Recognition: 2 theorem links
· Lean TheoremRhythm: Learning Interactive Whole-Body Control for Dual Humanoids
Pith reviewed 2026-05-15 17:08 UTC · model grok-4.3
The pith
Rhythm framework enables real-world interactive whole-body control for dual humanoid robots by transferring behaviors like hugging and dancing from simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that integrating an Interaction-Aware Motion Retargeting module to produce kinematically feasible references from human data, an Interaction-Guided Reinforcement Learning policy that masters coupled dynamics via graph-based rewards, and a real-world deployment system achieves robust transfer of diverse interactive behaviors such as hugging and dancing from simulation to physical dual-humanoid systems.
What carries the argument
The Interaction-Aware Motion Retargeting (IAMR) module that converts human interaction data into feasible dual-humanoid references, paired with the Interaction-Guided Reinforcement Learning (IGRL) policy that uses graph-based rewards to handle coupled contact dynamics.
Load-bearing premise
The retargeted motion references remain kinematically feasible and dynamically stable when the robots experience real contact forces and sensor noise on physical hardware.
What would settle it
Repeated real-world trials in which the dual robots fail to complete a hugging or dancing sequence without falling, exceeding joint limits, or losing balance under contact.
Figures





read the original abstract
Realizing interactive whole-body control for multi-humanoid systems is critical for unlocking complex collaborative capabilities in shared environments. Although recent advancements have significantly enhanced the agility of individual robots, bridging the gap to physically coupled multi-humanoid interaction remains challenging, primarily due to severe kinematic mismatches and complex contact dynamics. To address this, we introduce Rhythm, the first unified framework enabling real-world deployment of dual-humanoid systems for complex, physically plausible interactions. Our framework integrates three core components: (1) an Interaction-Aware Motion Retargeting (IAMR) module that generates feasible humanoid interaction references from human data; (2) an Interaction-Guided Reinforcement Learning (IGRL) policy that masters coupled dynamics via graph-based rewards; and (3) a real-world deployment system that enables robust transfer of dual-humanoid interaction. Extensive experiments on physical Unitree G1 robots demonstrate that our framework achieves robust interactive whole-body control, successfully transferring diverse behaviors such as hugging and dancing from simulation to reality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Rhythm framework for interactive whole-body control of dual-humanoid systems. It comprises an Interaction-Aware Motion Retargeting (IAMR) module that generates kinematically feasible references from human data, an Interaction-Guided Reinforcement Learning (IGRL) policy that learns coupled dynamics using graph-based rewards, and a real-world deployment system. The central claim is that this unified approach enables robust sim-to-real transfer of complex physically coupled behaviors such as hugging and dancing on physical Unitree G1 robots, as shown via extensive experiments.
Significance. If the hardware results hold under quantitative scrutiny, the work would advance multi-robot collaboration by addressing kinematic mismatches and contact dynamics in shared environments, an important gap beyond single-robot agility. The graph-reward formulation in IGRL and the IAMR retargeting represent a coherent technical integration worth further study in the field.
major comments (3)
- [Abstract] Abstract: the assertion of 'robust interactive whole-body control' and 'successful transferring' of hugging and dancing rests on 'extensive experiments' yet supplies no trial counts, success rates, force-tracking errors, baseline comparisons, or failure-mode statistics, leaving the central sim-to-real claim unquantified and difficult to assess.
- [IAMR module and deployment system] IAMR module and deployment system: the assumption that IAMR produces references stable under real contact forces, latency, and sensor noise on Unitree G1 hardware is load-bearing for the transfer claim but is stated without supporting analysis, error metrics, or ablation on kinematic feasibility under dynamics mismatch.
- [IGRL policy] IGRL policy: the graph-based reward formulation is presented as key to mastering coupled dynamics, but the manuscript provides no ablations, sensitivity analysis on reward weights, or comparisons showing its contribution relative to standard RL objectives.
minor comments (2)
- [Methods] Notation for graph reward weights and interaction terms should be defined with explicit equations or pseudocode in the methods to support reproducibility.
- [Figures] Figure captions describing real-robot trials would benefit from added quantitative labels (e.g., number of successful runs) even if detailed tables appear elsewhere.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating revisions where we have strengthened the presentation of results and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'robust interactive whole-body control' and 'successful transferring' of hugging and dancing rests on 'extensive experiments' yet supplies no trial counts, success rates, force-tracking errors, baseline comparisons, or failure-mode statistics, leaving the central sim-to-real claim unquantified and difficult to assess.
