Double-Precision Matrix Multiplication Emulation via Ozaki-II Scheme with FP8 Quantization
Pith reviewed 2026-05-15 13:08 UTC · model grok-4.3
The pith
A novel adaptation allows the Ozaki-II scheme to emulate DGEMM using FP8 MMA units with reduced computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a novel technique to demonstrate DGEMM emulation based on the Ozaki-II scheme that operates on FP8 MMA units. Compared to the FP8-based Ozaki-I scheme, our method significantly reduces the computational cost and enables efficient FP64 emulation.
What carries the argument
Adapted Ozaki-II scheme for FP8 quantization that modifies the algorithmic structure to work with FP8 MMA units.
Load-bearing premise
The Ozaki-II algorithmic structure can be directly modified for FP8 quantization without introducing unacceptable rounding errors or needing extra corrections that erase the cost savings.
What would settle it
A direct comparison on benchmark matrices measuring operation count and numerical error for the new FP8 Ozaki-II method versus the existing FP8 Ozaki-I method; failure to show lower cost or acceptable accuracy would disprove the claim.
Figures




read the original abstract
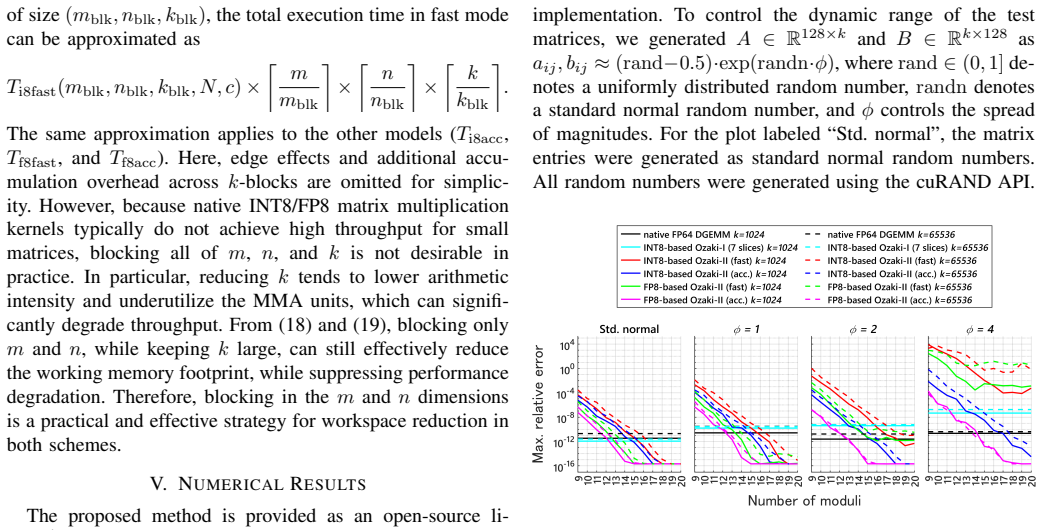
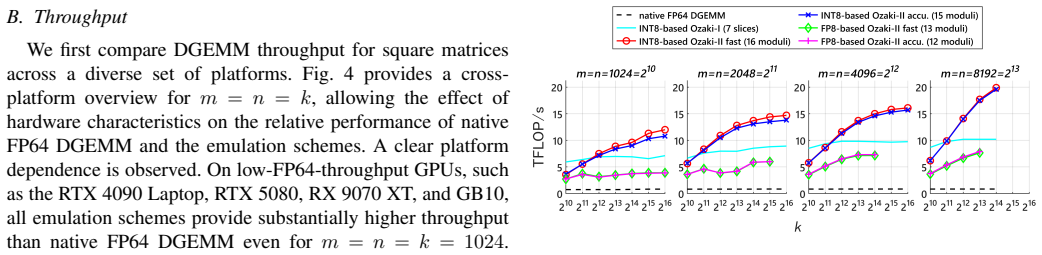
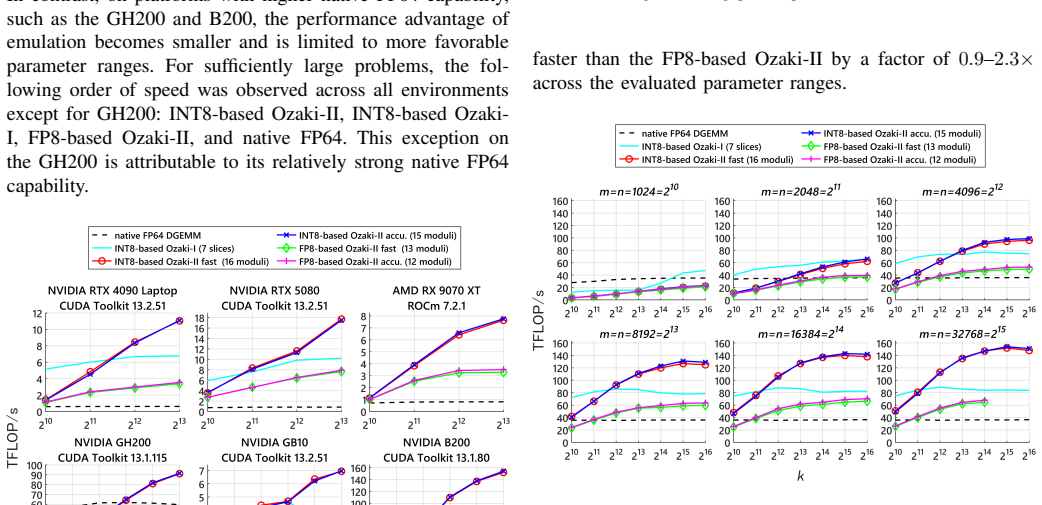
In this paper, we propose a method for emulating double-precision general matrix--matrix multiplication (DGEMM), a fundamental and performance-critical kernel in many high-performance computing applications. Ozaki-I and Ozaki-II are established DGEMM emulation schemes via low-precision matrix multiply-accumulate (MMA) units. For the Ozaki-I scheme, INT8-, FP8-, and FP16-based implementations have been proposed, all of which can be realized based on the same underlying algorithmic structure. In contrast, although INT8-based implementations of the Ozaki-II scheme have