Recognition: 2 theorem links
· Lean TheoremEmDT: Embedding Diffusion Transformer for Tabular Data Generation in Fraud Detection
Pith reviewed 2026-05-15 10:55 UTC · model grok-4.3
The pith
A diffusion transformer with UMAP clustering generates synthetic fraud samples that improve downstream detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EmDT identifies distinct fraudulent patterns through UMAP clustering and trains a Transformer denoising network with sinusoidal positional embeddings to generate synthetic tabular fraud samples via diffusion. When these samples are added to the training data for a decision-tree classifier, downstream classification performance on fraud detection tasks improves significantly over prior methods. The generated data maintains comparable privacy protection and preserves the feature correlations present in the original dataset.
What carries the argument
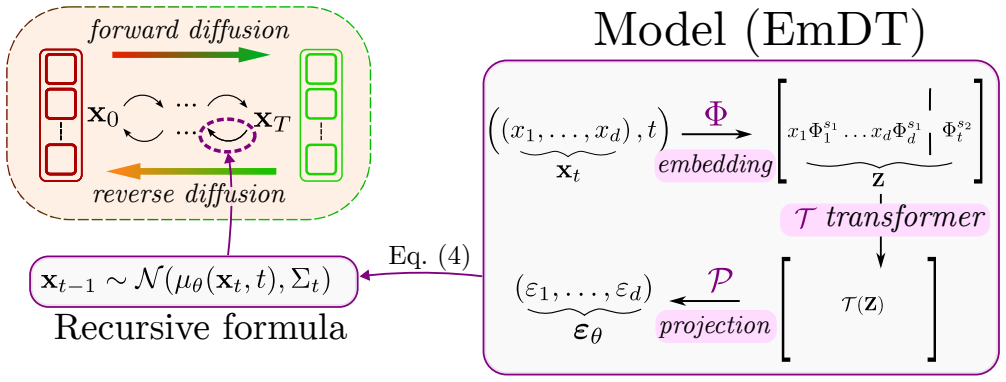
The Clustered Embedding Diffusion-Transformer (EmDT), which applies UMAP clustering to fraud patterns and uses a Transformer with sinusoidal embeddings for denoising in the diffusion generation of tabular samples.
If this is right
- Training an XGBoost classifier on data augmented with EmDT samples yields higher fraud detection performance than training on data augmented by existing oversampling or generative techniques.
- Feature correlations measured in the synthetic data remain close to those measured in the real data.
- Privacy metrics for the generated samples stay comparable to those achieved by other generative methods.
- The full pipeline outperforms standard oversampling approaches in the final classification results on imbalanced tabular fraud data.
Where Pith is reading between the lines
- The clustering step may support generating samples focused on particular fraud subtypes if the clusters align with different behavioral patterns.
- The same generation approach could be tested on other imbalanced tabular tasks such as rare-event prediction in finance or healthcare.
- Replacing the final XGBoost classifier with alternative models while keeping the EmDT-generated data could be checked to see whether the performance gains hold.
Load-bearing premise
UMAP clustering reliably separates distinct fraudulent patterns and the sinusoidal embeddings let the transformer capture the important feature relationships in tabular fraud data without introducing artifacts that degrade later classification.
What would settle it
If adding EmDT-generated samples to the training set produces no improvement or a drop in fraud detection metrics such as precision or recall for an XGBoost classifier compared to baseline augmentation methods on the same credit card dataset.
