Recognition: no theorem link
SeedPolicy: Horizon Scaling via Self-Evolving Diffusion Policy for Robot Manipulation
Pith reviewed 2026-05-15 16:38 UTC · model grok-4.3
The pith
Integrating self-evolving gated attention into diffusion policies resolves temporal bottlenecks and scales effective horizons for long-horizon robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
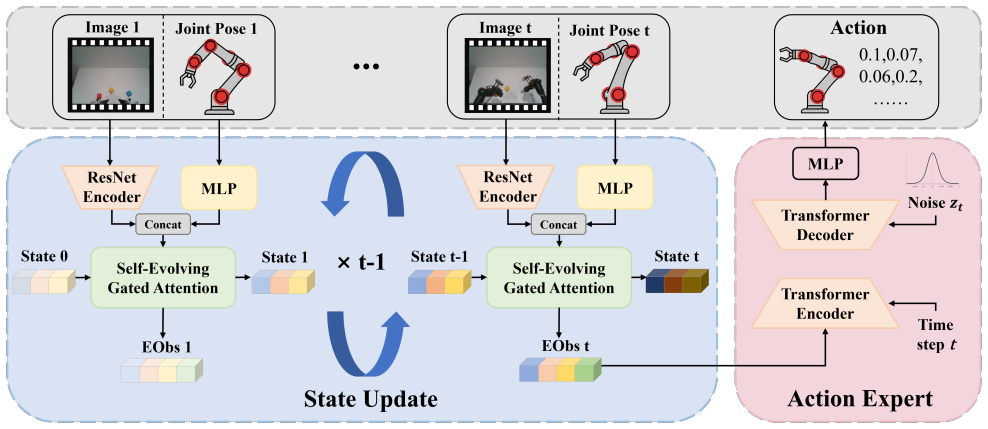
SeedPolicy resolves the temporal modeling bottleneck in Diffusion Policy by integrating Self-Evolving Gated Attention, which maintains a time-evolving latent state via gated attention for efficient recurrent updates that accumulate long-term context into a compact representation while filtering irrelevant temporal information. This extends the effective temporal horizon with moderate overhead and leads to superior performance on long-horizon imitation learning tasks for robot manipulation.
What carries the argument
Self-Evolving Gated Attention (SEGA), a temporal module that maintains a time-evolving latent state via gated attention to enable efficient recurrent updates accumulating long-term context.
If this is right
- Diffusion policies can scale observation horizons without the usual performance drop.
- Large relative gains appear on 50-task benchmarks, with the biggest lifts under randomized conditions.
- Strong efficiency advantage holds against vision-language-action models using 10-100 times more parameters.
- The method sets a new state-of-the-art baseline for imitation learning on long-horizon robotic manipulation.
Where Pith is reading between the lines
- The gated recurrent update pattern could transfer to other policy architectures that currently rely on stacked frames.
- Efficient latent-state memory may reduce the need for ever-larger context windows in real-time robot control.
- Similar mechanisms might help sequential decision tasks outside manipulation, such as navigation or assembly planning.
- The approach points toward hybrid recurrent-diffusion designs that keep compute costs low while extending temporal reach.
Load-bearing premise
The gated attention mechanism reliably accumulates relevant long-term context while filtering irrelevant temporal information across diverse manipulation tasks without introducing new failure modes or losing critical details.
What would settle it
An experiment where increasing the observation horizon in SeedPolicy causes performance to degrade at the same rate as in standard Diffusion Policy, or where SEGA fails to filter distractors in a task requiring precise recall of distant events.
