chen, Jiangbin Zheng, and Stan Z. Li. Moganet: Multi-order gated aggregation network. InInter- national Conference on Learning Representations, 2024. 7, 4
work page 2024
-
[33]
Met2net: A decoupled two-stage spatio-temporal forecasting model for complex meteorological systems
Shaohan Li, Hao Yang, Min Chen, and Xiaolin Qin. Met2net: A decoupled two-stage spatio-temporal forecasting model for complex meteorological systems. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 5458–5468, 2025. 1, 2, 7
work page 2025
-
[34]
Discrete cosin transformer: Image modeling from frequency domain
Xinyu Li, Yanyi Zhang, Jianbo Yuan, Hanlin Lu, and Yibo Zhu. Discrete cosin transformer: Image modeling from frequency domain. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 5468–5478, 2023. 3
work page 2023
-
[35]
More convnets in the 2020s: Scaling up kernels beyond 51x51 us- ing sparsity
Shiwei Liu, Tianlong Chen, Xiaohan Chen, Xuxi Chen, Qiao Xiao, Boqian Wu, Tommi K¨arkk¨ainen, Mykola Pechenizkiy, Decebal Constantin Mocanu, and Zhangyang Wang. More convnets in the 2020s: Scaling up kernels beyond 51x51 us- ing sparsity. InInternational Conference on Learning Rep- resentations, 2023. 2, 3
work page 2023
-
[36]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021. 2, 7, 4
work page 2021
-
[37]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 11976–11986,
-
[38]
Deep predictive coding networks for video prediction and unsu- pervised learning
William Lotter, Gabriel Kreiman, and David Cox. Deep predictive coding networks for video prediction and unsu- pervised learning. InInternational Conference on Learning Representations, 2017. 1, 7, 4
work page 2017
-
[39]
David Marr and Ellen Hildreth. Theory of edge detection. Proceedings of the Royal Society of London. Series B. Bio- logical Sciences, 207(1167):187–217, 1980. 1, 2
work page 1980
-
[40]
Juhong Min, Yucheng Zhao, Chong Luo, and Minsu Cho. Peripheral vision transformer.Advances in Neural Informa- tion Processing Systems, 35:32097–32111, 2022. 3
work page 2022
-
[41]
Triplet attention transformer for spatiotemporal predictive learning
Xuesong Nie, Xi Chen, Haoyuan Jin, Zhihang Zhu, Yun- feng Yan, and Donglian Qi. Triplet attention transformer for spatiotemporal predictive learning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7036–7045, 2024. 2
work page 2024
-
[42]
Wavelet-driven spatiotemporal predictive learning: Bridg- ing frequency and time variations
Xuesong Nie, Yunfeng Yan, Siyuan Li, Cheng Tan, Xi Chen, Haoyuan Jin, Zhihang Zhu, Stan Z Li, and Donglian Qi. Wavelet-driven spatiotemporal predictive learning: Bridg- ing frequency and time variations. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4334– 4342, 2024. 2 10
work page 2024
-
[43]
Folded recur- rent neural networks for future video prediction
Marc Oliu, Javier Selva, and Sergio Escalera. Folded recur- rent neural networks for future video prediction. InProceed- ings of the European Conference on Computer Vision, pages 716–731, 2018. 6, 7
work page 2018
-
[44]
Xu Pan, Annie DeForge, and Odelia Schwartz. Generalizing biological surround suppression based on center surround similarity via deep neural network models.PLoS compu- tational biology, 19(9):e1011486, 2023. 2
work page 2023
-
[45]
Yongming Rao, Wenliang Zhao, Yansong Tang, Jie Zhou, Ser-Lam Lim, and Jiwen Lu. Hornet: Efficient high-order spatial interactions with recursive gated convolutions.Ad- vances in Neural Information Processing Systems, 2022. 7, 4
work page 2022
-
[46]
Recog- nizing human actions: a local svm approach
Christian Schuldt, Ivan Laptev, and Barbara Caputo. Recog- nizing human actions: a local svm approach. InProceedings of the 17th International Conference on Pattern Recognition,
- [47]
-
[48]
Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting.Advances in Neural Information Processing Systems, 28, 2015. 1, 2, 6, 7, 4
work page 2015
-
[49]
Unsupervised learning of video representations using lstms