been reported, the original algorithm cannot be directly adapted to exploit FP8 MMA units. In several recent architectures, such as NVIDIA Blackwell Ultra and NVIDIA Rubin, INT8 performance has been reduced, making reliance on INT8 alone insufficient. Therefore, we introduce a novel technique to demonstrate DGEMM emulation based on the Ozaki-II scheme that operates on FP8 MMA units. Compared to the FP8-based Ozaki-I scheme, our method significantly reduces the computational cost and enables efficient FP64 emulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a novel adaptation of the Ozaki-II scheme to enable DGEMM emulation on FP8 MMA units. It observes that the original Ozaki-II algorithm cannot be directly ported to FP8 (unlike Ozaki-I, which supports INT8/FP8/FP16 under the same structure) and introduces a new technique that is claimed to reduce computational cost relative to the FP8 Ozaki-I baseline while still delivering accurate FP64 results. The motivation is the reduced INT8 throughput on recent NVIDIA architectures such as Blackwell Ultra and Rubin.
Significance. If the claimed cost reduction and error control are rigorously established, the work would be a useful incremental advance for low-precision emulation kernels on FP8-dominant hardware. It directly addresses a practical limitation of prior Ozaki schemes and could improve performance portability for scientific codes that rely on DGEMM emulation.
major comments (2)
- [Abstract and §3] Abstract and §3 (algorithm description): the central claim that the novel FP8 adaptation of Ozaki-II 'significantly reduces the computational cost' relative to FP8 Ozaki-I is not supported by any operation-count table, flop breakdown, or pseudocode. Without these, it is impossible to verify whether the added quantization or splitting steps required for FP8 dynamic-range handling erase the purported savings.
