Recognition: 2 theorem links
· Lean TheoremMEDSYN: Benchmarking Multi-EviDence SYNthesis in Complex Clinical Cases for Multimodal Large Language Models
Pith reviewed 2026-05-15 19:33 UTC · model grok-4.3
The pith
Multimodal models match clinicians on differential diagnosis lists but show much larger gaps when selecting the final diagnosis from mixed evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MEDSYN reveals that while top MLLMs often match or surpass expert clinicians in generating differential diagnoses from complex multimodal cases, they display a substantially larger gap between differential and final diagnosis performance, highlighting a failure in synthesizing heterogeneous clinical evidence types such as medical history, lab results, and imaging.
What carries the argument
MEDSYN benchmark paired with the Evidence Sensitivity metric, which measures how effectively models use varying clinical evidence types to reach a final diagnosis.
If this is right
- Models overrely on less discriminative textual evidence such as medical history rather than visual or lab data.
- A measurable cross-modal utilization gap exists in how MLLMs handle different evidence types.
- Evidence Sensitivity scores directly correlate with higher final diagnostic accuracy.
- Targeted interventions guided by Evidence Sensitivity measurements can raise model performance on complex cases.
Where Pith is reading between the lines
- Clinical deployment of these models would benefit from extra safeguards on cases that combine many evidence types.
- Training methods that explicitly reward cross-modal evidence integration could close the observed gap.
- Extending the benchmark to live hospital data streams would test whether the identified failure mode persists outside curated cases.
Load-bearing premise
The selected complex clinical cases accurately reflect real-world diagnostic difficulty and the DDx and FDx metrics allow a fair comparison between models and human experts.
What would settle it
Re-running the same DDx-to-FDx evaluation on an independent set of real patient cases collected from clinical practice and checking whether the performance gap between models and clinicians shrinks or disappears.
Figures







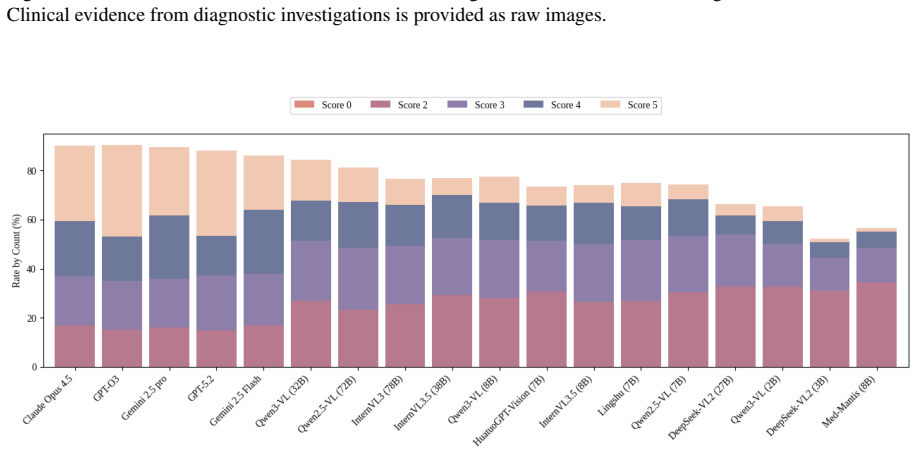
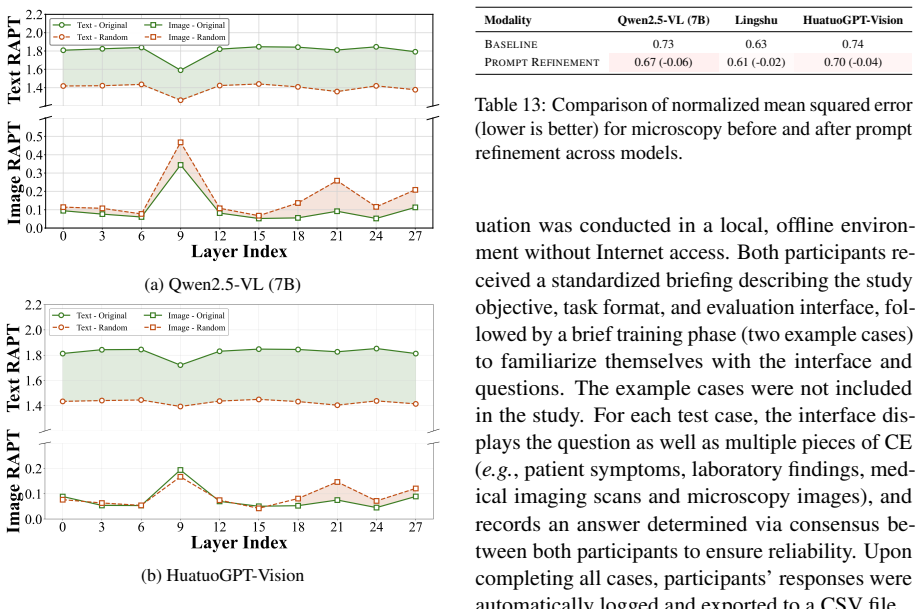




read the original abstract
Multimodal large language models (MLLMs) have shown great potential in medical applications, yet existing benchmarks inadequately capture real-world clinical complexity. We introduce MEDSYN, a multilingual, multimodal benchmark of highly complex clinical cases with up to 7 distinct visual clinical evidence (CE) types per case. Mirroring clinical workflow, we evaluate 18 MLLMs on differential diagnosis (DDx) generation and final diagnosis (FDx) selection. While top models often match or even outperform human experts on DDx generation, all MLLMs exhibit a much larger DDx--FDx performance gap compared to expert clinicians, indicating a failure mode in synthesis of heterogeneous CE types. Ablations attribute this failure to (i) overreliance on less discriminative textual CE ($\it{e.g.