Recognition: 2 theorem links
· Lean TheoremEditFlow: Benchmarking and Optimizing Code Edit Recommendation Systems via Reconstruction of Developer Flows
Pith reviewed 2026-05-15 19:41 UTC · model grok-4.3
The pith
Code edit recommendation systems disrupt developer workflows because benchmarks use static snapshots instead of incremental editing sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EditFlow reconstructs developer editing flows from development logs to create a simulation-based benchmark that measures and improves recommendation systems on their ability to follow incremental, context-sensitive edit sequences instead of optimizing solely for final code states.
What carries the argument
Reconstruction of edit-order data from logs into digital-twin simulations that benchmark recommendation performance against developers' ongoing editing flows.
If this is right
- Models can be optimized to produce edits that respect the sequence and context of a developer's current work rather than jumping to end states.
- Benchmarks become sensitive to temporal alignment, revealing performance differences invisible to static snapshot evaluation.
- A single optimization strategy can endow systems of different scales and architectures with mental-flow awareness.
- Recommendation quality is judged by how little the suggestion interrupts the developer's next natural step.
Where Pith is reading between the lines
- The same log-reconstruction technique could be applied to non-code editing tasks such as document revision or UI design to test whether incremental-flow awareness improves assistance there as well.
- If reconstructed flows capture common reasoning patterns, they might serve as training signals for models that anticipate likely next edits before a developer types them.
- Widespread adoption would require checking whether the simulated flows remain representative when developers work in teams or on unfamiliar codebases.
Load-bearing premise
Edit-order data reflecting developers' mental flow can be reliably reconstructed from development logs without prohibitive manual annotation and that a digital-twin simulation can faithfully reproduce the editing process for benchmarking.
What would settle it
A controlled user study in which EditFlow-optimized models produce no measurable reduction in task completion time or flow disruption compared with standard models on the same tasks.
Figures



read the original abstract
Large language models (LLMs) for code editing have achieved remarkable progress, yet recent empirical studies reveal a fundamental disconnect between technical accuracy and developer productivity. Despite their strong benchmark performance, developers complete tasks 19% slower when using AI assistance, with over 68.81% of recommendations disrupting their mental flow. This misalignment stems from the use of static commit snapshots that lack temporal information, causing models to optimize for end results rather than the incremental, context-sensitive steps that align with developers' natural reasoning process. To bridge this gap, we present EditFlow, which benchmarks and optimizes subsequent code edit recommendation systems through the reconstruction of developer editing flows. EditFlow addresses three key challenges. First, collecting edit-order data that reflects developers' flow is inherently difficult: manual annotation introduces prohibitive overhead, while development logs capture only single trajectories instead of all plausible editing flows. Second, benchmarking recommendation performance against developers' ongoing editing flow requires a digital-twin-like simulation that can faithfully simulate the editing process. Third, existing heterogeneous systems vary drastically in scale and architecture, posing challenges for developing a unified optimization strategy that endows all models with mental-flow awareness regardless of design or capability. ......
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs for code editing exhibit a fundamental misalignment with developer productivity—developers complete tasks 19% slower with 68.81% of recommendations disrupting mental flow—because models are trained and evaluated on static commit snapshots that lack temporal/edit-order information and therefore optimize for end-states rather than incremental, context-sensitive steps. EditFlow is introduced as a benchmarking and optimization framework that reconstructs plausible developer editing flows from logs, builds digital-twin simulations of the editing process, and supplies a unified strategy to endow heterogeneous models with mental-flow awareness.
