Recognition: 2 theorem links
· Lean TheoremTrajTok: Learning Trajectory Tokens enables better Video Understanding
Pith reviewed 2026-05-15 19:09 UTC · model grok-4.3
The pith
TrajTok learns trajectory tokens end-to-end through implicit space-time clustering to improve video model accuracy and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TrajTok contains a unified segmenter that performs implicit clustering over pixels in both space and time to directly produce object trajectories in a single forward pass. By prioritizing downstream adaptability over pixel-perfect segmentation fidelity, the tokenizer dynamically adjusts token granularity to semantic complexity independent of video duration, enabling a video CLIP model trained from scratch to reach the best accuracy at scale across classification and retrieval benchmarks while matching the efficiency of the best token-merging methods.
What carries the argument
Unified segmenter that performs implicit clustering over pixels in space and time to produce object trajectories.
If this is right
- Video models can handle longer sequences without token count growing with duration.
- Accuracy on classification and retrieval improves while compute stays comparable to token-merging methods.
- The same tokenizer module works as a probing head on frozen visual features.
- It functions as an alignment connector inside vision-language models for long-video reasoning.
- Token count becomes independent of video length and scales with scene complexity instead.
Where Pith is reading between the lines
- Trajectory tokens could support more consistent temporal modeling in video generation or prediction tasks.
- The single-pass clustering approach may reduce latency in real-time video analysis pipelines.
- Integration of TrajTok-style adapters with audio or text streams could improve multimodal temporal alignment.
Load-bearing premise
Implicit clustering of pixels in space and time will produce trajectories that remain semantically useful for downstream video tasks when the segmenter trains only for task adaptability rather than pixel-level fidelity.
What would settle it
A controlled experiment in which a standard patch-based video model or token-merging baseline outperforms TrajViT2 on large-scale video classification and retrieval benchmarks at matched compute and model size.
Figures







read the original abstract
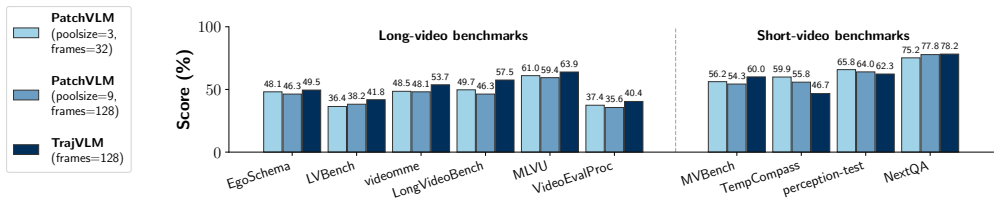
Tokenization in video models, typically through patchification, generates an excessive and redundant number of tokens. This severely limits video efficiency and scalability. While recent trajectory-based tokenizers offer a promising solution by decoupling video duration from token count, they rely on complex external segmentation and tracking pipelines that are slow and task-agnostic. We propose TrajTok, an end-to-end video tokenizer module that is fully integrated and co-trained with video models for a downstream objective, dynamically adapting its token granularity to semantic complexity, independent of video duration. TrajTok contains a unified segmenter that performs implicit clustering over pixels in both space and time to directly produce object trajectories in a single forward pass. By prioritizing downstream adaptability over pixel-perfect segmentation fidelity, TrajTok is lightweight and efficient, yet empirically improves video understanding performance. With TrajTok, we implement a video CLIP model trained from scratch (TrajViT2). It achieves the best accuracy at scale across both classification and retrieval benchmarks, while maintaining efficiency comparable to the best token-merging methods. TrajTok also proves to be a versatile component beyond its role as a tokenizer. We show that it can be seamlessly integrated as either a probing head for pretrained visual features (TrajAdapter) or an alignment connector in vision-language models (TrajVLM) with especially strong performance in long-video reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TrajTok, an end-to-end trainable video tokenizer module containing a unified segmenter that performs implicit space-time pixel clustering to produce object trajectories in a single forward pass. TrajTok is co-trained with downstream video models to adapt token granularity to semantic complexity rather than video duration, avoiding external segmentation pipelines. The authors implement this in TrajViT2, a video CLIP model trained from scratch, claiming state-of-the-art accuracy on classification and retrieval benchmarks at scale with efficiency comparable to token-merging methods. TrajTok is also shown as a versatile component in TrajAdapter for probing pretrained features and TrajVLM as an alignment connector for long-video reasoning.
