Recognition: 2 theorem links
· Lean TheoremGCGNet: Graph-Consistent Generative Network for Time Series Forecasting with Exogenous Variables
Pith reviewed 2026-05-15 14:14 UTC · model grok-4.3
The pith
GCGNet improves time series forecasting with exogenous variables by enforcing consistency between generated and true correlation graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GCGNet first employs a Variational Generator to produce coarse predictions. A Graph Structure Aligner then guides it by evaluating the consistency between the generated and true correlations represented as graphs that are robust to noises. Finally, a Graph Refiner refines the predictions to prevent degeneration and improve accuracy, enabling better capture of joint temporal and channel correlations.
What carries the argument
Graph Structure Aligner, which measures consistency between the correlation graphs of the generated predictions and the true data to guide the forecasting process.
If this is right
- Jointly modeling temporal and channel correlations via graph consistency outperforms two-step separate modeling approaches.
- Representing correlations as graphs provides robustness against various forms of noise in time series data.
- The Graph Refiner step prevents degeneration of predictions and enhances overall accuracy.
- Extensive tests on 12 real-world datasets confirm superior performance over state-of-the-art baselines.
Where Pith is reading between the lines
- This method could be adapted to multivariate time series without explicit exogenous variables by treating all channels similarly.
- Future work might explore dynamic graph structures that evolve over time rather than static consistency enforcement.
- Applying GCGNet to domains like financial forecasting where noise and external factors are prevalent could test its generalization.
Load-bearing premise
Representing correlations as graphs and enforcing consistency between generated and true graphs will reliably capture joint dependencies without introducing artifacts or requiring extensive tuning.
What would settle it
On a dataset with added noise, if GCGNet's graph-aligned predictions do not outperform separate-modeling baselines or if the enforced graphs deviate from true correlations without accuracy gains, the claim would be falsified.
Figures





read the original abstract
Exogenous variables offer valuable supplementary information for predicting future endogenous variables. Forecasting with exogenous variables needs to consider both past-to-future dependencies (i.e., temporal correlations) and the influence of exogenous variables on endogenous variables (i.e., channel correlations). This is pivotal when future exogenous variables are available, because they may directly affect the future endogenous variables. Many methods have been proposed for time series forecasting with exogenous variables, focusing on modeling temporal and channel correlations. However, most of them use a two-step strategy, modeling temporal and channel correlations separately, which limits their ability to capture joint correlations across time and channels. Furthermore, in real-world scenarios, time series are frequently affected by various forms of noises, underscoring the critical importance of robustness in such correlations modeling. To address these limitations, we propose GCGNet, a Graph-Consistent Generative Network for time series forecasting with exogenous variables. Specifically, GCGNet first employs a Variational Generator to produce coarse predictions. A Graph Structure Aligner then further guides it by evaluating the consistency between the generated and true correlations, where the correlations are represented as graphs, and are robust to noises. Finally, a Graph Refiner is proposed to refine the predictions to prevent degeneration and improve accuracy. Extensive experiments on 12 real-world datasets demonstrate that GCGNet outperforms state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GCGNet, a Graph-Consistent Generative Network for time series forecasting with exogenous variables. It consists of a Variational Generator for coarse predictions, a Graph Structure Aligner that enforces consistency between generated and true correlation graphs (representing joint temporal and channel correlations and claimed to be robust to noise), and a Graph Refiner to prevent degeneration and improve accuracy. The central claim is that this joint modeling via graph consistency outperforms state-of-the-art baselines on 12 real-world datasets.