- [§4] §4 (error analysis): no forward-error bound, rounding-error analysis, or numerical verification is supplied for the FP8-quantized Ozaki-II variant. The manuscript must demonstrate that the adaptation controls accumulation error without extra corrective passes; otherwise the cost-reduction claim cannot be evaluated.
minor comments (1)
- [Abstract] The abstract and introduction repeatedly use 'Ozaki-I' and 'Ozaki-II' without a brief reminder of the original algorithmic difference; a one-sentence recap would improve readability for readers unfamiliar with the prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and have revised the manuscript to provide the requested details on operation counts and error analysis.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (algorithm description): the central claim that the novel FP8 adaptation of Ozaki-II 'significantly reduces the computational cost' relative to FP8 Ozaki-I is not supported by any operation-count table, flop breakdown, or pseudocode. Without these, it is impossible to verify whether the added quantization or splitting steps required for FP8 dynamic-range handling erase the purported savings.
Authors: We agree that an explicit breakdown strengthens the claim. In the revised version we add a table in §3 that lists the exact number of FP8 MMA operations, memory accesses, and splitting steps for both the proposed Ozaki-II adaptation and the FP8 Ozaki-I baseline. Updated pseudocode and a short flop-count derivation are included to show that the FP8-specific quantization avoids the extra splitting overhead of Ozaki-I, confirming the cost reduction. revision: yes
-
Referee: [§4] §4 (error analysis): no forward-error bound, rounding-error analysis, or numerical verification is supplied for the FP8-quantized Ozaki-II variant. The manuscript must demonstrate that the adaptation controls accumulation error without extra corrective passes; otherwise the cost-reduction claim cannot be evaluated.
Authors: We accept that a formal error analysis is required. We expand §4 with a forward-error bound derivation for the FP8-quantized Ozaki-II scheme, a rounding-error analysis demonstrating that accumulation error remains controlled without additional corrective passes, and numerical verification results that compare observed errors against the derived bounds and against the FP8 Ozaki-I baseline. revision: yes
Circularity Check
No circularity: novel FP8 adaptation of Ozaki-II presented as independent algorithmic contribution
full rationale
The paper introduces a new technique for FP8-based Ozaki-II DGEMM emulation, explicitly contrasting it with prior Ozaki-I and INT8 Ozaki-II schemes. No equations, fitted parameters, or predictions are shown that reduce to inputs by construction. References to established Ozaki schemes serve as background rather than load-bearing self-citations that force the result; the central claim rests on the described novel modification, which is presented as original work without self-referential derivation or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard rounding and associativity properties of IEEE floating-point arithmetic hold for both FP8 and FP64 operations.
