Recognition: 2 theorem links
· Lean TheoremWhere Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranking
Pith reviewed 2026-05-15 19:23 UTC · model grok-4.3
The pith
Selective extraction of internal attention from peak layers allows zero-shot LLMs to match larger reinforced re-rankers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
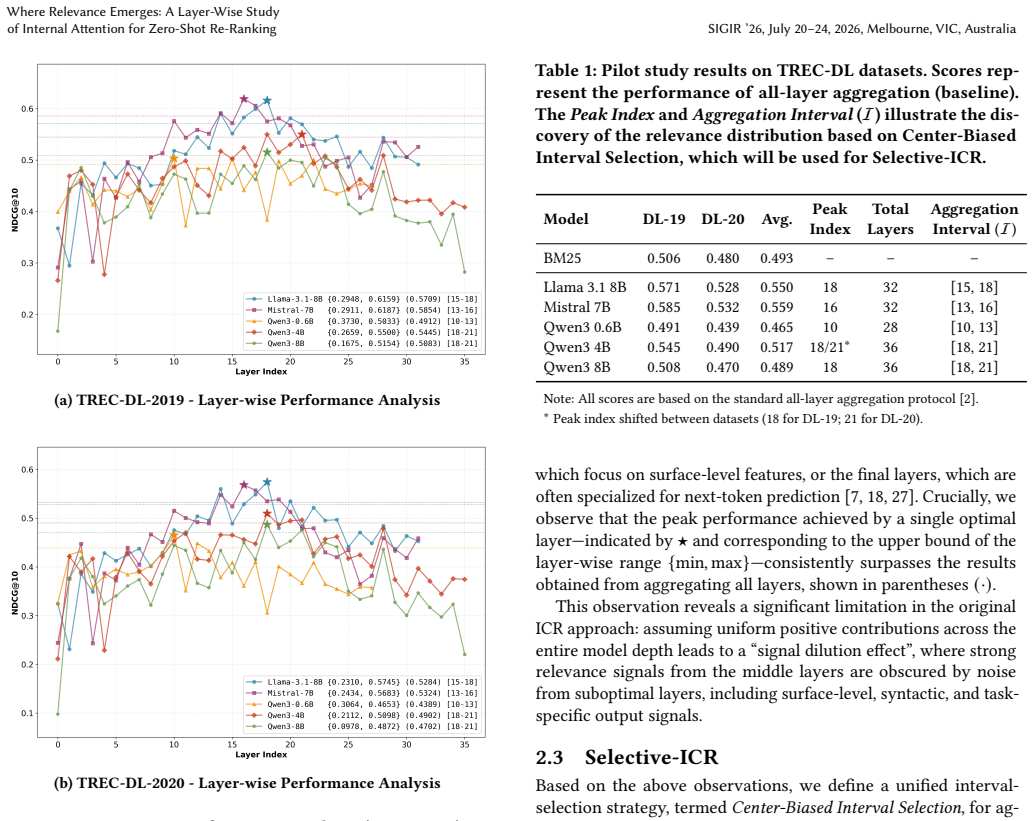
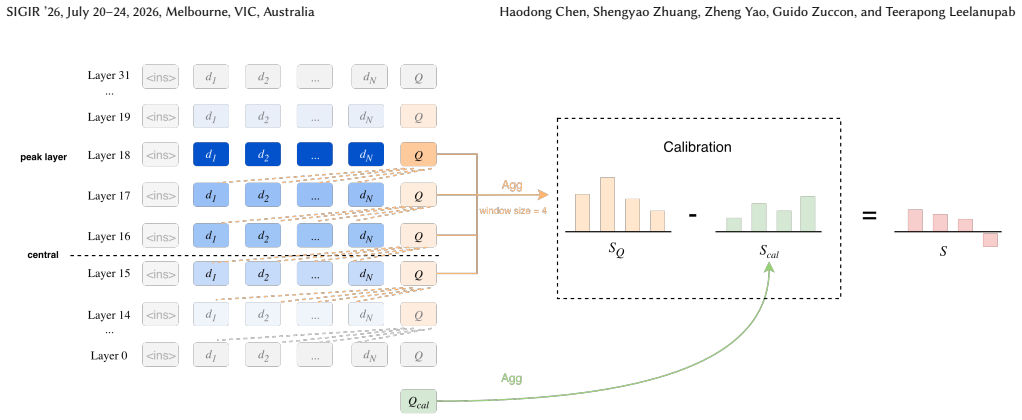
The central discovery is a universal bell-curve distribution of relevance signals across the layers of transformer models when performing in-context re-ranking. By selectively attending to the peak layers identified in this distribution, the proposed Selective-ICR extracts high-quality signals for ranking. This results in reduced inference latency of 30-50% with no effectiveness loss, and demonstrates that an 8B parameter zero-shot model can match the performance of 14B models trained via reinforcement learning on reasoning-intensive tasks.