Significance. If the graph consistency mechanism can be shown to reliably capture joint temporal-channel dependencies without artifacts from lagged or incomplete graph estimation, the approach would address a clear limitation of existing two-step methods and offer a more integrated way to incorporate exogenous information in noisy forecasting settings.
major comments (1)
- Graph Structure Aligner: The construction of 'true' correlation graphs from historical endogenous/exogenous series (as described in the method) cannot encode future exogenous influences that are available at inference time and may directly affect future endogenous variables. This mismatch is load-bearing for the consistency loss and the joint-modeling claim; the loss may penalize the generator for necessary deviations from an incomplete past-derived structure rather than capturing the required dependencies. The robustness-to-noise claim does not resolve this estimation gap. Please detail the exact procedure for building the true graphs and how future exogenous variables are (or are not) incorporated.
minor comments (1)
- Abstract: The claim of outperformance on 12 datasets is stated without any reference to experimental setup, baselines, metrics, error bars, or ablation results, which prevents assessment of the empirical support for the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our Graph Structure Aligner. We address the major comment below and will revise the manuscript to provide the requested details.
read point-by-point responses
-
Referee: Graph Structure Aligner: The construction of 'true' correlation graphs from historical endogenous/exogenous series (as described in the method) cannot encode future exogenous influences that are available at inference time and may directly affect future endogenous variables. This mismatch is load-bearing for the consistency loss and the joint-modeling claim; the loss may penalize the generator for necessary deviations from an incomplete past-derived structure rather than capturing the required dependencies. The robustness-to-noise claim does not resolve this estimation gap. Please detail the exact procedure for building the true graphs and how future exogenous variables are (or are not) incorporated.
Authors: We agree that additional detail is needed on the graph construction procedure. The true correlation graphs are built exclusively from historical windows of the endogenous and exogenous series using a noise-robust estimator (Pearson correlation with thresholding, as described in Section 3.2). This captures the stationary joint temporal-channel structure assumed to underlie the data. At inference, the Variational Generator receives both historical observations and the available future exogenous variables as input to produce the coarse predictions; the Graph Structure Aligner then computes the generated graph from these predictions and applies the consistency loss against the fixed historical true graph. Future exogenous values therefore influence the generated predictions (and thus the generated graph) through the generator, while the consistency term regularizes the overall structure toward the historical joint correlations. We will expand Section 3.2 with the precise algorithmic steps, input specifications, and a clarifying paragraph on the role of future exogenous variables in the generator versus the aligner. revision: yes
Circularity Check
No significant circularity in GCGNet derivation chain
full rationale
The paper describes a Variational Generator for coarse predictions, a Graph Structure Aligner enforcing consistency between generated and true correlations (represented as graphs estimated from input data series), and a Graph Refiner for final adjustments. These steps use externally computed true graphs from historical endogenous/exogenous series as an independent reference signal rather than defining them in terms of model outputs. No equations or claims reduce predictions to inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems are invoked in the provided description. The joint temporal-channel modeling via consistency loss remains an independent architectural contribution, making the derivation self-contained against external data benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- network hyperparameters and variational parameters
axioms (1)
- domain assumption Correlations between time series variables can be effectively represented as graphs that remain robust to various forms of noise
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A Graph Structure Aligner module then guides the generator by evaluating the consistency between the generated and true correlations, where the correlations are represented as graphs... Lalign = ||A - Â||1