Authors: We agree that the abstract would be strengthened by explicit quantitative support. In the revised manuscript we have updated the abstract to reference the key metrics already reported in the experiments section (trial counts, success rates for hugging and dancing, and baseline comparisons) and added a concise summary of failure-mode statistics. This makes the central sim-to-real claim directly quantifiable without altering the underlying experimental results. revision: yes
-
Referee: [IAMR module and deployment system] IAMR module and deployment system: the assumption that IAMR produces references stable under real contact forces, latency, and sensor noise on Unitree G1 hardware is load-bearing for the transfer claim but is stated without supporting analysis, error metrics, or ablation on kinematic feasibility under dynamics mismatch.
Authors: We acknowledge that the original manuscript provided limited quantitative backing for IAMR stability under real-world conditions. We have added retargeting error metrics, an ablation on kinematic feasibility under simulated dynamics mismatch, and a new discussion of latency and sensor noise effects observed during deployment. Full quantitative force-tracking under contact remains limited by our current hardware instrumentation; we have therefore added an explicit limitations paragraph while retaining the qualitative success of the deployed interactions as supporting evidence. revision: partial
-
Referee: [IGRL policy] IGRL policy: the graph-based reward formulation is presented as key to mastering coupled dynamics, but the manuscript provides no ablations, sensitivity analysis on reward weights, or comparisons showing its contribution relative to standard RL objectives.
Authors: We agree that ablations and comparisons would better isolate the contribution of the graph-based rewards. In the revised manuscript we have moved the existing ablation studies from the supplement into the main text, added sensitivity analysis on reward weights, and included direct comparisons against standard RL objectives (dense reward without graph structure). These additions demonstrate the performance gain attributable to the interaction-guided formulation. revision: yes
Circularity Check
No circularity: claims rest on empirical sim-to-real experiments without self-referential derivations or fitted predictions
full rationale
The paper presents a three-component framework (IAMR for retargeting, IGRL for policy learning via graph rewards, and a deployment system) whose central claim of robust dual-humanoid interaction transfer is asserted via 'extensive experiments' on Unitree G1 robots. No equations, uniqueness theorems, or ansatzes are supplied in the text that reduce reported success metrics to quantities defined by the same fitted parameters or prior self-citations. The derivation chain is therefore self-contained as an empirical engineering contribution rather than a closed mathematical loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- graph reward weights
axioms (1)
- domain assumption Graph-based rewards suffice to master coupled contact dynamics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IAMR ... Interaction Mesh ... Laplacian coordinates ... Eself + Einter ... distance-aware dynamic weighting ωij(dij)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
graph-based rewards r_inter ... r_contact ... Contact Graph ... Interaction Graph
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
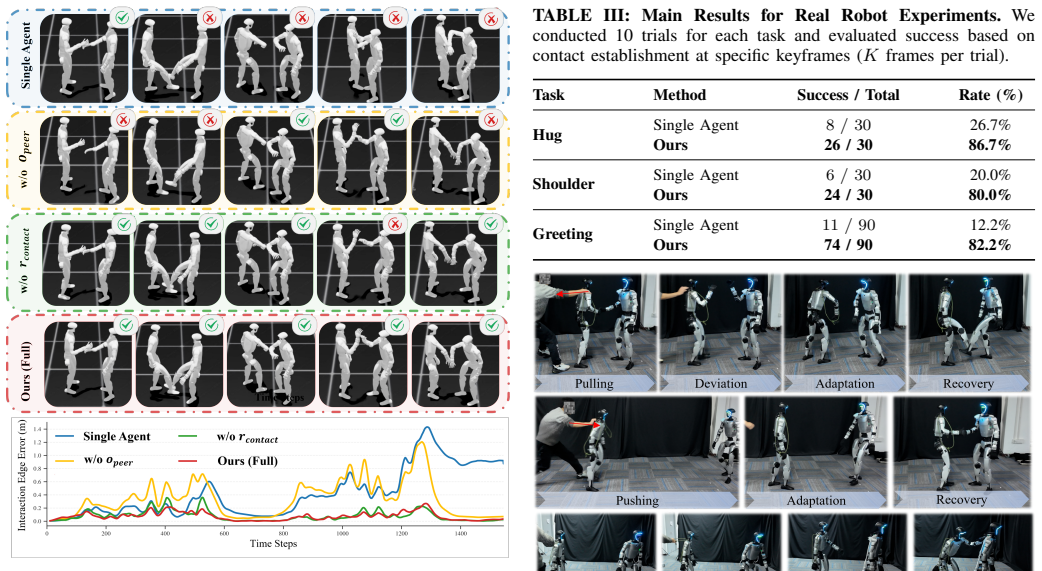
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marc Alexa. Differential coordinates for local mesh morphing and deformation.The Visual Computer, 19 (2):105–114, 2003
work page 2003
-
[2]
