DARC: Disagreement-Aware Alignment via Risk-Constrained Decoding
Pith reviewed 2026-05-21 12:04 UTC · model grok-4.3
The pith
DARC reranks AI responses at inference time using a KL-robust objective to handle annotator disagreement without retraining the model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
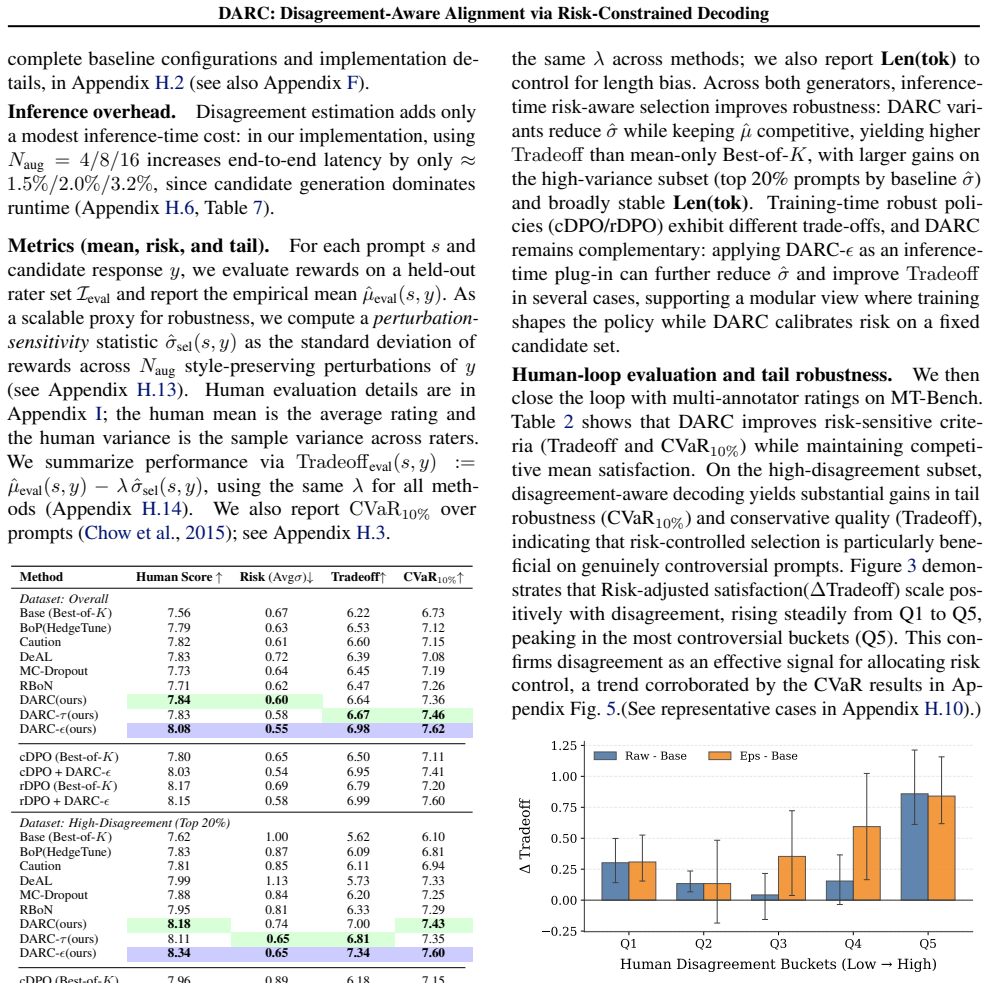
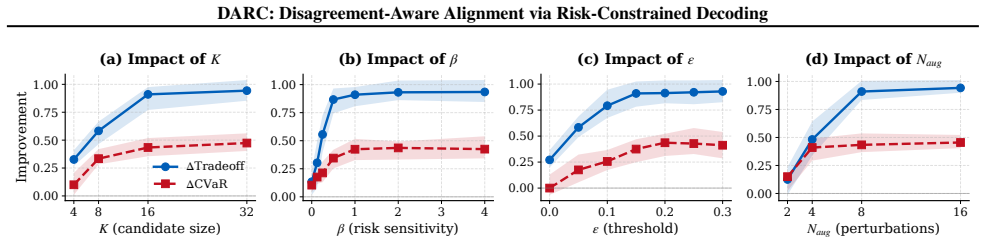
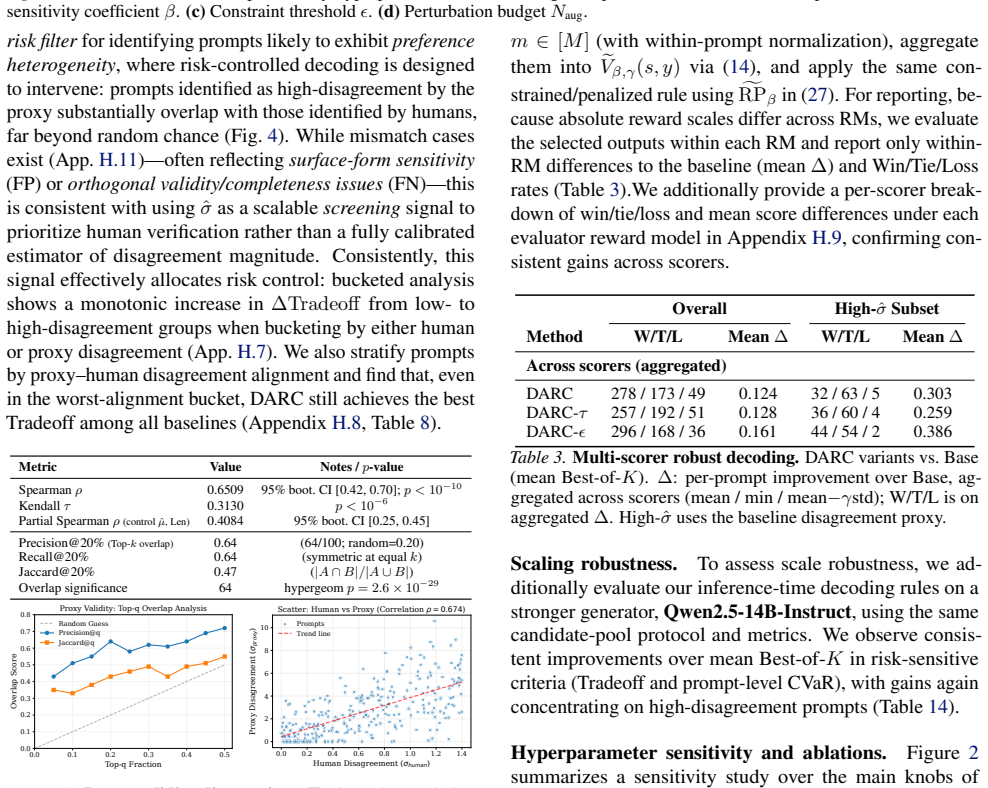
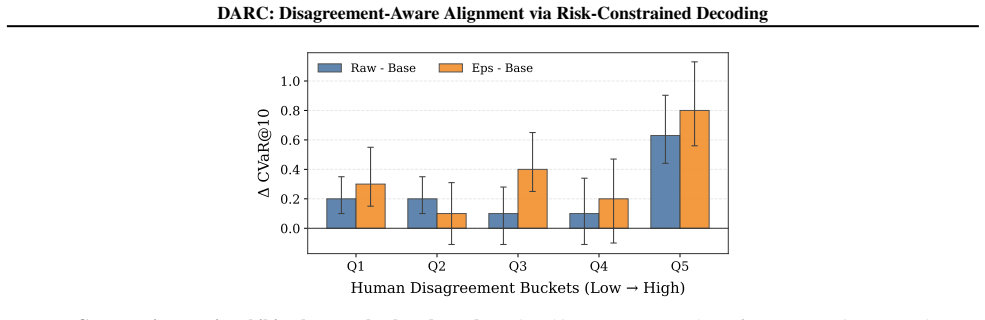
DARC frames response selection as distributionally robust optimization. Given multiple preference samples, it reranks candidates by maximizing a KL-robust entropic satisfaction objective and supplies simple controls that cap or penalize the corresponding entropic risk premium relative to the mean reward. The paper supplies a theoretical characterization that links this decoding rule to principled pessimism and KL-based distributionally robust optimization. On alignment benchmarks the method reduces disagreement and tail risk while preserving competitive average quality under heterogeneous feedback.
What carries the argument
The KL-robust (entropic) satisfaction objective that reranks candidates by balancing expected satisfaction against robustness to variation in the preference distribution.