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose GCGNet, a Graph-Consistent Generative Network... robust to noises
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
David Campos, Bin Yang, Tung Kieu, Miao Zhang, Chenjuan Guo, and Christian S Jensen. Qcore: Data-efficient, on-device continual calibration for quantized models–extended version.arXiv preprint arXiv:2404.13990,
-
[2]
Razvan-Gabriel Cirstea, Chenjuan Guo, Bin Yang, Tung Kieu, Xuanyi Dong, and Shirui Pan. Tri- former: Triangular, variable-specific attentions for long sequence multivariate time series fore- casting. InIJCAI, pp. 1994–2001,
work page 1994
-
[3]
Long-term forecasting with tide: Time-series dense encoder.Trans
Abhimanyu Das, Weihao Kong, Andrew Leach, Shaan Mathur, Rajat Sen, and Rose Yu. Long-term forecasting with tide: Time-series dense encoder.Trans. Mach. Learn. Res., 2023,
work page 2023
-
[4]
Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. Timevae: A variational auto- encoder for multivariate time series generation.arXiv preprint arXiv:2111.08095,
-
[5]
Amplifier: Bringing attention to ne- glected low-energy components in time series forecasting
11 Published as a conference paper at ICLR 2026 Jingru Fei, Kun Yi, Wei Fan, Qi Zhang, and Zhendong Niu. Amplifier: Bringing attention to ne- glected low-energy components in time series forecasting. InAAAI, volume 39, pp. 11645–11653,
work page 2026
-
[6]
Hans Hersbach, Bill Bell, Paul Berrisford, Shoji Hirahara, Andr´as Hor´anyi, Joaqu´ın Mu˜noz-Sabater, Julien Nicolas, Carole Peubey, Raluca Radu, Dinand Schepers, et al. The era5 global reanalysis. Quarterly journal of the royal meteorological society, 146(730):1999–2049,
work page 1999
-
[7]
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Yifan Hu, Yuante Li, Peiyuan Liu, Yuxia Zhu, Naiqi Li, Tao Dai, Shu-tao Xia, Dawei Cheng, and Changjun Jiang. Fintsb: A comprehensive and practical benchmark for financial time series forecasting.arXiv preprint arXiv:2502.18834, 2025a. Yifan Hu, Guibin Zhang, Peiyuan Liu, Disen Lan, Naiqi Li, Dawei Cheng, Tao Dai, Shu-Tao Xia, and Shirui Pan. Timefilter: ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Temporal fusion transformers for interpretable multi-horizon time series forecasting
12 Published as a conference paper at ICLR 2026 Bryan Lim, Sercan ¨O Arık, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting. 37(4):1748–1764,
work page 2026
-
[9]
Follow your pose: Pose-guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Xiu Li, and Qifeng Chen. Follow your pose: Pose-guided text-to-video generation using pose-free videos. InAAAI, volume 38, pp. 4117–4125, 2024a. Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fin...
-
[10]
13 Published as a conference paper at ICLR 2026 Xuecheng Qi, Huiqi Hu, Jinwei Guo, Chenchen Huang, Xuan Zhou, Ning Xu, Yu Fu, and Aoying Zhou. High-availability in-memory key-value store using rdma and optane dcpmm.Frontiers of Computer Science, 17(1):171603,
work page 2026
-
[11]
Xiangfei Qiu, Hanyin Cheng, Xingjian Wu, Jilin Hu, and Chenjuan Guo. A comprehensive survey of deep learning for multivariate time series forecasting: A channel strategy perspective.arXiv preprint arXiv:2502.10721, 2025a. Xiangfei Qiu, Zhe Li, Wanghui Qiu, Shiyan Hu, Lekui Zhou, Xingjian Wu, Zhengyu Li, Chenjuan Guo, Aoying Zhou, Zhenli Sheng, Jilin Hu, C...
-
[12]
Instance Normalization: The Missing Ingredient for Fast Stylization
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Instance normalization: The missing in- gredient for fast stylization.arXiv preprint arXiv:1607.08022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
14 Published as a conference paper at ICLR 2026 Stylianos I Vagropoulos, GI Chouliaras, Evaggelos G Kardakos, Christos K Simoglou, and Anas- tasios G Bakirtzis. Comparison of sarimax, sarima, modified sarima and ann-based models for short-term pv generation forecasting. InENERGYCON, pp. 1–6,
work page 2026
-
[14]
15 Published as a conference paper at ICLR 2026 Xinle Wu, Xingjian Wu, Bin Yang, Lekui Zhou, Chenjuan Guo, Xiangfei Qiu, Jilin Hu, Zhenli Sheng, and Christian S Jensen. Autocts++: zero-shot joint neural architecture and hyperparameter search for correlated time series forecasting.The VLDB Journal, 33(5):1743–1770,
work page 2026
-
[15]
Chengqing Yu, Fei Wang, Zezhi Shao, Tangwen Qian, Zhao Zhang, Wei Wei, Zhulin An, Qi Wang, and Yongjun Xu. Ginar+: A robust end-to-end framework for multivariate time series forecasting with missing values.IEEE Transactions on Knowledge and Data Engineering, 37(8):4635–4648, 2025a. Chengqing Yu, Fei Wang, Chuanguang Yang, Zezhi Shao, Tao Sun, Tangwen Qian...