Figures





read the original abstract
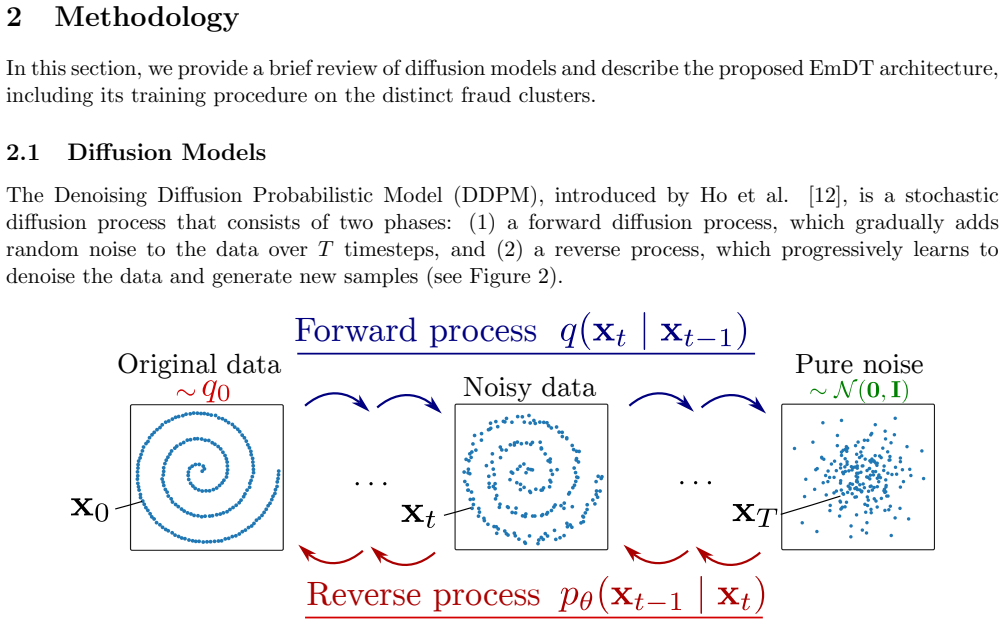
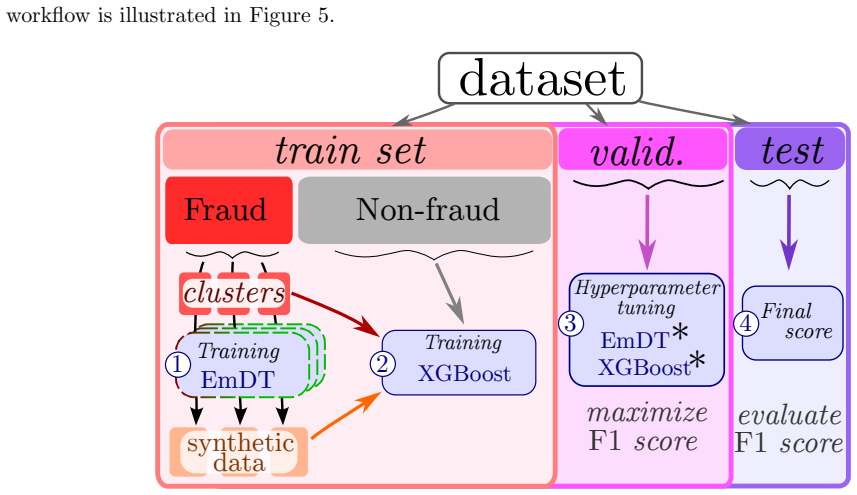
Imbalanced datasets pose a difficulty in fraud detection, as classifiers are often biased toward the majority class and perform poorly on rare fraudulent transactions. Synthetic data generation is therefore commonly used to mitigate this problem. In this work, we propose the Clustered Embedding Diffusion-Transformer (EmDT), a diffusion model designed to generate fraudulent samples. Our key innovation is to leverage UMAP clustering to identify distinct fraudulent patterns, and train a Transformer denoising network with sinusoidal positional embeddings to capture feature relationships throughout the diffusion process. Once the synthetic data has been generated, we employ a standard decision-tree-based classifier (e.g., XGBoost) for classification, as this type of model remains better suited to tabular datasets. Experiments on a credit card fraud detection dataset demonstrate that EmDT significantly improves downstream classification performance compared to existing oversampling and generative methods, while maintaining comparable privacy protection and preserving feature correlations present in the original data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Clustered Embedding Diffusion-Transformer (EmDT) for generating synthetic fraudulent samples to address class imbalance in tabular fraud detection. It first applies UMAP to partition the minority (fraud) class into distinct patterns, then trains a separate Transformer-based denoising diffusion model with sinusoidal positional embeddings on each cluster; the resulting synthetic data augments training for a downstream XGBoost classifier. Experiments on a credit-card fraud dataset are claimed to show significant gains in classification performance over oversampling and other generative baselines while preserving feature correlations and privacy.