Visual imitation enables contextual humanoid control
Arthur Allshire, Hongsuk Choi, Junyi Zhang, David McAllister, Anthony Zhang, Chung Min Kim, Trevor Darrell, Pieter Abbeel, Jitendra Malik, and Angjoo Kanazawa. Visual imitation enables contextual humanoid control. InConference on Robot Learning, 2025
work page 2025
- [3]
-
[4]
HOMIE: Humanoid loco- manipulation with isomorphic exoskeleton cockpit
Qingwei Ben, Feiyu Jia, Jia Zeng, Junting Dong, Dahua Lin, and Jiangmiao Pang. HOMIE: Humanoid loco- manipulation with isomorphic exoskeleton cockpit. In Robotics: Science and Systems, 2025
work page 2025
-
[5]
Longbing Cao. Humanoid robots and humanoid ai: Review, perspectives and directions.ACM Computing Surveys, 58(4):1–37, 2025
work page 2025
-
[6]
Symbridge: A human-in-the-loop cyber-physical interactive system for adaptive human- robot symbiosis
Haoran Chen, Yiteng Xu, Yiming Ren, Yaoqin Ye, Xin- ran Li, Ning Ding, Yuxuan Wu, Yaoze Liu, Peishan Cong, Ziyi Wang, et al. Symbridge: A human-in-the-loop cyber-physical interactive system for adaptive human- robot symbiosis. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025
work page 2025
-
[7]
Gmt: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
Zixuan Chen, Mazeyu Ji, Xuxin Cheng, Xuanbin Peng, Xue Bin Peng, and Xiaolong Wang. GMT: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
-
[8]
Expressive whole-body control for humanoid robots
Xuxin Cheng, Yandong Ji, Junming Chen, Ruihan Yang, Ge Yang, and Xiaolong Wang. Expressive whole-body control for humanoid robots. InRobotics: Science and Systems, 2024
work page 2024
-
[9]
Yushi Du, Yixuan Li, Baoxiong Jia, Yutang Lin, Pei Zhou, Wei Liang, Yanchao Yang, and Siyuan Huang. Learning human-humanoid coordination for collaborative object carrying.arXiv preprint arXiv:2510.14293, 2025
-
[10]
CooHOI: Learning cooperative human- object interaction with manipulated object dynamics
Jiawei Gao, Ziqin Wang, Zeqi Xiao, Jingbo Wang, Tai Wang, Jinkun Cao, Xiaolin Hu, Si Liu, Jifeng Dai, and Jiangmiao Pang. CooHOI: Learning cooperative human- object interaction with manipulated object dynamics. Advances in Neural Information Processing Systems, 37: 79741–79763, 2024
work page 2024
-
[11]
ReMoS: 3D motion-conditioned reaction synthesis for two-person in- teractions
Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Christian Theobalt, and Philipp Slusallek. ReMoS: 3D motion-conditioned reaction synthesis for two-person in- teractions. InEuropean Conference on Computer Vision (ECCV), 2024
work page 2024
-
[12]
Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning
Xinyang Gu, Yen-Jen Wang, Xiang Zhu, Chengming Shi, Yanjiang Guo, Yichen Liu, and Jianyu Chen. Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning. InRobotics: Science and Systems, 2024
work page 2024
-
[13]
Jinrui Han, Weiji Xie, Jiakun Zheng, Jiyuan Shi, Weinan Zhang, Ting Xiao, and Chenjia Bai. KungfuBot2: Learn- ing versatile motion skills for humanoid whole-body control.arXiv preprint arXiv:2509.16638, 2025
-
[14]
Point-LIO: robust high- bandwidth light detection and ranging inertial odometry
Dongjiao He, Wei Xu, Nan Chen, Fanze Kong, Chongjian Yuan, and Fu Zhang. Point-LIO: robust high- bandwidth light detection and ranging inertial odometry. Advanced Intelligent Systems, 5(7):2200459, 2023
work page 2023
-
[15]
OmniH2O: Universal and dexterous human- to-humanoid whole-body teleoperation and learning
Tairan He, Zhengyi Luo, Xialin He, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. OmniH2O: Universal and dexterous human- to-humanoid whole-body teleoperation and learning. In Conference on Robot Learning, 2024
work page 2024
-
[16]
Learning human- to-humanoid real-time whole-body teleoperation