What carries the argument
The bell-curve distribution of relevance signals across transformer layers, which enables the Selective-ICR strategy to pick only peak layers for efficient signal extraction.
Load-bearing premise
The relevance signal distribution follows a bell-curve pattern that is the same for all transformer architectures and does not require per-task tuning to select the right layers.
What would settle it
Running the method on a new model architecture where the peak layers do not yield better results than averaging all layers would show the assumption does not hold.
Figures



read the original abstract
Zero-shot document re-ranking with Large Language Models (LLMs) has evolved from Pointwise methods to Listwise and Setwise approaches that optimize computational efficiency. Despite their success, these methods predominantly rely on generative scoring or output logits, which face bottlenecks in inference latency and result consistency. In-Context Re-ranking (ICR) has recently been proposed as an O(1) alternative method. ICR extracts internal attention signals directly, avoiding the overhead of text generation. However, existing ICR methods simply aggregate signals across all layers; layer-wise contributions and their consistency across architectures have been left unexplored. Furthermore, no unified study has compared internal attention with traditional generative and likelihood-based mechanisms across diverse ranking frameworks under consistent conditions. In this paper, we conduct an orthogonal evaluation of generation, likelihood, and internal attention mechanisms across multiple ranking frameworks. We further identify a universal "bell-curve" distribution of relevance signals across transformer layers, which motivates the proposed Selective-ICR strategy that reduces inference latency by 30%-50% without compromising effectiveness. Finally, evaluation on the reasoning-intensive BRIGHT benchmark shows that precisely capturing high-quality in-context attention signals fundamentally reduces the need for model scaling and reinforcement learning: a zero-shot 8B model matches the performance of 14B reinforcement-learned re-rankers, while even a 0.6B model outperforms state-of-the-art generation-based approaches. These findings redefine the efficiency-effectiveness frontier for LLM-based re-ranking and highlight the latent potential of internal signals for complex reasoning ranking tasks. Our code and results are publicly available at https://github.com/ielab/Selective-ICR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a layer-wise analysis of internal attention signals in LLMs for zero-shot document re-ranking. It identifies a consistent 'bell-curve' distribution of relevance signals across transformer layers, proposes Selective-ICR to extract signals only from peak layers (reducing latency 30-50%), and reports that on the BRIGHT benchmark a zero-shot 8B model using this approach matches 14B RL-trained re-rankers while a 0.6B model outperforms generation-based SOTA methods. Code is released publicly.
Significance. If the bell-curve shape and peak-layer selection prove stable without test-set leakage or per-dataset fitting, the work would meaningfully shift the efficiency frontier for LLM re-ranking by showing that targeted internal signals can substitute for generation and large-scale RL. Public code strengthens reproducibility.
major comments (3)
- [Abstract] Abstract: The claim that 'precisely capturing high-quality in-context attention signals fundamentally reduces the need for model scaling and reinforcement learning' rests on Selective-ICR performance; the manuscript must explicitly state whether the layer indices for each model size were determined solely from training/validation splits or by inspecting attention statistics on the BRIGHT test split itself.
