Recognition: no theorem link
When to Act, Ask, or Learn: Uncertainty-Aware Policy Steering
Pith reviewed 2026-05-15 18:57 UTC · model grok-4.3
The pith
A robot policy can decide to act, query for clarification, or request human intervention by calibrating its uncertainty estimates with conformal prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
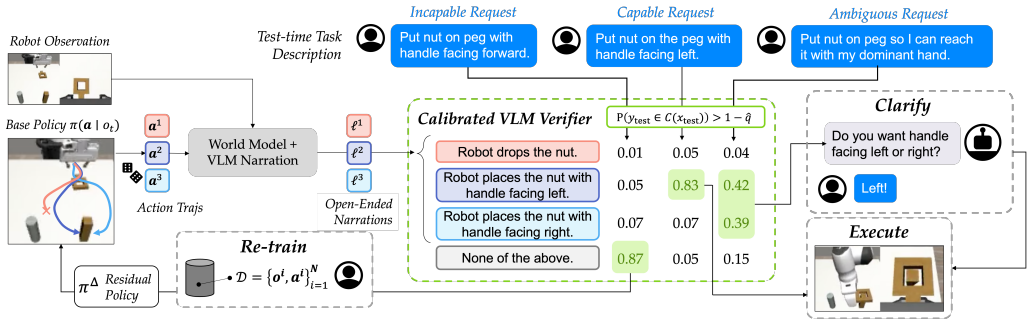
Uncertainty-aware policy steering (UPS) jointly reasons about semantic task uncertainty and low-level action feasibility, selecting an uncertainty resolution strategy of execute, query via natural language, or intervene, with conformal prediction calibrating the VLM verifier and pre-trained policy composition to provide statistical assurances on correct selection, followed by residual learning from interventions for continual improvement with minimal human feedback.
What carries the argument
Uncertainty-aware policy steering (UPS), which composes a VLM verifier with a pre-trained base policy and applies conformal prediction to their joint outputs to select among execute, query, or intervene strategies.
Load-bearing premise
Conformal prediction applied to the composition of the VLM verifier and pre-trained policy produces valid statistical guarantees for strategy selection in real robotic deployment.
What would settle it
In hardware or simulation trials, the observed rate of incorrect strategy selections (execute when ambiguous, query when capable, or intervene when capable) exceeds the error bound guaranteed by the conformal prediction calibration.
Figures























read the original abstract
Policy steering is an emerging way to adapt robot behaviors at deployment-time: a learned verifier analyzes low-level action samples proposed by a pre-trained policy (e.g., diffusion policy) and selects only those aligned with the task. While Vision-Language Models (VLMs) are promising general-purpose verifiers due to their reasoning capabilities, existing frameworks often assume these models are well-calibrated. In practice, the overconfident judgment from VLM can degrade the steering performance under both high-level semantic uncertainty in task specifications and low-level action uncertainty or incapability of the pre-trained policy. We propose uncertainty-aware policy steering (UPS), a framework that jointly reasons about semantic task uncertainty and low-level action feasibility, and selects an uncertainty resolution strategy: execute a high-confidence action, clarify task ambiguity via natural language queries, or ask for action interventions to correct the low-level policy when it is deemed incapable at the task. We leverage conformal prediction to calibrate the composition of the VLM and the pre-trained base policy, providing statistical assurances that the verifier selects the correct strategy. After collecting interventions during deployment, we employ residual learning to improve the capability of the pre-trained policy, enabling the system to learn continually but with minimal expensive human feedback. We demonstrate our framework through experiments in simulation and on hardware, showing that UPS can disentangle confident, ambiguous, and incapable scenarios and minimizes expensive user interventions compared to uncalibrated baselines and prior human- or robot-gated continual learning approaches. Videos can be found at https://jessie-yuan.github.io/ups/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Uncertainty-Aware Policy Steering (UPS), a framework that combines a VLM-based verifier with conformal prediction to jointly handle semantic task uncertainty and low-level action feasibility in pre-trained robot policies. The verifier selects among three strategies—execute a high-confidence action, issue a natural-language clarification query, or request a human intervention for residual learning—while claiming statistical coverage guarantees on correct strategy selection. After interventions, residual learning updates the base policy for continual improvement with limited human feedback. Validation is provided via simulation and hardware experiments showing reduced interventions relative to uncalibrated and prior gated baselines.
