Recognition: no theorem link
Large Language Model-Enhanced Relational Operators: Taxonomy, Benchmark, and Analysis
Pith reviewed 2026-05-15 17:33 UTC · model grok-4.3
The pith
A unified taxonomy places LLM-enhanced relational operators into five categories and a benchmark of 350 queries identifies concrete design best practices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-Enhanced Relational Operators are defined as LLM calls that keep a strict relational input-output interface. The taxonomy sorts them into Select, Match, Impute, Cluster, and Order, each with listed operands and implementation variants. Evaluation on the 290 single-operator and 60 multi-operator queries of LROBench yields measurable performance differences across variants, from which the authors extract empirical best practices; these practices are then used to build an LRO suite that is compared directly against existing multi-operator systems on complex semantic workloads.
What carries the argument
The LRO taxonomy that aligns operators into Select, Match, Impute, Cluster and Order categories together with their operand and implementation variants, supported by the LROBench benchmark of 290 single-LRO and 60 multi-LRO queries across 27 databases.
If this is right
- Designers can select LRO implementations according to the measured performance differences for better accuracy or speed on individual tasks.
- Instantiating a multi-LRO system with the identified best practices yields higher end-to-end effectiveness on complex semantic queries than current systems.
- The five-category taxonomy supplies a consistent language for comparing and extending operators across different research efforts.
- Releasing the full benchmark data and evaluation code allows direct reproduction and extension of the reported measurements.
Where Pith is reading between the lines
- Adoption of the taxonomy could encourage database engines to expose standard interfaces for semantic operators rather than ad-hoc LLM calls.
- The same evaluation approach might be applied to measure how these operators behave under streaming or distributed execution settings.
- Hybrid query planners could treat the five LRO types as first-class algebraic operators when optimizing mixed relational and semantic workloads.
Load-bearing premise
The 290 single and 60 multi queries chosen for the benchmark adequately represent the full range of real-world semantic query needs and operating logics.
What would settle it
A fresh collection of semantic queries drawn from an additional domain that produces materially different performance rankings or best-practice recommendations would falsify the claim that the current benchmark results generalize.
Figures






read the original abstract
With the development of large language models (LLMs), numerous studies integrate LLMs through operator-like components to enhance relational data processing tasks, e.g., filters with semantic predicates, knowledge-augmented table imputation, reasoning-driven entity matching and more challenging semantic query processing. These components invoke LLMs while preserving a relational input/output interface, which we refer to as LLM-Enhanced Relational Operators (LROs). From an operator perspective, unfortunately, these existing LROs suffer from fragmented definition, various implementation strategies and inadequate evaluation benchmarks. To this end, in this paper, we first establish a unified LRO taxonomy to align existing LROs, and categorize them into: Select, Match, Impute, Cluster and Order, along with their operands and implementation variants. Second, we design LROBench, a comprehensive benchmark featuring 290 single-LRO queries and 60 multi-LRO queries, spanning 27 databases across more than 10 domains. LROBench covers all operating logics and operand granularities in its single-LRO workload, and provides challenging multi-LRO queries stratified by query complexity. Based on these, we evaluate individual LROs under various implementations, deriving practical insights into LRO design choices and summarizing our empirical best practices. We further compare the end-to-end performance of existing multi-LRO systems against an LRO suite instantiated with these best practices, in order to investigate how to design an effective LRO set for multi-LRO systems targeting complex semantic queries. Last, to facilitate future work, we outline promising future directions and open-source all benchmark data and evaluation code, available at https://github.com/LROBench/LROBench/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified taxonomy for LLM-Enhanced Relational Operators (LROs), categorizing them into Select, Match, Impute, Cluster, and Order along with their operands and implementation variants. It introduces LROBench, a benchmark with 290 single-LRO queries and 60 multi-LRO queries across 27 databases in more than 10 domains, which is asserted to cover all operating logics and operand granularities for single-LRO workloads. The work evaluates individual LRO implementations, derives empirical best practices, compares end-to-end performance of multi-LRO systems against an LRO suite using those practices, and open-sources the benchmark data and code.
