Recognition: 2 theorem links
· Lean TheoremImplicit Bias in Deep Linear Discriminant Analysis
Pith reviewed 2026-05-15 16:45 UTC · model grok-4.3
The pith
Deep LDA on diagonal linear networks transforms additive gradient updates into multiplicative ones under balanced initialization, conserving the (2/L) quasi-norm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
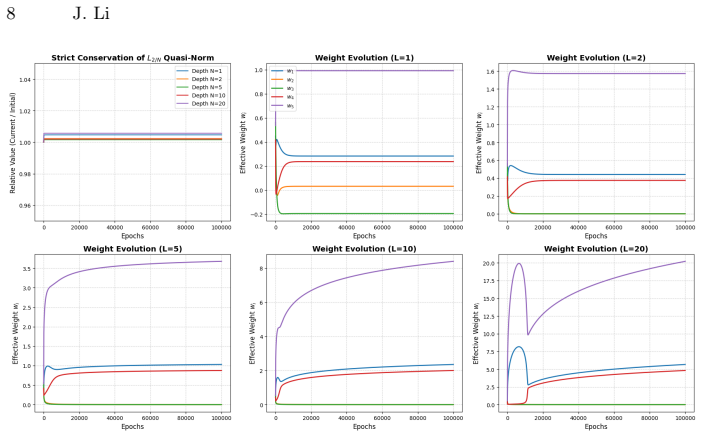
By analyzing the gradient flow of the loss on a L-layer diagonal linear network, we prove that under balanced initialization, the network architecture transforms standard additive gradient updates into multiplicative weight updates, which demonstrates an automatic conservation of the (2/L) quasi-norm.
What carries the argument
the network-induced conversion of additive gradient updates into multiplicative weight updates under balanced initialization, which enforces conservation of the (2/L) quasi-norm
If this is right
- Additive gradient steps become multiplicative, changing the trajectory of weight evolution during training.
- The (2/L) quasi-norm is preserved automatically as a direct consequence of the architecture and initialization.
- Solutions reached by Deep LDA inherit structural bias toward vectors whose effective (2/L) quasi-norm matches the conserved value.
- The implicit bias is tied to the scale-invariant nature of the Deep LDA objective in this specific network class.
Where Pith is reading between the lines
- If the multiplicative-update property extends to deeper or non-linear networks, it could predict similar quasi-norm conservation in practical LDA-based classifiers.
- Comparing training dynamics on diagonal versus full linear layers would isolate whether the conservation effect is truly architecture-specific.
- The same gradient-flow analysis might apply to other scale-invariant losses, revealing a broader family of implicit quasi-norm biases.
Load-bearing premise
The claimed transformation to multiplicative updates and quasi-norm conservation requires both balanced initialization and a network composed only of diagonal linear layers.
What would settle it
Observe whether the (2/L) quasi-norm stays constant when gradient descent is run on the same Deep LDA loss but with either unbalanced initialization or at least one non-diagonal linear layer.
Figures


read the original abstract
While the Implicit Bias(or Implicit Regularization) of standard loss functions has been studied, the optimization geometry induced by discriminative metric-learning objectives remains largely unexplored.To the best of our knowledge, this paper presents an initial theoretical analysis of the implicit regularization induced by the Deep LDA,a scale invariant objective designed to minimize intraclass variance and maximize interclass distance. By analyzing the gradient flow of the loss on a L-layer diagonal linear network, we prove that under balanced initialization, the network architecture transforms standard additive gradient updates into multiplicative weight updates, which demonstrates an automatic conservation of the (2/L) quasi-norm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the implicit bias of the Deep LDA objective, a scale-invariant loss that minimizes intra-class variance and maximizes inter-class distance. Focusing on gradient flow for an L-layer diagonal linear network under balanced initialization, it proves that the architecture converts standard additive gradient updates into multiplicative weight updates, which algebraically implies automatic conservation of the (2/L) quasi-norm.
Significance. If the derivation holds within its stated scope, the result supplies a concrete mechanism by which network architecture and initialization interact with a discriminative metric-learning loss to produce implicit quasi-norm regularization. This extends the literature on implicit bias beyond cross-entropy or squared-loss settings and offers a parameter-free conservation law that could inform the design of scale-invariant deep models.
minor comments (2)
- [Abstract] Abstract: the phrase 'Deep LDA' is used without a one-sentence definition of the objective; adding a brief parenthetical description would improve accessibility for readers outside the immediate subfield.
- [Discussion] The manuscript should explicitly state whether the (2/L) quasi-norm conservation is exact only for perfectly diagonal layers or holds approximately under small off-diagonal perturbations; a short remark or remark in the discussion would clarify the robustness of the claim.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The referee's summary correctly captures our main result on the conversion of additive updates to multiplicative updates under balanced initialization for the Deep LDA objective, leading to conservation of the (2/L) quasi-norm.
