Recognition: 2 theorem links
· Lean TheoremRethinking the Harmonic Loss via Non-Euclidean Distance Layers
Pith reviewed 2026-05-15 12:55 UTC · model grok-4.3
The pith
Swapping the distance metric inside harmonic loss yields better accuracy, stability, and lower emissions than the original Euclidean version or cross-entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
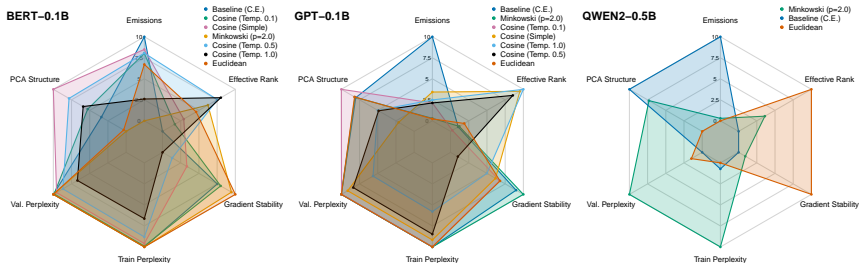
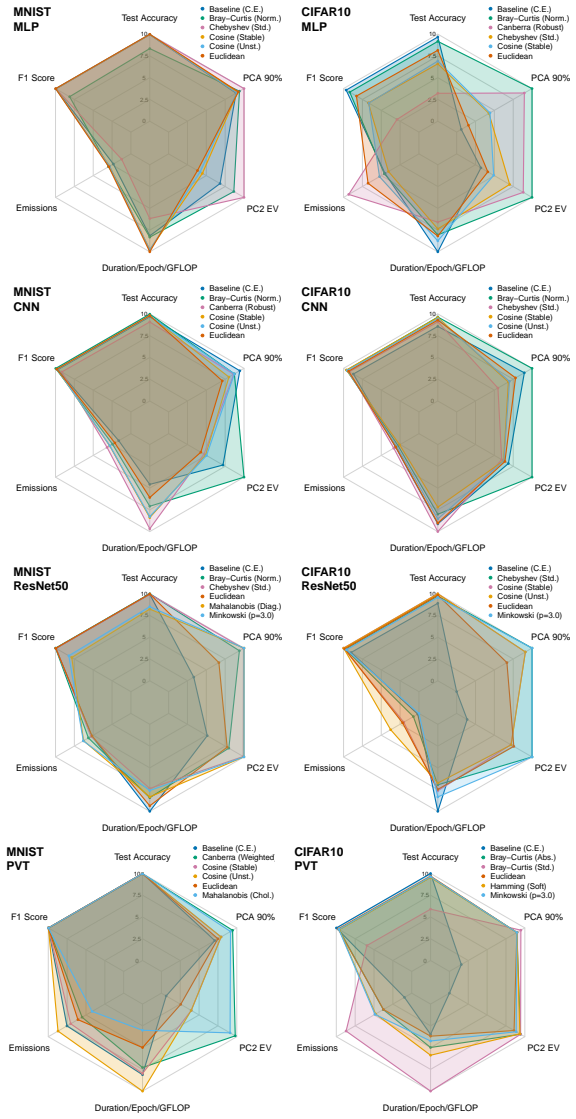
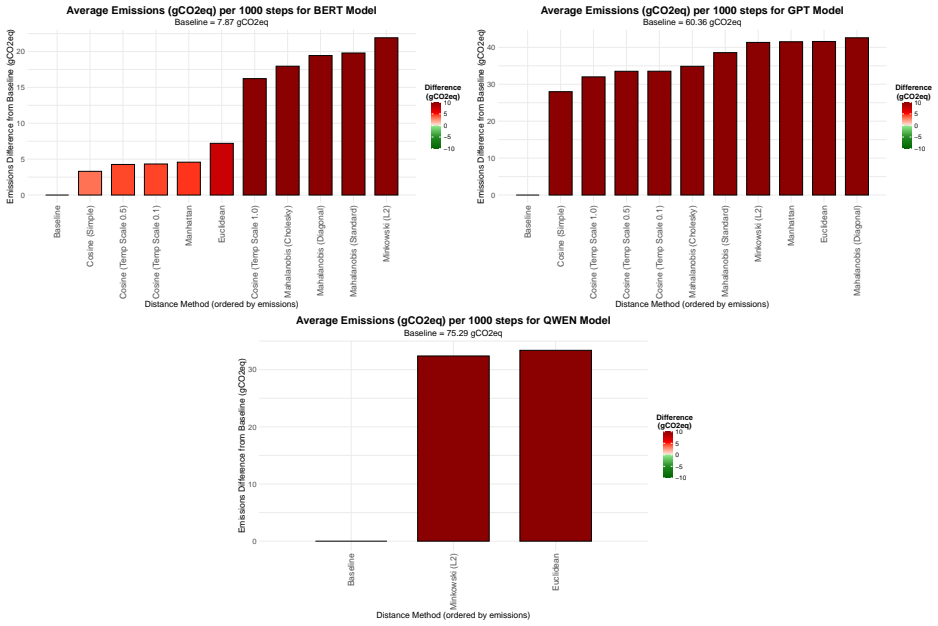
Replacing the Euclidean distance inside the harmonic loss with a range of other metrics produces distance-tailored harmonic losses that, on vision backbones, give higher accuracy and lower carbon emissions with cosine distance and greater interpretability with Bray-Curtis or Mahalanobis distance; on large language models the cosine variant improves gradient stability, representation structure, and emission reductions compared with both cross-entropy and the Euclidean harmonic head.
