Recognition: no theorem link
FedNSAM:Consistency of Local and Global Flatness for Federated Learning
Pith reviewed 2026-05-15 18:28 UTC · model grok-4.3
The pith
FedNSAM uses global Nesterov momentum to align local and global flatness in federated learning, delivering a tighter convergence bound than FedSAM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By defining the flatness distance between local and global loss surfaces, the authors demonstrate that local sharpness minimization does not transfer to the global model under high heterogeneity. FedNSAM therefore replaces the local gradient direction for perturbation estimation with the global Nesterov momentum, using the same vector for both the ascent step that finds the worst-case point and the subsequent extrapolation. The resulting algorithm yields a strictly smaller convergence bound than FedSAM while preserving the same per-round communication cost.
What carries the argument
global Nesterov momentum vector employed as the shared direction for local perturbation estimation and extrapolation
If this is right
- Tighter convergence bound holds by the Nesterov extrapolation term in the analysis.
- Local SAM updates now improve global generalization rather than only local generalization.
- The method requires no extra communication beyond standard federated averaging.
- Performance gains appear on both convolutional and attention-based architectures.
Where Pith is reading between the lines
- The same momentum-injection idea could be tested on other local optimizers such as Adam or AdaGrad inside federated frameworks.
- Reducing flatness distance may lower the number of communication rounds needed to reach a target accuracy.
- The flatness-distance metric itself offers a diagnostic tool for comparing any pair of local and global sharpness-aware methods.
Load-bearing premise
Global Nesterov momentum can be applied directly to each client’s local perturbation calculation without creating fresh inconsistencies between local and global geometry.
What would settle it
An experiment that measures flatness distance on a highly heterogeneous data split before and after FedNSAM training and finds that the distance fails to shrink while test accuracy also fails to improve over FedSAM.
Figures




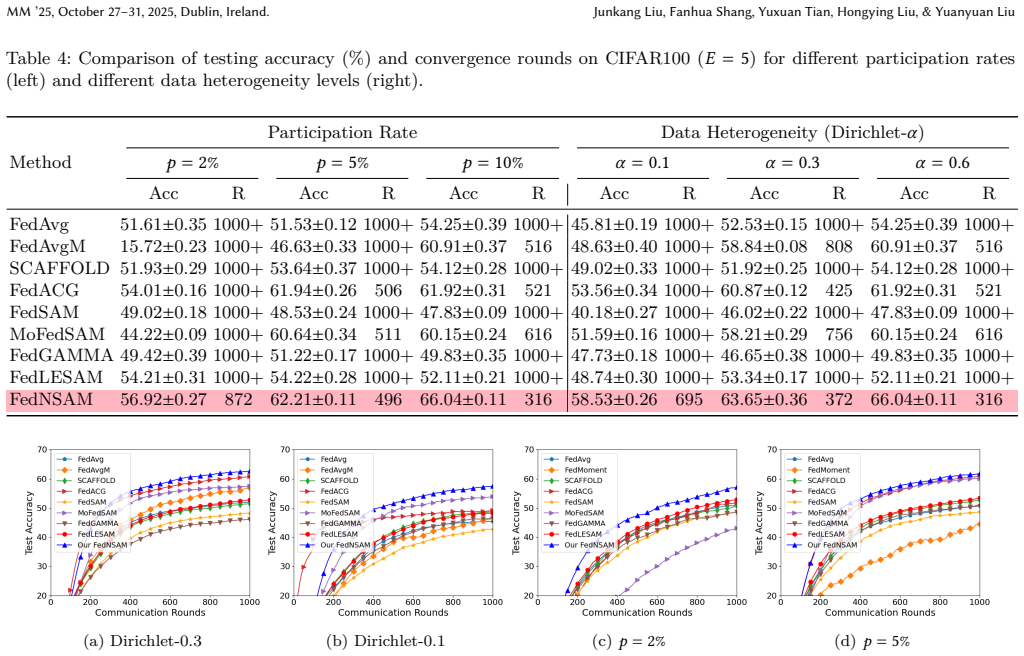

read the original abstract
In federated learning (FL), multi-step local updates and data heterogeneity usually lead to sharper global minima, which degrades the performance of the global model. Popular FL algorithms integrate sharpness-aware minimization (SAM) into local training to address this issue. However, in the high data heterogeneity setting, the flatness in local training does not imply the flatness of the global model. Therefore, minimizing the sharpness of the local loss surfaces on the client data does not enable the effectiveness of SAM in FL to improve the generalization ability of the global model. We define the \textbf{flatness distance} to explain this phenomenon. By rethinking the SAM in FL and theoretically analyzing the \textbf{flatness distance}, we propose a novel \textbf{FedNSAM} algorithm that accelerates the SAM algorithm by introducing global Nesterov momentum into the local update to harmonize the consistency of global and local flatness. \textbf{FedNSAM} uses the global Nesterov momentum as the direction of local estimation of client global perturbations and extrapolation. Theoretically, we prove a tighter convergence bound than FedSAM by Nesterov extrapolation. Empirically, we conduct comprehensive experiments on CNN and Transformer models to verify the superior performance and efficiency of \textbf{FedNSAM}. The code is available at https://github.com/junkangLiu0/FedNSAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedNSAM, a federated learning method that integrates global Nesterov momentum into local sharpness-aware minimization (SAM) updates. It defines a 'flatness distance' to explain why local flatness fails to imply global flatness under high data heterogeneity, claims to prove a tighter convergence bound than FedSAM via Nesterov extrapolation, and reports superior empirical performance on CNN and Transformer models with code released on GitHub.