Reference graph
Works this paper leans on
-
[1]
(2026) NVIDIA Vera Rubin NVL72
NVIDIA Corporation. (2026) NVIDIA Vera Rubin NVL72. Retrieved 25 January, 2026. [Online]. Available: https://www.nvidia.com/en- us/data-center/vera-rubin-nvl72
work page 2026
-
[2]
(2024) NVIDIA H200 Tensor Core GPU
——. (2024) NVIDIA H200 Tensor Core GPU. Retrieved 25 January,
work page 2024
-
[3]
Available: https://resources.nvidia.com/en-us-hopper- architecture/hpc-datasheet-sc23
[Online]. Available: https://resources.nvidia.com/en-us-hopper- architecture/hpc-datasheet-sc23
-
[4]
(2025) NVIDIA Blackwell Architecture Technical Brief v2.1
——. (2025) NVIDIA Blackwell Architecture Technical Brief v2.1. Retrieved 25 January, 2026. [Online]. Available: https://resources.nvidia.com/en-us-blackwell-architecture
work page 2025
-
[5]
(2020) Nvidia a100 tensor core gpu archi- tecture v1.0
——. (2020) Nvidia a100 tensor core gpu archi- tecture v1.0. Retrieved 5 December, 2025. [Online]. Available: https://images.nvidia.com/aem-dam/en-zz/Solutions/data- center/nvidia-ampere-architecture-whitepaper.pdf
work page 2020
-
[6]
(2023) Nvidia h100 tensor core gpu architecture v1.04
——. (2023) Nvidia h100 tensor core gpu architecture v1.04. Retrieved 5 December, 2025. [Online]. Available: https://resources.nvidia.com/en- us-hopper-architecture/nvidia-h100-tensor-c
work page 2023
-
[7]
(2025) Amd instinct mi300x apu
Advanced Micro Devices, Inc. (2025) Amd instinct mi300x apu. Retrieved 5 December, 2025. [Online]. Avail- able: https://www.amd.com/content/dam/amd/en/documents/instinct- tech-docs/data-sheets/amd-instinct-mi300a-data-sheet.pdf
work page 2025
-
[8]
(2025) Amd instinct mi300x accelera- tor
——. (2025) Amd instinct mi300x accelera- tor. Retrieved 5 December, 2025. [Online]. Avail- able: https://www.amd.com/content/dam/amd/en/documents/instinct- tech-docs/data-sheets/amd-instinct-mi300x-data-sheet.pdf
work page 2025
-
[9]
(2025) Amd instinct mi325x accelera- tor
——. (2025) Amd instinct mi325x accelera- tor. Retrieved 5 December, 2025. [Online]. Avail- able: https://www.amd.com/content/dam/amd/en/documents/instinct- tech-docs/product-briefs/instinct-mi325x-datasheet.pdf
work page 2025
-
[10]
(2025) Amd instinct mi350x gpu
——. (2025) Amd instinct mi350x gpu. Re- trieved 5 December, 2025. [Online]. Avail- able: https://www.amd.com/content/dam/amd/en/documents/instinct- tech-docs/product-briefs/amd-instinct-mi350x-gpu-brochure.pdf
work page 2025
-
[11]
(2025) Amd instinct mi355x gpu
——. (2025) Amd instinct mi355x gpu. Re- trieved 5 December, 2025. [Online]. Avail- able: https://www.amd.com/content/dam/amd/en/documents/instinct- tech-docs/product-briefs/amd-instinct-mi355x-gpu-brochure.pdf
work page 2025
-
[12]
(2025) Intel Core Ultra 200H and 200U Series Processors, Datasheet, V olume 1 of
Intel Corporation. (2025) Intel Core Ultra 200H and 200U Series Processors, Datasheet, V olume 1 of
work page 2025
- [13]
-
[14]
Google Cloud. (2026) Tpu v6e. Retrieved 25 February, 2026. [Online]. Available: https://docs.cloud.google.com/tpu/docs/v6e?hl=en
work page 2026
-
[15]
——. (2026) Tpu7x (ironwood). Retrieved 25 February, 2026. [Online]. Available: https://docs.cloud.google.com/tpu/docs/tpu7x?hl=en
work page 2026
-
[16]
K. Ozaki, T. Ogita, S. Oishi, and S. M. Rump, “Error-free transformations of matrix multiplication by using fast routines of matrix multiplication and its applications,”Numerical Algorithms, vol. 59, no. 1, pp. 95–118, 2012. [Online]. Available: https://doi.org/10.1007/s11075- 011-9478-1
-
[17]
——, “Generalization of error-free transformation for matrix multiplication and its application,”Nonlinear Theory and Its Applications, IEICE, vol. 4, no. 1, pp. 2–11, 2013. [Online]. Available: https://doi.org/10.1587/nolta.4.2
-
[18]
K. Ozaki, Y . Uchino, and T. Imamura, “Ozaki Scheme II: A GEMM-oriented emulation of floating-point matrix multiplication using an integer modular technique,” 2025. [Online]. Available: https://arxiv.org/abs/2504.08009
-
[19]
DGEMM on integer matrix multiplication unit,
H. Ootomo, K. Ozaki, and R. Yokota, “DGEMM on integer matrix multiplication unit,”The International Journal of High Performance Computing Applications, vol. 38, no. 4, pp. 297–313, 2024. [Online]. Available: https://doi.org/10.1177/10943420241239588
-
[20]
Y . Uchino, K. Ozaki, and T. Imamura, “Performance enhancement of the Ozaki Scheme on integer matrix multiplication unit,” The International Journal of High Performance Computing Applications, vol. 39, no. 3, pp. 462–476, 2025. [Online]. Available: https://doi.org/10.1177/10943420241313064
-
[21]
——, “High-performance and power-efficient emulation of matrix multiplication using INT8 matrix engines,” inProceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC Workshops ’25. St. louis, MO, USA: Association for Computing Machinery, 2025, pp. 1824–1831. [Online]. Avail...