What carries the argument
Distance-tailored harmonic loss layers that substitute a chosen non-Euclidean metric for the original Euclidean distance when computing the loss between model outputs and targets.
If this is right
- Cosine harmonic loss becomes a drop-in candidate for training both vision and language models when emission reduction is a design goal.
- Bray-Curtis or Mahalanobis harmonic losses can be selected when post-hoc interpretability of class boundaries is prioritized over raw speed.
- Training dynamics on language models become more stable when the loss uses cosine rather than Euclidean or cross-entropy geometry.
- Overall carbon cost of large-scale training can be lowered by metric choice inside an existing loss template without altering model size.
Where Pith is reading between the lines
- The same substitution principle could be tested on other distance-based losses or on reinforcement-learning objectives.
- If cosine distance proves robust across more domains, it may become the default geometry for any loss that compares embeddings to targets.
- The interpretability gains from Bray-Curtis and Mahalanobis suggest that metric choice can be treated as a tunable hyper-parameter for downstream explanation methods.
Load-bearing premise
Changing only the distance function inside the loss is sufficient to obtain the reported gains in accuracy, stability, and emissions without further changes to architecture, optimizer, or training schedule.
What would settle it
A controlled re-training experiment on the same vision or language model and dataset that swaps only the distance metric in the harmonic loss and measures whether accuracy, gradient norms, or measured carbon output change by more than a few percent.
Figures












read the original abstract
Cross-entropy loss has long been the standard choice for training deep neural networks, yet it suffers from interpretability limitations, unbounded weight growth, and inefficiencies that can contribute to costly training dynamics. The harmonic loss is a distance-based alternative grounded in Euclidean geometry that improves interpretability and mitigates phenomena such as grokking, or delayed generalization on the test set. However, the study of harmonic loss remains narrow: only Euclidean distance is explored, and no systematic evaluation of computational efficiency or sustainability was conducted. We extend harmonic loss by systematically investigating a broad spectrum of distance metrics as replacements for the Euclidean distance. We comprehensively evaluate distance-tailored harmonic losses on both vision backbones and large language models. Our analysis is framed around a three-way evaluation of model performance, interpretability, and sustainability. On vision tasks, cosine distances provide the most favorable trade-off, consistently improving accuracy while lowering carbon emissions, whereas Bray-Curtis and Mahalanobis further enhance interpretability at varying efficiency costs. On language models, cosine-based harmonic losses improve gradient and learning stability, strengthen representation structure, and reduce emissions relative to cross-entropy and Euclidean heads. Our code is available at: https://anonymous.4open.science/r/rethinking-harmonic-loss-5BAB/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the harmonic loss framework—originally based on Euclidean distance—by systematically replacing it with alternative distance metrics including cosine, Bray-Curtis, and Mahalanobis. It evaluates the resulting distance-tailored losses on vision backbones and large language models using a three-way lens of performance, interpretability, and sustainability (carbon emissions). The central claims are that cosine distance yields the best accuracy-emissions trade-off on vision tasks, that Bray-Curtis and Mahalanobis improve interpretability at varying efficiency costs, and that cosine-based harmonic losses enhance gradient stability, representation structure, and emission reduction on language models relative to both cross-entropy and the original Euclidean harmonic loss.
