Recognition: no theorem link
Don't Ignore the Tail: Decoupling top-K Probabilities for Efficient Language Model Distillation
Pith reviewed 2026-05-15 20:07 UTC · model grok-4.3
The pith
Decoupling the top-K probabilities from the tail in the distillation loss reduces mode dominance and boosts tail contribution in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
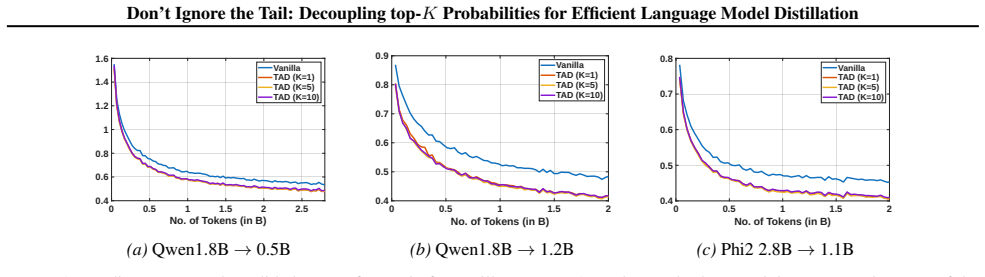
The proposed method modifies the KL divergence by decoupling the contribution of the teacher's top-K predicted probabilities from the lower-probability predictions. This reduces the impact of the teacher modes and increases the contribution of the tail of the distribution, leading to effective distillation of decoder language models in both pre-training and supervised settings at standard computational cost.
What carries the argument
The decoupled tail-aware divergence, which separates the top-K component from the tail component in the loss calculation to balance their contributions.
Load-bearing premise
Emphasizing the tail via decoupling provides a net positive learning signal without losing essential information from the high-probability modes.
What would settle it
Training two students with identical setups except for the loss (standard KL vs decoupled), and finding that the decoupled version underperforms on metrics that reward accurate tail probability estimation, such as perplexity on rare token sequences.
Figures

read the original abstract
The core learning signal used in language model distillation is the standard Kullback-Leibler (KL) divergence between the student and teacher distributions. Traditional KL divergence tends to be dominated by the next tokens with the highest probabilities, i.e., the teacher's modes, thereby diminishing the influence of less probable yet potentially informative components of the output distribution. We propose a new tail-aware divergence that decouples the contribution of the teacher model's top-K predicted probabilities from that of lower-probability predictions, while maintaining the same computational profile as the KL Divergence. Our decoupled approach reduces the impact of the teacher modes and, consequently, increases the contribution of the tail of the distribution. Experimental results demonstrate that our modified distillation method yields competitive performance in both pre-training and supervised distillation of decoder models across various datasets. Furthermore, the distillation process is efficient and can be performed with a modest academic budget for large datasets, eliminating the need for industry-scale computing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a tail-aware divergence for language model distillation that decouples the teacher model's top-K probabilities from the lower-probability tail. This modification to standard KL divergence is claimed to reduce mode dominance and increase the relative contribution of the tail while preserving the same computational profile. Experiments reportedly show competitive performance for both pre-training and supervised distillation of decoder models across datasets, achievable with modest academic compute budgets.
Significance. If the decoupling demonstrably amplifies tail gradients without discarding critical mode information, the method could offer a lightweight, parameter-light (only K) improvement to distillation that better utilizes the full teacher distribution. The efficiency claim for large datasets with academic resources is a practical strength worth verifying.
major comments (3)
- [Method] Method section (likely §3): The abstract claims the decoupled divergence 'increases the contribution of the tail' relative to KL, but without the explicit loss equation it is impossible to confirm whether top-K separation includes renormalization of the tail mass or a multiplicative reweighting; absent this, the tail probabilities remain small and their gradients may not grow, as noted in the stress-test concern.
- [Experiments] Experiments section (likely §4): The abstract reports 'competitive performance' but provides no details on baselines, statistical significance, ablation on K, or exact loss formulation; without these, the central claim that decoupling yields a net positive learning signal cannot be assessed from the given text.
- [§3.1] §3.1 or equivalent: The decoupling is presented as an independent modification to KL with no circularity, yet the weakest assumption—that emphasizing the tail provides a net positive without losing mode information—requires a concrete gradient comparison or toy example to show the tail term is effectively up-weighted.
minor comments (2)
- [Abstract] Abstract: Mention the specific datasets and model sizes used to support the 'competitive performance' claim for concreteness.