}$, medical history) and (ii) a cross-modal CE utilization gap. We introduce Evidence Sensitivity to quantify the latter and show that a smaller gap correlates with higher diagnostic accuracy. Finally, we demonstrate how it can be used to guide interventions to improve model performance. We will open-source our benchmark and code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MEDSYN, a multilingual multimodal benchmark of complex clinical cases featuring up to 7 distinct visual clinical evidence (CE) types. It evaluates 18 MLLMs on differential diagnosis (DDx) generation and final diagnosis (FDx) selection, reporting that top models match or exceed expert clinicians on DDx but exhibit a substantially larger DDx-FDx performance gap. This gap is attributed to overreliance on less discriminative textual CE and a cross-modal CE utilization gap; the authors introduce an Evidence Sensitivity metric to quantify the latter, show its correlation with accuracy, and demonstrate its use for guiding interventions. The benchmark and code are to be open-sourced.
Significance. If the central empirical claims are robustly supported with complete protocol details, the work would usefully identify a specific synthesis limitation in MLLMs for heterogeneous clinical evidence, providing both diagnostic insight and a practical metric (Evidence Sensitivity) that could guide targeted model improvements in medical AI.
major comments (2)
- [Abstract] Abstract: the central claim that all MLLMs show a much larger DDx-FDx gap than expert clinicians (indicating synthesis failure) is load-bearing, yet the abstract supplies no information on case selection criteria, sample size, inter-annotator agreement, statistical testing, or the precise human baseline protocol (prompting, time limits, output constraints, or CE presentation format). Without these, the gap cannot be confidently attributed to cross-modal synthesis deficits rather than mismatched evaluation conditions.
- [Abstract] Abstract: the ablations on textual overreliance and Evidence Sensitivity are performed only on models and therefore do not address whether the DDx-FDx comparison to clinicians was conducted under equivalent task framing; this leaves the headline attribution to 'failure mode in synthesis of heterogeneous CE types' under-supported.
minor comments (2)
- The definition and exact computation of the new Evidence Sensitivity metric should be stated explicitly in the main text (not only in supplementary material) so readers can reproduce the correlation with diagnostic accuracy.
