Recognition: 1 theorem link
· Lean TheoremFusion Complexity Inversion: Why Simpler Cross View Modules Outperform SSMs and Cross View Attention Transformers for Pasture Biomass Regression
Pith reviewed 2026-05-15 14:25 UTC · model grok-4.3
The pith
Simpler two-layer gated depthwise convolutions outperform complex cross-view transformers and state-space models when estimating pasture biomass from scarce dual-view imagery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes fusion complexity inversion on scarce agricultural data for pasture biomass regression: simpler cross-view fusion via a two-layer gated depthwise convolution surpasses cross-view attention transformers, bidirectional state-space models, and full Mamba architectures. Backbone pretraining scale dominates all architectural choices, delivering consistent gains. Metadata-only training imposes a universal performance ceiling independent of fusion method, and the study derives guidelines that favor backbone quality and local modules over complex global fusion for similar sparse benchmarks.
What carries the argument
fusion complexity inversion, the pattern in which simpler local fusion mechanisms outperform more complex global attention and state-space mechanisms on limited agricultural datasets
If this is right
- Backbone pretraining scale yields larger and more consistent gains than changes to fusion mechanisms.
- Metadata-only training creates a performance ceiling that collapses differences between fusion approaches.
- Local modules are preferable to global attention or sequence-modeling alternatives on sparse agricultural benchmarks.
- Practical guidelines emerge for model adaptation that prioritize backbone quality over fusion complexity.
Where Pith is reading between the lines
- The inversion principle may appear in other remote-sensing regression tasks that use small or imbalanced labeled collections.
- As dataset size increases, the advantage of simpler modules could diminish, suggesting a need for scaling experiments.
- Development effort for agricultural vision systems should shift toward stronger pretraining rather than more intricate fusion layers.
Load-bearing premise
Performance differences across fusion mechanisms and backbones arise purely from their architectural designs rather than from unstated variations in hyperparameter tuning, training schedules, or data augmentation.
What would settle it
Re-train all configurations with identical hyperparameters, schedules, and augmentations on the same dataset to check whether the simpler gated convolution module still leads.
Figures









read the original abstract
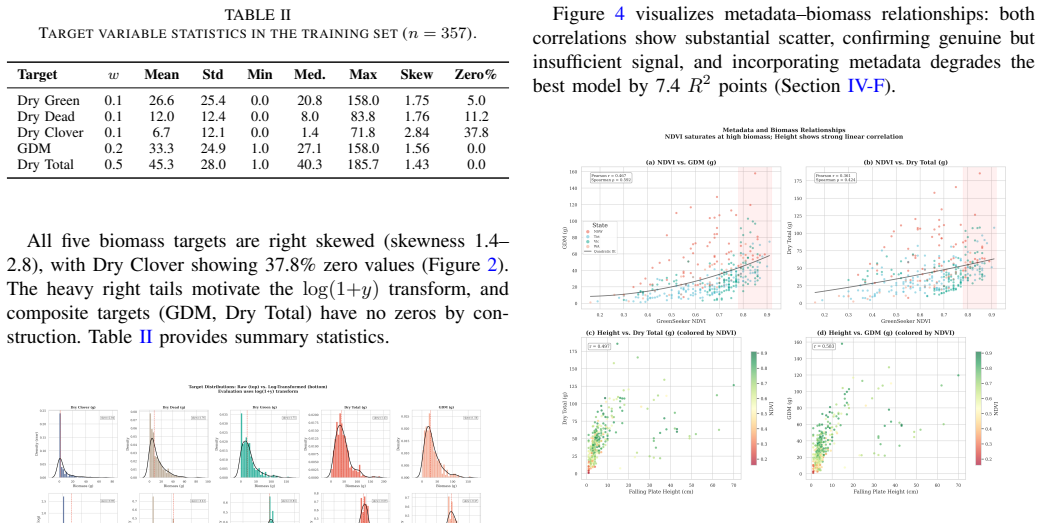
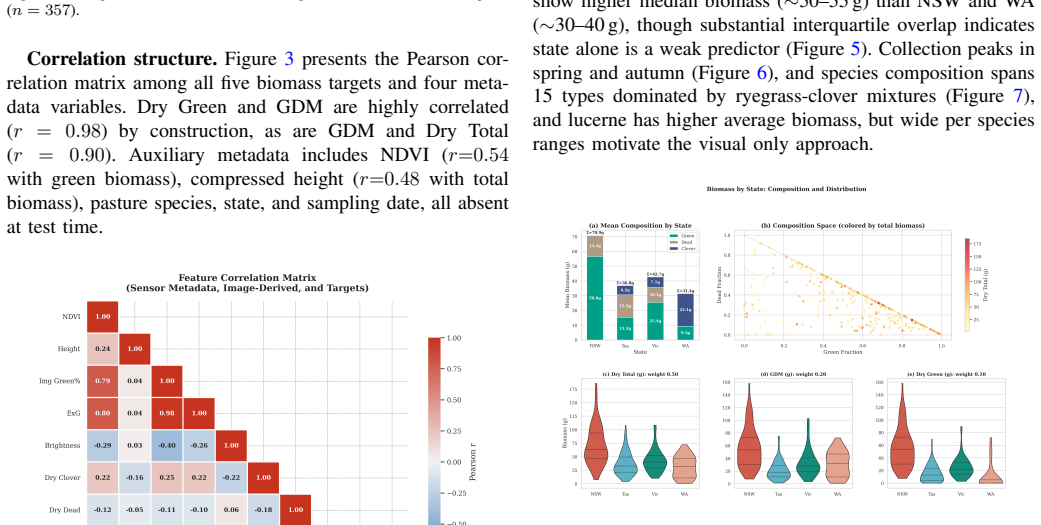
Accurate estimation of pasture biomass from agricultural imagery is critical for sustainable livestock management, yet existing methods are limited by the small, imbalanced, and sparsely annotated datasets typical of real world monitoring. In this study, adaptation of vision foundation models to agricultural regression is systematically evaluated on the CSIRO Pasture Biomass benchmark, a 357 image dual view dataset with laboratory validated, component wise ground truth for five biomass targets, through 17 configurations spanning four backbones (EfficientNet-B3 to DINOv3-ViT-L), five cross view fusion mechanisms, and a 4x2 metadata factorial. A counterintuitive principle, termed "fusion complexity inversion", is uncovered: on scarce agricultural data, a two layer gated depthwise convolution (R^2 = 0.903) outperforms cross view attention transformers (0.833), bidirectional SSMs (0.819), and full Mamba (0.793, below the no fusion baseline). Backbone pretraining scale is found to monotonically dominate all architectural choices, with the DINOv2 -> DINOv3 upgrade alone yielding +5.0 R^2 points. Training only metadata (species, state, and NDVI) is shown to create a universal ceiling at R^2 ~ 0.829, collapsing an 8.4 point fusion spread to 0.1 points. Actionable guidelines for sparse agricultural benchmarks are established: backbone quality should be prioritized over fusion complexity, local modules preferred over global alternatives, and features unavailable at inference excluded.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates adaptation of vision foundation models for pasture biomass regression on the CSIRO Pasture Biomass benchmark (357-image dual-view dataset with lab-validated ground truth). Across 17 configurations with four backbones (EfficientNet-B3 to DINOv3-ViT-L) and five cross-view fusion mechanisms, it reports that a two-layer gated depthwise convolution achieves R²=0.903, outperforming cross-view attention transformers (0.833), bidirectional SSMs (0.819), and full Mamba (0.793, below no-fusion baseline). It introduces the principle of 'fusion complexity inversion' on scarce agricultural data, finds that backbone pretraining scale dominates all choices (+5.0 R² from DINOv2 to DINOv3), and shows metadata-only training creates a universal ceiling at R²~0.829.
Significance. If the performance ordering holds under controlled conditions, the work supplies practical guidelines for small-data agricultural vision: prioritize backbone pretraining quality over fusion complexity, prefer local modules to global ones, and exclude inference-unavailable features. The observation that metadata collapses an 8.4-point fusion spread to 0.1 points is a concrete, actionable result for deployment.
major comments (1)
- [Abstract and results section] The central claim of fusion complexity inversion rests on the R² gaps (0.903 for gated depthwise conv vs. 0.833 for cross-view attention and 0.793 for Mamba) being attributable solely to the fusion mechanisms. The manuscript does not state that a uniform hyperparameter optimization procedure (identical search space, trial count, or fixed defaults) was applied across all 17 configurations; complex modules such as SSMs and transformers are known to be sensitive to learning rate, initialization, and regularization, so any unstated per-model tuning could artifactually favor the simpler gated convolution.
minor comments (1)
- [Abstract] The abstract omits any mention of statistical significance testing, exact train/validation/test splits, or the precise hyperparameter controls used, which are needed to assess whether the reported gaps are robust.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need to explicitly document our experimental controls. We address the concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and results section] The central claim of fusion complexity inversion rests on the R² gaps (0.903 for gated depthwise conv vs. 0.833 for cross-view attention and 0.793 for Mamba) being attributable solely to the fusion mechanisms. The manuscript does not state that a uniform hyperparameter optimization procedure (identical search space, trial count, or fixed defaults) was applied across all 17 configurations; complex modules such as SSMs and transformers are known to be sensitive to learning rate, initialization, and regularization, so any unstated per-model tuning could artifactually favor the simpler gated convolution.