Significance. If the empirical isolation of the distance metric holds and the reported gains are robust, the work would offer a practical, low-overhead route to more interpretable and potentially greener training objectives. The emphasis on sustainability metrics alongside accuracy and interpretability is timely, and the public code release supports reproducibility. However, the absence of tabulated quantitative results, error bars, or explicit hyperparameter controls in the provided abstract limits immediate assessment of whether the claimed advantages survive controlled re-implementation.
major comments (2)
- [Experiments and Results] The central empirical claims rest on the assumption that only the distance function inside the harmonic loss is changed while architecture, optimizer, learning-rate schedule, and regularization remain identical across variants. Different metrics possess distinct ranges and gradient magnitudes; without explicit verification that a single hyperparameter set was used (or that per-metric retuning was avoided), observed gains in accuracy and stability could arise from better effective optimization rather than the metric itself. This assumption is load-bearing for the three-way evaluation narrative.
- [Abstract] The abstract asserts consistent accuracy improvements and emission reductions for cosine-based losses, yet supplies no quantitative tables, error bars, statistical tests, or baseline implementation details. This makes it impossible to verify whether the claimed improvements are robust or affected by post-hoc metric selection, directly undermining the soundness of the performance and sustainability conclusions.
minor comments (1)
- [Abstract] The code link is given as an anonymous repository; the manuscript should clarify whether the released code includes the exact training scripts, hyperparameter files, and carbon-emission measurement routines used to generate the reported figures.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. Below we respond point-by-point to the major concerns raised, clarifying our methodology and outlining planned revisions.
read point-by-point responses
-
Referee: [Experiments and Results] The central empirical claims rest on the assumption that only the distance function inside the harmonic loss is changed while architecture, optimizer, learning-rate schedule, and regularization remain identical across variants. Different metrics possess distinct ranges and gradient magnitudes; without explicit verification that a single hyperparameter set was used (or that per-metric retuning was avoided), observed gains in accuracy and stability could arise from better effective optimization rather than the metric itself. This assumption is load-bearing for the three-way evaluation narrative.
Authors: The manuscript details in Section 4 that a single set of hyperparameters, including learning rate schedule and regularization, was used for all distance variants to isolate the effect of the metric. We avoided per-metric retuning. Distance normalization is applied within the loss to handle varying ranges and gradients. We will include a dedicated paragraph in the revision explicitly verifying this setup and discussing its implications for the evaluation. revision: yes
-
Referee: [Abstract] The abstract asserts consistent accuracy improvements and emission reductions for cosine-based losses, yet supplies no quantitative tables, error bars, statistical tests, or baseline implementation details. This makes it impossible to verify whether the claimed improvements are robust or affected by post-hoc metric selection, directly undermining the soundness of the performance and sustainability conclusions.
Authors: While the abstract prioritizes brevity, the full manuscript contains tables with quantitative results, error bars from repeated experiments, and baseline details in Sections 5 and 6, along with the public code. We will revise the abstract to incorporate key quantitative findings and references to these sections to better support the claims. revision: yes
Circularity Check
No circularity: purely empirical comparisons with no derivation or self-referential reduction