Significance. If the claimed tighter bound holds under standard FL heterogeneity assumptions and the empirical gains are reproducible across diverse settings, the work could meaningfully advance SAM-based FL by resolving local-global flatness inconsistency. The public code release is a positive factor for reproducibility.
major comments (1)
- [Abstract] Abstract: the central claim of proving a tighter convergence bound than FedSAM 'by Nesterov extrapolation' and the definition of flatness distance are presented without any equations, proof steps, assumptions on heterogeneity, or derivation outline. This prevents assessment of whether the bound is non-circular or load-bearing for the consistency argument.
minor comments (1)
- [Title] The title contains a missing space after the colon ('FedNSAM:Consistency').
Simulated Author's Rebuttal
We thank the referee for their review and for identifying the need for greater clarity in how the abstract presents our theoretical claims. We address the point directly below and outline the planned revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of proving a tighter convergence bound than FedSAM 'by Nesterov extrapolation' and the definition of flatness distance are presented without any equations, proof steps, assumptions on heterogeneity, or derivation outline. This prevents assessment of whether the bound is non-circular or load-bearing for the consistency argument.
Authors: We agree that the abstract, owing to its length constraints, presents the claims at a summary level without equations or proof outlines. The full manuscript contains the formal definition of flatness distance, the heterogeneity assumptions, and the complete convergence analysis establishing the tighter bound via the Nesterov extrapolation step. The argument is structured so that the flatness distance first quantifies the local-global inconsistency, after which the extrapolation is shown to tighten the bound; the reasoning is therefore not circular. To address the concern, we will revise the abstract to include a concise reference to the flatness distance and the role of Nesterov extrapolation in the bound improvement. revision: yes
Circularity Check
No circularity detectable from available abstract
full rationale
Only the abstract is provided, which outlines the FedNSAM method, defines flatness distance to explain local-global inconsistency, and states that a tighter convergence bound than FedSAM is proved via Nesterov extrapolation. No equations, derivation steps, or self-citations are present in the text. Without inspectable math or load-bearing premises, no step can be shown to reduce by construction to its own inputs or prior self-citations. The central claim remains an independent theoretical assertion supported by the proposed algorithm and experiments.
Axiom & Free-Parameter Ledger
invented entities (1)
-
flatness distance
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rodolfo Stoffel Antunes, Cristiano André da Costa, Arne Küderle, Imrana Abdullahi Yari, and Björn Eskofier. 2022. Federated learning for healthcare: Systematic review and architecture pro- posal. ACM Transactions on Intelligent Systems and Technology (TIST) 13, 4 (2022), 1–23
work page 2022
-
[2]
David Byrd and Antigoni Polychroniadou. 2020. Differentially private secure multi-party computation for federated learning in financial applications. In Proceedings of the First ACM Interna- tional Conference on AI in Finance. 1–9
work page 2020
-
[3]
Debora Caldarola, Barbara Caputo, and Marco Ciccone. 2022. Improving generalization in federated learning by seeking flat minima. In European Conference on Computer Vision. Springer, 654–672
work page 2022
- [4]
-
[5]
Muzhi Dai, Jiashuo Sun, Zhiyuan Zhao, Shixuan Liu, Rui Li, Junyu Gao, and Xuelong Li. 2025. From Captions to Re- wards (CAREVL): Leveraging Large Language Model Experts for Enhanced Reward Modeling in Large Vision-Language Mod- els. arXiv: 2503.06260 [cs.CV] https://arxiv.org/abs/2503.06260
-
[6]
Rong Dai, Xun Yang, Yan Sun, Li Shen, Xinmei Tian, Meng Wang, and Yongdong Zhang. 2023. Fedgamma: Federated learn- ing with global sharpness-aware minimization. IEEE Transac- tions on Neural Networks and Learning Systems (2023)
work page 2023
-
[7]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa De- hghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [9]
- [10]
-