Circularity Check
No significant circularity; derivation is algebraic consequence of gradient flow under stated assumptions
full rationale
The paper's central claim is a direct proof that, for an L-layer diagonal linear network under balanced initialization, the gradient flow of the Deep LDA loss converts additive updates into multiplicative ones, yielding conservation of the (2/L) quasi-norm. This follows from the explicit structure of the diagonal layers and the balanced-init condition applied to the continuous-time gradient-flow ODEs. No fitted parameters are renamed as predictions, no self-citations bear the load of the uniqueness or transformation step, and the result is scoped precisely to the model class where the algebra holds. The derivation is therefore self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Gradient flow governs the continuous-time dynamics of the Deep LDA loss
- ad hoc to paper Weights satisfy balanced initialization
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By analyzing the gradient flow of the loss on a L-layer diagonal linear network, we prove that under balanced initialization, the network architecture transforms standard additive gradient updates into multiplicative weight updates, which demonstrates an automatic conservation of the (2/L) quasi-norm.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.equivNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
d/dt sum_i w_i^{2/L} = -2 w^T grad L(w) = 0 by scale invariance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
UCI Machine Learning Repository (1992)
Aeberhard, S., Forina, M.: Wine. UCI Machine Learning Repository (1992). https://doi.org/10.24432/C5PC7J
-
[2]
Berthier, R.: Incremental learning in diagonal linear networks. J. Mach. Learn. Res.24(1) (Jan 2023)
work page 2023
-
[3]
Deep Linear Discriminant Analysis
Dorfer, M., Kelz, R., Widmer, G.: Deep linear discriminant analysis (2015). https://doi.org/10.48550/ARXIV.1511.04707, https://arxiv.org/abs/1511.04707
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1511.04707 2015
-
[4]
Annals of Eugenics7(2), 179–188 (1936)
FISHER, R.A.: The use of multiple measurements in taxonomic problems. Annals of Eugenics7(2), 179–188 (1936). https://doi.org/https://doi.org/10.1111/j.1469- 1809.1936.tb02137.x 12 J. Li
-
[5]
Golub,G.H.,VanLoan,C.F.:MatrixComputations.TheJohnsHopkinsUniversity Press, 4th edn. (2013)
work page 2013
-
[6]
In: Proceedings of the 32nd International Con- ference on Neural Information Processing Systems
Gunasekar, S., Lee, J.D., Soudry, D., Srebro, N.: Implicit bias of gradient descent on linear convolutional networks. In: Proceedings of the 32nd International Con- ference on Neural Information Processing Systems. p. 9482–9491. NIPS’18, Curran Associates Inc., Red Hook, NY, USA (2018)
work page 2018
-
[7]
In: Proceedings of the 31st Inter- national Conference on Neural Information Processing Systems
Gunasekar, S., Woodworth, B., Bhojanapalli, S., Neyshabur, B., Srebro, N.: Im- plicit regularization in matrix factorization. In: Proceedings of the 31st Inter- national Conference on Neural Information Processing Systems. p. 6152–6160. NIPS’17, Curran Associates Inc., Red Hook, NY, USA (2017)
work page 2017
-
[8]
Proceedings of the IEEE84(6), 907 (Jun 1996)
Helmke, U., Moore, J.: Optimization and dynamical systems. Proceedings of the IEEE84(6), 907 (Jun 1996). https://doi.org/10.1109/jproc.1996.503147, http://dx.doi.org/10.1109/JPROC.1996.503147
-
[9]
Proceedings of the National Academy of Sci- ences79(8), 2554–2558 (Apr 1982)
Hopfield, J.J.: Neural networks and physical systems with emergent collec- tive computational abilities. Proceedings of the National Academy of Sci- ences79(8), 2554–2558 (Apr 1982). https://doi.org/10.1073/pnas.79.8.2554, http://dx.doi.org/10.1073/pnas.79.8.2554
-
[10]
Gradient descent aligns the layers of deep linear networks
Ji, Z., Telgarsky, M.: Gradient descent aligns the layers of deep linear networks (2018). https://doi.org/10.48550/ARXIV.1810.02032, https://arxiv.org/abs/1810.02032
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.02032 2018
-
[11]
Gradient descent maximizes the margin of homogeneous neural networks
Lyu, K., Li, J.: Gradient descent maximizes the margin of homoge- neous neural networks (2019). https://doi.org/10.48550/ARXIV.1906.05890, https://arxiv.org/abs/1906.05890
-
[12]
Proceedings of the National Academy of Sciences117(40), 24652–24663 (2020)
Papyan, V., Han, X.Y., Donoho, D.L.: Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences117(40), 24652–24663 (2020). https://doi.org/10.1073/pnas.2015509117, https://www.pnas.org/doi/abs/10.1073/pnas.2015509117
-
[13]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Razin, N., Cohen, N.: Implicit regularization in deep learning may not be explain- able by norms. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY, USA (2020)
work page 2020
-
[14]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Saxe, A.M., McClelland, J.L., Ganguli, S.: Exact solutions to the non- linear dynamics of learning in deep linear neural networks (2013). https://doi.org/10.48550/ARXIV.1312.6120, https://arxiv.org/abs/1312.6120
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.6120 2013
-
[15]
Soudry, D., Hoffer, E., Nacson, M.S., Gunasekar, S., Srebro, N.: The implicit bias of gradient descent on separable data. J. Mach. Learn. Res.19(1), 2822–2878 (Jan 2018)
work page 2018
-
[16]
Street, W.N., Wolberg, W.H., Mangasarian, O.L.: Nuclear feature extraction for breast tumor diagnosis. Proc. SPIE1905, 861–870 (1993)
work page 1993
-
[17]
Bioinformatics Ad- vances4(1) (Jan 2024)
Wang, J., Safo, S.E.: Deep ida: a deep learning approach for integrative discriminant analysis of multi-omics data with fea- ture ranking—an application to covid-19. Bioinformatics Ad- vances4(1) (Jan 2024). https://doi.org/10.1093/bioadv/vbae060, http://dx.doi.org/10.1093/bioadv/vbae060
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.