Significance. If the empirical claims can be substantiated, the work would offer a practical advance in synthetic tabular data generation for imbalanced fraud settings by explicitly modeling multimodal fraud patterns via clustering before diffusion. The per-cluster Transformer diffusion approach with sinusoidal embeddings is a reasonable architectural choice for capturing feature dependencies in tabular data and could generalize to other rare-event detection tasks.
major comments (3)
- [Experiments] Experiments section: the central claim that EmDT 'significantly improves' downstream XGBoost performance is unsupported because no numerical results (AUC, F1, or precision-recall with error bars), ablation tables, or statistical significance tests are provided; only qualitative statements appear.
- [Methodology] Methodology (UMAP clustering paragraph): no analysis of cluster stability is reported (e.g., adjusted Rand index across random seeds, sensitivity to n_neighbors or min_dist), yet the skeptic correctly notes that unstable partitions would confound attribution of any downstream gains to the diffusion-Transformer rather than simply to more diverse synthetic samples.
- [Evaluation] Evaluation (correlation-preservation claim): the assertion that 'feature correlations present in the original data' are preserved lacks any quantitative check such as Frobenius distance between correlation matrices or mutual-information scores between real and synthetic data, leaving the claim unverified.
minor comments (2)
- [Abstract] Abstract: the phrase 'significantly improves' should be replaced by concrete effect sizes or a pointer to the results table/figure.
- [Model Architecture] Notation: the description of the sinusoidal embedding inside the Transformer denoising network is insufficiently precise; the exact form of the embedding (e.g., frequency schedule) and how it is added to tabular features should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current manuscript would benefit from additional quantitative support and analyses. We will revise the paper to address each of the major comments as detailed below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that EmDT 'significantly improves' downstream XGBoost performance is unsupported because no numerical results (AUC, F1, or precision-recall with error bars), ablation tables, or statistical significance tests are provided; only qualitative statements appear.
Authors: We acknowledge the referee's point that the current version presents only qualitative statements regarding performance gains. In the revised manuscript we will add comprehensive numerical results, including tables with mean AUC, F1, and AUPRC scores (with standard deviations from 5 independent runs), ablation studies isolating the contribution of clustering and the Transformer diffusion components, and paired statistical significance tests (e.g., Wilcoxon signed-rank) against baselines to substantiate the claims. revision: yes
-
Referee: [Methodology] Methodology (UMAP clustering paragraph): no analysis of cluster stability is reported (e.g., adjusted Rand index across random seeds, sensitivity to n_neighbors or min_dist), yet the skeptic correctly notes that unstable partitions would confound attribution of any downstream gains to the diffusion-Transformer rather than simply to more diverse synthetic samples.
Authors: We agree that demonstrating cluster stability is necessary to attribute gains correctly. The revised version will include a dedicated stability analysis: adjusted Rand index computed across multiple random seeds for the UMAP step, plus sensitivity plots and tables showing how downstream classifier performance varies with changes in n_neighbors and min_dist. This will confirm that the identified fraud patterns are robust. revision: yes
-
Referee: [Evaluation] Evaluation (correlation-preservation claim): the assertion that 'feature correlations present in the original data' are preserved lacks any quantitative check such as Frobenius distance between correlation matrices or mutual-information scores between real and synthetic data, leaving the claim unverified.