Significance. If the benchmark coverage and evaluation results hold, the taxonomy and LROBench could standardize fragmented research on LLM-augmented relational operators, enabling reproducible comparisons and guiding design choices for semantic query processing. The open-sourcing of data, queries, and code is a clear strength that supports future work in this emerging area.
major comments (1)
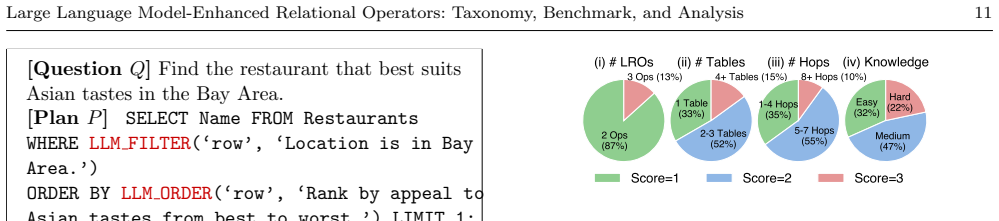
- [Abstract] Abstract and LROBench description: the claim that the 290 single-LRO queries 'cover all operating logics and operand granularities' is load-bearing for the taxonomy alignment and downstream best-practice recommendations, yet no formal enumeration of the logic space, sampling frame, or completeness argument is provided; queries are described as manually curated and stratified only by complexity, leaving open the possibility that sub-classes (e.g., multi-hop semantic predicates or domain-specific constraints) are underrepresented.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the benchmark construction. We address the major comment below and have prepared revisions to strengthen the presentation of LROBench coverage.
read point-by-point responses
-
Referee: [Abstract] Abstract and LROBench description: the claim that the 290 single-LRO queries 'cover all operating logics and operand granularities' is load-bearing for the taxonomy alignment and downstream best-practice recommendations, yet no formal enumeration of the logic space, sampling frame, or completeness argument is provided; queries are described as manually curated and stratified only by complexity, leaving open the possibility that sub-classes (e.g., multi-hop semantic predicates or domain-specific constraints) are underrepresented.
Authors: We agree that the original wording of the coverage claim was insufficiently justified. Section 3 defines the taxonomy by operator categories (Select, Match, Impute, Cluster, Order) together with operand types and granularities. The 290 queries were manually constructed by first enumerating the Cartesian product of these taxonomy dimensions and then instantiating each cell with representative examples drawn from the 27 databases. Stratification occurred along both operator type and complexity, not complexity alone. While a formal completeness proof is not possible for an open semantic space, we will add a new subsection (4.2) that explicitly lists the enumerated logic combinations, provides the sampling rationale, and includes a table mapping each taxonomy cell to the number of queries. We have also incorporated additional multi-hop predicate and domain-constraint examples into the released benchmark. The abstract claim will be revised to state that LROBench covers the operating logics and operand granularities defined by the taxonomy. These changes preserve the empirical results while addressing the concern directly. revision: partial
Circularity Check
No circularity in taxonomy or benchmark construction
full rationale
The paper surveys existing LLM-enhanced operators from the literature to establish a taxonomy (Select/Match/Impute/Cluster/Order), then manually curates 290 single-LRO and 60 multi-LRO queries stratified by complexity across 27 databases. No equations, parameter fitting, predictions, or self-citation chains appear in the central claims. The coverage assertion follows directly from the taxonomy categories rather than reducing to a self-definitional loop or fitted input. All benchmark data and code are open-sourced, making the work externally verifiable without internal circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs invoked via operator-like components preserve relational input/output interfaces while adding semantic capabilities
invented entities (1)
-
LRO (LLM-Enhanced Relational Operator)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
OmniTQA: A Cost-Aware System for Hybrid Query Processing over Semi-Structured Data
OmniTQA integrates LLM semantic reasoning as a first-class query operator with classical relational operators in a cost-aware planner for hybrid structured and semi-structured data.