Significance. If the empirical performance claims hold with proper verification, TrajTok could advance efficient video understanding by enabling adaptive, task-aware tokenization without heavy external dependencies, potentially improving scalability for long videos while maintaining or boosting accuracy over patch-based or merging baselines.
major comments (2)
- [Abstract] Abstract: the central claim that TrajViT2 'achieves the best accuracy at scale across both classification and retrieval benchmarks' is presented without any quantitative results, tables, or specific benchmark numbers, preventing verification of the reported gains over token-merging methods.
- [Method] TrajTok method description: the unified segmenter is optimized solely for downstream adaptability via implicit clustering, but no ablations or trajectory-quality metrics (e.g., against ground-truth tracks) are referenced to confirm that the resulting tokens preserve object-level semantics rather than low-level motion patterns; this directly bears on whether the accuracy advantage holds.
minor comments (1)
- [Abstract] Abstract: the phrasing 'maintaining efficiency comparable to the best token-merging methods' would benefit from explicit FLOPs or token-count comparisons even at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and verifiability where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TrajViT2 'achieves the best accuracy at scale across both classification and retrieval benchmarks' is presented without any quantitative results, tables, or specific benchmark numbers, preventing verification of the reported gains over token-merging methods.
Authors: We agree that the abstract would benefit from explicit numbers to support immediate verification. In the revised version, we will add key quantitative results (e.g., top-1 accuracy on Kinetics-400 and retrieval mAP gains relative to token-merging baselines) directly into the abstract, with references to the corresponding tables. revision: yes
-
Referee: [Method] TrajTok method description: the unified segmenter is optimized solely for downstream adaptability via implicit clustering, but no ablations or trajectory-quality metrics (e.g., against ground-truth tracks) are referenced to confirm that the resulting tokens preserve object-level semantics rather than low-level motion patterns; this directly bears on whether the accuracy advantage holds.
Authors: The segmenter is deliberately optimized for downstream task performance rather than explicit segmentation fidelity, as described in Section 3. We provide supporting ablations in Section 4 showing consistent accuracy and efficiency gains over patch-based and merging baselines. While direct quantitative metrics against ground-truth tracks are not included (the method prioritizes adaptability over pixel-level accuracy), qualitative trajectory visualizations and the observed downstream improvements indicate capture of semantic object-level patterns. We will expand the discussion of this design choice in the revision. revision: partial
Circularity Check
No significant circularity detected in TrajTok derivation chain
full rationale
The paper presents TrajTok as a novel end-to-end trainable video tokenizer module that performs implicit space-time pixel clustering via a unified segmenter, co-trained directly for downstream video understanding objectives. No equations, derivations, or self-citations are shown that reduce the claimed performance gains (e.g., TrajViT2 accuracy on classification/retrieval) to quantities defined by the method's own fitted parameters or inputs by construction. The approach is described as a new architectural component evaluated empirically on standard benchmarks, with efficiency claims tied to token reduction rather than tautological redefinitions. This is a standard empirical method paper without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Implicit space-time clustering of pixels produces object trajectories that are semantically meaningful for video understanding when optimized for downstream performance rather than segmentation fidelity.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TrajTok contains a unified segmenter that performs implicit clustering over pixels in both space and time to directly produce object trajectories in a single forward pass. By prioritizing downstream adaptability over pixel-perfect segmentation fidelity...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use a combination of Dice loss and Focal loss... to prioritize the discovery of all object regions over strict pixel-level class accuracy.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vivit: A video vi- sion transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. Vivit: A video vi- sion transformer. InICCV, 2021. 1, 2, 5 Table 8.Datasets used for training TrajVLM under the “fi- nal” mixture.This mixture combines a large set of academic VideoQA datasets, temporal reasoning datasets, and synthetic cap- tioning/QA corpora. C...
