Recognition: 2 theorem links
· Lean TheoremText-Phase Synergy Network with Dual Priors for Unsupervised Cross-Domain Image Retrieval
Pith reviewed 2026-05-15 11:56 UTC · model grok-4.3
The pith
A network combining CLIP text prompts and phase features retrieves same-category images across domains without labels
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
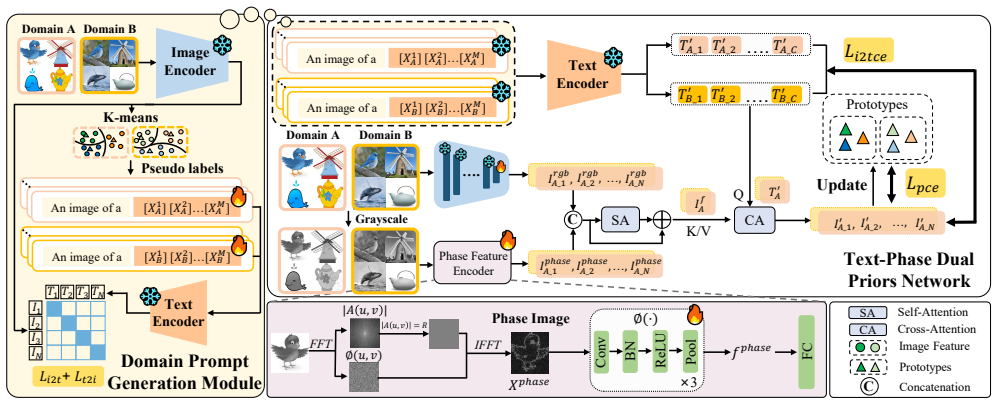
The Text-Phase Synergy Network with Dual Priors uses CLIP to create domain-specific text prompts that serve as a text prior for semantic supervision and incorporates domain-invariant phase features as a phase prior to align domains while maintaining semantic content, resulting in improved performance over methods relying on discrete pseudo-labels.
What carries the argument
TPSNet's dual priors mechanism, where the text prior from CLIP provides precise semantic guidance and the phase prior supplies domain-invariant information to prevent semantic degradation during cross-domain alignment.
If this is right
- The approach replaces inaccurate discrete pseudo-labels with continuous semantic supervision from text prompts.
- Integration of phase features reduces domain gaps without losing category information.
- Overall retrieval accuracy increases on standard UCDIR benchmark datasets.
- Representations become more robust for matching images from different visual domains.
Where Pith is reading between the lines
- Similar dual-prior strategies might apply to other unsupervised domain adaptation tasks beyond retrieval, such as classification or segmentation.
- Exploring phase features in combination with other foundation models could yield further gains in handling domain shifts.
- Validation on datasets with extreme domain differences, like sketch to photo, would test the limits of the phase prior's invariance.
Load-bearing premise
CLIP can generate class-specific prompts that give more accurate semantic supervision than clustering-based pseudo-labels, and phase features can be added to image representations without degrading their semantic meaning.
What would settle it
If ablation experiments show that removing either the text prior or the phase prior does not decrease performance on the UCDIR benchmarks, the value of their synergy would be called into question.
Figures








read the original abstract
This paper studies unsupervised cross-domain image retrieval (UCDIR), which aims to retrieve images of the same category across different domains without relying on labeled data. Existing methods typically utilize pseudo-labels, derived from clustering algorithms, as supervisory signals for intra-domain representation learning and cross-domain feature alignment. However, these discrete pseudo-labels often fail to provide accurate and comprehensive semantic guidance. Moreover, the alignment process frequently overlooks the entanglement between domain-specific and semantic information, leading to semantic degradation in the learned representations and ultimately impairing retrieval performance. This paper addresses the limitations by proposing a Text-Phase Synergy Network with Dual Priors(TPSNet). Specifically, we first employ CLIP to generate a set of class-specific prompts per domain, termed as domain prompt, serving as a text prior that offers more precise semantic supervision. In parallel, we further introduce a phase prior, represented by domain-invariant phase features, which is integrated into the original image representations to bridge the domain distribution gaps while preserving semantic integrity. Leveraging the synergy of these dual priors, TPSNet significantly outperforms state-of-the-art methods on UCDIR benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TPSNet, a Text-Phase Synergy Network with Dual Priors, for unsupervised cross-domain image retrieval (UCDIR). It identifies limitations in existing pseudo-label approaches from clustering, which provide inaccurate semantic guidance and cause semantic degradation during domain alignment. TPSNet introduces a text prior via CLIP-generated class-specific domain prompts for more precise supervision and a phase prior using domain-invariant phase features to bridge domain gaps while preserving semantics. The central claim is that the synergy of these dual priors enables significant outperformance over state-of-the-art methods on UCDIR benchmarks.