- The abstract states the benchmark is multilingual; the languages involved and any translation or localization procedures should be summarized for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional protocol details will strengthen the presentation of our central claims and will revise the abstract to summarize key elements from the full manuscript. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that all MLLMs show a much larger DDx-FDx gap than expert clinicians (indicating synthesis failure) is load-bearing, yet the abstract supplies no information on case selection criteria, sample size, inter-annotator agreement, statistical testing, or the precise human baseline protocol (prompting, time limits, output constraints, or CE presentation format). Without these, the gap cannot be confidently attributed to cross-modal synthesis deficits rather than mismatched evaluation conditions.
Authors: We agree the abstract should be expanded for completeness. We will revise it to include brief summaries of: case selection criteria (complex real-world cases with up to 7 visual CE types, detailed in Section 3.1), sample size, inter-annotator agreement for expert labels, statistical testing of the DDx-FDx gap difference, and the human baseline protocol (identical CE presentation format, time limits, output constraints, and workflow as used for models). These elements are already reported in the full manuscript (Sections 3 and 4); adding them to the abstract will directly address the concern about attribution. revision: yes
-
Referee: [Abstract] Abstract: the ablations on textual overreliance and Evidence Sensitivity are performed only on models and therefore do not address whether the DDx-FDx comparison to clinicians was conducted under equivalent task framing; this leaves the headline attribution to 'failure mode in synthesis of heterogeneous CE types' under-supported.
Authors: The ablations are intentionally model-focused to diagnose the source of the observed gap in MLLMs. The clinician comparison was performed under equivalent task framing: the same cases, the same multimodal CE types presented in identical format (text plus visuals), the same workflow (DDx list generation followed by FDx selection), and the same output constraints. We will revise the abstract to explicitly note this equivalence of task framing between models and clinicians, thereby supporting the attribution of the larger model gap to synthesis limitations. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements
full rationale
The paper is a pure empirical benchmark study that introduces MEDSYN cases and reports measured DDx/FDx performance gaps for 18 MLLMs versus clinicians. No derivations, equations, fitted parameters, or predictions are claimed; all results are direct evaluations on held-out complex cases. Ablations on textual overreliance and Evidence Sensitivity are internal model probes that do not reduce to self-definition or self-citation chains. The central claim (larger DDx-FDx gap in models) is an observed difference, not a quantity forced by construction from the input data or prior self-work. This is the standard non-circular outcome for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The constructed clinical cases with up to seven visual evidence types mirror real-world diagnostic complexity and workflow
invented entities (1)
-
Evidence Sensitivity
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce MEDSYN, a multilingual, multimodal benchmark of highly complex clinical cases with up to 7 distinct visual clinical evidence (CE) types per case... We introduce Evidence Sensitivity to quantify the latter...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ablations attribute this failure to (i) overreliance on less discriminative textual CE... and (ii) a cross-modal CE utilization gap.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vqa-med: Overview of the medical visual question answering task at imageclef 2019.(No Ti- tle). Anthropic. 2025. Introducing claude 4. Anthropic News. James Burgess, Jeffrey J Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, and 1 others. 2025. Mi- crovqa: A m...
-
[2]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Words or vision: Do vision-language models have blind faith in text? InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 3867–3876. Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, and 1 others. 2024. A survey on in-context learning. InProceedings of the 2024 co...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
IEEE. Zhining Liu, Ziyi Chen, Hui Liu, Chen Luo, Xianfeng Tang, Suhang Wang, Joy Zeng, Zhenwei Dai, Zhan Shi, Tianxin Wei, and 1 others. 2025. Seeing but not believing: Probing the disconnect between vi- sual attention and answer correctness in vlms.arXiv preprint arXiv:2510.17771. Ilya Loshchilov and Frank Hutter. 2017. Decou- pled weight decay regulariz...