Authors: We agree that the manuscript should have stated the hyperparameter protocol explicitly. All 17 configurations were trained under a single, fixed protocol with no per-model grid search or differential tuning: AdamW optimizer, initial learning rate 1e-4 with cosine annealing, batch size 16, 100 epochs, identical data augmentations, and weight decay 1e-4. Complex modules (SSMs, Mamba, cross-view transformers) used only the initialization and regularization defaults from their original implementations; no additional hyperparameters were searched or adjusted beyond those applied to the gated depthwise convolution baseline. We will add a new subsection in Methods (and a supplementary table) that lists every shared hyperparameter value and confirms the uniform procedure was followed for all backbones and fusion variants. This revision directly supports the fusion complexity inversion claim by removing any ambiguity about fairness of comparison. revision: yes
Circularity Check
No circularity: purely empirical benchmark with direct performance measurements
full rationale
The paper reports R² values from 17 model configurations evaluated on the CSIRO Pasture Biomass dataset. No equations, derivations, or fitted parameters are presented that reduce to their own inputs by construction. The 'fusion complexity inversion' is an observed empirical pattern, not a derived result. No self-citations are load-bearing for any central claim, and backbone pretraining effects are measured directly. This is a standard empirical comparison without circular reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Gated depthwise convolution layers
- Backbone scale selection
axioms (1)
- domain assumption The CSIRO Pasture Biomass benchmark provides representative sparse agricultural data with reliable lab-validated targets.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a two layer gated depthwise convolution (R² = 0.903) outperforms cross view attention transformers (0.833), bidirectional SSMs (0.819), and full Mamba (0.793)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Combining satellite imagery and machine learning to predict poverty,
N. Jean, M. Burke, M. Xie, W. M. Davis, D. B. Lobell, and S. Ermon, “Combining satellite imagery and machine learning to predict poverty,” Science, vol. 353, no. 6301, pp. 790–794, 2016
work page 2016
-
[2]
C. Adjorlolo, O. Mutanga, and M. A. Cho, “Estimation of canopy nitrogen concentration across C3 and C4 grasslands using WorldView-2 multispectral data,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 7, no. 11, pp. 4385–4392, 2014
work page 2014
-
[3]
Understanding Robustness of Transformers for Image Classification,
S. Bhojanapalli, W. Chen, A. Veit, and A. S. Rawat, “Understanding Robustness of Transformers for Image Classification,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021
work page 2021
-
[4]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9650–9660, 2021
work page 2021
-
[5]
Self-supervised pre-training for remote sensing image analysis,
D. Wang, J. Zhang, B. Du, G. S. Xia, and D. Tao, “Self-supervised pre-training for remote sensing image analysis,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–16, 2022
work page 2022
-
[6]
Multi-view learning for fusion of multi-sensor data,
Y . Chen, X. Wang, Z. Zhang, and H. Liu, “Multi-view learning for fusion of multi-sensor data,”Information Fusion, vol. 79, pp. 75–94, 2022
work page 2022
-
[7]
J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y . Ng, “Multimodal deep learning,” inProceedings of the 28th International Conference on Machine Learning (ICML), pp. 689–696, 2011
work page 2011
-
[8]
Meta-learning for cross- regional crop type mapping,
M. Rußwurm, N. Jacobs, and D. Tuia, “Meta-learning for cross- regional crop type mapping,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Workshops (CVPR Agriculture-Vision Workshop), 2023
work page 2023
-
[9]
J. Gao, “NDVI – a review,”Remote Sensing Reviews, vol. 13, no. 1–2, pp. 145–174, 1996
work page 1996
-
[10]
Estimation of ground cover and vegetation height from images using deep learning,
L. Petrich, G. Lohrmann, M. Neumann, and N. Weishaupt, “Estimation of ground cover and vegetation height from images using deep learning,” Precision Agriculture, vol. 21, no. 6, pp. 1243–1262, 2020
work page 2020
-
[11]
Plant phenotyping with deep learning,
S. A. Tsaftaris, M. Minervini, and H. Scharr, “Plant phenotyping with deep learning,”Annual Review of Plant Biology, vol. 74, 2023
work page 2023
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[14]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu, “Mixed precision training,” inInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[15]
Estimating pasture biomass from top-view images: A dataset for precision agriculture,
Q. Liao, D. Wang, R. Haling, J. Liu, X. Li, M. Plomecka, A. Robson, M. Pringle, R. Pirie, M. Walker, and J. Whelan, “Estimating pasture biomass from top-view images: A dataset for precision agriculture,” arXiv preprint arXiv:2510.22916, 2025
-
[16]
VMamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “VMamba: Visual state space model,”arXiv preprint arXiv:2401.10166, 2024
-
[17]
DINOv2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P. Y . Huang, S. W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “DINOv2: Learning robust visual features without supe...