- [Method] Notation: Clarify whether K is the sole free parameter and how it is chosen across experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the manuscript would benefit from greater mathematical clarity and experimental detail. We address each major comment below and will incorporate the requested changes in the revised version.
read point-by-point responses
-
Referee: [Method] Method section (likely §3): The abstract claims the decoupled divergence 'increases the contribution of the tail' relative to KL, but without the explicit loss equation it is impossible to confirm whether top-K separation includes renormalization of the tail mass or a multiplicative reweighting; absent this, the tail probabilities remain small and their gradients may not grow, as noted in the stress-test concern.
Authors: We thank the referee for this observation. The current manuscript describes the decoupling at a high level but does not include the explicit loss equation. In the revision we will add the precise formulation in Section 3: the top-K mass is isolated, the remaining tail is renormalized to sum to one, and the loss is the sum of a standard KL term on the top-K and a scaled KL term on the renormalized tail. This renormalization directly amplifies tail gradients. We will also include a short gradient derivation and a stress-test example to confirm the effect. revision: yes
-
Referee: [Experiments] Experiments section (likely §4): The abstract reports 'competitive performance' but provides no details on baselines, statistical significance, ablation on K, or exact loss formulation; without these, the central claim that decoupling yields a net positive learning signal cannot be assessed from the given text.
Authors: We agree that the experimental section is currently underspecified. In the revised manuscript we will expand Section 4 to report: (i) the full set of baselines (standard KL, temperature-scaled KL, and other recent divergences), (ii) mean and standard deviation over three random seeds with paired t-test p-values, (iii) an ablation table varying K from 5 to 100, and (iv) the exact loss equation with implementation pseudocode. These additions will allow direct assessment of the net learning signal. revision: yes
-
Referee: [§3.1] §3.1 or equivalent: The decoupling is presented as an independent modification to KL with no circularity, yet the weakest assumption—that emphasizing the tail provides a net positive without losing mode information—requires a concrete gradient comparison or toy example to show the tail term is effectively up-weighted.
Authors: We accept this critique. The manuscript currently relies on the high-level claim without supporting derivation. In the revision we will insert a new subsection (or appendix) containing (a) a side-by-side gradient comparison between standard KL and the decoupled loss, and (b) a small-vocabulary toy example (vocabulary size 8) that numerically demonstrates higher relative gradients on tail tokens while the top-K modes remain fully represented. This will make the net-positive assumption explicit and verifiable. revision: yes
Circularity Check
No circularity: independent modification to KL with no self-referential derivation
full rationale
The paper proposes a new tail-aware divergence by decoupling top-K teacher probabilities from the tail, presented as a direct conceptual change to standard KL that preserves its computational profile. No equations, derivations, or self-citations are exhibited in the provided text that reduce the new loss to a fitted quantity defined by the same data or to a prior result by the same authors. The central claim rests on the explicit decoupling step rather than any loop back to inputs, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption The lower-probability tail of the teacher distribution contains informative components that improve student learning when emphasized.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, M., Aneja, J., Awadalla, H., Awadallah, A., Awan, A. A., Bach, N., Bahree, A., Bakhtiari, A., Bao, J., Behl, H., et al. Phi-3 technical report: A highly capable lan- guage model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Azerbayev, Z., Schoelkopf, H., Paster, K., Santos, M. D., McAleer, S., Jiang, A. Q., Deng, J., Biderman, S., and Welleck, S. Llemma: An open language model for math- ematics.arXiv preprint arXiv:2310.10631,
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Distilling the knowl- edge in a neural network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowl- edge in a neural network. InNIPS 2014 Deep Learn- ing Workshop,
work page 2014
-
[6]
Distilling the Knowledge in a Neural Network
doi: 10.48550/ARXIV .1503.02531. URLhttps://arxiv.org/abs/1503.02531. 9 Don’t Ignore the Tail: Decoupling top-KProbabilities for Efficient Language Model Distillation Iwana, B. K., Kuroki, R., and Uchida, S. Explaining con- volutional neural networks using softmax gradient layer- wise relevance propagation. In2019 IEEE/CVF Inter- national Conference on Co...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[7]
Sequence-Level Knowledge Distillation
Kim, Y . and Rush, A. M. Sequence-level knowledge distil- lation.arXiv preprint arXiv:1606.07947,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Rho-1: Not all tokens are what you need.arXiv preprint arXiv:2404.07965,
Lin, Z., Gou, Z., Gong, Y ., Liu, X., Shen, Y ., Xu, R., Lin, C., Yang, Y ., Jiao, J., Duan, N., et al. Rho-1: Not all tokens are what you need.arXiv preprint arXiv:2404.07965,
-
[10]
Liu, H., Zhang, Y ., Wang, B., Chen, W., and Hu, X. Full-ece: A metric for token-level calibration on large language models.arXiv preprint arXiv:2406.11345, 2024a. Liu, Q., Zheng, X., Muennighoff, N., Zeng, G., Dou, L., Pang, T., Jiang, J., and Lin, M. Regmix: Data mixture as regression for language model pre-training.arXiv preprint arXiv:2407.01492, 2024...