Authors: We accept that a purely qualitative claim is insufficient. The revised manuscript will report quantitative metrics: the Frobenius norm between the Pearson correlation matrices of real and synthetic data, average absolute difference in pairwise correlations, and mutual information scores (or normalized mutual information) between corresponding feature pairs to verify preservation of dependencies. revision: yes
Circularity Check
No circularity: generative model trained on data and evaluated on independent downstream task
full rationale
The paper describes training a diffusion-Transformer on UMAP-clustered fraud data and evaluating via XGBoost on held-out classification performance. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The derivation consists of standard training followed by external evaluation; nothing reduces to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- UMAP clustering hyperparameters
- Diffusion schedule parameters
axioms (1)
- domain assumption Tabular fraud data contains clusterable patterns that a Transformer can denoise while preserving correlations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ϵθ = P ◦ T ◦ Φ(x, t) ... Φ(x, t) = [x1 ψ(s1)1, …, xd ψ(s1)d, ψ(s2)t] with ψ(s)j = [sin(s·j), cos(s·j), …]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Adam: A Method for Stochastic Optimization
Kingma DP Ba J Adam et al. A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 1412(6), 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2623–2631, 2019
work page 2019
-
[3]
Abdulalem Ali, Shukor Abd Razak, Siti Hajar Othman, Taiseer Abdalla Elfadil Eisa, Arafat Al- Dhaqm, Maged Nasser, Tusneem Elhassan, Hashim Elshafie, and Abdu Saif. Financial fraud de- tection based on machine learning: a systematic literature review.Applied Sciences, 12(19):9637, 2022
work page 2022
-
[4]
Masad A Alrasheedi. Enhancing fraud detection in credit card transactions: A comparative study of machine learning models.Computational Economics, pages 1–27, 2025
work page 2025
-
[5]
Mohammadreza Armandpour, Ali Sadeghian, Huangjie Zheng, Amir Sadeghian, and Mingyuan Zhou. Re-imagine the negative prompt algorithm: Transform 2d diffusion into 3d, alleviate janus problem and beyond.arXiv preprint arXiv:2304.04968, 2023
-
[6]
Smote for high-dimensional class-imbalanced data.BMC bioinformatics, 14(1):106, 2013
Rok Blagus and Lara Lusa. Smote for high-dimensional class-imbalanced data.BMC bioinformatics, 14(1):106, 2013
work page 2013
-
[7]
Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique.Journal of artificial intelligence research, 16:321–357, 2002
work page 2002
-
[8]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
work page 2016
-
[9]
Yisong Chen, Chuqing Zhao, Yixin Xu, Chuanhao Nie, and Yixin Zhang. Deep learning in financial fraud detection: Innovations, challenges, and applications.Data Science and Management, 2025
work page 2025
-
[10]
Diagnosing and enhancing vae models.arXiv preprint arXiv:1903.05789, 2019
Bin Dai and David Wipf. Diagnosing and enhancing vae models.arXiv preprint arXiv:1903.05789, 2019
-
[11]
Calibrating proba- bility with undersampling for unbalanced classification
Andrea Dal Pozzolo, Olivier Caelen, Reid A Johnson, and Gianluca Bontempi. Calibrating proba- bility with undersampling for unbalanced classification. In2015 IEEE Symposium Series on Com- putational Intelligence, pages 159–166. IEEE, 2015
work page 2015
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[13]
Stefan Hochrainer-Stigler, Georg Pflug, Ulf Dieckmann, Elena Rovenskaya, Stefan Thurner, Sebas- tian Poledna, Gergely Boza, Joanne Linnerooth-Bayer, and ˚Ake Br¨ annstr¨ om. Integrating systemic risk and risk analysis using copulas.International Journal of Disaster Risk Science, 9(4):561–567, 2018
work page 2018
-
[14]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761, 2020
work page internal anchor Pith review arXiv 2009
-
[15]