work page 2021
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, et al. V-jepa 2: Self-supervised video models enable understanding, predic- tion and planning.arXiv preprint arXiv:2506.09985, 2025. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nico- las Ballas. V-jepa: Video joint-embedding predictive archi- tecture.arXiv preprint arXiv:2404.08471, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Is 11 space-time attention all you need for video understanding? InICML, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is 11 space-time attention all you need for video understanding? InICML, 2021. 1, 2
work page 2021
-
[5]
Flexivit: One model for all patch sizes
Lukas Beyer, Xiaohua Zhai, Alexander Kolesnikov, Joan Puigcerver, Alexander Steiner, Daniel Keysers, Barret Zoph, and Neil Houlsby. Flexivit: One model for all patch sizes. In CVPR, 2023. 1
work page 2023
-
[6]
Token merging: Your vit but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. InICLR, 2023. 1, 2
work page 2023
-
[7]
MONet: Unsupervised Scene Decomposition and Representation
Chris Burgess, Hyunjik Kim, Loic Matthey, Nick Wat- ters, Rishabh Kabra, Irina Higgins, Matthew Botvinick, and Alexander Lerchner. Monet: Unsupervised scene decompo- sition and representation. InarXiv:1901.11390, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[8]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 5, 6, 8
work page 2015
-
[9]
Conceptual 12m: Pushing web-scale image-text pre- training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre- training to recognize long-tail visual concepts. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021. 5, 9
work page 2021
-
[10]
Subobject-level image tokeniza- tion.arXiv preprint arXiv:2402.14327, 2024
Delong Chen, Samuel Cahyawijaya, Jianfeng Liu, Baoyuan Wang, and Pascale Fung. Subobject-level image tokeniza- tion.arXiv preprint arXiv:2402.14327, 2024. 2, 9
-
[11]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13320–13331, 2024. 5, 9
work page 2024
-
[12]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022. 2, 3
work page 2022
-
[13]
Joonmyung Choi, Sanghyeok Lee, Jaewon Chu, Minhyuk Choi, and Hyunwoo J. Kim. vid-tldr: Training free token merging for light-weight video transformer. InCVPR, 2024. 2
work page 2024
-
[14]
Rohan Choudhury, Guanglei Zhu, Sihan Liu, Koichiro Ni- inuma, Kris M. Kitani, and L´aszl´o A. Jeni. Don’t look twice: Faster video transformers with run-length tokenization. In NeurIPS, 2024. 1, 2, 5
work page 2024
-
[15]
Accelerating Vision Transformers with Adaptive Patch Sizes
Rohan Choudhury, JungEun Kim, Jinhyung Park, Eunho Yang, L´aszl´o A. Jeni, and Kris M. Kitani. Accelerating vi- sion transformers with adaptive patch sizes.arXiv preprint arXiv:2510.18091, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Molmo 2: Open weights and open data for state-of- the-art video and image models, 2026
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Rohun Tripathi, Sangho Lee, Mohammadreza Salehi, Ja- son Ren, Chris Dongjoo Kim, Yinuo Yang, Vincent Shao, Yue Yang, Weikai Huang, Ziqi Gao, Taira Anderson, Jianrui Zhang, Jitesh Jain, George Stoica, Ali Farhadi, and Ranjay Krishna. Molmo 2: Open weights and open data for state-of- the-art video an...
-
[17]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models.arXiv preprint arXiv:2409.17146, 2024. 1, 7, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2009. 5, 6
work page 2009
-
[19]
Adaptive token sampling for efficient vision transform- ers
Mohsen Fayyaz, Soroush Abbasi Koohpayegani, and J ¨urgen Gall. Adaptive token sampling for efficient vision transform- ers. InECCV, 2022. 2
work page 2022
-
[20]
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning gener- ative visual models from few training examples: An incre- mental bayesian approach tested on 101 object categories. In IEEE Conference on Computer Vision and Pattern Recogni- tion Workshop (CVPRW), 2004. 5, 6
work page 2004
-
[21]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu et al. Video-mme: A comprehensive eval- uation benchmark of multi-modal llms in video analysis. arXiv:2405.21075, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Dat- acomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Sys- tems, 36:27092–27112, 2023. 9
work page 2023
-
[23]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Sebastian Westphal, Heuna Kim, Valentin Haenel, Moritz Fr ¨uh, Peter Yianilos, Marcel Mueller-Freitag, et al. The “something something” video database for learning and evaluating visual common sense. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2...