full rationale
The paper offers no derivation chain or equations that reduce a claimed prediction to fitted inputs defined inside the work. All results rest on experimental evaluations of distance metrics (cosine, Bray-Curtis, Mahalanobis) substituted into an existing harmonic loss on vision backbones and language models, reporting accuracy, stability, interpretability, and emissions. No self-citation is load-bearing for a uniqueness theorem or ansatz; the harmonic loss itself is referenced as prior work without the present claims depending on an unverified self-referential step. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
harmonic logit is the L2 distance ... p_W(y_k|x) = d_k^{-n} / sum d_j^{-n}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend harmonic loss by systematically investigating a broad spectrum of distance metrics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aggarwal, Alexander Hinneburg, and Daniel A
Charu C. Aggarwal, Alexander Hinneburg, and Daniel A. Keim. 2001. On the Surprising Behavior of Distance Metrics in High Dimensional Spaces. InICDT (Lecture Notes in Computer Science, Vol. 1973). Springer, 420–434
work page 2001
-
[2]
Nazhir Amaya-Tejera, Margarita Gamarra, Jorge I Vélez, and Eduardo Zurek. 2024. A distance- based kernel for classification via Support Vector Machines.Frontiers in Artificial Intelligence 7 (2024), 1287875
work page 2024
-
[3]
Baek, Ziming Liu, Riya Tyagi, and Max Tegmark
David D. Baek, Ziming Liu, Riya Tyagi, and Max Tegmark. 2025. Harmonic Loss Trains Interpretable AI Models.arXiv preprint arXiv:2502.01628(2025). doi: 10.48550/arXiv.2502. 01628
-
[4]
Adrien Bardes, Jean Ponce, and Yann LeCun. 2022. VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https: //openreview.net/forum?id=xm6YD62D1Ub
work page 2022
- [5]
-
[6]
Leonard Bereska and Stratis Gavves. 2024. Mechanistic Interpretability for AI Safety - A Review.Trans. Mach. Learn. Res.2024 (2024)
work page 2024
-
[7]
Malik Boudiaf, Jérôme Rony, Imtiaz Masud Ziko, Eric Granger, Marco Pedersoli, Pablo Piantanida, and Ismail Ben Ayed. 2020. A unifying mutual information view of metric learning: cross-entropy vs. pairwise losses. InEuropean conference on computer vision. Springer, 548–564
work page 2020
-
[8]
Anne Chao, Robin L Chazdon, Robert K Colwell, and Tsung-Jen Shen. 2010. An additive decomposition formula for the Bray–Curtis dissimilarity and their ecological meaning.Ecological Modelling221, 9 (2010), 1275–1283
work page 2010
-
[9]
Hanting Chen, Yunhe Wang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, and Chang Xu. 2020. AdderNet: Do We Really Need Multiplications in Deep Learning?. InCVPR. Computer Vision Foundation / IEEE, 1465–1474
work page 2020
-
[10]
Kwantae Cho, Jong-hyuk Roh, Youngsam Kim, and Sangrae Cho. 2019. A performance com- parison of loss functions. In2019 International Conference on Information and Communication Technology Convergence (ICTC). IEEE, 1146–1151
work page 2019
-
[11]
Hongjun Choi, Anirudh Som, and Pavan K. Turaga. 2020. AMC-Loss: Angular Margin Contrastive Loss for Improved Explainability in Image Classification. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, WA, USA, June 14-19, 2020. Computer Vision Foundation / IEEE, 3659–3666. doi:10.1109/ CVPRW50498.2020.00427
-
[12]
Collin Coil, Kamil Faber, Bartlomiej Sniezynski, and Roberto Corizzo. 2025. Distance-based change point detection for novelty detection in concept-agnostic continual anomaly detection. Journal of Intelligent Information Systems(2025), 1–39. 14
work page 2025
-
[13]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. ArcFace: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4690–4699
work page 2019
-
[14]
Yinpeng Dong, Hang Su, Jun Zhu, and Bo Zhang. 2017. Improving interpretability of deep neural networks with semantic information. InProceedings of the IEEE conference on computer vision and pattern recognition. 4306–4314
work page 2017
-
[15]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. 2022. Toy Models of Superposition.Transformer Circuits Thread(2022). https: //transformer-circuits.pub/...