-
[4]
Quilt-llava: Visual instruction tuning by extracting localized narratives from open-source histopathology videos.Preprint, arXiv:2312.04746. Dong Shu, Haiyan Zhao, Jingyu Hu, Weiru Liu, Ali Payani, Lu Cheng, and Mengnan Du. 2025. Large vision-language model alignment and misalignment: A survey through the lens of explainability.arXiv preprint arXiv:2501.0...
-
[5]
Parse Caption -> split per figure, identify modality cues, extract verbatim chunks with figure source tags
-
[6]
Parse Background -> extract non-imaging (background, labs, meds) and any labeled impression/differential; add imaging only if needed
- [7]
-
[8]
{modality_or_section_name} Findings
Aggregate chunks per key with \n\n and return JSON only. Here are some examples: ... The prompt for summarizing individual expert interpretations: You are an expert medical summarization assistant. Task Given ONE case, produce concise summaries while preserving the case ID, modality list, medications, and diagnosis information if present. Use ONLY the pro...
-
[9]
- ALL distractors MUST be drawn from the differential list
Distractor constraints (must all be true) - Output EXACTLY three distractors. - ALL distractors MUST be drawn from the differential list. (You may normalize wording but must not change the underlying diagnosis.) - Each distractor must be a real, recognized diagnosis. - Each distractor must be genuinely plausible for THIS patient given the provided history...
-
[10]
Make distractors confusing - Prefer distractors in the same organ system or a closely related one. - Prefer distractors that share major features with the ground truth (symptoms, labs, imaging, histology). - Each distractor should differ from the ground truth by subtle details (e.g., anatomic site, vascular territory, mechanism, histologic variant), such ...
-
[11]
shape": same head noun/pattern when possible (e.g., all
Remove lexical giveaways - Keep ground truth and distractors similar in "shape": same head noun/pattern when possible (e.g., all "... adenocarcinoma", all "... ischemic stroke", all "... cardiomyopathy"). - Keep length and syntactic structure similar across the four options. - Do not let only one option contain a uniquely specific keyword unless the other...
work page 2025
-
[13]
Scoring rules 5: The actual diagnosis appears explicitly in the differential
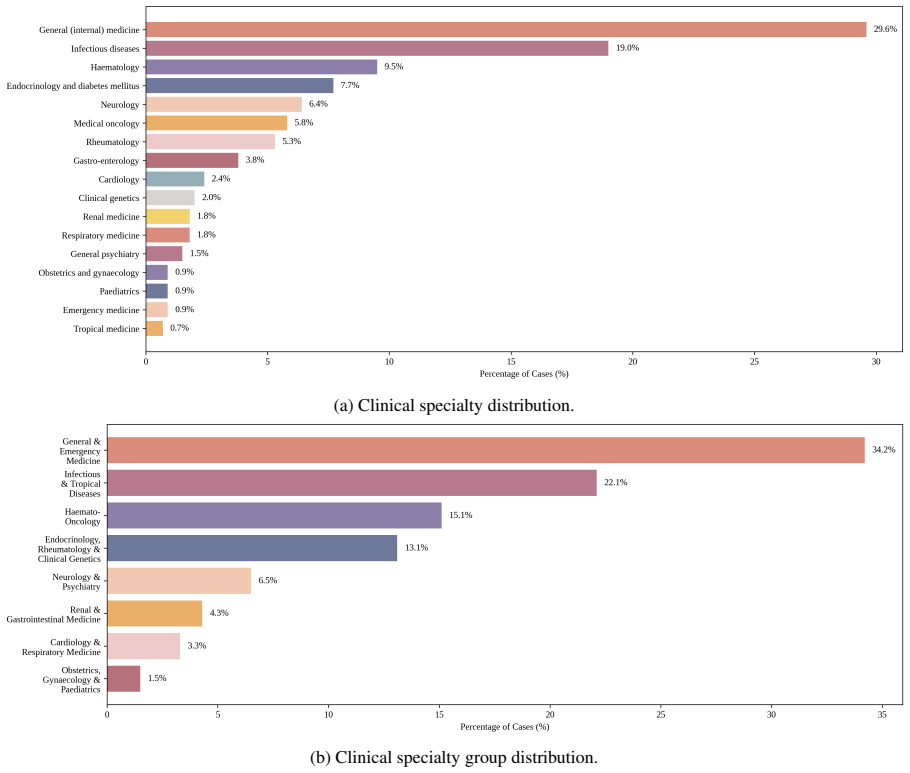
Differential diagnoses: {differential list} Task Using medical knowledge, compare the differential diagnoses with the final diagnosis and assign a quality score on a 0--5 scale. Scoring rules 5: The actual diagnosis appears explicitly in the differential. 4: A very close diagnosis is suggested (near-miss, closely adjacent). (a) Clinical specialty distribu...