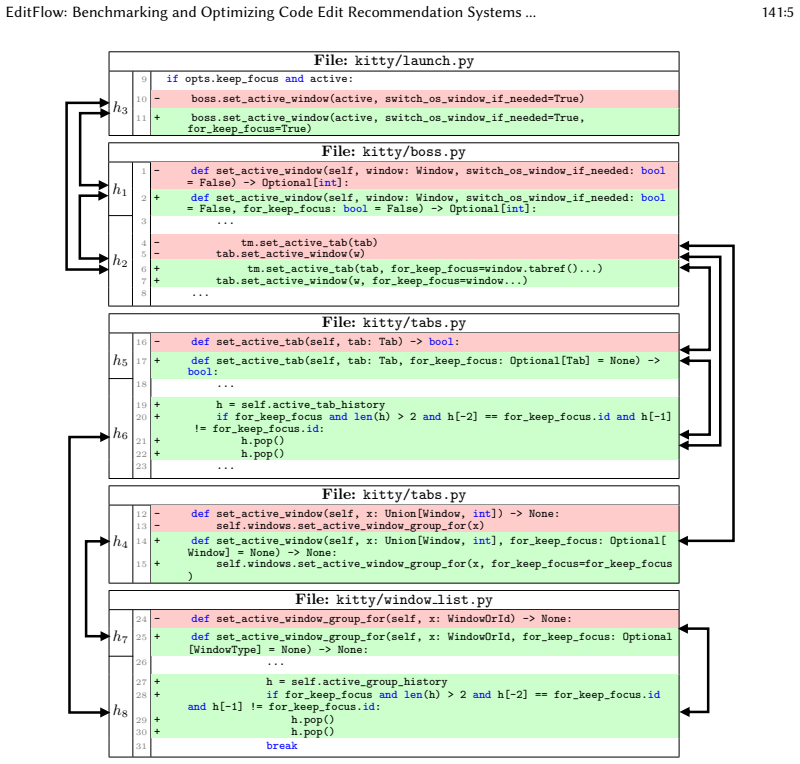
Significance. If the automated reconstruction of editing flows can be independently validated as recovering context-sensitive developer decisions rather than post-hoc rationalizations, the work would supply a more realistic evaluation paradigm for code-edit recommenders and could materially improve the practical utility of LLM-based editing tools.
major comments (2)
- [Abstract] Abstract: the central motivation rests on the reported 19% slowdown and 68.81% disruption figures, yet no source study, dataset, measurement protocol, or error analysis is supplied; without these the magnitude of the claimed misalignment cannot be assessed.
- [Abstract] Abstract (reconstruction challenge): the claim that EditFlow can reliably reconstruct edit-order data reflecting developers' mental flow from logs that capture only single trajectories is load-bearing for the entire benchmark; the manuscript provides no independent validation metric, accuracy evaluation, or comparison against manual annotations that would confirm the inferred sequences match actual context-sensitive decisions rather than artifacts of the reconstruction procedure.
minor comments (1)
- [Abstract] Abstract: the three enumerated challenges are clearly stated, but the high-level description of how the digital-twin simulation and unified optimization strategy jointly solve them would benefit from an explicit mapping sentence.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below and describe the revisions we will make to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central motivation rests on the reported 19% slowdown and 68.81% disruption figures, yet no source study, dataset, measurement protocol, or error analysis is supplied; without these the magnitude of the claimed misalignment cannot be assessed.
Authors: The referee correctly notes that the abstract does not cite the source of these statistics. The 19% slowdown and 68.81% disruption figures are taken from a prior controlled user study on developer productivity with AI code assistants (detailed in the introduction and related-work sections of the full manuscript, including the dataset and protocol). In the revised version we will add an explicit citation and a one-sentence description of the measurement protocol directly in the abstract so readers can immediately assess the magnitude of the claimed misalignment. revision: yes
-
Referee: [Abstract] Abstract (reconstruction challenge): the claim that EditFlow can reliably reconstruct edit-order data reflecting developers' mental flow from logs that capture only single trajectories is load-bearing for the entire benchmark; the manuscript provides no independent validation metric, accuracy evaluation, or comparison against manual annotations that would confirm the inferred sequences match actual context-sensitive decisions rather than artifacts of the reconstruction procedure.
Authors: We agree that an explicit, independent validation of the reconstruction procedure is necessary to support the central claim. The current manuscript describes the reconstruction algorithm in Section 3 and reports downstream consistency metrics on held-out logs, but does not include a direct comparison against manual annotations. In the revision we will add a new subsection (and corresponding abstract sentence) that presents a small-scale manual validation study: a subset of 50 editing sessions will be independently annotated by two developers, and we will report agreement metrics such as Kendall-tau correlation on edit order and precision of inferred context-sensitive steps. This will provide the requested accuracy evaluation and address the concern that the sequences may be reconstruction artifacts. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces EditFlow as a new measurement and optimization framework for code edit recommendation systems, addressing challenges in reconstructing editing flows from logs and simulating developer processes. No equations, fitted parameters, or self-citations are present that reduce any central claim (such as the misalignment from static snapshots) to a quantity defined by the paper's own inputs or prior work by construction. The approach is presented as an independent benchmarking methodology without self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Development logs capture representative editing trajectories that reflect developers' mental flow.