Tairan He, Zhengyi Luo, Wenli Xiao, Chong Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. Learning human- to-humanoid real-time whole-body teleoperation. In IEEE/RSJ International Conference on Intelligent Robots and Systems, 2024
work page 2024
-
[17]
Hodgins, Linxi Fan, Yuke Zhu, Changliu Liu, and Guanya Shi
Tairan He, Jiawei Gao, Wenli Xiao, Yuanhang Zhang, Zi Wang, Jiashun Wang, Zhengyi Luo, Guanqi He, Nikhil Sobanbabu, Chaoyi Pan, Zeji Yi, Guannan Qu, Kris Ki- tani, Jessica K. Hodgins, Linxi Fan, Yuke Zhu, Changliu Liu, and Guanya Shi. ASAP: Aligning simulation and real-world physics for learning agile humanoid whole- body skills. InRobotics: Science and S...
work page 2025
-
[18]
Learning getting-up policies for real-world hu- manoid robots
Xialin He, Runpei Dong, Zixuan Chen, and Saurabh Gupta. Learning getting-up policies for real-world hu- manoid robots. InRobotics: Science and Systems, 2025
work page 2025
-
[19]
Learning humanoid standing-up con- trol across diverse postures
Tao Huang, Junli Ren, Huayi Wang, Zirui Wang, Qing- wei Ben, Muning Wen, Xiao Chen, Jianan Li, and Jiangmiao Pang. Learning humanoid standing-up con- trol across diverse postures. InRobotics: Science and Systems, 2025
work page 2025
-
[20]
Wei-Jin Huang, Yue-Yi Zhang, Yi-Lin Wei, Zhi-Wei Xia, Juantao Tan, Yuan-Ming Li, Zhilin Zhao, and Wei-Shi Zheng. Learning whole-body human-humanoid interac- tion from human-human demonstrations.arXiv preprint arXiv:2601.09518, 2026
-
[21]
LCM: A multicast core management protocol for link-state routing networks
Yih Huang, Eric Fleury, and Philip K McKinley. LCM: A multicast core management protocol for link-state routing networks. InICC’98. 1998 IEEE International Conference on Communications. Conference Record. Af- filiated with SUPERCOMM’98 (Cat. No. 98CH36220), volume 2, pages 1197–1201. IEEE, 1998
work page 1998
-
[22]
AMO: Adaptive mo- tion optimization for hyper-dexterous humanoid whole- body control
Jialong Li, Xuxin Cheng, Tianshu Huang, Shiqi Yang, Ri-Zhao Qiu, and Xiaolong Wang. AMO: Adaptive mo- tion optimization for hyper-dexterous humanoid whole- body control. InRobotics: Science and Systems, 2025
work page 2025
-
[23]
Junheng Li, Ziwei Duan, Junchao Ma, and Quan Nguyen. Gait-Net-augmented implicit kino-dynamic MPC for dy- namic variable-frequency humanoid locomotion over dis- crete terrains. InRobotics: Science and Systems, 2025
work page 2025
-
[24]
CLONE: Closed-loop whole-body humanoid teleoperation for long-horizon tasks
Yixuan Li, Yutang Lin, Jieming Cui, Tengyu Liu, Wei Liang, Yixin Zhu, and Siyuan Huang. CLONE: Closed-loop whole-body humanoid teleoperation for long-horizon tasks. InConference on Robot Learning, 2025
work page 2025
-
[25]
Han Liang, Wenqian Zhang, Wenxuan Li, Jingyi Yu, and Lan Xu. InterGen: Diffusion-based multi-human motion generation under complex interactions.International Journal of Computer Vision (IJCV), 2024
work page 2024
-
[26]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Qiayuan Liao, Takara E Truong, Xiaoyu Huang, Yu- man Gao, Guy Tevet, Koushil Sreenath, and C Karen Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Michael L. Littman. Markov games as a framework for multi-agent reinforcement learning. InProceedings of the Eleventh International Conference on Machine Learning (ICML), volume 157, pages 157–163. Morgan Kaufmann, 1994
work page 1994
-
[28]
Humanoid Whole-Body Badminton via Multi-Stage Reinforcement Learning
Chenhao Liu, Leyun Jiang, Yibo Wang, Kairan Yao, Jinchen Fu, and Xiaoyu Ren. Humanoid whole-body badminton via multi-stage reinforcement learning.arXiv preprint arXiv:2511.11218, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Zuhong Liu, Junhao Ge, Minhao Xiong, Jiahao Gu, Bowei Tang, Wei Jing, and Siheng Chen. It Takes Two: Learning interactive whole-body control between humanoid robots.arXiv preprint arXiv:2510.10206, 2025