Figures












read the original abstract
Imitation Learning (IL) enables robots to acquire manipulation skills from expert demonstrations. Diffusion Policy (DP) models multi-modal expert behaviors but degrades when naively increasing stacked observation horizons, limiting long-horizon manipulation. We propose Self-Evolving Gated Attention (SEGA), a temporal module that maintains a time-evolving latent state via gated attention, enabling efficient recurrent updates that accumulate long-term context into a compact latent representation while filtering irrelevant temporal information. Integrating SEGA into DP yields Self-Evolving Diffusion Policy (SeedPolicy), which resolves the temporal modeling bottleneck and extends the effective temporal horizon with moderate overhead. On the RoboTwin 2.0 benchmark with 50 manipulation tasks, SeedPolicy outperforms DP and other IL baselines. Averaged across both CNN and Transformer backbones, SeedPolicy achieves 36.8% relative improvement in clean settings and 169% relative improvement in randomized challenging settings over the DP. Compared to vision-language-action models such as RDT with 1.2B parameters, SeedPolicy achieves stronger performance in the clean setting with one to two orders of magnitude fewer parameters, demonstrating strong efficiency. These results establish SeedPolicy as a state-of-the-art imitation learning method for long-horizon robotic manipulation. Code is available at: https://anonymous.4open.science/r/SeedPolicy-64F0/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Self-Evolving Diffusion Policy (SeedPolicy) by augmenting Diffusion Policy with a Self-Evolving Gated Attention (SEGA) temporal module. SEGA maintains a compact time-evolving latent state through gated attention to enable recurrent updates that accumulate long-horizon context while filtering irrelevant information, addressing DP's degradation with stacked observations. On the RoboTwin 2.0 benchmark across 50 manipulation tasks, SeedPolicy reports averaged relative gains of 36.8% (clean) and 169% (randomized challenging) over DP for both CNN and Transformer backbones, plus stronger clean-setting performance than the 1.2B-parameter RDT model despite using one to two orders of magnitude fewer parameters. Code is released.
Significance. If the results hold under rigorous validation, the contribution is meaningful for imitation learning: it offers a lightweight, recurrent-style fix to the known horizon-scaling bottleneck in diffusion policies without the parameter cost of large VLA models. The efficiency claims and public code are clear strengths that could influence practical long-horizon manipulation pipelines.
major comments (1)
- [Abstract and §4] Abstract and §4 (Experiments): The central performance claims (36.8% / 169% relative gains) are attributed to SEGA's gated updates preserving critical details across horizons, yet no horizon-scaling curves, attention-weight trajectories, or ablation replacing the gate with plain recurrence are reported. Without these, it remains possible that gains arise from added capacity or training variance rather than the claimed temporal mechanism.
minor comments (3)
- The anonymous code link should be replaced with a permanent repository or supplemented with full training hyperparameters, random seeds, and statistical significance tests (error bars, p-values) to support reproducibility.
- [Abstract] Clarify the exact parameter counts for SeedPolicy variants versus the cited RDT baseline and confirm whether the reported averages are macro- or micro-averaged across the 50 tasks.
- [§3.2] Figure captions and §3.2 should explicitly define the gating equations and any learned parameters in SEGA to allow readers to verify the 'parameter-free' or 'moderate overhead' claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The request for additional analyses to more directly attribute gains to the SEGA mechanism is reasonable, and we will incorporate the suggested elements into the revised manuscript to strengthen the experimental validation.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central performance claims (36.8% / 169% relative gains) are attributed to SEGA's gated updates preserving critical details across horizons, yet no horizon-scaling curves, attention-weight trajectories, or ablation replacing the gate with plain recurrence are reported. Without these, it remains possible that gains arise from added capacity or training variance rather than the claimed temporal mechanism.
