InnerQ: Hardware-Aware Tuning-Free Quantization of KV Cache for Large Language Models
Pith reviewed 2026-05-22 11:04 UTC · model grok-4.3
The pith
InnerQ quantizes the KV cache by grouping along the inner dimension to accelerate dequantization and cut decode latency in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
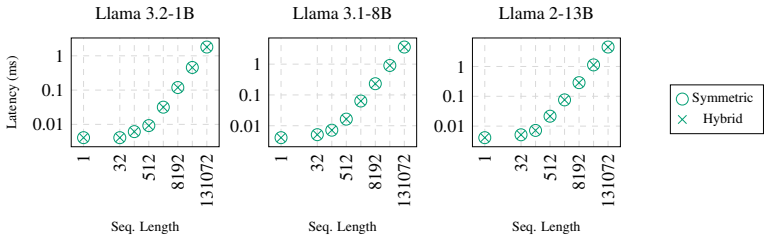
InnerQ introduces a hardware-aware tuning-free quantization scheme for the KV cache. It groups the cache matrices along the inner dimension to align dequantization with vector-matrix multiplication on GPUs, thereby increasing data reuse and reducing memory access. To preserve accuracy under compression, it uses hybrid symmetric-asymmetric quantization per group, high-precision windows for recent and attention sink tokens, and per-channel normalization of the key cache folded into model parameters. On Llama and Mistral models, this yields an average 1.3 times speedup over previous KV cache quantization methods and 2.7 times over the non-quantized baseline, while also improving few-shot evalua
What carries the argument
The inner-dimension grouping of KV cache matrices, which aligns dequantization directly with the vector-matrix multiplication performed during attention.
If this is right
- Decode latency drops by an average of 1.3 times compared to earlier KV cache quantization techniques.
- Decode latency drops by an average of 2.7 times compared to keeping the KV cache in full precision.
- Few-shot evaluation scores improve on Llama and Mistral models relative to prior quantization approaches.
- Memory footprint of the KV cache shrinks while maintaining fidelity through the combination of hybrid quantization and selective high-precision windows.
Where Pith is reading between the lines
- Similar grouping strategies could be applied to other memory-intensive operations in transformer inference to gain hardware efficiency.
- Longer context lengths become more practical on GPUs with limited memory when using this method.
- The tuning-free nature suggests it can be directly applied to new models without additional training or calibration steps.
Load-bearing premise
The grouping of cache matrices along the inner dimension will align dequantization with vector-matrix multiplication on target GPUs without adding overhead or losing precision that would cancel out the speed gains.
What would settle it
Running the same models on hardware where the inner-dimension grouping does not improve cache locality or dequantization speed, and observing no latency reduction or a reversal of the reported gains.
Figures




read the original abstract
When transformer-based language models are deployed for text generation, most of the inference time is spent in the decoding stage, where output tokens are generated sequentially. Reducing the hardware cost of each decoding step is therefore critical for efficient long-context generation. A major bottleneck is the key-value (KV) cache, whose size grows with sequence length and often dominates the model's memory footprint. Prior work has proposed quantization methods to compress the KV cache while minimizing its loss of precision. We present InnerQ, a hardware-aware KV cache quantization scheme that reduces decode latency without compromising evaluation performance. InnerQ performs group-wise quantization by grouping cache matrices along their inner dimension. This grouping strategy aligns dequantization with vector-matrix multiplication and increases data reuse across GPU compute units. As a result, InnerQ reduces memory access and accelerates dequantization, achieving an average $1.3\times$ speedup over prior KV cache quantization methods and $2.7\times$ over the non-quantized baseline. To maintain fidelity under aggressive compression, InnerQ incorporates three techniques: (i) hybrid quantization, which chooses symmetric or asymmetric quantization for each group based on local statistics; (ii) high-precision windows for both recent tokens and attention sink tokens to mitigate outlier leakage; and (iii) per-channel normalization of the key cache, computed once during prefill and folded into the model parameters to eliminate runtime overhead. Beyond reducing latency, experiments on Llama and Mistral models show that InnerQ also improves few-shot evaluation scores relative to prior KV cache quantization methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InnerQ, a hardware-aware KV cache quantization method for transformer LLMs. It performs group-wise quantization by grouping cache matrices along the inner dimension to align dequantization with vector-matrix multiplications and increase GPU data reuse. The approach incorporates hybrid symmetric/asymmetric quantization per group, high-precision windows for recent and attention-sink tokens, and per-channel key normalization computed during prefill and folded into model parameters. Experiments on Llama and Mistral models claim an average 1.3× decode latency reduction over prior KV cache quantization methods and 2.7× over the non-quantized baseline, with improved few-shot evaluation scores and no compromise on performance.