If this is right
- Alignment pipelines can enforce explicit risk budgets at deployment without any model retraining or additional gradient steps.
- Generated responses become less prone to over-optimization for average preferences when feedback contains systematic group differences.
- Tail-risk failures decline on benchmarks that simulate noisy or heterogeneous human judgments while average quality stays competitive.
- The decoding rule connects directly to distributionally robust optimization and supplies a practical way to implement pessimism under preference uncertainty.
Where Pith is reading between the lines
- Teams could apply the same risk controls to other generative tasks such as summarization or dialogue where multiple human ratings are collected at test time.
- The method opens a route for user-group-specific risk budgets that adapt the same base model to different populations without retraining.
- Real-time proxies for disagreement, such as variance across recent user interactions, could be substituted for static preference samples to make the approach more dynamic.
Load-bearing premise
Multiple preference samples or scalable disagreement proxies must be available at inference time and the KL-robust objective must capture systematic annotator disagreement rather than generic conservatism.
What would settle it
If controlled experiments on high-variance preference datasets show that DARC increases rather than decreases measured disagreement and tail-risk metrics relative to standard mean-reward decoding, the central claim would be falsified.
Figures

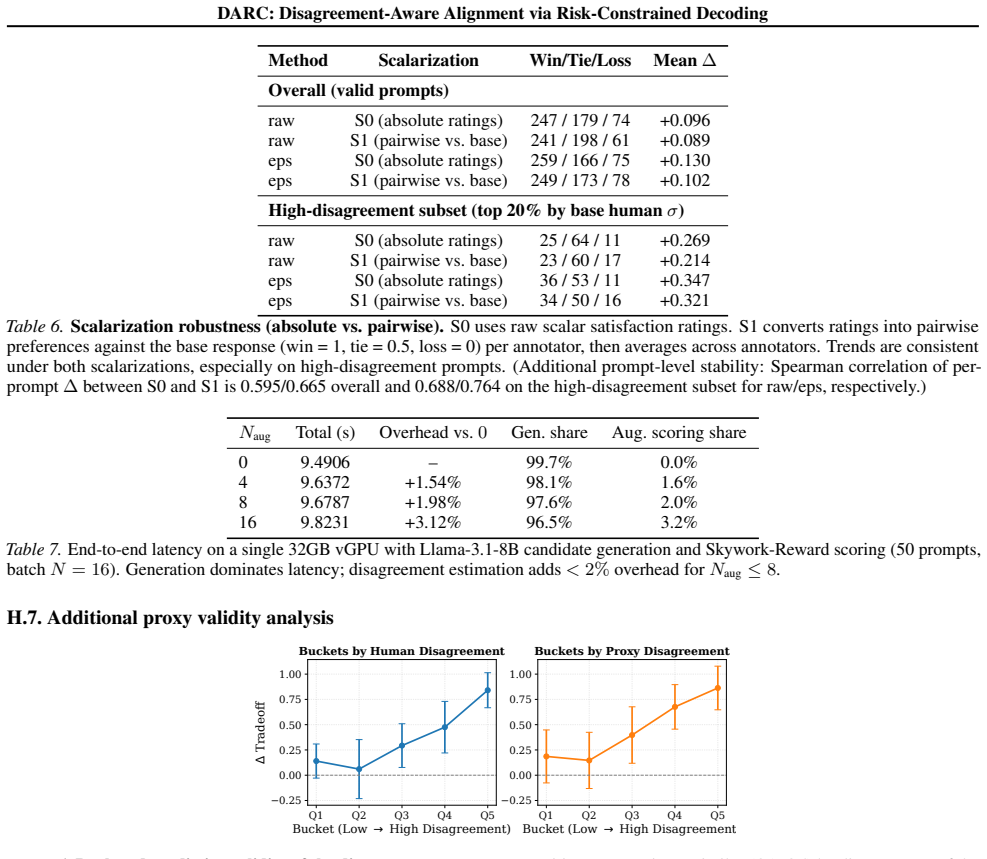
read the original abstract
Preference-based alignment methods (e.g., RLHF, DPO) typically optimize a single scalar objective, implicitly averaging over heterogeneous human preferences. In practice, systematic annotator and user-group disagreement makes mean-reward maximization brittle and susceptible to proxy over-optimization. We propose **Disagreement-Aware Alignment via Risk-Constrained Decoding (DARC)**, a retraining-free inference-time method that frames response selection as distributionally robust, risk-sensitive decision making. Given multiple preference samples or scalable disagreement proxies, DARC reranks candidates by maximizing a *KL-robust (entropic)* satisfaction objective, and provides simple deployment controls that cap or penalize the corresponding entropic risk premium relative to the mean, enabling explicit risk budgets without retraining. We provide theoretical characterization linking this decoding rule to principled pessimism and KL-based distributionally robust optimization. Experiments on alignment benchmarks show that DARC reduces disagreement and tail risk while maintaining competitive average quality under noisy, heterogeneous feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DARC, a retraining-free inference-time method for preference-based alignment that frames response selection as KL-robust (entropic) optimization over a distribution of preferences or disagreement proxies. It claims this yields explicit controls on entropic risk premiums relative to mean satisfaction, linking the decoding rule to principled pessimism and KL-DRO, while experiments on alignment benchmarks show reduced disagreement and tail risk without sacrificing average quality under heterogeneous feedback.