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): The universality of the bell-curve distribution is asserted but no cross-architecture ablation (e.g., on non-Llama or non-Transformer variants) or frozen-selection protocol is described; without evidence that peak locations remain stable when the selection rule is fixed in advance, the zero-shot framing and latency claims are at risk.
- [§5.2] §5.2 (BRIGHT results): The reported equivalence between the 8B zero-shot Selective-ICR and 14B RL re-rankers requires statistical significance tests and full disclosure of data splits; if layer selection was tuned on the same test instances used for final evaluation, the comparison is invalid.
minor comments (2)
- Add a table or figure explicitly listing the selected layer indices for each model size and dataset to allow direct replication.
- [§3] Clarify the precise aggregation formula for 'internal attention signals' (e.g., mean, max, or weighted) in the methods section rather than leaving it implicit.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify key aspects of our experimental protocol and strengthen the zero-shot claims. We address each major point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'precisely capturing high-quality in-context attention signals fundamentally reduces the need for model scaling and reinforcement learning' rests on Selective-ICR performance; the manuscript must explicitly state whether the layer indices for each model size were determined solely from training/validation splits or by inspecting attention statistics on the BRIGHT test split itself.
Authors: We agree this clarification is essential for the zero-shot framing. Layer indices were selected by inspecting attention statistics exclusively on the official BRIGHT validation split for each model size; the test split was never used for any selection or tuning. We will explicitly state this protocol in the revised abstract and add a dedicated paragraph in §4 (Experimental Setup) describing the split usage and confirming no test leakage. revision: yes
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): The universality of the bell-curve distribution is asserted but no cross-architecture ablation (e.g., on non-Llama or non-Transformer variants) or frozen-selection protocol is described; without evidence that peak locations remain stable when the selection rule is fixed in advance, the zero-shot framing and latency claims are at risk.
Authors: Our study is limited to Llama-family models due to computational resources, but the bell-curve pattern held consistently across 0.6B–8B scales. We will add a new subsection in the revision describing a frozen-selection protocol: peak layers identified on the 0.6B model are fixed and applied without re-tuning to the 8B model, preserving the reported latency gains and effectiveness. While a full cross-architecture study (e.g., Mistral or non-Transformer) is beyond the current scope, this frozen protocol directly addresses stability of the selection rule. revision: partial
-
Referee: [§5.2] §5.2 (BRIGHT results): The reported equivalence between the 8B zero-shot Selective-ICR and 14B RL re-rankers requires statistical significance tests and full disclosure of data splits; if layer selection was tuned on the same test instances used for final evaluation, the comparison is invalid.
Authors: We will add statistical significance tests (paired t-test and Wilcoxon signed-rank) with p-values to §5.2 comparing all methods. We will also expand §4 to fully disclose the BRIGHT official splits and reiterate that layer selection used only the validation portion. With these additions the equivalence claim remains valid under the zero-shot protocol; no test instances influenced layer choice. revision: yes
Circularity Check
No circularity: empirical observation of layer-wise attention patterns drives Selective-ICR without self-referential derivation
full rationale
The paper's core contribution is an empirical layer-wise analysis of internal attention signals on benchmarks including BRIGHT, identifying a bell-curve distribution that motivates Selective-ICR. This is a data-driven measurement and strategy proposal, not a derivation that reduces by construction to fitted parameters, self-definitions, or self-citation chains. Performance comparisons (e.g., 8B zero-shot matching 14B RL) are presented as experimental outcomes rather than tautological predictions. No equations or steps in the abstract or described chain exhibit the enumerated circularity patterns; the universality claim is an observation open to cross-validation, not a load-bearing self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer attention layers encode task-relevant information that can be read out directly without generation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We further identify a universal “bell-curve” distribution of relevance signals across transformer layers, which motivates the proposed Selective-ICR strategy
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the observed bell-shaped relevance distribution is an intrinsic property of decoder-only architectures
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Haodong Chen, Guido Zuccon, and Teerapong Leelanupab. 2025. Beyond GeneGPT: A Multi-Agent Architecture with Open-Source LLMs for Enhanced Ge- nomic Question Answering. InProceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region (SIGIR-AP ’25). Xi’an, China, 143–152. do...