work page 2024
-
[18]
O. Siméoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, et al., “DINOv3,”arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
A. Bauer, A. G. Bostrom, J. Ball, C. Applegate, T. Cheng, S. Laycock, S. M. Rojas, J. Kirwan, and J. Zhou, “Combining computer vision and interactive spatial statistics for the characterization of precision agriculture observations,”Computers and Electronics in Agriculture, vol. 162, pp. 223–234, 2019
work page 2019
-
[20]
The potential and challenge of remote sensing-based biomass estimation,
D. Lu, “The potential and challenge of remote sensing-based biomass estimation,”International Journal of Remote Sensing, vol. 27, no. 7, pp. 1297–1328, 2006
work page 2006
-
[21]
CrossViT: Cross-attention multi- scale vision transformer for image classification,
C. F. Chen, Q. Fan, and R. Panda, “CrossViT: Cross-attention multi- scale vision transformer for image classification,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 357–366, 2021
work page 2021
-
[22]
Multimodal transformer for unaligned multimodal language sequences,
Y . H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L. P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 6558–6569, 2019
work page 2019
-
[23]
Vision Mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision Mamba: Efficient visual representation learning with bidirectional state space model,” inProceedings of the 41st International Conference on Machine Learning (ICML), PMLR 235:62429–62442, 2024
work page 2024
-
[24]
A survey on vision mamba: Models, applications and challenges,
R. Xu, S. Yang, Y . Wang, Y . Cai, B. Du, and H. Chen, “A survey on vision mamba: Models, applications and challenges,”arXiv preprint arXiv:2404.18861, 2024
-
[25]
MambaVision: A hybrid Mamba-Transformer vision back- bone,
A. Hatamizadeh, H. Hosseini, N. Parchami, D. Terzopoulos, and J. Kautz, “MambaVision: A hybrid Mamba-Transformer vision back- bone,”arXiv preprint arXiv:2407.08083, 2024
-
[26]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[27]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning (ICML), PMLR 139:8748–8763, 2021
work page 2021
-
[28]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16000–16009, 2022
work page 2022
-
[29]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Am...
work page 1901
-
[30]
EfficientNet: Rethinking model scaling for convolutional neural networks,
M. Tan and Q. V . Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” inProceedings of the 36th International Conference on Machine Learning (ICML), PMLR 97:6105–6114, 2019
work page 2019
-
[31]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, pp. 5998– 6008, 2017
work page 2017
-
[32]
R. Wightman, “PyTorch image models (timm),” GitHub repository, https: //github.com/rwightman/pytorch-image-models, 2019
work page 2019
-
[33]
S. Skovsen, M. Dyrmann, A. K. Mortensen, K. A. Steen, O. Green, J. Eriksen, R. Gislum, R. N. Jørgensen, and H. Karstoft, “The Grass- Clover image dataset for semantic and hierarchical species understand- ing in agriculture,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshop), 2019
work page 2019
-
[34]
A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions,
E. Schulz, M. Speekenbrink, and A. Krause, “A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions,” Journal of Mathematical Psychology, vol. 85, pp. 1–16, 2018
work page 2018
-
[35]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),” arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
Robust estimation of a location parameter,
P. J. Huber, “Robust estimation of a location parameter,”The Annals of Mathematical Statistics, vol. 35, no. 1, pp. 73–101, 1964
work page 1964
-
[37]
Language modeling with gated convolutional networks,
Y . N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated convolutional networks,” inProceedings of the 34th Inter- national Conference on Machine Learning (ICML), PMLR 70:933–941, 2017
work page 2017
-
[38]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convo- lutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Ima- geNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L. J. Li, K. Li, and L. Fei-Fei, “Ima- geNet: A large-scale hierarchical image database,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 248–255, 2009
work page 2009
-
[40]
W. Guo, U. K. Rage, and S. Ninomiya, “Aerial imagery analysis – quantifying appearance and number of sorghum heads for breeding optimization,”Frontiers in Plant Science, vol. 9, p. 1544, 2018
work page 2018
-
[41]
ModDrop: Adaptive multi-modal gesture recognition,
N. Neverova, C. Wolf, G. Taylor, and F. Nebout, “ModDrop: Adaptive multi-modal gesture recognition,”IEEE Transactions on Pattern Analy- sis and Machine Intelligence, vol. 38, no. 8, pp. 1692–1706, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.