Significance. If the inner-dimension grouping delivers the claimed dequantization alignment and data reuse without hidden overheads or precision loss, InnerQ would offer a practical advance for memory-bound decode stages in long-context LLM inference. The tuning-free design, combination of outlier-handling techniques, and reported latency gains alongside improved few-shot scores are strengths that could influence deployment practices if the hardware benefits generalize across standard attention kernels.
major comments (2)
- [§4] §4 (Experiments): The central latency claims (1.3× over priors, 2.7× over baseline) and few-shot score improvements are reported without error bars, number of runs, or ablation studies isolating the contribution of the three techniques (hybrid quantization, high-precision windows, per-channel folding). This weakens verification of the 'no compromise on evaluation performance' assertion.
- [§3.1] §3.1 (Inner-dimension grouping): The claim that grouping along the inner dimension aligns dequantization with vector-matrix multiplication and boosts reuse across compute units lacks kernel-level pseudocode, micro-benchmark results, or analysis of potential extra indexing overhead, precision impact from hybrid quantization, or interaction with high-precision windows. This is load-bearing for the hardware-aware speedup claims.
minor comments (2)
- The abstract and method description should explicitly list the exact model sizes (e.g., Llama-7B, Mistral-7B) and sequence lengths used in latency and accuracy experiments for reproducibility.
- Notation for group size and window sizes could be introduced earlier with a clear table summarizing all hyperparameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment in detail below and indicate the revisions planned for the next version.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The central latency claims (1.3× over priors, 2.7× over baseline) and few-shot score improvements are reported without error bars, number of runs, or ablation studies isolating the contribution of the three techniques (hybrid quantization, high-precision windows, per-channel folding). This weakens verification of the 'no compromise on evaluation performance' assertion.
Authors: We agree that statistical reporting and ablations would strengthen the experimental section. In the revised manuscript we will state that latency results are averaged over three independent runs and will add error bars showing standard deviation. We will also insert a new ablation table in Section 4 that isolates the latency and few-shot contributions of hybrid quantization, high-precision windows, and per-channel folding. These additions will directly support the claim that evaluation performance is preserved. revision: yes
-
Referee: [§3.1] §3.1 (Inner-dimension grouping): The claim that grouping along the inner dimension aligns dequantization with vector-matrix multiplication and boosts reuse across compute units lacks kernel-level pseudocode, micro-benchmark results, or analysis of potential extra indexing overhead, precision impact from hybrid quantization, or interaction with high-precision windows. This is load-bearing for the hardware-aware speedup claims.
Authors: We acknowledge the value of more explicit hardware-level evidence. The revised Section 3.1 will include pseudocode for the grouped dequantization step that shows its alignment with vector-matrix multiplication. We will also add micro-benchmark results that quantify the reduction in memory traffic and data reuse across compute units. In the same section we will analyze indexing overhead, confirm that hybrid quantization does not measurably degrade precision relative to uniform quantization, and discuss the interaction with high-precision windows using both analytical arguments and empirical measurements from our existing evaluation suite. revision: yes
Circularity Check
No circularity: empirical method with independent hardware and accuracy claims
full rationale
The paper describes InnerQ as a set of concrete engineering choices—inner-dimension group-wise quantization to align dequantization with GEMM, hybrid symmetric/asymmetric per-group selection, high-precision windows for recent/sink tokens, and prefold per-channel key normalization—whose benefits are asserted via direct latency and few-shot measurements on Llama/Mistral. No equations, uniqueness theorems, or predictions are offered that reduce by construction to fitted parameters or prior self-citations; the central latency claims (1.3× / 2.7×) are presented as observed outcomes rather than derived quantities. The derivation chain is therefore self-contained and externally falsifiable through standard benchmark runs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dequantization can be fused with matrix multiplication when grouping follows the inner dimension of the cache matrices.