Reference graph
Works this paper leans on
-
[1]
Alibaba: Qwen3 technical report. CoRRabs/2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: NeurIPS Datasets and Benchmarks (2021)
Aly, R., Guo, Z., Schlichtkrull, M.S., Thorne, J., Vla- chos, A., Christodoulopoulos, C., Cocarascu, O., Mittal, A.: FEVEROUS: fact extraction and verification over unstructured and structured information. In: NeurIPS Datasets and Benchmarks (2021)
work page 2021
-
[3]
Anderson, E., Fritz, J., Lee, A., Li, B., Lindblad, M., Lindeman, H., Meyer, A., Parmar, P., Ranade, T., Shah, M.A., Sowell, B., Tecuci, D., Thapliyal, V., Welsh, M.: The design of an llm-powered unstructured analytics system. CoRRabs/2409.00847(2024)
-
[4]
URL https://www.anthropic.com/news/claude-sonnet-4-5
Anthropic: Introducing claude sonnet 4.5 (2025). URL https://www.anthropic.com/news/claude-sonnet-4-5
work page 2025
-
[5]
arXiv preprint arXiv:2408.14717 (2024)
Biswal, A., Patel, L., Jha, S., Kamsetty, A., Liu, S., Gonzalez, J.E., Guestrin, C., Zaharia, M.: Text2sql is not enough: Unifying ai and databases with tag. arXiv preprint arXiv:2408.14717 (2024)
-
[6]
BEAVER: An Enterprise Benchmark for Text-to-SQL
Chen, P.B., Wenz, F., Zhang, Y., Kayali, M., Tat- bul, N., Cafarella, M.J., Demiralp, C ¸., Stonebraker, M.: BEAVER: an enterprise benchmark for text-to-sql. CoRR abs/2409.02038(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [7]
- [8]
-
[9]
In: EMNLP (Findings), Findings of ACL, vol
Chen, W., Zha, H., Chen, Z., Xiong, W., Wang, H., Wang, W.Y.: Hybridqa: A dataset of multi-hop question answer- ing over tabular and textual data. In: EMNLP (Findings), Findings of ACL, vol. EMNLP 2020, pp. 1026–1036. Asso- ciation for Computational Linguistics (2020)
work page 2020
- [10]
-
[11]
Cremonesi, P., Koren, Y., Turrin, R.: Performance of recommender algorithms on top-n recommendation tasks. In: RecSys, pp. 39–46. ACM (2010)
work page 2010
-
[12]
C., P.S., Gokhale, C., Konda, P., Govind, Y., Paulsen, D.: The magellan data repository
Das, S., Doan, A., G. C., P.S., Gokhale, C., Konda, P., Govind, Y., Paulsen, D.: The magellan data repository. https://sites.google.com/site/anhaidgroup/ projects/data
-
[13]
Dong, X., Zhang, C., Ge, Y., Mao, Y., Gao, Y., Chen, L., Lin, J., Lou, D.: C3: zero-shot text-to-sql with chatgpt. CoRRabs/2307.07306(2023)
-
[14]
Elmasri, R., Navathe, S.B.: Fundamentals of Database Systems, 3rd Edition. Addison-Wesley-Longman (2000)
work page 2000
-
[15]
Flores, J., Nadal, S., Romero, O.: Towards scalable data discovery. In: EDBT, pp. 433–438. OpenProceedings.org (2021)
work page 2021
-
[16]
Gan, Y., Chen, X., Purver, M.: Re-appraising the schema linking for text-to-sql. In: ACL (Findings), pp. 835–852. Association for Computational Linguistics (2023)
work page 2023
-
[17]
Glenn, P., Dakle, P., Wang, L., Raghavan, P.: Blendsql: A scalable dialect for unifying hybrid question answering in relational algebra. In: ACL (Findings), pp. 453–466. Association for Computational Linguistics (2024)
work page 2024
-
[18]
He, X., Ban, Y., Zou, J., Wei, T., Cook, C.B., He, J.: Llm- forest: Ensemble learning of llms with graph-augmented prompts for data imputation. In: ACL (Findings), pp. 6921–6936. Association for Computational Linguistics (2025)
work page 2025
-
[19]
Huang, Z., Wu, E.: Relationalizing tables with large lan- guage models: The promise and challenges. In: ICDEW, pp. 305–309. IEEE (2024)
work page 2024
-
[20]
Journal of classification2(1), 193–218 (1985)
Hubert, L., Arabie, P.: Comparing partitions. Journal of classification2(1), 193–218 (1985)
work page 1985
-
[21]
Jin, T., Zhu, Y., Kang, D.: Elt-bench: An end-to-end benchmark for evaluating AI agents on ELT pipelines. CoRRabs/2504.04808(2025)
-
[22]