Significance. If the coverage guarantees remain valid, the work offers a principled mechanism for safe deployment-time adaptation of diffusion-style policies under both high-level ambiguity and low-level incapability, reducing expensive human oversight. The explicit use of conformal prediction on the VLM-policy composition and the integration of residual learning constitute concrete technical contributions that could support more reliable continual-learning robot systems.
major comments (2)
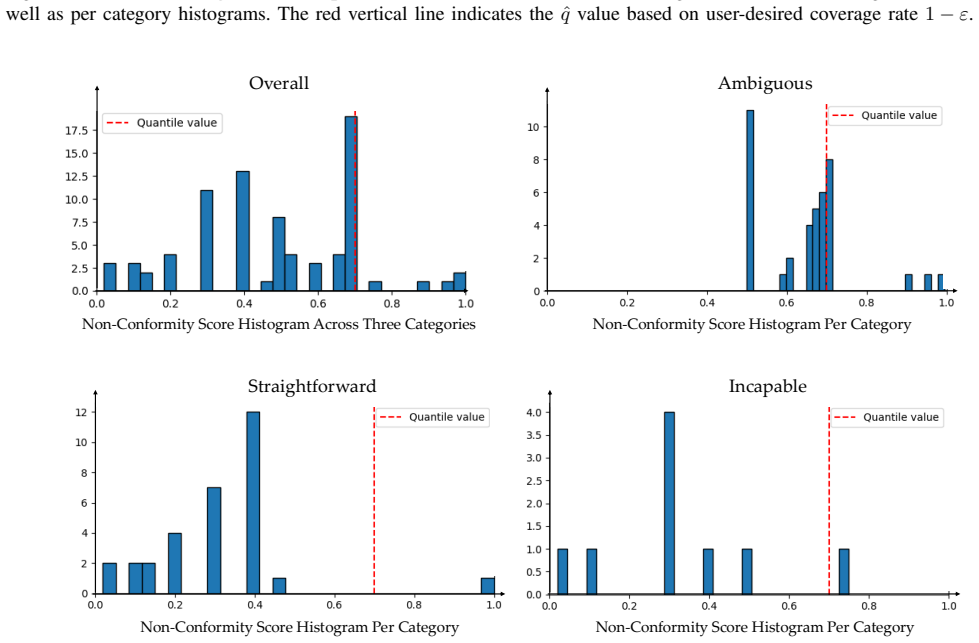
- [§4.2] §4.2 (Conformal Calibration): The calibration procedure is performed once on the initial pre-trained policy distribution. Residual learning then updates the policy from collected interventions, altering the joint (VLM, policy) output distribution and violating the exchangeability assumption required for marginal coverage guarantees on strategy selection. No re-calibration step or non-stationary conformal variant is described.
- [§5.1] §5.1 (Experimental Results): The reported success rates, intervention counts, and comparison tables lack per-condition standard deviations, trial counts, or statistical significance tests. Without these, it is impossible to determine whether the claimed reductions in user interventions are reliable or merely consistent with noise.
minor comments (2)
- [Abstract] Abstract: The claim of 'statistical assurances' should explicitly state the target coverage level (e.g., 1−α = 0.9) and the precise definition of the nonconformity score used for the three-way decision.
- [Figure 2] Figure 2: The pipeline diagram would be clearer if the conformal threshold computation and the residual-learning update loop were shown as separate sub-panels with explicit arrows indicating when re-calibration would (or would not) occur.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the conformal calibration procedure and the experimental reporting. We address each major comment point by point below and outline the revisions planned for the next manuscript version.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Conformal Calibration): The calibration procedure is performed once on the initial pre-trained policy distribution. Residual learning then updates the policy from collected interventions, altering the joint (VLM, policy) output distribution and violating the exchangeability assumption required for marginal coverage guarantees on strategy selection. No re-calibration step or non-stationary conformal variant is described.