[11]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778
work page 2016
- [12]
-
[13]
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. 2020. Scaf- fold: Stochastic controlled averaging for federated learning. In In- ternational Conference on Machine Learning. PMLR, 5132–5143
work page 2020
-
[14]
Geeho Kim, Jinkyu Kim, and Bohyung Han. 2024. Communication-efficient federated learning with accelerated client gradient. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12385–12394
work page 2024
-
[15]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
work page 2009
-
[16]
Ya Le and Xuan Yang. 2015. Tiny imagenet visual recognition challenge. CS 231N 7, 7 (2015), 3
work page 2015
-
[17]
Yann LeCun et al. 2015. LeNet-5, convolutional neural networks. URL: http://yann. lecun. com/exdb/lenet 20, 5 (2015), 14
work page 2015
-
[18]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. 2020. Federated optimiza- tion in heterogeneous networks. In Proceedings of Machine Learn- ing and Systems
work page 2020
-
[19]
Tao Li, Pan Zhou, Zhengbao He, Xinwen Cheng, and Xiaolin Huang. 2024. Friendly sharpness-aware minimization. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5631–5640
work page 2024
-
[20]
Junkang Liu, Yuanyuan Liu, Fanhua Shang, Hongying Liu, Jin Liu, and Wei Feng. 2025. Improving Generalization in Federated Learning with Highly Heterogeneous Data via Momentum-Based Stochastic Controlled Weight A veraging. In Forty-second Inter- national Conference on Machine Learning
work page 2025
- [21]
-
[22]
Junkang Liu, Fanhua Shang, Yuanyuan Liu, Hongying Liu, Yuan- gang Li, and YunXiang Gong. 2024. Fedbcgd: Communication- efficient accelerated block coordinate gradient descent for fed- erated learning. In Proceedings of the 32nd ACM International Conference on Multimedia. 2955–2963
work page 2024
-
[23]
Junkang Liu, Fanhua Shang, Yuxuan Tian, Hongying Liu, and Yuanyuan Liu. 2025. Consistency of local and global flatness for federated learning. In Proceedings of the 33rd ACM International Conference on Multimedia. 3875–3883
work page 2025
- [24]
-
[25]
Junkang Liu, Fanhua Shang, Kewen Zhu, Hongying Liu, Yuanyuan Liu, and Jin Liu. 2025. FedAdamW: A Communication-Efficient Optimizer with Convergence and Generalization Guarantees for Federated Large Models. arXiv preprint arXiv:2510.27486 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [26]
-
[27]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierar- chical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision. 10012–10022
work page 2021
-
[28]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hamp- son, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics. PMLR, 1273–1282
work page 2017
-
[29]
Yurii Nesterov. 2013. Introductory lectures on convex optimiza- tion: A basic course. Vol. 87. Springer Science & Business Media
work page 2013
-
[30]
Zhe Qu, Xingyu Li, Rui Duan, Yao Liu, Bo Tang, and Zhuo Lu. 2022. Generalized federated learning via sharpness aware minimization. In International Conference on Machine Learning. PMLR, 18250–18280
work page 2022
-
[31]
Nicola Rieke, Jonny Hancox, Wenqi Li, Fausto Milletari, Holger R Roth, Shadi Albarqouni, Spyridon Bakas, Mathieu N Galtier, Bennett A Landman, Klaus Maier-Hein, et al. 2020. The future of digital health with federated learning. NPJ digital medicine 3, 1 (2020), 119
work page 2020
-
[32]
Karen Simonyan and Andrew Zisserman. 2014. Very deep con- volutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
Yan Sun, Li Shen, Shixiang Chen, Liang Ding, and Dacheng Tao. 2023. Dynamic regularized sharpness aware minimization in federated learning: Approaching global consistency and smooth landscape. In International Conference on Machine Learning. PMLR, 32991–33013
work page 2023
-
[34]
Linlin Yang, Hongying Liu, Yuanyuan Liu, Fanhua Shang, Liang Wan, and Licheng Jiao. 2025. Distillation guided deep unfolding network with frequency hierarchical regularization for low-dose CT image denoising. Neurocomputing (2025), 130535
work page 2025
-
[35]
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, and Xing Wei. 2025. FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving. arXiv preprint arXiv:2505.17685 (2025). Consistency of Local and Global Flatness for Federated Learning MM ’25, October 27–31, 2025, Dublin, Ireland. Algorithm 2 FedNSAM ...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.