Jo, S., Trummer, I.: Thalamusdb: Approximate query processing on multi-modal data. Proc. ACM Manag. Data2(3), 186 (2024)
work page 2024
-
[23]
Katsogiannis-Meimarakis, G., Mirylenka, K., Scotton, P., Fusco, F., Labbi, A.: In-depth analysis of llm-based schema linking. In: EDBT, pp. 117–130. OpenProceed- ings.org (2026)
work page 2026
-
[24]
Biometrika30(1-2), 81–93 (1938)
Kendall, M.G.: A new measure of rank correlation. Biometrika30(1-2), 81–93 (1938)
work page 1938
-
[25]
Khatiwada, A., Fan, G., Shraga, R., Chen, Z., Gat- terbauer, W., Miller, R.J., Riedewald, M.: SANTOS: relationship-based semantic table union search. Proc. ACM Manag. Data1(1), 9:1–9:25 (2023)
work page 2023
-
[26]
Lao, J., Zimmerer, A., Ovcharenko, O., Cong, T., Russo, M., Vitagliano, G., Cochez, M., ¨Ozcan, F., Gupta, G., Hottelier, T., Jagadish, H.V., Kissel, K., Schelter, S., Kipf, A., Trummer, I.: Sembench: A benchmark for semantic query processing engines. CoRRabs/2511.01716(2025)
- [27]
-
[28]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K¨ uttler, H., Lewis, M., Yih, W., Rockt¨ aschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive NLP tasks. In: NeurIPS (2020)
work page 2020
-
[29]
In: WWW (Companion Volume), pp
Li, H., Li, S., Hao, F., Zhang, C.J., Song, Y., Chen, L.: Booster: Leveraging large language models for enhancing entity resolution. In: WWW (Companion Volume), pp. 1043–1046. ACM (2024)
work page 2024
-
[30]
Li, H., Zhang, J., Li, C., Chen, H.: RESDSQL: decoupling schema linking and skeleton parsing for text-to-sql. In: AAAI, pp. 13,067–13,075. AAAI Press (2023)
work page 2023
-
[31]
Li, J., Hui, B., Qu, G., Yang, J., Li, B., Li, B., Wang, B., Qin, B., Geng, R., Huo, N., Zhou, X., Ma, C., Li, G., Chang, K.C., Huang, F., Cheng, R., Li, Y.: Can LLM already serve as A database interface? A big bench for large-scale database grounded text-to-sqls. In: NeurIPS (2023)
work page 2023
-
[32]
Li, P., He, Y., Yashar, D., Cui, W., Ge, S., Zhang, H., Fainman, D.R., Zhang, D., Chaudhuri, S.: Table-gpt: Ta- ble fine-tuned GPT for diverse table tasks. Proc. ACM Manag. Data2(3), 176 (2024)
work page 2024
-
[33]
Lin, Y., Hulsebos, M., Ma, R., Shankar, S., Zeighami, S., Parameswaran, A.G., Wu, E.: Towards accurate and efficient document analytics with large language models. CoRRabs/2405.04674(2024)
-
[34]
In: Proceed- ings of the Conference on Innovative Database Research (CIDR)
Liu, C., Russo, M., Cafarella, M., Cao, L., Chen, P.B., Chen, Z., Franklin, M., Kraska, T., Madden, S., Shahout, R., Vitagliano, G.: Palimpzest: Optimizing ai-powered analytics with declarative query processing. In: Proceed- ings of the Conference on Innovative Database Research (CIDR)
-
[35]
Liu, G., Tan, Y., Zhong, R., Xie, Y., Zhao, L., Wang, Q., Hu, B., Li, Z.: Solid-sql: Enhanced schema-linking based in-context learning for robust text-to-sql. In: COLING, pp. 9793–9803. Association for Computational Linguistics (2025) 22 Su et al
work page 2025
-
[36]
Liu, S., Xu, J., Tjangnaka, W., Semnani, S.J., Yu, C.J., Lam, M.: SUQL: conversational search over structured and unstructured data with large language models. In: NAACL-HLT (Findings), pp. 4535–4555. Association for Computational Linguistics (2024)
work page 2024
-
[37]
Ma, L., Thakurdesai, N., Chen, J., Xu, J., K¨ orpeoglu, E., Kumar, S., Achan, K.: Llms with user-defined prompts as generic data operators for reliable data processing. In: IEEE Big Data, pp. 3144–3148. IEEE (2023)
work page 2023
-
[38]
VLDB Endow.16(4), 738–746 (2022)
Narayan, A., Chami, I., Orr, L.J., R´ e, C.: Can foundation models wrangle your data? Proc. VLDB Endow.16(4), 738–746 (2022)
work page 2022
- [39]
-
[40]