Significance. If the dual-prior design is shown to deliver reliable semantic supervision and domain-invariant features without degradation, the work could advance UCDIR by moving beyond discrete pseudo-labels toward multimodal and signal-based priors. The integration of CLIP text embeddings with phase features offers a potentially generalizable strategy for handling domain shifts in retrieval tasks.
major comments (3)
- [Abstract] Abstract: The claim that CLIP-generated class-specific domain prompts provide 'more precise and comprehensive semantic supervision' than clustering-derived pseudo-labels is load-bearing for the central contribution, yet the manuscript provides no quantitative comparison (e.g., prompt-to-image similarity vs. clustering purity) or ablation isolating the text prior's contribution; this must be addressed with explicit metrics in the experimental section.
- [Abstract] Abstract: The phase prior is asserted to integrate 'without semantic degradation' and bridge domain gaps, but the description contains no equations, extraction procedure, or fusion mechanism; without these details the claim that phase features preserve semantics while aligning distributions cannot be evaluated and is central to the synergy argument.
- [Abstract] Abstract: The outperformance claim rests on the assumption that CLIP domain prompts remain reliable across non-natural domains (e.g., sketches, paintings), but CLIP's photo-centric training data introduces a documented bias risk; the paper must include domain-specific ablation or failure-case analysis to substantiate that the text prior outperforms pseudo-labels under this bias.
minor comments (1)
- [Abstract] Abstract: Missing space in 'Dual Priors(TPSNet)' should be corrected to 'Dual Priors (TPSNet)'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments help clarify how to better substantiate the dual-prior claims. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that CLIP-generated class-specific domain prompts provide 'more precise and comprehensive semantic supervision' than clustering-derived pseudo-labels is load-bearing for the central contribution, yet the manuscript provides no quantitative comparison (e.g., prompt-to-image similarity vs. clustering purity) or ablation isolating the text prior's contribution; this must be addressed with explicit metrics in the experimental section.
Authors: We agree that direct quantitative evidence strengthens the central claim. In the revised manuscript we will add an experimental subsection reporting prompt-to-image cosine similarity for the CLIP domain prompts versus clustering purity on the same features, together with an ablation that isolates the text prior by comparing full TPSNet against a variant using only the phase prior and pseudo-label supervision. revision: yes
-
Referee: [Abstract] Abstract: The phase prior is asserted to integrate 'without semantic degradation' and bridge domain gaps, but the description contains no equations, extraction procedure, or fusion mechanism; without these details the claim that phase features preserve semantics while aligning distributions cannot be evaluated and is central to the synergy argument.
Authors: The full manuscript (Section 3.2) already contains the phase extraction via Fourier transform (Equation 2) and the fusion module that concatenates phase features with amplitude features before the encoder (Equations 3-4). To improve accessibility we will insert a short description of the extraction and fusion steps into the abstract and add a schematic figure in the revised version. revision: partial
-
Referee: [Abstract] Abstract: The outperformance claim rests on the assumption that CLIP domain prompts remain reliable across non-natural domains (e.g., sketches, paintings), but CLIP's photo-centric training data introduces a documented bias risk; the paper must include domain-specific ablation or failure-case analysis to substantiate that the text prior outperforms pseudo-labels under this bias.