Forward citations
Cited by 2 Pith papers
-
Runtime-Certified Bounded-Error Quantized Attention
A tiered KV cache architecture computes per-head per-step error bounds on quantized attention and uses adaptive fallback to guarantee bounded or exact outputs relative to FP16 reference.
-
Attention Sinks and Outliers in Attention Residuals
OASIS mitigates attention sinks and outliers in AttnResidual models via Softmax1 null space and inter-layer signals, reporting norm and kurtosis reductions plus large gains in quantized perplexity and task accuracy.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. doi: 10.48550/arXiv.2110.14168
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168 2021
- [2]
-
[3]
URLhttps://openreview.net/forum?id=nI6JyFSnyV
-
[4]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, 10 H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou. A framework for few-shot language model evaluation, 07 2024. URL https://zenodo.org/ reco...
-
[5]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Mar...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[6]
C. Hooper, S. Kim, H. Mohammadzadeh, M. W. Mahoney, Y . S. Shao, K. Keutzer, and A. Gholami. KVQuant: Towards 10 million context length LLM inference with KV cache quantization. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 1270–1303. Curran...
-
[7]
H. Kang, Q. Zhang, S. Kundu, G. Jeong, Z. Liu, T. Krishna, and T. Zhao. GEAR: An efficient error reduction framework for KV cache compression in LLM inference. In M. Rezagholizadeh, P. Passban, S. Samiee, V . Partovi Nia, Y . Cheng, Y . Deng, Q. Liu, and B. Chen, editors, Proceedings of The 4th NeurIPS Efficient Natural Language and Speech Processing Work...
-
[8]
URLhttps://proceedings.mlr.press/v262/kang24a.html
-
[9]
A. Liu, J. Liu, Z. Pan, Y . He, G. Haffari, and B. Zhuang. MiniCache: KV cache compression in depth dimension for large language models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, volume 37, pages 139997–140031. Curran Associates, Inc., 2024. doi: 10.52...
-
[10]
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V . Braverman, B. Chen, and X. Hu. KIVI: A tuning- free asymmetric 2bit quantization for KV cache.arXiv preprint arXiv:2402.02750, 2024. doi: 10.48550/arXiv.2402.02750
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.02750 2024
-
[11]
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean. Efficiently scaling transformer inference. In D. Song, M. Carbin, and T. Chen, editors,Proceedings of Machine Learning and Systems, volume 5, pages 606–624. Cu- ran, 2023. URL https://proceedings.mlsys.org/paper_files/paper/2023/file/ c4be71ab8d24cdfb45e3...
work page 2023
-
[12]
R. Sanovar, S. Bharadwaj, R. S. Amant, V . Rühle, and S. Rajmohan. LeanAttention: Hardware- aware scalable attention mechanism for the decode-phase of transformers. InEighth Conference on Machine Learning and Systems, 2025. URL https://openreview.net/forum?id= KVZDNEoC0Q
work page 2025
- [13]
-
[14]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabsa, I. Kloumann, A. Koren...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[15]
H. Wang, L. Han, K. Xu, and A. Srivastava. Squat: Subspace-orthogonal KV cache quantization. arXiv preprint arXiv:2503.24358, 2025. doi: 10.48550/arXiv.2503.24358. 13 Algorithm 1Multi-head attention with quantized cache in the decode phase Require:Input sequenceX∈R 1×d Require:Trainable weightsW Q, WO, WK, WV ∈R d×d Require:Number of headsn h and head dim...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.