-
[30]
Perpetual humanoid control for real-time simulated avatars
Zhengyi Luo, Jinkun Cao, Alexander Winkler, Kris Ki- tani, and Weipeng Xu. Perpetual humanoid control for real-time simulated avatars. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 10895– 10904, 2023
work page 2023
-
[31]
DeepMimic: Example-guided deep re- inforcement learning of physics-based character skills
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel Van de Panne. DeepMimic: Example-guided deep re- inforcement learning of physics-based character skills. ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
work page 2018
-
[32]
Xue Bin Peng, Yunrong Guo, Lina Halper, Sergey Levine, and Sanja Fidler. ASE: Large-scale reusable adversarial skill embeddings for physically simulated characters.ACM Transactions on Graphics (TOG), 41 (4):1–17, 2022
work page 2022
-
[33]
Non-conflicting energy minimization in reinforce- ment learning based robot control
Skand Peri, Akhil Perincherry, Bikram Pandit, and Stefan Lee. Non-conflicting energy minimization in reinforce- ment learning based robot control. InConference on Robot Learning, 2025
work page 2025
-
[34]
Junli Ren, Junfeng Long, Tao Huang, Huayi Wang, Zirui Wang, Feiyu Jia, Wentao Zhang, Jingbo Wang, Ping Luo, and Jiangmiao Pang. Humanoid Goalkeeper: Learning from position conditioned task-motion constraints.arXiv preprint arXiv:2510.18002, 2025
-
[35]
Aleksandr Segal, Dirk Haehnel, and Sebastian Thrun. Generalized-ICP. InRobotics: Science and Systems, volume 2, page 435. Seattle, W A, 2009
work page 2009
-
[36]
LangWBC: Language-directed humanoid whole-body control via end-to-end learning
Yiyang Shao, Bike Zhang, Qiayuan Liao, Xiaoyu Huang, Yuman Gao, Yufeng Chi, Zhongyu Li, Sophia Shao, and Koushil Sreenath. LangWBC: Language-directed humanoid whole-body control via end-to-end learning. InRobotics: Science and Systems, 2025
work page 2025
-
[37]
A comprehensive review of humanoid robots.SmartBot, 1(1):e12008, 2025
Qincheng Sheng, Zhongxiang Zhou, Jinhao Li, Xiangyu Mi, Pingyu Xiang, Zhenghan Chen, Haocheng Xu, Shen- han Jia, Xiyang Wu, Yuxiang Cui, et al. A comprehensive review of humanoid robots.SmartBot, 1(1):e12008, 2025
work page 2025
-
[38]
Sebastian Starke, Yiwei Zhao, Taku Komura, and Kazi Zaman. Local motion phases for learning multi-contact character movements.ACM Transactions on Graphics, 39(4), 2020
work page 2020
-
[39]
Zhi Su, Bike Zhang, Nima Rahmanian, Yuman Gao, Qiayuan Liao, Caitlin Regan, Koushil Sreenath, and S Shankar Sastry. HITTER: A humanoid table tennis robot via hierarchical planning and learning.arXiv preprint arXiv:2508.21043, 2025
-
[40]
BeamDojo: Learning agile humanoid locomotion on sparse footholds
Huayi Wang, Zirui Wang, Junli Ren, Qingwei Ben, Tao Huang, Weinan Zhang, and Jiangmiao Pang. BeamDojo: Learning agile humanoid locomotion on sparse footholds. InRobotics: Science and Systems, 2025
work page 2025
-
[41]
InterMoE: Individual-specific 3d human interaction generation via dynamic temporal- selective moe
Lipeng Wang, Hongxing Fan, Haohua Chen, Zehuan Huang, and Lu Sheng. InterMoE: Individual-specific 3d human interaction generation via dynamic temporal- selective moe. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
work page 2026
-
[42]
Skillmimic: Learning basketball interaction skills from demonstrations
Yinhuai Wang, Qihan Zhao, Runyi Yu, Hok Wai Tsui, Ailing Zeng, Jing Lin, Zhengyi Luo, Jiwen Yu, Xiu Li, Qifeng Chen, Jian Zhang, Lei Zhang, and Ping Tan. Skillmimic: Learning basketball interaction skills from demonstrations. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 17540– 17549, June 2025