Authors: We acknowledge that the current experiments, while showing consistent gains across backbones and settings, do not include the specific diagnostics requested. In the revision we will add: (1) horizon-scaling curves that plot task success rate versus observation horizon length (from 1 to 16 frames) for both baseline DP and SeedPolicy, directly illustrating the improved scaling behavior; (2) representative attention-weight trajectories over time that visualize how the gated mechanism selectively retains or discards information from past observations; and (3) an ablation that replaces the gated attention with a plain recurrent module (e.g., a standard GRU-style update without the learned gate) while keeping parameter count matched, to isolate the contribution of the gating operation. These additions will help distinguish the claimed temporal mechanism from capacity or variance effects. We believe the existing multi-backbone, multi-setting results already provide supporting evidence, but the new analyses will make the attribution more rigorous. revision: yes
Circularity Check
No circularity: empirical gains measured on external benchmark
full rationale
The paper introduces SEGA as a new gated-attention temporal module and integrates it into Diffusion Policy to form SeedPolicy. All reported results (36.8% and 169% relative gains) are obtained by direct evaluation on the independent RoboTwin 2.0 benchmark against standard baselines. No equations, fitted parameters, or self-citations are presented that reduce the performance numbers to quantities defined inside the paper itself. The architecture is proposed rather than derived from prior self-referential results, so the central claims remain externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gated attention can maintain a compact time-evolving latent state that accumulates relevant context while discarding irrelevant information
invented entities (1)
-
Self-Evolving Gated Attention (SEGA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Global optimality of elman-type rnn in the mean-field regime
Andrea Agazzi, Jian-Xiong Lu, and Sayan Mukherjee. Global optimality of elman-type rnn in the mean-field regime. InInternational Conference on Machine Learn- ing (ICML), pages 187–218. PMLR, 2023
work page 2023
-
[2]
Homanga Bharadhwaj, Jay Vakil, Mohit Sharma, Ab- hinav Gupta, Shubham Tulsiani, and Vikash Kumar. Roboagent: Generalization and efficiency in robot manip- ulation via semantic augmentations and action chunking. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4788–4795. IEEE, 2024
work page 2024
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions
Yevgen Chebotar, Quan Vuong, Karol Hausman, Fei Xia, Yao Lu, Alex Irpan, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, et al. Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. InConference on Robot Learning, pages 3909–3928. PMLR, 2023
work page 2023
-
[5]
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Rein- forcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
work page 2021
-
[6]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Qiwei Liang, Zixuan Li, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
G3flow: Generative 3d semantic flow for pose-aware and gen- eralizable object manipulation
Tianxing Chen, Yao Mu, Zhixuan Liang, Zanxin Chen, Shijia Peng, Qiangyu Chen, Mingkun Xu, et al. G3flow: Generative 3d semantic flow for pose-aware and gen- eralizable object manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1735–1744, 2025
work page 2025
-
[8]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[9]
Learning phrase representations using rnn encoder–decoder for statistical machine trans- lation
Kyunghyun Cho, Bart van Merrienboer, C ¸ aglar G¨ulc ¸ehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine trans- lation. InProceedings of the 2014 Conference on Empir- ical Methods in Natural Language Processing (EMNLP), pages 1724–1734, 2014
work page 2014
-
[10]
Jeffrey L. Elman. Finding structure in time.Cognitive Science, 14(2):179–211, 1990
work page 1990
-
[11]
Shichao Fan, Quantao Yang, Yajie Liu, Kun Wu, Zheng- ping Che, Qingjie Liu, and Min Wan. Diffusion trajectory-guided policy for long-horizon robot manip- ulation.arXiv preprint arXiv:2502.10040, 2025
-
[12]
Rvt-2: Learning precise manipulation from few demonstrations
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu- Wei Chao, and Dieter Fox. Rvt-2: Learning precise manipulation from few demonstrations.arXiv preprint arXiv:2406.08545, 2024
-
[13]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Youqiang Gui, Fanglong Wu, and Peng Cheng. Tscir: Towards composite weather degradation image restora- tion via a two-stage framework.Neurocomputing, page 132798, 2026
work page 2026
-
[15]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion poli- cies.arXiv preprint arXiv:2304.10573, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Long short- term memory.Neural Computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short- term memory.Neural Computation, 9(8):1735–1780, 1997
work page 1997
-
[17]
Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem.Advances in neural information processing systems, 34:1273–1286, 2021
work page 2021
-
[18]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Crossway diffusion: Improving diffusion-based visuomotor policy via self-supervised learning
Xiang Li, Varun Belagali, Jinghuan Shang, and Michael S Ryoo. Crossway diffusion: Improving diffusion-based visuomotor policy via self-supervised learning. In2024 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 16841–16849. IEEE, 2024