Authors: We agree that residual learning from interventions induces a distribution shift that can violate the exchangeability assumption underlying the initial conformal calibration. The coverage guarantees therefore apply strictly to the pre-trained policy at calibration time. To strengthen the framework for continual deployment, we will revise §4.2 to explicitly discuss this limitation and introduce a periodic re-calibration step that re-computes conformal thresholds on batches of collected intervention data. This addition will be described in an updated §4.2 and §4.3, preserving the minimal-feedback goal while restoring marginal coverage guarantees after policy updates. revision: yes
-
Referee: [§5.1] §5.1 (Experimental Results): The reported success rates, intervention counts, and comparison tables lack per-condition standard deviations, trial counts, or statistical significance tests. Without these, it is impossible to determine whether the claimed reductions in user interventions are reliable or merely consistent with noise.
Authors: We concur that the current experimental presentation would be strengthened by rigorous statistical reporting. In the revised manuscript we will add the number of trials per condition, per-condition standard deviations for all metrics (success rate, intervention count, query count), and results of appropriate statistical tests (e.g., paired t-tests with p-values) comparing UPS against the baselines. These details will be incorporated into §5.1, the tables, and the figure captions. revision: yes
Circularity Check
No circularity; framework applies established conformal prediction and residual learning without self-referential reduction
full rationale
The derivation chain in the paper applies conformal prediction to calibrate the joint VLM and pre-trained policy outputs for strategy selection (act/ask/learn), then uses residual learning on collected interventions to update the base policy. These steps rely on standard properties of conformal prediction (marginal coverage under exchangeability) and residual learning techniques from the literature, without defining the statistical assurances or strategy selection as equivalent to the fitted inputs by construction. No equations reduce the central claim to a self-definition, no predictions are statistically forced from a subset fit, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The framework remains self-contained against external benchmarks for calibration and continual improvement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conformal prediction provides valid statistical guarantees when applied to the composition of VLM verifier outputs and pre-trained policy feasibility.
Reference graph
Works this paper leans on
-
[1]
Let’s think in two steps: Mitigating agreement bias in mllms with self- grounded verification
Moises Andrade, Joonhyuk Cha, Brandon Ho, Vriksha Srihari, Karmesh Yadav, and Zsolt Kira. Let’s think in two steps: Mitigating agreement bias in mllms with self- grounded verification. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[2]
Anastasios N Angelopoulos, Stephen Bates, et al. Con- formal prediction: A gentle introduction.Foundations and trends® in machine learning, 16(4):494–591, 2023
work page 2023
-
[3]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Goal inference as inverse planning
Chris L Baker, Joshua B Tenenbaum, and Rebecca R Saxe. Goal inference as inverse planning. InProceedings of the annual meeting of the cognitive science society, volume 29, 2007
work page 2007
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0 : A vision- language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
work page 2024
-
[7]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Maria Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of The 33rd Interna- tional Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 1050– 1059, New York, New York, USA, 20–22 Jun ...
work page 2016
-
[8]
Mastering diverse domains through world models.Nature, 2023
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timo- thy Lillicrap. Mastering diverse domains through world models.Nature, 2023
work page 2023
-
[9]
Thriftydagger: Budget-aware novelty and risk gating for interactive imitation learning
Ryan Hoque, Ashwin Balakrishna, Ellen Novoseller, Albert Wilcox, Daniel S Brown, and Ken Goldberg. Thriftydagger: Budget-aware novelty and risk gating for interactive imitation learning. In5th Annual Conference on Robot Learning, 2021
work page 2021
-
[10]
Transic: Sim-to-real policy transfer by learning from online correction
Yunfan Jiang, Chen Wang, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Transic: Sim-to-real policy transfer by learning from online correction. InConference on Robot Learning, pages 1691–1729. PMLR, 2025
work page 2025
-
[11]
Hg-dagger: Inter- active imitation learning with human experts