Authors: We acknowledge the documented CLIP bias for non-photographic domains. While our current benchmarks already contain sketch and painting subsets, we will add a dedicated ablation table and failure-case discussion that directly compares text-prior performance against pseudo-label baselines on these domains, highlighting cases where CLIP prompts degrade and how the phase prior mitigates the effect. revision: yes
Circularity Check
No circularity: priors treated as external inputs
full rationale
The manuscript introduces TPSNet by adopting CLIP-generated domain prompts and phase features as independent priors supplied by external pre-trained models and standard feature extraction. These quantities are not fitted to the target retrieval metric, not defined in terms of the claimed synergy, and not justified via self-citation chains that reduce to the present result. No equations appear that would equate a prediction to a fitted parameter or rename an input as an output. The performance claims rest on benchmark comparisons rather than any self-referential derivation, rendering the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLIP can generate accurate class-specific prompts per domain that offer more precise semantic supervision than clustering-based pseudo-labels
- domain assumption Domain-invariant phase features can be extracted and integrated into image representations while preserving semantic integrity
invented entities (2)
-
Text prior (domain prompts from CLIP)
no independent evidence
-
Phase prior (domain-invariant phase features)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
employ CLIP to generate a set of class-specific prompts per domain, termed as domain prompt, serving as a text prior
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-labelling via simultaneous clustering and representation learning
YM Asano, C Rupprecht, and A Vedaldi. Self-labelling via simultaneous clustering and representation learning. InPro- ceedings of the International Conference on Learning Rep- resentations, 2019. 3
work page 2019
-
[2]
Prompt- based distribution alignment for unsupervised domain adap- tation
Shuanghao Bai, Min Zhang, Wanqi Zhou, Siteng Huang, Zhirong Luan, Donglin Wang, and Badong Chen. Prompt- based distribution alignment for unsupervised domain adap- tation. InProceedings of the AAAI conference on Artificial Intelligence, pages 729–737, 2024. 2
work page 2024
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Unsupervised learning of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Pi- otr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. InPro- ceedings of the Annual Conference on Neural Information Processing Systems, pages 9912–9924, 2020. 3
work page 2020
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE International Conference on Computer Vision, pages 9650–9660, 2021. 6, 3
work page 2021
-
[6]
Improved Baselines with Momentum Contrastive Learning
Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020. 6, 3
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[7]
An image is worth 16x16 words: Transformers for im- age recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, G Heigold, S Gelly, et al. An image is worth 16x16 words: Transformers for im- age recognition at scale. InProceedings of the International Conference on Learning Representations, 2020. 5
work page 2020
-
[8]
Pros: Prompting-to-simulate generalized knowledge for universal cross-domain retrieval
Kaipeng Fang, Jingkuan Song, Lianli Gao, Pengpeng Zeng, Zhi-Qi Cheng, Xiyao Li, and Heng Tao Shen. Pros: Prompting-to-simulate generalized knowledge for universal cross-domain retrieval. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 17292–17301, 2024. 1
work page 2024
-
[9]
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pas- cal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario March, and Victor Lempitsky. Domain-adversarial training of neural networks.Journal of Machine Learning Research, 17(59):1–35, 2016. 3
work page 2016
-
[10]
Chunjiang Ge, Rui Huang, Mixue Xie, Zihang Lai, Shiji Song, Shuang Li, and Gao Huang. Domain adaptation via prompt learning.IEEE Transactions on Neural Networks and Learning Systems, 36(1):1160–1170, 2023. 2
work page 2023
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 5
work page 2016
-
[12]
X-mir: Ex- plainable medical image retrieval