-
[11]
Orca-math: Unlocking the potential of slms in grade school math.arXiv preprint arXiv:2402.14830,
Mitra, A., Khanpour, H., Rosset, C., and Awadallah, A. Orca-math: Unlocking the potential of slms in grade school math.arXiv preprint arXiv:2402.14830,
-
[12]
T., Joshi, R., Chochowski, M., Patwary, M., Shoeybi, M., Catanzaro, B., Kautz, J., and Molchanov, P
Muralidharan, S., Sreenivas, S. T., Joshi, R., Chochowski, M., Patwary, M., Shoeybi, M., Catanzaro, B., Kautz, J., and Molchanov, P. Compact language models via pruning and knowledge distillation.arXiv preprint arXiv:2407.14679,
-
[13]
Paster, K., Santos, M. D., Azerbayev, Z., and Ba, J. Open- webmath: An open dataset of high-quality mathematical web text.arXiv preprint arXiv:2310.06786,
-
[15]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
URL http:// arxiv.org/abs/1910.01108. Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[16]
Shleifer, S. and Rush, A. M. Pre-trained summarization distillation.arXiv preprint arXiv:2010.13002,
-
[17]
Tang, Y ., Tran, C., Li, X., Chen, P.-J., Goyal, N., Chaudhary, V ., Gu, J., and Fan, A. Multilingual translation with extensible multilingual pretraining and finetuning.arXiv preprint arXiv:2008.00401,
-
[18]
Galactica: A Large Language Model for Science
Taylor, R., Kardas, M., Cucurull, G., Scialom, T., Hartshorn, A., Saravia, E., Poulton, A., Kerkez, V ., and Stojnic, R. Galactica: A large language model for science.arXiv preprint arXiv:2211.09085,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahri- ari, B., Ramé, A., et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Llama 2: Open Foundation and Fine-Tuned Chat Models
10 Don’t Ignore the Tail: Decoupling top-KProbabilities for Efficient Language Model Distillation Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
URL http://arxiv.org/ abs/1910.03771. Wu, C., Wu, F., and Huang, Y . One teacher is enough? pre- trained language model distillation from multiple teach- ers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 4408–4413,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[23]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Yu, L., Jiang, W., Shi, H., Yu, J., Liu, Z., Zhang, Y ., Kwok, J. T., Li, Z., Weller, A., and Liu, W. Metamath: Boot- strap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
TinyLlama: An Open-Source Small Language Model
Zhang, P., Zeng, G., Wang, T., and Lu, W. Tinyllama: An open-source small language model.arXiv preprint arXiv:2401.02385,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V ., et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Derivation of the Gradient Here we present an elaborated derivation of the gradients
A. Derivation of the Gradient Here we present an elaborated derivation of the gradients. The derivations follow the material in the appendix of An- shumann et al. (2025). If pi = exp(z i)/P|V| i=1 exp(zi) is the softmax probability for a logit zi for a vocabulary V, then the gradient ofp k is (from (Iwana et al., 2019)): ∂pj ∂zi =p j 1[i=j] −p i (7) Now, ...
work page 2025
-
[28]
All students have approx- imately 1B active parameters, except for the 0.5B student of Qwen, which has approximately 475M active parameters. The architectures of the students of Qwen 1.5−1.8 B are kept the same as in the MiniPLM paper (Gu et al., 2025). The experiments are divided into two major parts: pre- training distillation from scratch, and continue...
work page 2025
-
[29]
B.1. Cost of Supervised Distillation We conduct a comparative cost analysis of GPU hours re- quired to produce state-of-the-art mathematical reasoning, starting with foundational models such as TinyLlama-1.1B and Llama2-7B. Models like Llemma or Rho-1 are trained using industrial resources. Rho-1 is trained for approxi- mately 10 hours on a 32-GPU H100 st...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.