Michael Kelly, Chelsea Sidrane, Katherine Driggs- Campbell, and Mykel J Kochenderfer. Hg-dagger: Inter- active imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
work page 2019
-
[12]
Jacky Kwok, Christopher Agia, Rohan Sinha, Matt Fout- ter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models.arXiv preprint arXiv:2506.17811, 2025
-
[13]
Risk-calibrated human-robot interaction via set-valued intent prediction
Justin Lidard, Hang Pham, Ariel Bachman, Bryan Boateng, and Anirudha Majumdar. Risk-calibrated human-robot interaction via set-valued intent prediction. Robotics: Science and Systems, 2024
work page 2024
-
[14]
Multi-task interactive robot fleet learning with visual world models
Huihan Liu, Yu Zhang, Vaarij Betala, Evan Zhang, James Liu, Crystal Ding, and Yuke Zhu. Multi-task interactive robot fleet learning with visual world models. In8th Annual Conference on Robot Learning, 2024
work page 2024
-
[15]
Calibrating llm-based evaluator
Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. Calibrating llm-based evaluator. In Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (lrec-coling 2024), pages 2638–2656, 2024
work page 2024
-
[16]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart ´ın-Mart´ın. What matters in learning from offline human demon- strations for robot manipulation. InarXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Zhiting Mei, Tenny Yin, Micah Baker, Ola Shorinwa, and Anirudha Majumdar. World models that know when they don’t know: Controllable video generation with calibrated uncertainty.arXiv preprint arXiv:2512.05927, 2025
-
[18]
Zhiting Mei, Christina Zhang, Tenny Yin, Justin Lidard, Ola Shorinwa, and Anirudha Majumdar. Reasoning about uncertainty: Do reasoning models know when they don’t know?arXiv preprint arXiv:2506.18183, 2025
-
[19]
Ensembledagger: A bayesian approach to safe imitation learning
Kunal Menda, Katherine Driggs-Campbell, and Mykel J Kochenderfer. Ensembledagger: A bayesian approach to safe imitation learning. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5041–5048. IEEE, 2019
work page 2019
-
[20]
Lbap: Improved uncertainty alignment of llm planners using bayesian inference
James F Mullen and Dinesh Manocha. Lbap: Improved uncertainty alignment of llm planners using bayesian inference. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 18716– 18723. IEEE, 2025
work page 2025
-
[21]
Allen Z Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, et al. Robots that ask for help: Uncertainty alignment for large language model planners.Conference on Robot Learning, 2023
work page 2023
-
[22]
Yaniv Romano, Matteo Sesia, and Emmanuel Candes. Classification with valid and adaptive coverage.Ad- vances in neural information processing systems, 33: 3581–3591, 2020
work page 2020
-
[23]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelli- gence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[24]
Tom Silver, Kelsey Allen, Josh Tenenbaum, and Leslie Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalk- wyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Pablo Valle, Chengjie Lu, Shaukat Ali, and Aitor Arrieta. Evaluating uncertainty and quality of visual language action-enabled robots.arXiv preprint arXiv:2507.17049, 2025
-
[27]
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, 2005
work page 2005
-
[28]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[29]
Yilin Wu, Anqi Li, Tucker Hermans, Fabio Ramos, An- drea Bajcsy, and Claudia P’erez-D’Arpino. Do what you say: Steering vision-language-action models via runtime reasoning-action alignment verification.arXiv preprint arXiv:2510.16281, 2025
-
[30]
Yilin Wu, Ran Tian, Gokul Swamy, and Andrea Bajcsy. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment.Robotics: Science and Systems, 2025
work page 2025
-
[31]
Wenli Xiao, Haotian Lin, Andy Peng, Haoru Xue, Tairan He, Yuqi Xie, Fengyuan Hu, Jimmy Wu, Zhengyi Luo, Linxi Fan, et al. Self-improving vision-language-action models with data generation via residual rl.arXiv preprint arXiv:2511.00091, 2025
-
[32]
Zhao, Henny Admoni, Reid Simmons, Aa- ditya Ramdas, and Andrea Bajcsy
Michelle D. Zhao, Henny Admoni, Reid Simmons, Aa- ditya Ramdas, and Andrea Bajcsy. Conformalized in- teractive imitation learning: Handling expert shift and intermittent feedback. InInternational Conference on Learning Representations (ICLR), 2025. URL https: //openreview.net/forum?id=Ym2RNPX6la
work page 2025
-
[33]
Dino-wm: World models on pre-trained visual features enable zero-shot planning
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[34]
Thomas P Zollo and Richard Zemel. Confidence cali- bration in vision-language-action models.arXiv preprint arXiv:2507.17383, 2025. APPENDIX A. Proof of Coverage Guarantees To maintain formal coverage guarantees despite temporal dependencies, we follow the same proof style as in [21] and perform sequence-level calibration using the minimum score over phase...