- domain assumption A digital-twin simulation can faithfully reproduce the incremental editing process for benchmarking purposes.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize mental flow as pairwise edit order relations... mental flow graph G=(H,E) where edges encode ≺, ≻, ∼ relations recovered by auto-tuned LLM prompt.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Digital twin replays reconstructed edit sequences... flow categories Keep/Jump/Revert/Break defined via one-hop successors in the partial-order graph.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2025. Claude Code SDK - Anthropic. https://docs.anthropic.com/en/docs/claude-code/sdk
work page 2025
-
[2]
2025. Cursor - The AI Code Editor. https://www.cursor.com/. [Accessed 2025-03-31]
work page 2025
-
[3]
2025. EditFlow — sites.google.com. https://sites.google.com/view/editflow. doi:10.5281/zenodo.19369527 [Accessed 2025-08-02]
-
[4]
2025. Windsurf Editor. https://windsurf.com/editor. [Accessed 2025-03-31]
work page 2025
-
[5]
Anthropic. 2025. Claude 3.7 Sonnet and Claude Code. https://www.anthropic.com/news/claude-3-7-sonnet. [Accessed 2025-08-31]
work page 2025
-
[6]
Anthropic. 2025. Claude Code: Deep coding at terminal velocity. https://www.anthropic.com/claude-code. [Accessed 2025-03-31]
work page 2025
-
[7]
Anthropic. 2025. Introducing Claude 3.5 Sonnet. https://www.anthropic.com/news/claude-3-5-sonnet. [Accessed 2025-08-31]
work page 2025
-
[8]
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, B Ashok, and Shashank Shet. 2024. Codeplan: Repository-level coding using llms and planning.Proceedings of the ACM on Software Engineering1, FSE (2024), 675–698. doi:10.1145/3643757
-
[9]
Joel Becker, Nate Rush, Elizabeth Barnes, and David Rein. 2025. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.arXiv preprint arXiv:2507.09089(2025). doi:10.48550/arXiv.2507.09089
-
[10]
Branden Butler, Sixing Yu, Arya Mazaheri, and Ali Jannesari. 2024. Pipeinfer: Accelerating llm inference using asynchronous pipelined speculation. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–19. doi:10.1109/SC41406.2024.00046 Proc. ACM Program. Lang., Vol. 10, No. OOPSLA1, Article 141. Publica...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41406.2024.00046 2024
-
[11]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774(2024). doi:10.48550/arXiv.2401.10774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.10774 2024
-
[12]
Yufan Cai, Zhe Hou, David Sanán, Xiaokun Luan, Yun Lin, Jun Sun, and Jin Song Dong. 2025. Automated program refinement: Guide and verify code large language model with refinement calculus.Proceedings of the ACM on Programming Languages9, POPL (2025), 2057–2089. doi:10.1145/3704905
-
[13]
Yufan Cai, Yun Lin, Chenyan Liu, Jinglian Wu, Yifan Zhang, Yiming Liu, Yeyun Gong, and Jin Song Dong. 2023. On-the-fly adapting code summarization on trainable cost-effective language models.Advances in Neural Information Processing Systems36 (2023), 56660–56672. https://dl.acm.org/doi/10.5555/3666122.3668597
-
[14]
Saikat Chakraborty, Yangruibo Ding, Miltiadis Allamanis, and Baishakhi Ray. 2022. CODIT: Code Editing With Tree- Based Neural Models.IEEE Transactions on Software Engineering48, 4 (2022), 1385–1399. doi:10.1109/TSE.2020.3020502
-
[15]
1990.Flow: The psychology of optimal experience
Mihaly Csikszentmihalyi and Mihaly Csikzentmihaly. 1990.Flow: The psychology of optimal experience. Vol. 1990. Harper & Row New York. doi:10.1080/00222216.1992.11969876
-
[16]
Cursor. 2025. Cursor CLI Overview. https://docs.cursor.com/en/cli/overview. [Accessed 2025-08-31]