-
[22]
D. Mukunoki, K. Ozaki, T. Ogita, and T. Imamura, “DGEMM using Tensor Cores, and its accurate and reproducible versions,” inHigh Performance Computing, P. Sadayappan, B. L. Chamberlain, G. Juckeland, and H. Ltaief, Eds. Cham: Springer International Publishing, 2020, pp. 230–248. [Online]. Available: https://doi.org/10.1007/978-3-030-50743-5 12
-
[23]
DGEMM using FP64 Arithmetic Emulation and FP8 Tensor Cores with Ozaki Scheme,
D. Mukunoki, “DGEMM using FP64 Arithmetic Emulation and FP8 Tensor Cores with Ozaki Scheme,” inProceedings of the Supercomputing Asia and International Conference on High Performance Computing in Asia Pacific Region Workshops, ser. SCA/HPCAsiaWS ’26. Osaka, Japan: Association for Computing Machinery, 2026, p. 303–311. [Online]. Available: https://doi.org/...
-
[24]
Emulation of complex matrix multiplication based on the Chinese Remainder Theorem,
Y . Uchino, Q. Ma, T. Imamura, K. Ozaki, and P. L. Gutsche, “Emulation of complex matrix multiplication based on the Chinese Remainder Theorem,” 2025. [Online]. Available: https://arxiv.org/abs/2512.08321
-
[25]
Error estimation of floating-point summation and dot product,
S. M. Rump, “Error estimation of floating-point summation and dot product,”BIT Numerical Mathematics, vol. 52, no. 1, pp. 201–220,
-
[26]
Available: https://doi.org/10.1007/s10543-011-0342-4
[Online]. Available: https://doi.org/10.1007/s10543-011-0342-4
-
[27]
(2026) SAKURAONE: a managed high performance computing cluster
SAKURA internet Inc. (2026) SAKURAONE: a managed high performance computing cluster. Retrieved 26 March, 2026. [Online]. Available: https://www.sakura.ad.jp/sakuraone/
work page 2026
-
[28]
A. Schwarz, A. Anders, C. Brower, H. Bayraktar, J. Gunnels, K. Clark, R. G. Xu, S. Rodriguez, S. Cayrols, P. Tabaszewski, and V . Podlozhnyuk, “Guaranteed dgemm accuracy while using reduced precision tensor cores through extensions of the ozaki scheme,” ser. SCA/HPCAsia ’26. Association for Computing Machinery, 2026, p. 91–101. [Online]. Available: https:...
-
[29]
S. R. Bernabeu, “Energy-Efficient Supercomputing Through Tensor Core-Accelerated Mixed-Precision Computing and Floating- Point Emulation,” Oral presentation at NVIDIA GTC 2025, Mar. 2025. [Online]. Available: https://www.nvidia.com/en-us/on- demand/session/gtc25-s71487/
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.