Brian Hu, Bhavan Vasu, and Anthony Hoogs. X-mir: Ex- plainable medical image retrieval. InProceedings of the IEEE Winter Conference on Applications of Computer Vi- sion, pages 440–450, 2022. 1
work page 2022
-
[13]
Feature representation learn- ing for unsupervised cross-domain image retrieval
Conghui Hu and Gim Hee Lee. Feature representation learn- ing for unsupervised cross-domain image retrieval. InPro- ceedings of the European Conference on Computer Vision, pages 529–544. Springer, 2022. 2, 5, 6, 7, 3
work page 2022
-
[14]
Unsuper- vised feature representation learning for domain-generalized cross-domain image retrieval
Conghui Hu, Can Zhang, and Gim Hee Lee. Unsuper- vised feature representation learning for domain-generalized cross-domain image retrieval. InProceedings of the IEEE International Conference on Computer Vision, pages 11016– 11025, 2023. 2, 5, 6, 7
work page 2023
-
[15]
Cross-domain image retrieval with a dual attribute- aware ranking network
Junshi Huang, Rogerio S Feris, Qiang Chen, and Shuicheng Yan. Cross-domain image retrieval with a dual attribute- aware ranking network. InProceedings of the IEEE Inter- national Conference on Computer Vision, pages 1062–1070,
-
[16]
Cross- domain image retrieval with attention modeling
Xin Ji, Wei Wang, Meihui Zhang, and Yang Yang. Cross- domain image retrieval with attention modeling. InProceed- ings of the 25th ACM International Conference on Multime- dia, pages 1654–1662, 2017. 2
work page 2017
-
[17]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InProceedings of the International Conference on Machine Learning, pages 4904–4916, 2021. 2
work page 2021
-
[18]
Sri Karnila, Suhendro Irianto, and Rio Kurniawan. Face recognition using content based image retrieval for intelli- gent security.International Journal of Advanced Engineer- ing Research and Science, 6(1):91–98, 2019. 1
work page 2019
-
[19]
Vilt: Vision- and-language transformer without convolution or region su- pervision
Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision- and-language transformer without convolution or region su- pervision. InProceedings of the International Conference on Machine Learning, pages 5583–5594, 2021. 2
work page 2021
-
[20]
Unsupervised cross-domain image retrieval via prototypical optimal trans- port
Bin Li, Ye Shi, Qian Yu, and Jingya Wang. Unsupervised cross-domain image retrieval via prototypical optimal trans- port. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3009–3017, 2024. 2, 5, 6, 7, 3
work page 2024
-
[21]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InProceed- ings of the International Conference on Machine Learning, pages 12888–12900, 2022. 2, 4, 5
work page 2022
-
[22]
Jian Liang, Dapeng Hu, and Jiashi Feng. Do we really need to access the source data? source hypothesis transfer for un- supervised domain adaptation. InProceedings of the Interna- tional Conference on Machine Learning, pages 6028–6039,
-
[23]
Mm-embed: Universal multimodal retrieval with multimodal llms
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal llms. InPro- ceedings of the International Conference on Learning Rep- resentations, 2025. 5, 7
work page 2025
-
[24]
Dida: Disambiguated domain align- ment for cross-domain retrieval with partial labels
Haoran Liu, Ying Ma, Ming Yan, Yingke Chen, Dezhong Peng, and Xu Wang. Dida: Disambiguated domain align- ment for cross-domain retrieval with partial labels. InPro- ceedings of the AAAI conference on Artificial Intelligence, pages 3612–3620, 2024. 2
work page 2024
-
[25]
Lamra: 9 Large multimodal model as your advanced retrieval assistant
Yikun Liu, Pingan Chen, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: 9 Large multimodal model as your advanced retrieval assistant. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025. 5, 7
work page 2025
-
[26]
Conditional adversarial domain adapta- tion
Mingsheng Long, ZHANGJIE CAO, Jianmin Wang, and Michael I Jordan. Conditional adversarial domain adapta- tion. InProceedings of the Annual Conference on Neural Information Processing Systems, 2018. 3
work page 2018
-
[27]
The importance of phase in signals.Proceedings of the IEEE, 69(5):529–541, 1981
Alan V Oppenheim and Jae S Lim. The importance of phase in signals.Proceedings of the IEEE, 69(5):529–541, 1981. 2
work page 1981
-
[28]
Styleclip: Text-driven manipulation of stylegan imagery
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. InProceedings of the IEEE International Conference on Computer Vision, pages 2085–2094, 2021. 2
work page 2085
-