work page 2025
- [17]
-
[18]
Sedick David Baker Effendi, Berk Çirisci, Rajdeep Mukherjee, Hoan Anh Nguyen, and Omer Tripp. 2023. A language- agnostic framework for mining static analysis rules from code changes. In2023 IEEE/ACM 45th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 327–339. doi:10.1109/ICSE-SEIP58684.2023. 00035
-
[19]
Mattia Fazzini, Qi Xin, and Alessandro Orso. 2019. Automated API-usage update for Android apps. InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis. 204–215. doi:10.1145/3339066
-
[20]
Nicole Forsgren, Margaret-Anne Storey, Chandra Maddila, Thomas Zimmermann, Brian Houck, and Jenna Butler. 2021. The SPACE of Developer Productivity: There’s more to it than you think.Queue19, 1 (2021), 20–48. doi:10.1145/3453928
-
[21]
getsentry/sentry. 2025. Ensure releases can be used when scraping is disabled. https://github.com/getsentry/sentry/ commit/de2de4a9da751041baa329be551ee4e0b12021d9. [Accessed 2025-08-31]
work page 2025
-
[22]
GitHub. 2023. GitHub Copilot. https://github.com/features/copilot [Accessed 2025-08-31]
work page 2023
-
[23]
Google. 2025. google-gemini/gemini-cli: An open-source AI agent that brings the power of Gemini directly into your terminal. https://github.com/google-gemini/gemini-cli. [Accessed 2025-03-31]
work page 2025
-
[24]
Priyanshu Gupta, Avishree Khare, Yasharth Bajpai, Saikat Chakraborty, Sumit Gulwani, Aditya Kanade, Arjun Rad- hakrishna, Gustavo Soares, and Ashish Tiwari. 2023. Grace: Language Models Meet Code Edits. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023). Ass...
-
[25]
Zhen Huang, Zengzhi Wang, Shijie Xia, and Pengfei Liu. 2024. OlympicArena Medal Ranks: Who Is the Most Intelligent AI So Far? arXiv:2406.16772 [cs.CL] doi:10.48550/arXiv.2406.16772
-
[26]
Maliheh Izadi, Jonathan Katzy, Tim Van Dam, Marc Otten, Razvan Mihai Popescu, and Arie Van Deursen. 2024. Language models for code completion: A practical evaluation. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13. doi:10.1145/3597503.3639138
-
[27]
Sabine Janssens and Vadim Zaytsev. 2022. Go with the flow: software engineers and distractions. InProceedings of the 25th International Conference on Model Driven Engineering Languages and Systems: Companion Proceedings. 934–938. doi:10.1145/3550356.3559101
-
[28]
Eirini Kalliamvakou and GitHub Staff. 2025. Yes, good DevEx increases productivity. Here is the data. https://github. blog/news-insights/research/good-devex-increases-productivity/. [Accessed 2025-12-31]
work page 2025
-
[29]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines.The Twelfth International Conference on Learning Representa...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.03714 2024
-
[30]
kovidgoyal/kitty. 2025. When using –keep-focus ensure active history list is not affected. https://github.com/kovidgoyal/ kitty/commit/c4c62c15. [Accessed 2025-08-31]
work page 2025
-
[31]
Jia Li, Ge Li, Zhuo Li, Zhi Jin, Xing Hu, Kechi Zhang, and Zhiyi Fu. 2023. Codeeditor: Learning to edit source code with pre-trained models.ACM Transactions on Software Engineering and Methodology32, 6 (2023), 1–22. doi:10.1145/3597207
-
[32]
Bo Lin, Shangwen Wang, Zhongxin Liu, Yepang Liu, Xin Xia, and Xiaoguang Mao. 2023. CCT5: A Code-Change- Oriented Pre-Trained Model.arXiv preprint arXiv:2305.10785(2023). doi:10.1145/3611643.3616339
-
[33]
Yun Lin, You Sheng Ong, Jun Sun, Gordon Fraser, and Jin Song Dong. 2021. Graph-based seed object synthesis for search-based unit testing. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1068–1080. doi:10.1145/3468264.3468619 Proc. ACM Program. Lang., Vol. 10,...