-
[35]
The image 4 is the final state of the task execution
-
[36]
Determine task outcome from the Wrist View and Front View: - GRASPING THE CUP IS A SUCCESS if you only see part of the cup round edge in the wrist view in the final frame. - GRASPING THE CUP IS A FAILURE if you can clearly see a complete round shape of the cup edge in the wrist view in the final frame. Reference Examples (Ground Truth): - Image 1: GRASPIN...
-
[37]
tell the task outcome according to the rules
-
[38]
don’t need to say the comparison between images Fig. 15:Hardware Prompt For Behavior Translation (Grasp) Role: You are an expert Robotic Systems Monitor specializing in spatial reasoning, and failure detection. Task: Analyze the final outcome of a robot performing the task of picking up the cup and placing it in the bin. Visual Inputs: Each example contai...
-
[39]
The image 3 is the final state of the task execution
-
[40]
- FAILURE if the cup is on the border or it lies down in the bin
Determine task outcome from the Wrist View: - SUCCESS if the cup is in either LEFT/RIGHT bin and standing upright. - FAILURE if the cup is on the border or it lies down in the bin. Reference Examples (Ground Truth): - Image 1: Successful because it places the cup in the LEFT bin and you can see the green cup is in the right part of the orange bin in the w...
-
[41]
tell the placement of the cup [LEFT/RIGHT]
-
[42]
tell the task outcome
-
[43]
Please place the nut on the peg with the handle facing left
don't need to say the comparison between images Fig. 16:Hardware Prompt For Behavior Translation (Place) User Intent Task Instruction left “Please place the nut on the peg with the handle facing left.” left “I want the nut positioned on the peg with the handle directed left.” left “Put the nut on the peg so that its handle is oriented leftward.” left “Set...
-
[45]
If no mode fully meets the user's intent, you must choose "an option not listed here"
-
[46]
Assume that each mode's outcome is exactly as described in the options, with no adjustments. Response format:
-
[47]
Begin your response with the single letter corresponding to your choice
-
[48]
Repeat the description of that mode
-
[49]
User instruction: {USER_INSTRUCTION} Fig
Provide a one-sentence reason explaining why it is the most appropriate choice. User instruction: {USER_INSTRUCTION} Fig. 17:Hardware Prompt for VLM Verification in Fore- warn Environment setup: You are a robot arm situated on one side of a tabletop and a user stands on the other side. All directions referenced should be from the user's perspective. Goal:...
-
[50]
If the Intent Options has only A, output is: {"A": <score for option A>}
-
[51]
If the Intent Options has A and B, output is: {"A": <score for option A>, "B": <score for option B>}
-
[52]
If the Intent Options has A , B, C, output is: {"A": <score for option A>, "B": <score for option B>,"C": <score for option C>}
-
[53]
If the Intent Options has A, B, C, D, output is: {"A": <score for option A>, "B": <score for option B>, "C": <score for option C>, "D": <score for option D>} Do not include any other text in your response, just the JSON object with the scores. <logit version> Format your response as follows : Provide only the single letter that corresponds to the selected...
-
[54]
Preserve the intent of the original instruction
-
[55]
Clearly specify which option was chosen based on the human's answer
-
[56]
Be concise and actionable
-
[57]
Sound natural (as if the user had given this instruction from the start) Generate ONLY the updated instruction, nothing else. Do not include any preamble or explanation. Fig. 20:Hardware Prompt for Updating Instructions You are a helpful robot assistant that needs to clarify ambiguous instructions before executing tasks. The user has given you the followi...
-
[58]
Be polite and natural-sounding
-
[59]
Clearly present the available options
-
[60]
Do not include any preamble or explanation
Help resolve the ambiguity so you can complete the task correctly Generate ONLY the clarification question, nothing else. Do not include any preamble or explanation. Fig. 21:Hardware Prompt for Clarification Questions Role: You are an expert Robotic Systems Monitor specializing in spatial reasoning, and failure detection. Task: Based on the user's instruc...