[29]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE International Conference on Computer Vision, pages 1406–1415, 2019. 5
work page 2019
-
[30]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InProceedings of the International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 2, 5
work page 2021
-
[31]
Denseclip: Language-guided dense prediction with context- aware prompting
Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. Denseclip: Language-guided dense prediction with context- aware prompting. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 18082– 18091, 2022. 2
work page 2022
-
[32]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE In- ternational Conference on Computer Vision, pages 618–626,
-
[33]
Mo- bile product image search by automatic query object extrac- tion
Xiaohui Shen, Zhe Lin, Jonathan Brandt, and Ying Wu. Mo- bile product image search by automatic query object extrac- tion. InProceedings of the European Conference on Com- puter Vision, pages 114–127. Springer, 2012. 1
work page 2012
-
[34]
Zixin Tang, Haihui Fan, Jinchao Zhang, Hui Ma, Xiaoyan Gu, Bo Li, and Weiping Wang. Shieldir: Privacy-preserving unsupervised cross-domain image retrieval via dual protec- tion transformation. InProceedings of the 33rd ACM In- ternational Conference on Multimedia, pages 6383–6392,
-
[35]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 2, 3, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Visualizing data using t-sne.Journal of Machine Learning Research, 9 (86):2579–2605, 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9 (86):2579–2605, 2008. 8
work page 2008
-
[37]
Deep hashing network for unsupervised domain adaptation
Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5018–5027, 2017. 5
work page 2017
-
[38]
Unsupervised cross-domain im- age retrieval with semantic-attended mixture-of-experts
Kai Wang, Jiayang Liu, Xing Xu, Jingkuan Song, Xin Liu, and Heng Tao Shen. Unsupervised cross-domain im- age retrieval with semantic-attended mixture-of-experts. In Proceedings of the 47th International ACM SIGIR Confer- ence on Research and Development in Information Retrieval, pages 197–207, 2024. 2, 5, 6, 7, 3
work page 2024
-
[39]
Semantic feature learn- ing for universal unsupervised cross-domain retrieval
Lixu Wang, Xinyu Du, and Qi Zhu. Semantic feature learn- ing for universal unsupervised cross-domain retrieval. In Proceedings of the Annual Conference on Neural Informa- tion Processing Systems, 2024. 2
work page 2024
-
[40]
Boost- ing unsupervised domain adaptation: A fourier approach
Mengzhu Wang, Shanshan Wang, Ye Wang, Wei Wang, Tianyi Liang, Junyang Chen, and Zhigang Luo. Boost- ing unsupervised domain adaptation: A fourier approach. Knowledge-Based Systems, 264:110325, 2023. 2, 3
work page 2023
-
[41]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Correspondence-free domain alignment for unsupervised cross-domain image retrieval
Xu Wang, Dezhong Peng, Ming Yan, and Peng Hu. Correspondence-free domain alignment for unsupervised cross-domain image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, pages 10200–10208,
-
[43]
Boosting fine-grained fashion retrieval with relational knowledge distillation
Ling Xiao and Toshihiko Yamasaki. Boosting fine-grained fashion retrieval with relational knowledge distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8229–8234, 2024. 1
work page 2024
-
[44]
Fda: Fourier domain adaptation for semantic segmentation
Yanchao Yang and Stefano Soatto. Fda: Fourier domain adaptation for semantic segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 4085–4095, 2020. 2, 3
work page 2020
-
[45]
Sail-vl2 technical report.arXiv preprint arXiv:2509.14033, 2025
Weijie Yin, Yongjie Ye, Fangxun Shu, Yue Liao, Zijian Kang, Hongyuan Dong, Haiyang Yu, Dingkang Yang, Jia- cong Wang, Han Wang, et al. Sail-vl2 technical report.arXiv preprint arXiv:2509.14033, 2025. 5, 7
-
[46]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE International Conference on Computer Vision, pages 11975–11986, 2023. 2, 4, 5
work page 2023
-
[47]
Yuchen Zhang, Tianle Liu, Mingsheng Long, and Michael Jordan. Bridging theory and algorithm for domain adapta- tion. InProceedings of the 36th International Conference on Machine Learning, pages 7404–7413, 2019. 3 10 Text-Phase Synergy Network with Dual Priors for Unsupervised Cross-Domain Image Retrieval Supplementary Material In the technical appendices...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.