-
[34]
Yun Lin, Xin Peng, Zhenchang Xing, Diwen Zheng, and Wenyun Zhao. 2015. Clone-based and interactive recommen- dation for modifying pasted code. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. 520–531. doi:10.1145/2786805.2786871
-
[35]
Yun Lin, Jun Sun, Gordon Fraser, Ziheng Xiu, Ting Liu, and Jin Song Dong. 2020. Recovering fitness gradients for interprocedural Boolean flags in search-based testing. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. 440–451. doi:10.1145/3395363.3397358
-
[36]
Chenyan Liu, Yufan Cai, Yun Lin, Yuhuan Huang, Yunrui Pei, Bo Jiang, Ping Yang, Jin Song Dong, and Hong Mei. 2024. CoEdPilot: Recommending Code Edits with Learned Prior Edit Relevance, Project-wise Awareness, and Interactive Nature. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024)....
-
[37]
Changshu Liu, Pelin Cetin, Yogesh Patodia, Baishakhi Ray, Saikat Chakraborty, and Yangruibo Ding. 2024. Automated code editing with search-generate-modify. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings. 398–399. doi:10.1145/3639478.3643124
-
[38]
Chenyan Liu, Yun Lin, Yuhuan Huang, Jiaxin Chang, Binhang Qi, Bo Jiang, Zhiyong Huang, and Jin Song Dong. 2025. Learning Project-wise Subsequent Code Edits via Interleaving Neural-based Induction and Tool-based Deduction. In 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 1377–1389. doi:10.1109/ ASE63991.2025.00117
-
[39]
Ruofan Liu, Xiwen Teoh, Yun Lin, Guanjie Chen, Ruofei Ren, Denys Poshyvanyk, and Jin Song Dong. 2025. GUIPilot: A Consistency-Based Mobile GUI Testing Approach for Detecting Application-Specific Bugs.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 753–776. doi:10.1145/3728909
-
[40]
Gloria Mark, Daniela Gudith, and Ulrich Klocke. 2008. The cost of interrupted work: more speed and stress. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems. 107–110. doi:10.1145/1357054.1357072
-
[41]
Mykola Maslych, Mohammadreza Katebi, Christopher Lee, Yahya Hmaiti, Amirpouya Ghasemaghaei, Christian Pumarada, Janneese Palmer, Esteban Segarra Martinez, Marco Emporio, Warren Snipes, et al. 2025. Mitigating response delays in free-form conversations with LLM-powered intelligent virtual agents. InProceedings of the 7th ACM Conference on Conversational Us...
-
[42]
André N Meyer, Thomas Fritz, Gail C Murphy, and Thomas Zimmermann. 2014. Software developers’ perceptions of productivity. InProceedings of the 22nd ACM SIGSOFT international symposium on foundations of software engineering. 19–29. doi:10.1145/2635868.2635892
-
[43]
Amr Mohamed, Maram Assi, and Mariam Guizani. 2025. The impact of LLM-assistants on software developer productivity: A systematic literature review.arXiv preprint arXiv:2507.03156(2025). doi:10.48550/arXiv.2507.03156
-
[44]
Abi Noda, Margaret-Anne Storey, Nicole Forsgren, and Michaela Greiler. 2023. DevEX: What actually drives productiv- ity?Commun. ACM66, 11 (2023), 44–49. doi:10.1145/3610285
-
[45]
OpenAI. 2025. OpenAI o1-mini | OpenAI. https://openai.com/index/openai-o1-mini-advancing-cost-efficient- reasoning. [Accessed 2025-03-31]
work page 2025
-
[46]
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khat- tab. 2024. Optimizing instructions and demonstrations for multi-stage language model programs.arXiv preprint arXiv:2406.11695(2024). doi:10.48550/arXiv.2406.11695
-
[47]
Veronica Pimenova, Sarah Fakhoury, Christian Bird, Margaret-Anne Storey, and Madeline Endres. 2025. Good Vibrations? A Qualitative Study of Co-Creation, Communication, Flow, and Trust in Vibe Coding.arXiv preprint arXiv:2509.12491(2025). doi:10.48550/arXiv.2509.12491
