Recognition: 2 theorem links
· Lean TheoremDRIV-EX: Counterfactual Explanations for Driving LLMs
Pith reviewed 2026-05-15 17:43 UTC · model grok-4.3
The pith
DRIV-EX generates fluent counterfactual scene descriptions that flip LLM driving decisions by using optimized embeddings to guide controlled text regeneration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DRIV-EX identifies the input shifts required to flip an LLM driving plan by performing gradient-based optimization on continuous embeddings and then using those embeddings solely as a semantic guide to bias a controlled decoding process that regenerates the original scene description, thereby producing outputs that maintain linguistic fluency, domain validity, and proximity to the input.
What carries the argument
Gradient-optimized embeddings used as a semantic guide to bias controlled decoding toward a counterfactual target while regenerating the scene text.
If this is right
- LLM driving planners can be audited for latent biases through the specific minimal changes identified.
- Concrete examples of required alterations can directly inform robustness improvements to the agents.
- The generated explanations remain usable for interpretation because they preserve validity and proximity.
- The technique outperforms existing baselines in producing valid and fluent outputs on transcribed highway data.
Where Pith is reading between the lines
- The regeneration step could extend to other sequential decision domains where LLMs process textual descriptions of states.
- If the method holds on more varied or multimodal scenes, it might reduce reliance on manual inspection of model outputs.
- Applying the same embedding-guidance pattern to non-driving tasks would test whether the core mechanism generalizes beyond road scenes.
Load-bearing premise
The optimized embeddings can steer the decoding process to produce coherent and valid driving scene descriptions without introducing incoherence or straying too far from the original input.
What would settle it
A collection of generated counterfactuals in which a large fraction describe physically impossible driving scenes or contain meaning-altering grammatical errors, as assessed by domain experts on the same highD transcriptions, would falsify the reliability claim.