Nitish Srivastava, Elman Mansimov, and Ruslan Salakhudi- nov. Unsupervised learning of video representations using lstms. InInternational Conference on Machine Learning, pages 843–852. PMLR, 2015. 5
work page 2015
-
[50]
Cheng Tan, Zhangyang Gao, Lirong Wu, Yongjie Xu, Jun Xia, Siyuan Li, and Stan Z. Li. Temporal attention unit: To- wards efficient spatiotemporal predictive learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18770–18782, 2023. 1, 6, 7, 4
work page 2023
-
[51]
Cheng Tan, Siyuan Li, Zhangyang Gao, Wenfei Guan, Ze- dong Wang, Zicheng Liu, Lirong Wu, and Stan Z Li. Open- stl: A comprehensive benchmark of spatio-temporal predic- tive learning.Advances in Neural Information Processing Systems, 36:69819–69831, 2023. 2, 5, 4
work page 2023
-
[52]
Cheng Tan, Zhangyang Gao, Siyuan Li, and Stan Z Li. Simvpv2: Towards simple yet powerful spatiotemporal pre- dictive learning.IEEE Transactions on Multimedia, 2025. 7, 4
work page 2025
-
[53]
Swinlstm: Improving spatiotemporal prediction accuracy using swin transformer and lstm
Song Tang, Chuang Li, Pu Zhang, and RongNian Tang. Swinlstm: Improving spatiotemporal prediction accuracy using swin transformer and lstm. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13470–13479, 2023. 1, 2, 6, 7
work page 2023
-
[54]
Vmrnn: Integrating vision mamba and lstm for efficient and accurate spatiotemporal forecasting
Yujin Tang, Peijie Dong, Zhenheng Tang, Xiaowen Chu, and Junwei Liang. Vmrnn: Integrating vision mamba and lstm for efficient and accurate spatiotemporal forecasting. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition Workshops, pages 5663–5673,
-
[55]
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lu- cas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision.Advances in Neural Information Processing Systems, 34:24261–24272,
-
[56]
Going deeper with im- age transformers
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Herv´e J´egou. Going deeper with im- age transformers. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 32–42, 2021. 5
work page 2021
-
[57]
Patches are all you need? Transactions on Machine Learning Research, 2023
Asher Trockman and J Zico Kolter. Patches are all you need? Transactions on Machine Learning Research, 2023. Fea- tured Certification. 7, 4
work page 2023
-
[58]
Maxwell H Turner, Gregory W Schwartz, and Fred Rieke. Receptive field center-surround interactions mediate context- dependent spatial contrast encoding in the retina.Elife, 7: e38841, 2018. 2
work page 2018
-
[59]
Pichao Wang, Wanqing Li, Philip Ogunbona, Jun Wan, and Sergio Escalera. Rgb-d-based human motion recognition with deep learning: A survey.Computer vision and image understanding, 171:118–139, 2018. 1
work page 2018
-
[60]
Yunbo Wang, Mingsheng Long, Jianmin Wang, Zhifeng Gao, and Philip S Yu. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms.Advances in Neural Information Processing Systems, 30, 2017. 1, 2, 6, 7, 4
work page 2017
-
[61]
Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning
Yunbo Wang, Zhifeng Gao, Mingsheng Long, Jianmin Wang, and Philip S Yu. Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning. InInternational Conference on Machine Learning, pages 5123–5132. PMLR, 2018. 2, 6, 7, 4
work page 2018
-
[62]
Eidetic 3d lstm: A model for video prediction and beyond
Yunbo Wang, Lu Jiang, Ming-Hsuan Yang, Li-Jia Li, Ming- sheng Long, and Li Fei-Fei. Eidetic 3d lstm: A model for video prediction and beyond. InInternational Conference on Learning Representations, 2018. 2, 6, 7, 4
work page 2018
-
[63]
Yunbo Wang, Jianjin Zhang, Hongyu Zhu, Mingsheng Long, Jianmin Wang, and Philip S Yu. Memory in memory: A predictive neural network for learning higher-order non- stationarity from spatiotemporal dynamics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 9154–9162, 2019. 2, 6, 7, 4
work page 2019
-
[64]
Yunbo Wang, Haixu Wu, Jianjin Zhang, Zhifeng Gao, Jian- min Wang, Philip S Yu, and Mingsheng Long. Predrnn: A recurrent neural network for spatiotemporal predictive learn- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2208–2225, 2022. 7, 4
work page 2022
-
[65]