work page 2017
-
[24]
Multi-object representation learning with iterative variational inference
Klaus Greff, Raphael L Kaufman, and et al. Multi-object representation learning with iterative variational inference. InICML, 2019. 2
work page 2019
-
[25]
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual to- ken pruning for efficient video large language models.arXiv preprint arXiv:2412.16117, 2024. 2, 7
-
[26]
Perceiver: General perception with it- erative attention.ICML, 2021
Andrew Jaegle et al. Perceiver: General perception with it- erative attention.ICML, 2021. 2, 3
work page 2021
-
[27]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Andrew Jaegle et al. Perceiver io: A general architecture for structured inputs & outputs.arXiv:2107.14795, 2021. 2
work page internal anchor Pith review arXiv 2021
-
[28]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, et al. The kinetics human action video dataset. InarXiv preprint arXiv:1705.06950, 2017. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Token fusion: Bridging the gap between token pruning and token merging
Minchul Kim et al. Token fusion: Bridging the gap between token pruning and token merging. InWACV, 2024. 2
work page 2024
-
[30]
Thomas Kipf, Gamaleldin F. Elsayed, Aravindh Mahen- dran, Austin Stone, Sara Sabour, Georg Heigold, Rico Jon- schkowski, Alexey Dosovitskiy, and Klaus Greff. Condi- tional object-centric learning from video. InICLR, 2022. 2
work page 2022
-
[31]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 2 12
work page 2023
-
[32]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. 5, 6
work page 2009
-
[33]
Trokens: Semantic- aware relational trajectory tokens for few-shot action recog- nition
Pulkit Kumar, Shuaiyi Huang, Matthew Walmer, Sai Saketh Rambhatla, and Abhinav Shrivastava. Trokens: Semantic- aware relational trajectory tokens for few-shot action recog- nition. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 13544–13556, 2025. 2
work page 2025
-
[34]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Matryoshka representation learning.Advances in Neu- ral Information Processing Systems, 35:30233–30249, 2022. 2, 4
work page 2022
-
[35]
Mvbench: A comprehensive multi- modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi- modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 7, 8
work page 2024
-
[36]
Not all patches are what you need: Expediting vi- sion transformers via token reorganizations
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, and Jue Wang. Not all patches are what you need: Expediting vi- sion transformers via token reorganizations. InICLR, 2022. 2
work page 2022
-
[37]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), 2014. 5, 6
work page 2014
-
[38]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017. 4
work page 2017
-
[39]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 5, 7
work page 2023
-
[40]
Xiangrui Liu, Yan Shu, Zheng Liu, Ao Li, Yang Tian, and Bo Zhao. Video-xl-pro: Reconstructive token compres- sion for extremely long video understanding.arXiv preprint arXiv:2503.18478, 2025. 2
-
[41]
Yutao Liu et al. Tempcompass: Do video llms really under- stand videos? InFindings of the Association for Computa- tional Linguistics (ACL), 2024. 7, 8
work page 2024
-
[42]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 11976–11986,
-
[43]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. InCVPR,
-
[44]
Object- centric learning with slot attention
Francesco Locatello, Dirk Weissenborn, and et al. Object- centric learning with slot attention. InNeurIPS, 2020. 2
work page 2020
-
[45]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations (ICLR), 2019. 11
work page 2019
-
[46]
Wentao Ma, Weiming Ren, Yiming Jia, Zhuofeng Li, Ping Nie, Ge Zhang, and Wenhu Chen. Videoeval-pro: Robust and realistic long video understanding evaluation.arXiv preprint arXiv:2505.14640, 2025. 7
-
[47]
Egoschema: A diagnostic benchmark for very long- form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding. InAdvances in Neu- ral Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023. 7
work page 2023
-
[48]
Jieru Mei, Liang-Chieh Chen, Alan Yuille, and Cihang Xie. Spformer: Enhancing vision transformer with superpixel representation.arXiv preprint arXiv:2401.02931, 2024. 1
-
[49]
Large-scale video panoptic seg- mentation in the wild: A benchmark
Jiaxu Miao, Xiaohan Wang, Yu Wu, Wei Li, Xu Zhang, Yun- chao Wei, and Yi Yang. Large-scale video panoptic seg- mentation in the wild: A benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21033–21043, 2022. 10
work page 2022
-
[50]
Atten- tion bottlenecks for multimodal fusion
Arsha Nagrani, Anurag Arnab, and Cordelia Schmid. Atten- tion bottlenecks for multimodal fusion. InNeurIPS, 2021. 2
work page 2021
-
[51]
Per- ception test: A diagnostic benchmark for multimodal video models