Figures




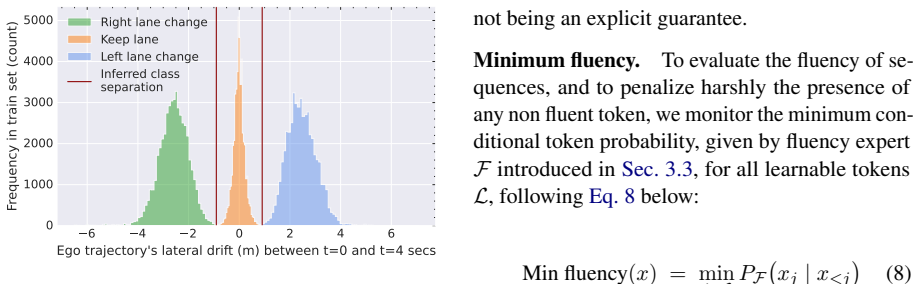
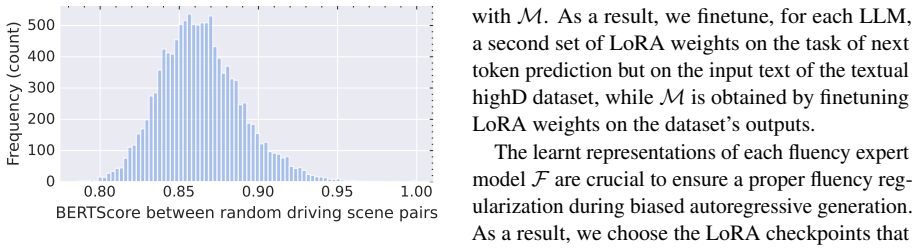




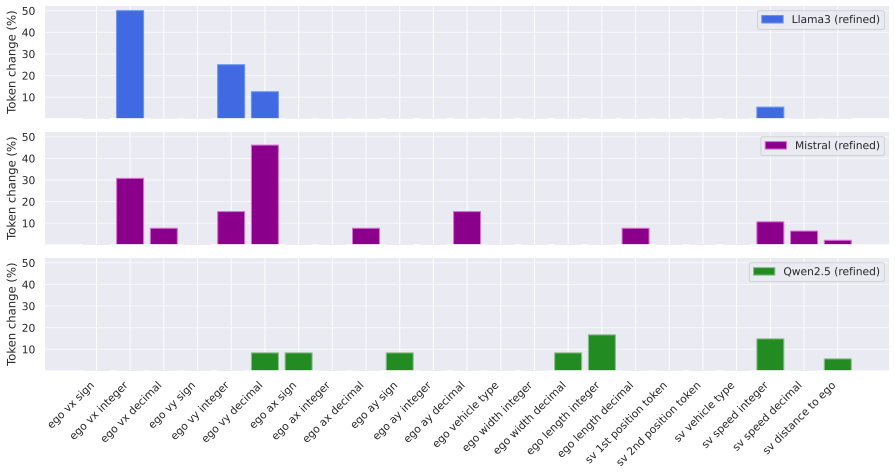


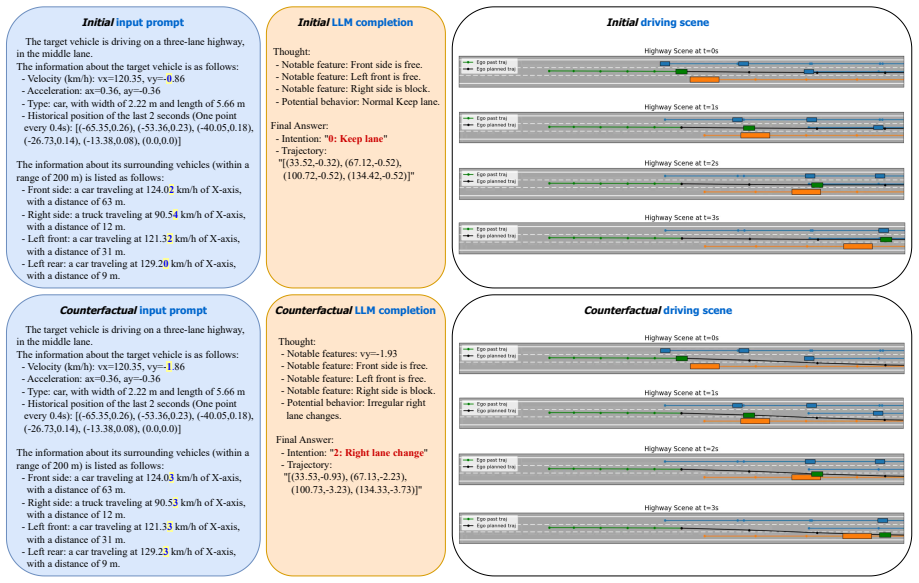

read the original abstract
Large language models (LLMs) are increasingly used as reasoning engines in autonomous driving, yet their decision-making remains opaque. We propose to study their decision process through counterfactual explanations, which identify the minimal semantic changes to a scene description required to alter a driving plan. We introduce DRIV-EX, a method that leverages gradient-based optimization on continuous embeddings to identify the input shifts required to flip the model's decision. Crucially, to avoid the incoherent text typical of unconstrained continuous optimization, DRIV-EX uses these optimized embeddings solely as a semantic guide: they are used to bias a controlled decoding process that re-generates the original scene description. This approach effectively steers the generation toward the counterfactual target while guaranteeing the linguistic fluency, domain validity, and proximity to the original input, essential for interpretability. Evaluated using the LC-LLM planner on a textual transcription of the highD dataset, DRIV-EX generates valid, fluent counterfactuals more reliably than existing baselines. It successfully exposes latent biases and provides concrete insights to improve the robustness of LLM-based driving agents. The code is available at "https://github.com/Amaia-CARDIEL/DRIV_EX" .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DRIV-EX, a two-stage counterfactual explanation method for LLM-based driving planners such as LC-LLM. Gradient descent optimizes continuous embeddings to flip the model's output decision on a scene description; these embeddings then serve only as a soft semantic guide for a subsequent controlled decoding step that regenerates fluent, domain-valid text. The method is evaluated on a textual transcription of the highD dataset and is claimed to produce valid, fluent counterfactuals more reliably than baselines while exposing latent biases in the planner.