work page 2022
-
[16]
Fartash Faghri, David Duvenaud, David J. Fleet, and Jimmy Ba. 2020. A Study of Gradient Variance in Deep Learning.CoRRabs/2007.04532 (2020). arXiv:2007.04532 https://arxiv. org/abs/2007.04532
-
[17]
FAR AI. 2023. Uncovering Latent Human Wellbeing in LLM Embeddings. https://far. ai/news/uncovering-latent-human-wellbeing-in-llm-embeddings . Shows first principal component of GPT-3 embeddings correlates with ethics/well-being labels
work page 2023
-
[18]
Alessandro Fuschi, Alessandra Merlotti, and Daniel Remondini. 2025. Microbiome data: tell me which metrics and I will tell you which communities.ISME communications5, 1 (2025), ycaf125
work page 2025
-
[19]
Quentin Garrido, Randall Balestriero, Laurent Najman, and Yann LeCun. 2023. RankMe: Assessing the Downstream Performance of Pretrained Self-Supervised Representations by Their Rank. InICML (Proceedings of Machine Learning Research, Vol. 202). PMLR, 10929–10974
work page 2023
-
[20]
Arie Giloni and Manfred Padberg. 2003. The finite sample breakdown point ofℓ1-regression. In SIAM Journal on Optimization, Vol. 14. SIAM, 608–620
work page 2003
-
[21]
María José Gómez-Silva, Arturo de la Escalera, and José María Armingol. 2021. Back- propagation of the Mahalanobis distance through a deep triplet learning model for person re-identification.Integrated Computer-Aided Engineering28, 3 (2021), 277–288
work page 2021
-
[22]
Santiago Gonzalez and Risto Miikkulainen. 2020. Improved training speed, accuracy, and data utilization through loss function optimization. In2020 IEEE congress on evolutionary computation (CEC). IEEE, 1–8
work page 2020
-
[23]
Misgina Tsighe Hagos, Niamh Belton, Kathleen M Curran, and Brian Mac Namee. 2023. Distance-aware explanation based learning. In2023 IEEE 35th International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 279–286
work page 2023
-
[24]
Yihan He, Yuan Cao, Hong-Yu Chen, Dennis Wu, Jianqing Fan, and Han Liu. 2024. Can Transformers Perform PCA? https://openreview.net/forum?id=mjDNVksC5G ICLR 2025 Conference Withdrawn Submission
work page 2024
-
[25]
Li-Yu Hu, Min-Wei Huang, Shih-Wen Ke, and Chih-Fong Tsai. 2016. The distance function effect on k-nearest neighbor classification for medical datasets.SpringerPlus5, 1 (2016), 1304. 15
work page 2016
-
[26]
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. 2024. Sparse Autoencoders Find Highly Interpretable Features in Language Models. InInternational Conference on Learning Representations (ICLR), Poster.https://openreview.net/forum? id=F76bwRSLeK
work page 2024
-
[27]
Eric Jang, Shixiang Gu, and Ben Poole. 2017. Categorical Reparameterization with Gumbel- Softmax. InICLR (Poster). OpenReview.net
work page 2017
-
[28]
Katarzyna Janocha and Wojciech Marian Czarnecki. 2017. On loss functions for deep neural networks in classification.arXiv preprint arXiv:1702.05659(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Mingyu Jin, Qinkai Yu, Jingyuan Huang, Qingcheng Zeng, Zhenting Wang, Wenyue Hua, Haiyan Zhao, Kai Mei, Yanda Meng, Kaize Ding, Fan Yang, Mengnan Du, and Yongfeng Zhang. 2025. Exploring Concept Depth: How Large Language Models Acquire Knowledge and Concept at Different Layers?. InProceedings of the 31st International Conference on Computational Linguistic...
work page 2025
-
[30]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. 2022. Understanding Dimensional Collapse in Contrastive Self-supervised Learning. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=YevsQ05DEN7
work page 2022
-
[31]
2023.Understanding and Controlling the Activations of Language Models
Ole Jorgensen. 2023.Understanding and Controlling the Activations of Language Models. Ph.D. Dissertation. Imperial College London. https://ojorgensen.github.io/assets/ pdfs/Imperial_Dissertation.pdf
work page 2023
-
[32]
Vandana Kalra, Indu Kashyap, and Harmeet Kaur. 2022. Effect of distance measures on K-nearest neighbour classifier. In2022 Second International Conference on Computer Science, Engineering and Applications (ICCSEA). IEEE, 1–7
work page 2022
-
[33]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 6769–6781
work page 2020
-
[34]
S. L. Keeling and K. Kunisch. 2016. Robustℓ1 approaches to computing the geometric median and principal and independent components.Journal of Mathematical Imaging and Vision56, 2 (2016), 286–300
work page 2016
-
[35]
Godfrey N. Lance and William T. Williams. 1967. A General Theory of Classificatory Sorting Strategies: 1. Hierarchical Systems.Comput. J.9, 4 (1967), 373–380
work page 1967
-
[36]
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks.Advances in Neural Information Processing Systems31 (2018)
work page 2018
-
[37]
Yunwen Lei and Yiming Ying. 2020. Fine-Grained Analysis of Stability and Generalization for Stochastic Gradient Descent. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119). PMLR, 5809–5819.http://proceedings.mlr.press/v119/lei20c.html 16
work page 2020
-
[38]
Junhong Liu, Yijie Lin, Liang Jiang, Jia Liu, Zujie Wen, and Xi Peng. 2022. Improve Inter- pretability of Neural Networks via Sparse Contrastive Coding. InFindings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Compu...