work page 2025
-
[43]
Jungdam Won, Deepak Gopinath, and Jessica Hodgins. Control strategies for physically simulated characters performing two-player competitive sports.ACM Trans- actions on Graphics (TOG), 40(4):1–11, 2021
work page 2021
-
[44]
Weiji Xie, Jinrui Han, Jiakun Zheng, Huanyu Li, Xinzhe Liu, Jiyuan Shi, Weinan Zhang, Chenjia Bai, and Xue- long Li. KungfuBot: Physics-based humanoid whole- body control for learning highly-dynamic skills.Ad- vances in Neural Information Processing Systems, 2025
work page 2025
-
[45]
Inter-X: Towards versatile human- human interaction analysis
Liang Xu, Xintao Lv, Yichao Yan, Xin Jin, Shuwen Wu, Congsheng Xu, Yifan Liu, Yizhou Zhou, Fengyun Rao, Xingdong Sheng, Yunhui Liu, Wenjun Zeng, and Xiaokang Yang. Inter-X: Towards versatile human- human interaction analysis. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[46]
Liang Xu, Chengqun Yang, Zili Lin, Fei Xu, Yifan Liu, Congsheng Xu, Yiyi Zhang, Jie Qin, Xingdong Sheng, Yunhui Liu, et al. Perceiving and acting in first-person: A dataset and benchmark for egocentric human-object- human interactions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12535–12548, 2025
work page 2025
-
[47]
Learning Agile Striker Skills for Humanoid Soccer Robots from Noisy Sensory Input
Zifan Xu, Myoungkyu Seo, Dongmyeong Lee, Hao Fu, Jiaheng Hu, Jiaxun Cui, Yuqian Jiang, Zhihan Wang, Anastasiia Brund, Joydeep Biswas, et al. Learning agile striker skills for humanoid soccer robots from noisy sensory input.arXiv preprint arXiv:2512.06571, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
A unified and general humanoid whole-body controller for fine-grained locomotion
Yufei Xue, Wentao Dong, Minghuan Liu, Weinan Zhang, and Jiangmiao Pang. A unified and general humanoid whole-body controller for fine-grained locomotion. In Robotics: Science and Systems, 2025
work page 2025
-
[49]
Lujie Yang, Xiaoyu Huang, Zhen Wu, Angjoo Kanazawa, Pieter Abbeel, Carmelo Sferrazza, C Karen Liu, Rocky Duan, and Guanya Shi. OmniRetarget: Interaction- preserving data generation for humanoid whole-body loco-manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025
-
[50]
Wei Yao, Yunlian Sun, Chang Liu, Hongwen Zhang, and Jinhui Tang. PhysiInter: Integrating physical mapping for high-fidelity human interaction generation.arXiv preprint arXiv:2506.07456, 2025
-
[51]
Hi4D: 4D instance segmentation of close human interaction
Yifei Yin, Chen Guo, Manuel Kaufmann, Juan Jose Zarate, Jie Song, and Otmar Hilliges. Hi4D: 4D instance segmentation of close human interaction. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[52]
TWIST: Tele- operated whole-body imitation system
Yanjie Ze, Zixuan Chen, Joao Pedro Araujo, Zi-ang Cao, Xue Bin Peng, Jiajun Wu, and Karen Liu. TWIST: Tele- operated whole-body imitation system. InConference on Robot Learning, 2025
work page 2025
-
[53]
HuB: Learning extreme humanoid balance
Tong Zhang, Boyuan Zheng, Ruiqian Nai, Yingdong Hu, Yen-Jen Wang, Geng Chen, Fanqi Lin, Jiongye Li, Chuye Hong, Koushil Sreenath, and Yang Gao. HuB: Learning extreme humanoid balance. InConference on Robot Learning, 2025
work page 2025
-
[54]
Simulation and retargeting of complex multi-character interactions
Yunbo Zhang, Deepak Gopinath, Yuting Ye, Jessica Hodgins, Greg Turk, and Jungdam Won. Simulation and retargeting of complex multi-character interactions. In ACM SIGGRAPH 2023 Conference Proceedings, pages 1–11, 2023
work page 2023
-
[55]
Track any motions under any disturbances, 2025
Zhikai Zhang, Jun Guo, Chao Chen, Jilong Wang, Chenghuai Lin, Yunrui Lian, Han Xue, Zhenrong Wang, Maoqi Liu, Jiangran Lyu, et al. Track any motions un- der any disturbances.arXiv preprint arXiv:2509.13833, 2025
-