-
[16]
16 Published as a conference paper at ICLR 2026 A EXPERIMENTALDETAILS A.1 DATASETS Table 6: Statistics of datasets. Ex. and En. are abbreviations for the Exogenous variables and Endogenous variables, respectively. Dataset #Num Sampling Frequency Lengths Split Ex. Descriptions En. Descriptions NP 2 1 Hour 52,416 7:1:2 Grid Load, Wind Power Nord Pool Electr...
work page 2026
-
[17]
as exogenous variables, including temperature, surface pressure, relative humidity, wind speed, wind direction, and total precipitation. It is also worth noting that modern deep learning research typically evaluates models on a diverse collection of datasets to demonstrate generalization across different application domains (Ma et al., 2024a;b; 2025e; Yan...
work page 2023
-
[18]
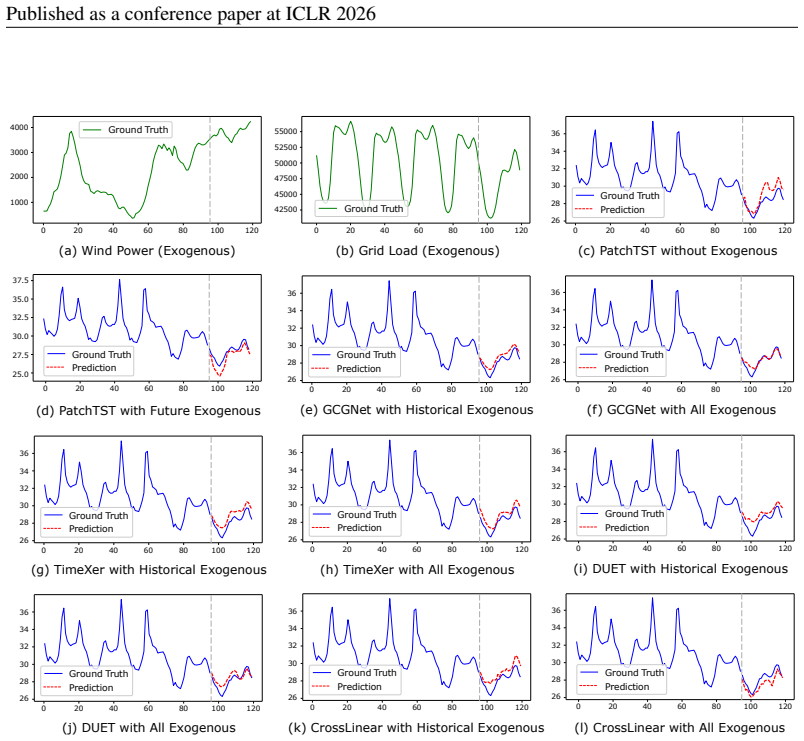
in Python 3.8 and execute on an NVIDIA Tesla-A800 GPU. We do not use the “Drop Last” operation during testing. To ensure reproducibility and facilitate experimenta- tion, datasets and code are available at: https://github.com/decisionintelligence/GCGNet. 17 Published as a conference paper at ICLR 2026 0 20 40 60 80 Ground Truth 1000 4000 3000 2000 100 120...
work page 2026
-
[19]
Figure 6a 32 64 128 256 512 Patch dimension 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60MAE DE Energy NP PJM (a) Patch dimension 32 64 128 256 512 VAE latent dimension 0.25 0.30 0.35 0.40 0.45 0.50MAE DE Energy NP PJM (b) V AE latent dimension 1 2 3 4 5 GCN layers 0.25 0.30 0.35 0.40 0.45 0.50 0.55MAE DE Energy NP PJM (c) GCN layers 0.1 0.3 0.5 0.7 0.9 Sparsit...
-
[20]
The inputs are (X endo,Y endo andX exo)
As shown in Figure 7, GCGNet consistently 20 Published as a conference paper at ICLR 2026 Table 8: Results under the setting where future exogenous variables are available and each model uses a fixed configuration across forecasting horizons. The inputs are (X endo,Y endo andX exo). The best results areRed, and the second-best restuls are Blue . Avg repre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.