Patel, L., Jha, S., Pan, M.Z., Gupta, H., Asawa, P., Guestrin, C., Zaharia, M.: Semantic operators and their optimization: Towards ai-based data analytics with accu- racy guarantees. Proc. VLDB Endow.18(11), 4171–4184 (2025)
work page 2025
-
[41]
Peeters, R., Steiner, A., Bizer, C.: Entity matching using large language models. In: EDBT, pp. 529–541. OpenPro- ceedings.org (2025)
work page 2025
-
[42]
¨O.: CHASE-SQL: multi-path reasoning and preference opti- mized candidate selection in text-to-sql
Pourreza, M., Li, H., Sun, R., Chung, Y., Talaei, S., Kakkar, G.T., Gan, Y., Saberi, A., Ozcan, F., Arik, S. ¨O.: CHASE-SQL: multi-path reasoning and preference opti- mized candidate selection in text-to-sql. In: ICLR. Open- Review.net (2025)
work page 2025
-
[43]
Pourreza, M., Rafiei, D.: DIN-SQL: decomposed in- context learning of text-to-sql with self-correction. In: NeurIPS (2023)
work page 2023
- [44]
-
[45]
Qiu, Z., Peng, Y., He, G., Yuan, B., Wang, C.: Tqa- bench: Evaluating llms for multi-table question answering with scalable context and symbolic extension. CoRR abs/2411.19504(2024)
-
[46]
Russo, M., Sudhir, S., Vitagliano, G., Liu, C., Kraska, T., Madden, S., Cafarella, M.J.: Abacus: A cost- based optimizer for semantic operator systems. CoRR abs/2505.14661(2025)
-
[47]
Selinger, P.G., Astrahan, M.M., Chamberlin, D.D., Lorie, R.A., Price, T.G.: Access path selection in a relational database management system. In: SIGMOD Conference, pp. 23–34. ACM (1979)
work page 1979
-
[48]
Shankar, S., Chambers, T., Shah, T., Parameswaran, A.G., Wu, E.: Docetl: Agentic query rewriting and evaluation for complex document processing. Proc. VLDB Endow. 18(9), 3035–3048 (2025)
work page 2025
-
[49]
Steiner, A., Peeters, R., Bizer, C.: Fine-tuning large lan- guage models for entity matching. In: ICDEW, pp. 9–17. IEEE (2025)
work page 2025
-
[50]
Strehl, A., Ghosh, J.: Cluster ensembles — A knowledge reuse framework for combining multiple partitions. J. Mach. Learn. Res.3, 583–617 (2002)
work page 2002
-
[51]
Sun, Z., Chai, C., Deng, Q., Jin, K., Guo, X., Han, H., Yuan, Y., Wang, G., Cao, L.: QUEST: query optimization in unstructured document analysis. Proc. VLDB Endow. 18(11), 4560–4573 (2025)
work page 2025
-
[52]
Thorne, J., Vlachos, A., Christodoulopoulos, C., Mittal, A.: FEVER: a large-scale dataset for fact extraction and verification. In: NAACL-HLT, pp. 809–819. Association for Computational Linguistics (2018)
work page 2018
- [53]
-
[54]
Wang, B., Ren, C., Yang, J., Liang, X., Bai, J., Chai, L., Yan, Z., Zhang, Q., Yin, D., Sun, X., Li, Z.: MAC-SQL: A multi-agent collaborative framework for text-to-sql. In: COLING, pp. 540–557. Association for Computational Linguistics (2025)
work page 2025
-
[55]
Wang, T., Chen, X., Lin, H., Chen, X., Han, X., Sun, L., Wang, H., Zeng, Z.: Match, compare, or select? an investigation of large language models for entity matching. In: COLING, pp. 96–109. Association for Computational Linguistics (2025)
work page 2025
- [56]
-
[57]
Yu, T., Zhang, R., Yang, K., Yasunaga, M., Wang, D., Li, Z., Ma, J., Li, I., Yao, Q., Roman, S., Zhang, Z., Radev, D.R.: Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text- to-sql task. In: EMNLP, pp. 3911–3921. Association for Computational Linguistics (2018)
work page 2018
-
[58]
Zhang, H., Dong, Y., Xiao, C., Oyamada, M.: Large lan- guage models as data preprocessors. In: VLDB Workshops. VLDB.org (2024)
work page 2024
-
[59]
Zhao, F., Agrawal, D., Abbadi, A.E.: Hybrid querying over relational databases and large language models. CoRR abs/2408.00884(2024)
-
[60]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Zhong, V., Xiong, C., Socher, R.: Seq2sql: Generating structured queries from natural language using reinforce- ment learning. CoRRabs/1709.00103(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.