-
[2]
Shijie Chen, Bernal Jiménez Gutiérrez, and Yu Su. 2025. Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers. InProceedings of the Thirteenth International Conference on Learning Representations (ICLR ’25). Singa- pore. doi:10.48550/arXiv.2410.02642
-
[3]
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, and Daniel Campos. 2021. Overview of the TREC 2020 Deep Learning Track.arXiv preprint arXiv:2102.07662(2021). doi:10.48550/arXiv.2102.07662
-
[4]
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, and Ellen M. Voorhees. 2020. Overview of the TREC 2019 Deep Learning Track.arXiv preprint arXiv:2003.07820(2020). doi:10.48550/arXiv.2003.07820
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, et al
-
[6]
The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024). doi:10.48550/arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[7]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Singh Chaplot, Devendra, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guil- laume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[8]
Vedang Lad, Jin Hwa Lee, Wes Gurnee, and Max Tegmark. 2025. Remarkable Robustness of LLMs: Stages of Inference?. InProceedings of the 39th Annual Conference on Neural Information Processing Systems (NIPS ’25). San Diego, USA. https://openreview.net/forum?id=Wxh5Xz7NpJ Where Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranki...
work page 2025
-
[9]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michi- hiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, et al . 2023. Holis- tic Evaluation of Language Models.arXiv preprint arXiv:2211.09110(2023). doi:10.48550/arXiv.2211.09110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.09110 2023
-
[10]
Jimmy Lin, Rodrigo Nogueira, and Andrew Yates. 2021. Pretrained Transformers for Text Ranking: BERT and Beyond. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Tutorials (NAACL ’21). doi:10.18653/v1/2021.naacl- tutorials.1
-
[11]
Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. 2023. Zero-Shot Listwise Document Reranking with a Large Language Model.arXiv preprint arXiv:2305.02156(2023). doi:10.48550/arXiv.2305.02156
-
[12]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Alt- man, Shyamal Anadkat, Red Avila, Igor Babuschkin, et al. 2024. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774(2024). doi:10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2024
-
[13]
Ronak Pradeep, Sahel Sharifymoghaddam, and Jimmy Lin. 2023. RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models.arXiv preprint arXiv:2309.15088(2023). doi:10.48550/arXiv.2309.15088
-
[14]
Ronak Pradeep, Sahel Sharifymoghaddam, and Jimmy Lin. 2023. RankZephyr: Effective and Robust Zero-Shot Listwise Reranking Is a Breeze!arXiv preprint arXiv:2312.02724(2023). doi:10.48550/arXiv.2312.02724
work page internal anchor Pith review doi:10.48550/arxiv.2312.02724 2023
-
[15]
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, et al. 2024. Large Language Models Are Effective Text Rankers with Pairwise Ranking Prompting. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL ’24). Mexico City,...