Significance. If the central claim holds, DRIV-EX would provide a practical way to generate interpretable, minimal semantic perturbations for opaque LLM driving agents, directly supporting robustness analysis and bias detection. The two-stage design (gradient optimization followed by guided decoding) addresses a known failure mode of unconstrained embedding optimization, namely incoherent or invalid text, which is a genuine contribution if empirically validated.
major comments (2)
- [§3.2] §3.2 (Controlled Decoding): the pipeline description states that optimized embeddings bias the decoder but provides no mechanism or post-hoc check ensuring that the final discrete token sequence, once re-embedded, still lies on the flipped side of the LC-LLM decision boundary. This is load-bearing for the validity claim; modest drift during regeneration would invalidate the counterfactual.
- [§4] §4 (Evaluation): the reported superiority over baselines is presented without ablation isolating the contribution of the gradient-optimized embedding versus the controlled decoding alone, nor any error analysis of cases where the decision flip fails to transfer. This weakens attribution of the reliability gains.
minor comments (2)
- [§1] The abstract and §1 refer to 'parameter-free' aspects of the method, but the gradient optimization step implicitly depends on learning-rate and step-count hyperparameters; clarify the exact scope of this claim.
- [Figure 2] Figure 2 (example counterfactuals) would benefit from an additional column showing the LC-LLM output before and after the change to make the decision flip visually immediate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Controlled Decoding): the pipeline description states that optimized embeddings bias the decoder but provides no mechanism or post-hoc check ensuring that the final discrete token sequence, once re-embedded, still lies on the flipped side of the LC-LLM decision boundary. This is load-bearing for the validity claim; modest drift during regeneration would invalidate the counterfactual.
Authors: We agree that post-regeneration verification is essential for the validity claim. Our implementation already re-encodes each generated counterfactual and re-queries LC-LLM to confirm the decision flip; we will add an explicit description of this check in §3.2 together with the observed preservation rate (currently >92% on the highD transcriptions). This addition requires no change to the method itself. revision: yes
-
Referee: [§4] §4 (Evaluation): the reported superiority over baselines is presented without ablation isolating the contribution of the gradient-optimized embedding versus the controlled decoding alone, nor any error analysis of cases where the decision flip fails to transfer. This weakens attribution of the reliability gains.
Authors: We acknowledge the value of isolating component contributions. We will add an ablation in §4 comparing the full DRIV-EX pipeline against (i) controlled decoding guided only by the original (non-optimized) embeddings and (ii) unconstrained embedding optimization without the decoding stage. We will also include a dedicated error-analysis subsection reporting failure rates, common drift patterns, and representative examples where the flip does not transfer. These results will be generated from the same highD evaluation set. revision: yes
Circularity Check
No circularity: algorithmic pipeline evaluated on external data
full rationale
The derivation consists of an explicit two-stage procedure (gradient optimization on embeddings to locate a decision flip, followed by controlled decoding that uses the optimized embedding only as a soft bias). No equation or step is defined in terms of its own output, no fitted parameter is relabeled as a prediction, and no load-bearing claim rests on a self-citation. Evaluation uses an external highD transcription, so the central claim does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
arg min_x c(xo,x) s.t. y*_T = arg max ... (Eq. 1); L_dec(x) = −log P_M(y*_T | y_<T, x) (Eq. 3); Bi,v = −w·ri·||v−ProjE(ei)||² (Eq. 6)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat_induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
N=15 iterations of Adam on soft embeddings; biased decoding with fluency model F
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Xingang Guo, Fangxu Yu, Huan Zhang, Lianhui Qin, and Bin Hu
Association for Computational Linguistics. Xingang Guo, Fangxu Yu, Huan Zhang, Lianhui Qin, and Bin Hu. 2024. Cold-attack: Jailbreaking llms with stealthiness and controllability. InForty-first In- ternational Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenRe- view.net. Kai-Chieh Hsu, Karen Leung, Yuxiao Chen, Jaime F. F...