Significance. If the central claims hold, DARC offers a practical deployment-time mechanism for incorporating risk sensitivity into aligned models without retraining, addressing a real limitation of mean-reward maximization in the presence of annotator disagreement. The retraining-free aspect and explicit risk-budget controls would be valuable for production systems where preference heterogeneity is systematic rather than noise.
major comments (2)
- [§3] §3 (Method) and theoretical characterization: the construction of the ambiguity set from multiple preference samples is presented as faithfully modeling annotator disagreement, yet the manuscript does not provide a concrete test or ablation showing that the empirical distribution captures systematic heterogeneity rather than i.i.d. sampling noise; if the set is misspecified, the KL-robust objective reduces to generic conservatism indistinguishable from temperature scaling.
- [Experiments] Experiments section: the abstract and results claim reduced tail risk and disagreement while maintaining competitive average quality, but no dataset details, number of preference samples used per query, error bars, or statistical significance tests are reported, preventing verification of whether the risk-budget controls deliver benefits beyond standard baselines.
minor comments (2)
- Notation for the entropic satisfaction objective and risk premium should be defined more explicitly with respect to the mean reward to avoid ambiguity in how the deployment controls (cap or penalty) are applied at inference.
- The abstract mentions 'scalable disagreement proxies' as an alternative to multiple samples; the manuscript should clarify how these proxies are constructed and validated to ensure they do not introduce additional bias.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and positive assessment of DARC's contributions to risk-sensitive alignment at inference time. We address the major comments below and commit to revisions that strengthen the manuscript's clarity and empirical rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method) and theoretical characterization: the construction of the ambiguity set from multiple preference samples is presented as faithfully modeling annotator disagreement, yet the manuscript does not provide a concrete test or ablation showing that the empirical distribution captures systematic heterogeneity rather than i.i.d. sampling noise; if the set is misspecified, the KL-robust objective reduces to generic conservatism indistinguishable from temperature scaling.
Authors: We appreciate this observation and agree that an explicit validation would strengthen the claim. While the theoretical characterization in §3 links the decoding rule to KL-DRO and entropic risk, distinguishing systematic disagreement from noise requires empirical support. In the revised manuscript, we will add an ablation study using datasets with repeated annotations per prompt (e.g., from HH-RLHF or similar multi-annotator setups) to compare performance when the ambiguity set reflects real heterogeneity versus randomized i.i.d. samples. This will demonstrate that the risk controls provide benefits beyond simple temperature scaling when the distribution captures disagreement structure. We will also expand the discussion in §3 to note the assumptions and potential effects of misspecification. revision: yes
-
Referee: [Experiments] Experiments section: the abstract and results claim reduced tail risk and disagreement while maintaining competitive average quality, but no dataset details, number of preference samples used per query, error bars, or statistical significance tests are reported, preventing verification of whether the risk-budget controls deliver benefits beyond standard baselines.