-
[48]
It’s weird that it knows what i want
James Prather, Brent N Reeves, Paul Denny, Brett A Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. “It’s weird that it knows what i want”: Usability and interactions with copilot for novice programmers.ACM transactions on computer-human interaction31, 1 (2023), 1–31. doi:10.1145/3617367
-
[49]
Binhang Qi, Yun Lin, Xinyi Weng, Yuhuan Huang, Chenyan Liu, Hailong Sun, and Jin Song Dong. 2025. Intention-Driven Generation of Project-Specific Test Cases.arXiv preprint arXiv:2507.20619(2025). doi:10.48550/arXiv.2507.20619
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.20619 2025
-
[50]
Qwen. 2025. Qwen3-Coder: Agentic Coding in the World. https://qwenlm.github.io/blog/qwen3-coder/. [Accessed 2025-03-31]
work page 2025
-
[51]
Baishakhi Ray, Daryl Posnett, Vladimir Filkov, and Premkumar Devanbu. 2014. A large scale study of programming languages and code quality in github. InProceedings of the 22nd ACM SIGSOFT international symposium on foundations of software engineering. 155–165. doi:10.1145/3126905
-
[52]
Xiaoxue Ren, Xinyuan Ye, Yun Lin, Zhenchang Xing, Shuqing Li, and Michael R Lyu. 2023. API-knowledge aware search-based software testing: where, what, and how. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1320–1332. doi:10.1145/3611643.3616269
-
[53]
AttributeError: ’NoneType’ object has no attribute ’isdigit’
sqlmapproject/sqlmap. 2025. fix for a bug reported by ToR: "AttributeError: ’NoneType’ object has no attribute ’isdigit’". https://github.com/sqlmapproject/sqlmap/commit/2cc167a42eb18030536107803dfbca6a71694f65. [Accessed 2025-08-31]. Proc. ACM Program. Lang., Vol. 10, No. OOPSLA1, Article 141. Publication date: April 2026. 141:28 C. Liu, Y. Lin, J. Chang...
work page 2025
-
[54]
John Sum and Kevin Ho. 2015. Analysis on the Effect of Multitasking. In2015 IEEE international conference on systems, man, and cybernetics. IEEE, 204–209. doi:10.1109/SMC.2015.48
-
[55]
Zhuofan Wen, Shangtong Gui, and Yang Feng. 2024. Speculative decoding with CTC-based draft model for LLM inference acceleration.Advances in Neural Information Processing Systems37 (2024), 92082–92100. doi:10.48550/arXiv. 2412.00061
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[56]
Jiyang Zhang, Pengyu Nie, Junyi Jessy Li, and Milos Gligoric. 2023. Multilingual code co-evolution using large language models. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 695–707. doi:10.1145/3611643.3616350
-
[57]
Jiyang Zhang, Sheena Panthaplackel, Pengyu Nie, Junyi Jessy Li, and Milos Gligoric. 2022. CoditT5: Pretraining for Source Code and Natural Language Editing. InInternational Conference on Automated Software Engineering. doi:10.48550/arXiv.2208.05446
-
[58]
Yuhao Zhang, Yasharth Bajpai, Priyanshu Gupta, Ameya Ketkar, Miltiadis Allamanis, Titus Barik, Sumit Gulwani, Arjun Radhakrishna, Mohammad Raza, Gustavo Soares, and Ashish Tiwari. 2022. Overwatch: Learning Patterns in Code Edit Sequences.Proc. ACM Program. Lang.6, OOPSLA2, Article 139 (oct 2022), 29 pages. doi:10.1145/3563302
-
[59]
Qihao Zhu, Zeyu Sun, Yuan-an Xiao, Wenjie Zhang, Kang Yuan, Yingfei Xiong, and Lu Zhang. 2021. A Syntax-Guided Edit Decoder for Neural Program Repair. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Athens, Greece)(ESEC/FSE 2021). Association for Computing Mac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.