work page 2024
-
[2]
EMMA: end-to-end multimodal model for au- tonomous driving.Trans. Mach. Learn. Res., 2025. Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. 2024. Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end au- tonomous driving. InAdvances in Neural Infor- mation Processing Systems 38: Annual Conference on Neural Informa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Jiwei Li, Xinlei Chen, Eduard H
Association for Computational Linguistics. Jiwei Li, Xinlei Chen, Eduard H. Hovy, and Dan Ju- rafsky. 2016. Visualizing and understanding neural models in NLP. InNAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego California, USA, June 12-17, 2016, pages...
work page 2016
-
[4]
Xin Liu, Muhammad Khalifa, and Lu Wang
Association for Computational Linguistics. Xin Liu, Muhammad Khalifa, and Lu Wang. 2023. BOLT: fast energy-based controlled text generation with tunable biases. InProceedings of the 61st An- nual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 186–200. Association for Com...
work page 2023
-
[5]
GPT-Driver: Learning to Drive with GPT
Gpt-driver: Learning to drive with GPT. CoRR, abs/2310.01415. Harry Mayne, Ryan Othniel Kearns, Yushi Yang, An- drew M. Bean, Eoin D. Delaney, Chris Russell, and Adam Mahdi. 2025. Llms don’t know their own deci- sion boundaries: The unreliability of self-generated counterfactual explanations. InProceedings of the 2025 Conference on Empirical Methods in Na...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Fight back against jailbreaking via prompt ad- versarial tuning. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neu- ral Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Hosein Mohebbi, Ali Modarressi, and Moham- mad Taher Pilehvar. 2021. Exploring the role of BERT token repres...
-
[7]
Explaining NLP models via minimal con- trastive editing (mice). InFindings of the Associ- ation for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021, volume ACL/IJCNLP 2021 ofFindings of ACL, pages 3840–
work page 2021
-
[8]
Luke Rowe, Rodrigue de Schaetzen, Roger Girgis, Christopher Pal, and Liam Paull
Association for Computational Linguistics. Luke Rowe, Rodrigue de Schaetzen, Roger Girgis, Christopher Pal, and Liam Paull. 2025. Poutine: Vision-language-trajectory pre-training and reinforce- ment learning post-training enable robust end-to-end autonomous driving.CoRR, abs/2506.11234. Torsten Scholak, Nathan Schucher, and Dzmitry Bah- danau. 2021. PICAR...
-
[9]
Ari Seff, Brian Cera, Dian Chen, Mason Ng, Aurick Zhou, Nigamaa Nayakanti, Khaled S
Association for Computational Linguistics. Ari Seff, Brian Cera, Dian Chen, Mason Ng, Aurick Zhou, Nigamaa Nayakanti, Khaled S. Refaat, Rami Al-Rfou, and Benjamin Sapp. 2023. Motionlm: Multi-agent motion forecasting as language model- ing. InIEEE/CVF International Conference on Com- puter Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 8545–855...
work page 2023
-
[10]
Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR
Counterfactual explanations without opening the black box: Automated decisions and the GDPR. CoRR, abs/1711.00399. Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gard- ner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing NLP. InProceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing and the...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Gold- blum, Jonas Geiping, and Tom Goldstein
Jailbroken: How does LLM safety training fail? InNeurIPS 2023. Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Gold- blum, Jonas Geiping, and Tom Goldstein. 2023. Hard prompts made easy: Gradient-based discrete opti- mization for prompt tuning and discovery. InAd- vances in Neural Information Processing Systems 36: Annual Conference on Neural Information P...
-
[12]
WOD-E2E: waymo open dataset for end-to- end driving in challenging long-tail scenarios.CoRR, abs/2510.26125. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayi- heng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Ji- axi Yang, Jingren Zhou, Junyang Lin, Kai Dang, and 22 oth...
-
[13]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Association for Computational Linguistics. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Evalu- ating text generation with BERT. In8th International 13 Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenRe- view.net. Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao L...
work page internal anchor Pith review Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.