Tabddpm: Modelling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Modelling tabular data with diffusion models. InInternational Conference on Machine Learning, pages 17564– 17579. PMLR, 2023. 15
work page 2023
-
[16]
Joffrey L Leevy, John Hancock, and Taghi M Khoshgoftaar. Comparative analysis of binary and one-class classification techniques for credit card fraud data.Journal of Big Data, 10(1):118, 2023
work page 2023
-
[17]
Guillaume Lema ˜AˇZtre, Fernando Nogueira, and Christos K Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning.Journal of machine learning research, 18(17):1–5, 2017
work page 2017
-
[18]
Arian Morteza and Maryam Amirmazlaghani. A novel gaussian-copula modeling for image despeck- ling in the shearlet domain.Signal Processing, 192:108340, 2022
work page 2022
-
[19]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high- performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[20]
Neha Patki, Roy Wedge, and Kalyan Veeramachaneni. The synthetic data vault. In2016 IEEE international conference on data science and advanced analytics (DSAA), pages 399–410. IEEE, 2016
work page 2016
-
[21]
Michael Platzer and Thomas Reutterer. Holdout-based empirical assessment of mixed-type synthetic data.Frontiers in big Data, 4:679939, 2021
work page 2021
-
[22]
Frauddiffuse: Diffusion-aided synthetic fraud augmentation for improved fraud detection
Ruma Roy, Darshika Tiwari, and Anubha Pandey. Frauddiffuse: Diffusion-aided synthetic fraud augmentation for improved fraud detection. InProceedings of the 5th ACM International Conference on AI in Finance, pages 90–98, 2024
work page 2024
-
[23]
Findiff: Diffusion models for financial tabular data generation
Timur Sattarov, Marco Schreyer, and Damian Borth. Findiff: Diffusion models for financial tabular data generation. InProceedings of the Fourth ACM International Conference on AI in Finance, pages 64–72, 2023
work page 2023
-
[24]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[25]
P Sundaravadivel, R Augustian Isaac, D Elangovan, D KrishnaRaj, VV Lokesh Rahul, and R Raja. Optimizing credit card fraud detection with random forests and smote.Scientific Reports, 15(1):17851, 2025
work page 2025
-
[26]
Paulina Tedesco, Alex Lenkoski, Hannah C Bloomfield, and Jana Sillmann. Gaussian copula mod- eling of extreme cold and weak-wind events over europe conditioned on winter weather regimes. Environmental Research Letters, 18(3):034008, 2023
work page 2023
-
[27]
Catastrophic forgetting and mode collapse in gans
Hoang Thanh-Tung and Truyen Tran. Catastrophic forgetting and mode collapse in gans. In2020 international joint conference on neural networks (ijcnn), pages 1–10. IEEE, 2020
work page 2020
-
[28]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[29]
Mario Villaiz´ an-Vallelado, Matteo Salvatori, Carlos Segura, and Ioannis Arapakis. Diffusion mod- els for tabular data imputation and synthetic data generation.ACM Transactions on Knowledge Discovery from Data, 19(6):1–32, 2025
work page 2025
-
[30]
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan.Advances in neural information processing systems, 32, 2019. 16
work page 2019
-
[31]
Tian Zhang, Hao Li, Jinyang Jiao, and Jing Lin. Temporal latent diffusion model for machine degradation trend forecasting.Knowledge-Based Systems, page 114753, 2025
work page 2025
-
[32]
Ctab-gan: Effective table data synthesizing
Zilong Zhao, Aditya Kunar, Robert Birke, and Lydia Y Chen. Ctab-gan: Effective table data synthesizing. InAsian conference on machine learning, pages 97–112. PMLR, 2021
work page 2021
-
[33]
Luping Zhi and Wanmin Wang. Research on modeling of the imbalanced fraudulent transaction detection problem based on embedding-aware conditional gan.Big Data Research, page 100557, 2025
work page 2025
-
[34]
Mengran Zhu, Ye Zhang, Yulu Gong, Changxin Xu, and Yafei Xiang. Enhancing credit card fraud detection a neural network and smote integrated approach.arXiv preprint arXiv:2405.00026, 2024. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.