Con- vnext v2: Co-designing and scaling convnets with masked autoencoders
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Con- vnext v2: Co-designing and scaling convnets with masked autoencoders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16133– 16142, 2023. 2, 5
work page 2023
-
[66]
Pastnet: Introducing physical inductive biases for spatio-temporal video prediction
Hao Wu, Fan Xu, Chong Chen, Xian-Sheng Hua, Xiao Luo, and Haixin Wang. Pastnet: Introducing physical inductive biases for spatio-temporal video prediction. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2917–2926, 2024. 2
work page 2024
-
[67]
Efficient and information-preserving future frame prediction and beyond
Wei Yu, Yichao Lu, Steve Easterbrook, and Sanja Fidler. Efficient and information-preserving future frame prediction and beyond. InInternational Conference on Learning Rep- resentations, 2020. 2, 6
work page 2020
-
[68]
Metaformer 11 is actually what you need for vision
Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. Metaformer 11 is actually what you need for vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10819–10829, 2022. 2, 7, 4
work page 2022
-
[69]
Deep spatio- temporal residual networks for citywide crowd flows predic- tion
Junbo Zhang, Yu Zheng, and Dekang Qi. Deep spatio- temporal residual networks for citywide crowd flows predic- tion. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1655–1661, 2017. 1, 5
work page 2017
-
[70]
Yiyuan Zhang, Xiaohan Ding, and Xiangyu Yue. Scaling up your kernels: Large kernel design in convnets towards uni- versal representations.IEEE Transactions on Pattern Analy- sis and Machine Intelligence, 2025. 2
work page 2025
-
[71]
Mmvp: Motion-matrix-based video prediction
Yiqi Zhong, Luming Liang, Ilya Zharkov, and Ulrich Neu- mann. Mmvp: Motion-matrix-based video prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4273–4283, 2023. 2, 6, 7 12 PFGNet: A Fully Convolutional Frequency-Guided Peripheral Gating Network for Efficient Spatiotemporal Predictive Learning Supplementary Material
work page 2023
-
[72]
Existence and Optimality of Ring-Shaped Pass Band In the main text, we established astrong existenceresult under monotonicity, guaranteeing a ring-shaped pass band forβ k ∈(0, β max). Here we present aweak existence theorem that aligns with PFGNet’s implementation, where β= tanh(β raw)∈(−1,1). Theorem 1(Weak Existence of Ring-Shaped Pass Band). LetH 1, H2...
-
[73]
Define the signal-to- noise ratio SNR(β) = R |Hβ(ω)|2PS(ω)dωR |Hβ(ω)|2PN(ω)dω
Let the composite filter response beH β =H L −βH S, whereH L andH S denote the frequency responses of the large and small kernels, respectively. Define the signal-to- noise ratio SNR(β) = R |Hβ(ω)|2PS(ω)dωR |Hβ(ω)|2PN(ω)dω . IfH L andH S are linearly independent inL 2([0, π])andR |HS|2PS dω >0, thenSNR(β)admits at least one finite stationary pointβ ⋆ sati...
-
[74]
Metric Definitions NotationLet the prediction and ground truth be ˆY,Y∈ RN×T×C×H×W . Dimensions:Nis the batch size,Tis the temporal length,Cis the number of channels, andH, W are the spatial sizes. An element ˆYn,t,c,h,w (orY n,t,c,h,w) is the value at batch indexn, time stept, channelc, and spatial location(h, w). Define the per-frame spatial size (inclu...
-
[75]
Figure 11 presents qualitative results of PFGNet
Additional experimental results Furthermore, we extend our evaluation to the Moving Fashion-MNIST (MFMNIST) dataset, with baseline results 3 obtained from OpenSTL [50] under identical experimental settings. Figure 11 presents qualitative results of PFGNet. As shown in Table 8, PFGNet achieves thehighest accu- racy among all recurrent-free models(MSE: 23.5...
-
[76]
Additional Ablation Studies As shown in Figure 12, we further analyze the effect of dif- ferentnsettings in the asymmetric convolution (n×k+ k×n) on the TaxiBJ dataset. The results show that varying nbrings only minor changes in performance; settingn=1 achieves nearly the same accuracy while reducing compu- 0.288 0.289 0.290 0.291 0.292 0.9850 0.9852 0.98...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.