-
[65]
[NOTE] Evaluation Rules (STRICT):
You can give any value between 0 and 1 and must give a probability value representing your own uncertainty rather than exactly 0 or 1!! Don't use 0 or 1! Evaluation Phase: [QUERY] Phase. [NOTE] Evaluation Rules (STRICT):
-
[66]
If it is grasping phase, just selects for appropriate grasping
Evaluate the options based on the evaluation phase and the user's intent provided to the robot. If it is grasping phase, just selects for appropriate grasping
-
[67]
If no mode fully meets the user's intent, you must choose "an option not listed here" over the failures
-
[68]
Assume that each mode's outcome is exactly as described in the options, with no adjustments. <self-score version> Format your response as follows : {"A": <score for option A>, "B": <score for option B>, "C": <score for option C>, "D": <score for option D>} Do not include any other text in your response, just the JSON object with the scores. Only include a...
-
[69]
Evaluate the options based on the evaluation phase, the reasoning and user instruction provided to the robot. If the evaluation phase is grasping, just selects the behavior mode for good grasping that can move to the next phase
-
[70]
Assign each possible behavior mode a likelihood score based on how probable it is given the instruction that the user provides to the robot
-
[71]
1.0 means the given behavior mode is the only feasible option given the user's instruction, and 0.0 means the given behavior mode is completely at odds with the user's instruction
-
[72]
Ensure that the scores sum to 1.0 across all modes and this is very important!!!
-
[73]
If multiple options seem equally likely, please distribute the likelihood scores evenly among those options
-
[75]
You can give any value between 0 and 1 and must give a probability value representing your own uncertainty rather than exactly 0 or 1!! Don't use 0 or 1! Clarifications: If the user's instruction is underspecified, please do not make any biased assumptions about the user's intent or preferences. <self-score version> Format your response for step 1 as foll...
-
[76]
If it is grasping phase, just selects for appropriate grasping
Evaluate the options based on the evaluation phase and the user's instruction. If it is grasping phase, just selects for appropriate grasping
-
[77]
If no mode fully satisfies the user's instruction, you must choose "an option not listed here" rather than other options
-
[78]
Assume that each mode's outcome is exactly as described in the options, with no adjustments. <self-score version> Response format: {"A": <score for option A>, "B": <score for option B>, "C": <score for option C>, "D": <score for option D>} Do not include any other text in your response, just the JSON object with the scores. <logit version> Format your res...
-
[79]
The Image 4 provided is the final state of the task execution
-
[80]
- GRASPING THE NUT IS A FAILURE if any of the following is true: 1
Determine task outcome from the Wrist View and Front View: - GRASPING THE NUT IS A SUCCESS if the gripper grasps the nut and the handle of the nut is between the grippers in the wrist view and the hole of the nut is centered in the wrist view. - GRASPING THE NUT IS A FAILURE if any of the following is true: 1. the gripper doesn't grasp the nut, 2. the nut...
-
[81]
Describe the task outcome according to the rules
-
[82]
Don’t need to explicitly say the comparison between images Fig. 26:Simulation Prompt For Behavior Translation (Grasp) Role: You are an expert Robotic Systems Monitor specializing in spatial reasoning, assembly verification, and failure detection. Task: Analyze the final outcome of a robot performing a square -nut peg-in-hole assembly from the last frame o...
-
[83]
Image 4 provided is the final state of the task execution
-
[84]
Determine task outcome from the Wrist View and Front View: - ALIGNING THE NUT IS A SUCCESS HANDLE -FACING-LEFT if both of the following are true: 1. the square hole of the nut is aligned with the square peg (i.e., the peg lies roughly within the inner borders of the nut's hole) in the wrist view and 2. the end effector of the robot is to the left of the p...
-
[85]
Describe the task outcome and direction of the nut (SUCCESS or FAILURE and, if SUCCESS, HANDLE-FACING-RIGHT or HANDLE-FACING-LEFT) according to the rules
-
[86]
Don't need to explicitly say the comparison between images Fig. 27:Simulation Prompt For Behavior Translation (Place) Task setup: You are an expert Robotic Systems Monitor specializing in spatial reasoning and failure detection. You are guiding a robot to complete a nut assembly task. The robot is situated on one side of a table and the user stands on the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.