[56]
Kun Zhou, Jin Huang, John Snyder, Xinguo Liu, Hujun Bao, Baining Guo, and Heung-Yeung Shum. Large mesh deformation using the volumetric graph laplacian.ACM Transactions on Graphics (TOG), 24(3):496–503, 2005. APPENDIX Overview This appendix is organized into three main sections (A– C) to support the clarity and reproducibility of the proposed framework,Rh...
work page 2005
-
[57]
Compatibility with Heterogeneous Motion Sources: Human motion datasets contain rich pose and interaction information but differ significantly in data format and physical attributes (e.g., height, body proportions). A key strength of our framework is its input-agnostic design: we first abstract diverse inputs into a standardized representation—time-series ...
-
[58]
Optimization Details and Hyperparameters:We explic- itly formulate the optimization objectives and constraints used to solve the kinematic conflict described in Sec. III-A. Optimization Formulation.We solve the retargeting problem frame-by-frame using a Sequential Quadratic Programming (SQP) approach. For each framet, we optimize the joint configurationsq...
-
[59]
Topological Graph Visualization:To provide an intuitive understanding of the topological priors, we visualize the ex- tracted graph structures using a representative interaction case (e.g., a handshake task), as shown in Fig. 7. The visualization highlights two distinct connectivity types used by IAMR: •The Interaction Graph (Yellow Edges):Bridges the key...
-
[60]
Network Architecture:Our policyπ θ(at|ot)employs a hierarchical encoder-decoder architecture designed to process heterogeneous temporal data. The network input is composed of three semantic groups, which are processed by specialized encoders before being fused for action generation. Observation Space & Inputs To capture complex coupled dynamics, the polic...
-
[61]
Reward Definitions:The total rewardr t is computed as a weighted sum of terms designed to balance kinematic fidelity with interaction plausibility, as detailed in Table IV. We prioritize interaction-centric objectives (e.g., relative geometry and contact) over individual tracking precision to encourage compliant multi-agent coupling. Interaction Graph Rew...
-
[62]
Robust Training Strategy:To ensure transferability to the physical world and handle the complexity of coupled interaction phases, we implement a rigorous training protocol comprising error-aware curriculum-based adaptive sampling and extensive domain randomization. Curriculum-based Adaptive Sampling Standard Reference State Initialization (RSI) relies on ...
-
[63]
Baseline Implementation Details:To strictly validate our contributions, we benchmark our framework against two sets of baselines: kinematic retargeting methods (answering Q1) and dynamic policy learning variants (answering Q2). Retargeting Baselines (Kinematic Level) All baselines utilize the same source motion data and undergo identical skeletal scaling ...
-
[64]
Evaluation Metric Implementation Details:We employ specific metrics for each component of our framework to eval- uate kinematic quality and dynamic performance respectively. Retargeting Evaluation Metrics (Q1) We evaluate retargeting quality from three complementary as- pects: physical feasibility, interaction fidelity, and downstream utility. •Inter-Pene...
-
[65]
Sim-to-Real Hardware:We validate our approach on the Unitree G1 humanoid robot platform. To bridge the gap between ideal simulation states and real-world noisy sensor data, we implement a fully onboard perception and control stack written in C++ for real-time performance. Robot Platform & Compute.The Unitree G1 (approx. 1.3 m height, 29 DoF) serves as our...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.