Viorica P ˘atr˘aucean, Lucas Smaira, Ankush Gupta, et al. Per- ception test: A diagnostic benchmark for multimodal video models. InAdvances in Neural Information Processing Sys- tems (NeurIPS), Datasets and Benchmarks Track, 2023. 7, 8
work page 2023
-
[52]
Plummer, Liwei Wang, Christopher Cervantes, Juan C
Bryan A. Plummer, Liwei Wang, Christopher Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), 2015. 5, 6
work page 2015
-
[53]
Zenon W. Pylyshyn and Roger W. Storm. Tracking multiple independent targets: Evidence for a parallel tracking mecha- nism.Spatial Vision, 3(3):179–197, 1988. 2
work page 1988
-
[54]
Qwen Team. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021. 2
work page 2021
-
[56]
Dynamicvit: Efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification. InNeurIPS,
-
[57]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi et al. Sam 2: Segment anything in images and videos.arXiv:2408.00714, 2024. 2, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Ryoo, AJ Piergiovanni, Mingxing Tan, and Anelia Angelova
Michael S. Ryoo, AJ Piergiovanni, Mingxing Tan, and Anelia Angelova. Tokenlearner: What can 8 learned tokens do for images and videos?NeurIPS, 2021. 1, 2, 5
work page 2021
-
[59]
Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning. InPro- ceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018. 5, 9
work page 2018
-
[60]
Sigurdsson, Gul Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta
Gunnar A. Sigurdsson, Gul Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in 13 homes: Crowdsourcing data collection for activity under- standing. InProceedings of the European Conference on Computer Vision (ECCV), 2016. 5, 6, 8
work page 2016
-
[61]
Scal- ing slot attention for unsupervised object discovery
Satvik Singh, Chris Burgess, and Alexander Lerchner. Scal- ing slot attention for unsupervised object discovery. InICLR,
-
[62]
Elizabeth S. Spelke. Principles of object perception.Cogni- tive Science, 14(1):29–56, 1990. 2
work page 1990
-
[63]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[64]
Generalised dice overlap as a deep learning loss function for highly unbalanced seg- mentations
Carole H Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M Jorge Cardoso. Generalised dice overlap as a deep learning loss function for highly unbalanced seg- mentations. InInternational Workshop on Deep Learning in Medical Image Analysis, pages 240–248. Springer, 2017. 4
work page 2017
-
[65]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Elder, Michael Kubovy, Stephen E
Johan Wagemans, James H. Elder, Michael Kubovy, Stephen E. Palmer, Irving Biederman, et al. A century of gestalt psychology in visual perception: I. perceptual group- ing and figure–ground organization.Psychological Bulletin, 138(6):1172–1217, 2012. 2
work page 2012
-
[67]
Efficient video transformers with spatial- temporal token selection
Junke Wang et al. Efficient video transformers with spatial- temporal token selection. InECCV, 2022. 2
work page 2022
-
[68]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yi- nan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14549–14560, 2023. 6
work page 2023
-
[69]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Lvbench: An extreme long video un- derstanding benchmark.arXiv preprint arXiv:2406.08035,
Weihan Wang et al. Lvbench: An extreme long video un- derstanding benchmark.arXiv preprint arXiv:2406.08035,
-
[71]
Vatex: A large-scale, high- quality multilingual dataset for video-and-language research
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high- quality multilingual dataset for video-and-language research. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 5, 6, 8
work page 2019
-
[72]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, and Mike Zheng Shou. Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation.arXiv preprint arXiv:2408.16730, 2024. 2
-
[74]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[75]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 5, 6, 8
work page 2016
-
[76]
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, and Afshin Dehghan. Slowfast-llava: A strong training-free base- line for video large language models.arXiv preprint arXiv:2407.15841, 2024. 7
-
[77]
Shilin Yan, Jiaming Han, Joey Tsai, Hongwei Xue, Rongyao Fang, Lingyi Hong, Ziyu Guo, and Ray Zhang. Crosslmm: Decoupling long video sequences from lmms via dual cross- attention mechanisms.arXiv preprint arXiv:2505.17020,
-
[78]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Xmem: Long- term video object segmentation with an atkinson–shiffrin memory model
Zongxin Yang, Yunchao Wei, and Yi Yang. Xmem: Long- term video object segmentation with an atkinson–shiffrin memory model. InECCV, 2022. 2
work page 2022
-
[80]
Zongxin Yang et al. Efficient video object segmentation via decomposing attention with optimized memory.arXiv preprint arXiv:2306.00961, 2023. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.