-
[39]
Chunjie Luo, Jianfeng Zhan, Xiaohe Xue, Lei Wang, Rui Ren, and Qiang Yang. 2018. Cosine Normalization: Using Cosine Similarity Instead of Dot Product in Neural Networks. InICANN (1) (Lecture Notes in Computer Science, Vol. 11139). Springer, 382–391
work page 2018
-
[40]
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. 2016. The concrete distribution: A continuous relaxation of discrete random variables.arXiv preprint arXiv:1611.00712(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Dimity Miller, Niko Sunderhauf, Michael Milford, and Feras Dayoub. 2021. Class anchor clustering: A loss for distance-based open set recognition. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3570–3578
work page 2021
-
[42]
Ibrahim Omara, Ahmed Hagag, Guangzhi Ma, Fathi E. Abd El-Samie, and Enmin Song. 2021. A novel approach for ear recognition: learning Mahalanobis distance features from deep CNNs. Mach. Vis. Appl.32, 1 (2021), 38
work page 2021
-
[43]
Tianyu Pang, Chao Du, Yinpeng Dong, and Jun Zhu. 2018. Max-Mahalanobis linear discriminant analysis networks. InInternational Conference on Machine Learning. PMLR, 4016–4025
work page 2018
-
[44]
Eileen Paula, Jayesh Soni, Himanshu Upadhyay, and Leonel Lagos. 2025. Comparative analysis of model compression techniques for achieving carbon efficient AI.Scientific Reports15, 1 (2025), 23461
work page 2025
-
[45]
Sun Pei-Xia, Lin Hui-Ting, and Luo Tao. 2016. Learning discriminative CNN features and simi- larity metrics for image retrieval. In2016 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC). IEEE, 1–5
work page 2016
-
[46]
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. 2022. Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets.CoRRabs/2201.02177 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
Kazi Rafat, Sadia Islam, Abdullah Al Mahfug, Md Ismail Hossain, Fuad Rahman, Sifat Momen, Shafin Rahman, and Nabeel Mohammed. 2023. Mitigating carbon footprint for knowledge distillation based deep learning model compression.Plos one18, 5 (2023), e0285668
work page 2023
-
[48]
Khan, and Fahad Shah- baz Khan
Kanchana Ranasinghe, Muzammal Naseer, Munawar Hayat, Salman H. Khan, and Fahad Shah- baz Khan. 2021. Orthogonal Projection Loss. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, 12313–12323. doi:10.1109/ICCV48922.2021.01211
-
[49]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992
work page 2019
-
[50]
Olivier Roy and Martin Vetterli. 2007. The effective rank: A measure of effective dimensionality. In2007 15th European signal processing conference. IEEE, 606–610. 17
work page 2007
-
[51]
Cynthia Rudin. 2019. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead.Nature Machine Intelligence1, 5 (2019), 206–215
work page 2019
-
[52]
Roy Schwartz, Jesse Dodge, Noah A Smith, and Oren Etzioni. 2020. Green ai.Commun. ACM 63, 12 (2020), 54–63
work page 2020
-
[53]
Kuncheng Song, Fred A Wright, and Yi-Hui Zhou. 2020. Systematic comparisons for composition profiles, taxonomic levels, and machine learning methods for microbiome-based disease prediction. Frontiers in Molecular Biosciences7 (2020), 610845
work page 2020
-
[54]
Arthur Templeton et al. 2023. Sparse Autoencoders Find Highly Interpretable Direc- tions in Language Models. https://www.alignmentforum.org/posts/Qryk6FqjtZk9FHHJR/ sparse-autoencoders-find-highly-interpretable-directions-in
work page 2023
-
[55]
Alex Turntrout. 2023. Steering GPT-2-XL by Adding an Activation Vector.https://turntrout. com/gpt2-steering-vectors
work page 2023
-
[56]
Anil Verma, Sumit Kumar Singh, Rupesh Kumar Sah, Rajiv Misra, and TN Singh. 2024. Perfor- mance Comparison of Deep Learning Models for CO2 Prediction: Analyzing Carbon Footprint with Advanced Trackers. In2024 IEEE International Conference on Big Data (BigData). IEEE, 4429–4437
work page 2024
-
[57]
Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu. 2018. CosFace: Large margin cosine loss for deep face recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5265–5274
work page 2018
-
[58]