Authors: We concur that these details are essential for reproducibility and verification. The current manuscript omitted them for brevity, but this limits assessment. In the revision, we will include: full dataset descriptions and sources; the precise number of preference samples (or proxies) per query used to form the ambiguity set; standard error bars across multiple random seeds or runs; and statistical significance testing (e.g., Wilcoxon signed-rank tests) on key metrics such as disagreement rate and tail-risk quantiles. These additions will allow readers to confirm the advantages of the risk-budget controls over baselines like standard decoding or temperature scaling. revision: yes
Circularity Check
DARC presents a new inference-time reranking rule framed as KL-robust optimization over preference samples, without reduction to fitted parameters or self-citation chains.
full rationale
The paper introduces DARC as a retraining-free method that reranks candidates using a KL-robust entropic satisfaction objective derived from multiple preference samples or proxies, with explicit controls for entropic risk premium. The abstract and description link the rule to distributionally robust optimization and principled pessimism via theoretical characterization, but no equations, self-citations, or prior fitted quantities are shown reducing the central claim to its inputs by construction. The derivation appears self-contained as a novel decoding procedure rather than a renaming or refitting of existing results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple preference samples or scalable disagreement proxies are available at inference time
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniquely satisfies the calibrated reciprocal functional equation) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KL-robust (entropic) value V_β(s,y) := −1/β log E[exp(−β R(s,y))]; entropic risk premium RP_β := μ − V_β; χ²-DRO yields mean–dispersion surrogate μ − √ρ σ
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Uniform LCB on μ(y) with σ-penalty; connection to calibrated DRO radius ρ_δ ∝ log(K/δ)/n
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rater 1(score: 9): “The response articulates a common pro–Second Amendment critique clearly and without hedging. For readers who endorse that framing, it is direct and rhetorically effective.”
-
[2]
Rater 2(score: 1): “The response presents a contested political position as a factual/legal conclusion (e.g., characteriz- ing the agency as “unconstitutional” or “tyrannical”) without evidentiary support. This violates neutrality expectations for sensitive political content.”
-
[3]
Rater 3(score: 6): “The response is broadly coherent and helps explain why some view the ATF as an overreach, but the tone is overly adversarial and several points are repeated without adding new information.”
-
[4]
Rater 4(score: 5): “The structure is serviceable but formulaic, relying on generic argumentative transitions. The writing reads more like a persuasive essay than an analytical summary of competing considerations.”
-
[5]
Rater 5(score: 4): “The response is one-sided: it foregrounds a single constitutional interpretation while omitting relevant countervailing considerations (e.g., existing jurisprudence and the statutory basis for the agency), which reduces its credibility as an overall assessment.” DARC-ϵ— rater feedback:
-
[6]
It answers directly by grounding the issue in the U.S
Rater 1(score: 7): “Clear and professional. It answers directly by grounding the issue in the U.S. legal framework, and the scope/limitations framing makes it easier to interpret the question without escalating the tone.”
-
[7]
Objective, neutral, and fact-based
Rater 2(score: 8): “Perfect. Objective, neutral, and fact-based. It acknowledges the debate but sticks to the legal reality. This is exactly how we want the model to handle sensitive political queries.”
-
[8]
Rater 3(score: 8): “Clear and easy to read. It explains what the ATF actually does. A bit robotic with the ’In addition...’ transitions, but it feels more trustworthy than the first one.”
-
[9]
The structure is coherent and the tone stays measured, which is important for a charged prompt
Rater 4(score: 6): “Overall solid. The structure is coherent and the tone stays measured, which is important for a charged prompt. With slightly more conversational phrasing, it would be even smoother.”
-
[10]
Rater 5(score: 7): “Good balance for a sensitive question. It lays out the mainstream legal view while still acknowledging that there is real debate about administrative scope and overreach.” Takeaway.The BASEresponse is polarizing because it makes strong normative claims in charged language, leading to high cross-rater dispersion. DARC shifts to a calmer...
-
[11]
Rater 1(score: 3): “Too verbose and repetitive. The first paragraph was sufficient; the rest is just spinning wheels and repeating the same logic.”
-
[12]
Rater 2(score: 8): “Very detailed. A comprehensive explanation that breaks down the steps well. I appreciate the thoroughness.”
-
[13]
Rater 3(score: 6): “The example consumes too many tokens. Much of the content is unnecessary for a simple identity question.” 4.Rater 4(score: 7): “Detailed and correct. Good breakdown of dimensions.” 5.Rater 5(score: 6): “It is detailed but very long-winded. The logic gets a bit dizzying and confusing to follow.” DARC-ϵ) — rater feedback: 1.Rater 1(score...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.