-
[14]
Final confirmed diagnosis: {ground_truth}
-
[15]
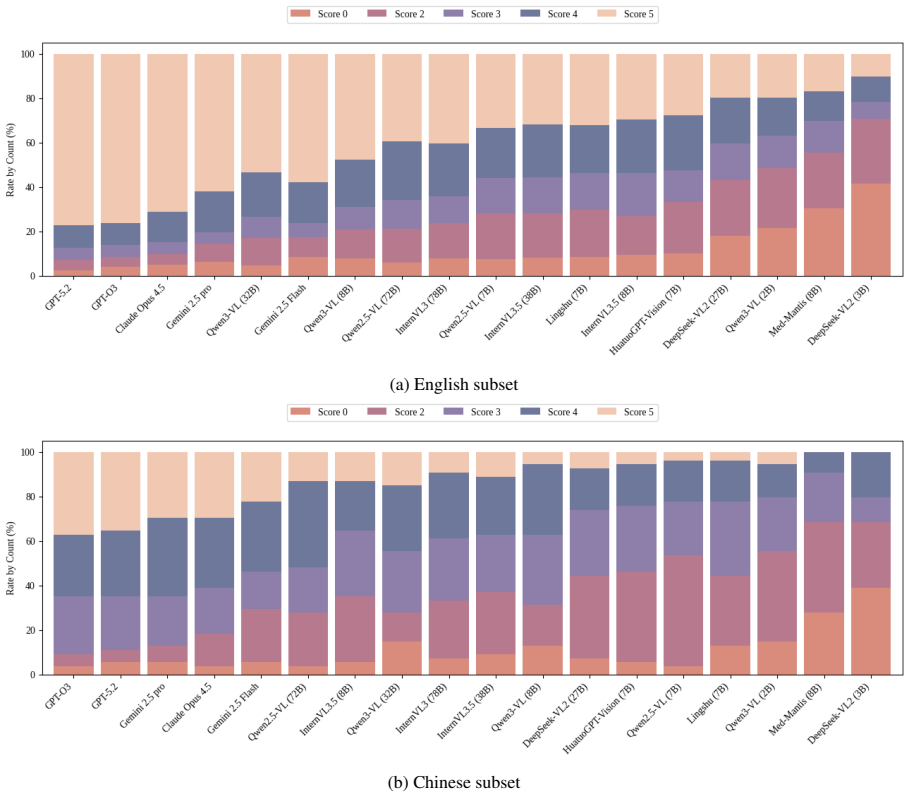
Generated diagnosis: {diagnosis} Task Using medical knowledge, compare the generated diagnoses with the final confirmed diagnosis and assign a quality score on a 0--5 scale. Scoring rules: 5: Exact match to the final diagnosis. 4: Very close diagnosis but not exact. 3: Closely related and plausibly helpful for reaching the final diagnosis (same disease fa...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.