Irene Wang, Newsha Ardalani, Mostafa Elhoushi, Daniel Jiang, Samuel Hsia, Ekin Sumbul, Divya Mahajan, Carole-Jean Wu, and Bilge Acun. 2025. CATransformers: Carbon Aware Transformers Through Joint Model-Hardware Optimization.arXiv preprint arXiv:2505.01386 (2025). doi:10.48550/arXiv.2505.01386Journal reference: NeurIPS 2025
- [59]
-
[60]
Yunshi Wen, Tengfei Ma, Ronny Luss, Debarun Bhattacharjya, Achille Fokoue, and Anak Agung Julius. 2025. Shedding Light on Time Series Classification using Interpretability Gated Networks. InICLR. OpenReview.net
work page 2025
-
[61]
Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao. 2016. A Discriminative Feature Learning Approach for Deep Face Recognition. InProceedings of the European Conference on Computer Vision (ECCV). Springer, 499–515. doi:10.1007/978-3-319-46478-7_31
-
[62]
Jinfeng Ye, Tao Li, Tao Xiong, and Ravi Janardan. 2012. A pureL1-norm principal component analysis.Computational Statistics & Data Analysis56, 12 (2012), 4474–4486
work page 2012
-
[63]
Quanshi Zhang, Ying Nian Wu, and Song-Chun Zhu. 2018. Interpretable convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition. 8827–8836
work page 2018
-
[64]
Yu Zhang, Peter Tiňo, Aleš Leonardis, and Ke Tang. 2021. A survey on neural network interpretability.IEEE transactions on emerging topics in computational intelligence5, 5 (2021), 726–742. 18 Appendix A Theoretical Properties of Distance-based Probabilistic Layers Setup.Let {(xi, yi)}n i=1 be the training set withyi ∈ {1, ..., K}. Each class has a prototy...
work page 2021
-
[65]
Stop the tracker and record interval-level metrics: emissions (kg CO2), duration, estimated CPU/GPU/RAM power and energy
-
[66]
Log cumulative emissions and training metrics (loss, lr) to W&B (if enabled)
-
[67]
Restart the tracker for the next interval to avoid long-running file locks and to attribute emissions to training phases cleanly. At the end of training, we stop the tracker one final time and persist all accumulated records to a CSV (emissions_*.csv) alongside model checkpoints. Key Configurations (Reproducibility)The following knobs are saved in run con...
-
[68]
Reduced grokking or complete elimination of delayed generalization. Training and test accuracy rise together, indicating that the model discovers the algorithmic rule rather than memorizing individual cases. 48
-
[69]
Improved interpretability via stable geometric structure. The emergence of a low– dimensional circular manifold with EV close to 1.0 serves as a quantitative and visual certificate of representation clarity. These results reinforce the core claims of the paper: harmonic losses promote structured, prototype–aligned representations and smoother, more reliab...
work page 1920
-
[70]
using 2D PCA, with class prototypes overlaid as markers. For the Euclidean harmonic head, the class clusters are roughly spherical and separated by (approximately) straight boundaries in the projection: decision regions are controlled mainly by radial distance to each prototype, yielding isotropic attraction basins around each center. Under Cosine harmoni...
-
[71]
Concept probing and visualization.Projections onto top PCs often align with semantically meaningful contrasts; e.g., the first PC of GPT-style embeddings correlated with human well- being judgments in zero-shot tests [17], and per-layer PCA can reconstruct or predict response modes in GPT-2 [31]
-
[72]
Diagnosing and localizing phenomena.Layer-wise or head-wise PCA reveals where variance concentrates, helping localize depth at which concepts emerge or consolidate (com- plementary to linear probing) [29]. Trackingsubspace distanceacross checkpoints detects representational drift during fine-tuning or domain shift
-
[73]
Sanity checks and baselines.With growing interest in sparse autoencoders (SAEs) for monosemantic features [26], PCA serves as a transparent baseline decomposition: if SAEs 63 meaningfully improve sparsity/faithfulness over PCA while matching reconstruction, that strengthens the interpretability claim [54]. PCA is most compelling under: a) approximately li...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.