-
[16]
Revanth Gangi Reddy, JaeHyeok Doo, Yifei Xu, Md Arafat Sultan, Deevya Swain, Avirup Sil, and Heng Ji. 2024. FIRST: Faster Improved Listwise Reranking with Single Token Decoding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP ’24). Miami, USA, 8642–8652. doi:10.186 53/v1/2024.emnlp-main.491
work page 2024
-
[17]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond. (2009), 333–389. doi:10.1561/1500000019
-
[18]
Devendra Sachan, Mike Lewis, Mandar Joshi, Armen Aghajanyan, Wen-tau Yih, Joelle Pineau, and Luke Zettlemoyer. 2023. Improving Passage Retrieval with Zero-Shot Question Generation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP ’22). Abu Dhabi, United Arab Emirates, 3781–3797. doi:10.18653/v1/2022.emnlp-main.249
-
[19]
Xinyuan Song, Keyu Wang, PengXiang Li, Lu Yin, and Shiwei Liu. 2025. De- mystifying the roles of llm layers in retrieval, knowledge, and reasoning.arXiv preprint arXiv:2510.02091(2025). doi:10.48550/arXiv.2510.02091
-
[20]
Hongjin Su, Shuyang Jiang, Yuhang Lai, Haoyuan Wu, Boao Shi, Che Liu, Qian Liu, and Tao Yu. 2024. ARKS: Active Retrieval in Knowledge Soup for Code Generation.arXiv preprint arXiv:2402.12317(2024). doi:10.48550/arXiv.2402.12317
-
[21]
Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O
Hongjin Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han-yu Wang, Haisu Liu, Quan Shi, Zachary S. Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O. Arik, Danqi Chen, and Tao Yu. 2025. BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval. InProceedings of the Thirteenth International Conference on Learning...
-
[22]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT Good at Search? Investi- gating Large Language Models as Re-Ranking Agents. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP ’23). Singapore, 14918–14937. doi:10.18653/v1/2023.emnlp-main.923
-
[23]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InProceedings of the 35th Annual Conference on Neural Information Processing Systems ((NIPS ’21). doi:10.48550/arXiv.2104.08663
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.08663 2021
-
[24]
Jason Wei, Maarten Paul Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew Mingbo Dai, and Quoc V. Le. 2022. Finetuned Language Models are Zero-Shot Learners. InProceedings of the Tenth International Conference on Learning Representations (ICLR ’22). https://openreview.net/for um?id=gEZrGCozdqR
work page 2022
-
[25]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, et al. 2025. Qwen3 Technical Report. arXiv preprint arXiv:2505.09388(2025). doi:10.48550/arXiv.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[26]
Zhe Yin, Xiaodong Gu, and Beijun Shen. 2025. Neuron-Guided Interpretation of Code LLMs: Where, Why, and How?arXiv preprint arXiv:2512.19980(2025). doi:10.48550/arXiv.2512.19980
-
[27]
Wuwei Zhang, Fangcong Yin, Howard Yen, Danqi Chen, and Xi Ye. 2025. Query- Focused Retrieval Heads Improve Long-Context Reasoning and Re-ranking. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP ’25). Suzhou, China, 23802–23816. doi:10.18653/v1/2025.emn lp-main.1214
-
[28]
Yang Zhang, Yanfei Dong, and Kenji Kawaguchi. 2024. Investigating layer impor- tance in large language models. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP (BlackboxNLP ’24). Miami, USA, 469–479. doi:10.18653/v1/2024.blackboxnlp-1.29
-
[29]
Shengyao Zhuang, Hang Li, and Guido Zuccon. 2021. Deep query likelihood model for information retrieval. InProceedings of the 43rd European Conference on Information Retrieval (ECIR ’21). LUCCA, Italy, 463–470. doi:10.1007/978-3- 030-72240-1_49
-
[30]
Shengyao Zhuang, Bing Liu, Bevan Koopman, and Guido Zuccon. 2023. Open- Source Large Language Models Are Strong Zero-shot Query Likelihood Models for Document Ranking. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP ’23). Singapore, 8807–8817. doi:10.18653 /v1/2023.findings-emnlp.590
work page 2023
-
[31]
Shengyao Zhuang, Xueguang Ma, Bevan Koopman, Jimmy Lin, and Guido Zuccon
-
[32]
doi:10.48550/a rXiv.2503.06034
Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning.arXiv preprint arXiv:2503.06034(2025). doi:10.48550/a rXiv.2503.06034
work page doi:10.48550/a 2025
-
[33]
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. 2024. A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). Washington, USA. doi:10.1145/3626772.3657813
-
[34]
Shengyao Zhuang and Guido Zuccon. 2021. TILDE: Term Independent Likelihood moDEl for Passage Re-ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’21). 1483–
work page 2021
-
[35]
doi:10.1145/3404835.3462922
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.