work page 2024
-
[20]
Fanqi Lin, Yingdong Hu, Pingyue Sheng, Chuan Wen, Jiacheng You, and Yang Gao. Data scaling laws in im- itation learning for robotic manipulation.arXiv preprint arXiv:2410.18647, 2024
-
[21]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Synthetic experience replay.Advances in Neural Information Processing Systems, 36:46323–46344, 2023
Cong Lu, Philip Ball, Yee Whye Teh, and Jack Parker- Holder. Synthetic experience replay.Advances in Neural Information Processing Systems, 36:46323–46344, 2023
work page 2023
-
[23]
Hierarchical diffusion policy for kinematics- aware multi-task robotic manipulation
Xiao Ma, Sumit Patidar, Iain Haughton, and Stephen James. Hierarchical diffusion policy for kinematics- aware multi-task robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18081–18090, 2024
work page 2024
-
[24]
Consistency policy: Accelerated visuomotor policies via consistency distillation
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, and Jeannette Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation.arXiv preprint arXiv:2405.07503, 2024
-
[25]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.arXiv preprint arXiv:2505.06708, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Real-world robot learning with masked visual pre-training
Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real-world robot learning with masked visual pre-training. In Conference on Robot Learning, pages 416–426. PMLR, 2023
work page 2023
-
[27]
Goal-conditioned imitation learning using score-based diffusion policies
Moritz Reuss, Maximilian Li, Xiaogang Jia, and Rudolf Lioutikov. Goal-conditioned imitation learning us- ing score-based diffusion policies.arXiv preprint arXiv:2304.02532, 2023
-
[28]
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transformers: Cloningkmodes with one stone.Advances in Neural Information Processing Systems, 35:22955–22968, 2022
work page 2022
-
[29]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[30]
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic ma- nipulation.arXiv preprint arXiv:2209.05451, 2022
-
[31]
Rupesh Kumar Srivastava, Klaus Greff, and J ¨urgen Schmidhuber. Highway networks.arXiv preprint arXiv:1505.00387, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[32]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks.arXiv preprint arXiv:1409.3215, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Bap- tiste Rozi`ere, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
An overview of large ai models and their applications.Visual Intelligence, 2(1):34, 2024
Xiaoguang Tu, Zhi He, Yi Huang, Zhi-Hao Zhang, Ming Yang, and Jian Zhao. An overview of large ai models and their applications.Visual Intelligence, 2(1):34, 2024
work page 2024
-
[36]
Peihao Wang, Wenqing Zheng, Tianlong Chen, and Zhangyang Wang. Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From the- ory to practice.arXiv preprint arXiv:2203.05962, 2022
-
[37]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2024.URL https://arxiv. org/abs/2309.17453, 1, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Han Xue, Jieji Ren, Wendi Chen, Gu Zhang, Yuan Fang, Guoying Gu, Huazhe Xu, and Cewu Lu. Re- active diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation.arXiv preprint arXiv:2503.02881, 2025
- [39]
-
[40]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation.arXiv preprint arXiv:2412.04987, 2024
-
[42]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Mul- timax: Sparse and multi-modal attention learning
Yuxuan Zhou, Mario Fritz, and Margret Keuper. Mul- timax: Sparse and multi-modal attention learning. In International Conference on Machine Learning (ICML), pages 61897–61912. PMLR, 2024. APPENDIX A. Overview In this appendix, we provide supplementary details and extensive experimental results to further substantiate the ef- fectiveness and robustness of ...
work page 2024
-
[44]
Task Setup and Randomization:We collected 50 expert demonstrations for three representative long-horizon tasks: Sequential Picking,Bottle Handover, andLooping Place- Retrieval. To foster strong generalization capabilities, we introduced systematic spatial randomization during the data TABLE VIII HARDWARESPECIFICATIONS OF THEDOS-W1 PLATFORM.THE SYSTEM INTE...
-
[45]
Temporal Alignment and Static Filtering:Following collec- tion, we address the asynchronous nature of the raw data. The raw data from the DOS-W1 platform comprises independent streams of RGB video and high-frequency proprioceptive logs. We first synchronize these streams by aligning proprioceptive timestamps to video frame timestamps via nearest-neighbor ...
-
[46]
Dataset Aggregation and F ormatting:In the final stage, the processed episodes are aggregated into Zarr archives to optimize I/O throughput. We format the imitation learning objective as a next-state prediction problem, where the action At corresponds to the state vector att+1. Furthermore, visual observations are decoded and transposed to the channel-fir...
-
[47]
to balance storage efficiency with access speed. D. Additional Quantitative and Qualitative Results a) Robustness Analysis under Randomized Settings: Table IX provides the task-level performance breakdown that underpins the significant average gains reported in the main text. As expected, the introduction of severe environmen- tal randomization leads to a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.