Towards Fair and Robust Volumetric CT Classification via KL-Regularised Group Distributionally Robust Optimisation
Pith reviewed 2026-05-15 09:39 UTC · model grok-4.3
The pith
KL-regularised Group DRO with a MobileViT encoder raises both worst-group F1 and average performance in volumetric CT classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KL-regularised Group DRO adaptively reweights training batches according to current per-group loss while the KL term keeps the group distribution from degenerating, allowing a single model to improve both robustness to site shifts and fairness across gender-class combinations without separate per-site retraining.
What carries the argument
KL-regularised Group Distributionally Robust Optimisation that upweights underperforming groups during optimisation while the KL divergence penalty on the group weighting distribution prevents collapse.
If this is right
- A single set of hyperparameters can be used across multiple acquisition centres without site-specific retuning.
- Direct definition of groups at the gender-class granularity lifts accuracy on severely underrepresented combinations such as female squamous cell carcinoma.
- The same lightweight volumetric architecture works for both binary and multi-class CT tasks while satisfying the robustness and fairness objectives.
- Worst-group performance improves without a proportional drop in average performance.
Where Pith is reading between the lines
- The same regularisation pattern could be tested on other medical imaging tasks where scanner vendor and patient demographics create distribution shifts.
- If the optimal KL coefficient proves stable across new datasets, the method would reduce the engineering cost of deploying models in new hospitals.
- The approach suggests that explicit regularisation on the robustness objective itself can shrink the usual gap between average and worst-group accuracy.
Load-bearing premise
The KL penalty will keep group weights from collapsing to one or two sites or subgroups while still delivering meaningful worst-case protection across all centres and genders.
What would settle it
Train the identical MobileViT-plus-SliceTransformer architecture with standard Group DRO (KL coefficient set to zero) on the same data splits and measure whether the group weights concentrate on a single centre or gender class and whether the reported per-group F1 scores fall below the KL-regularised figures.
Figures



read the original abstract
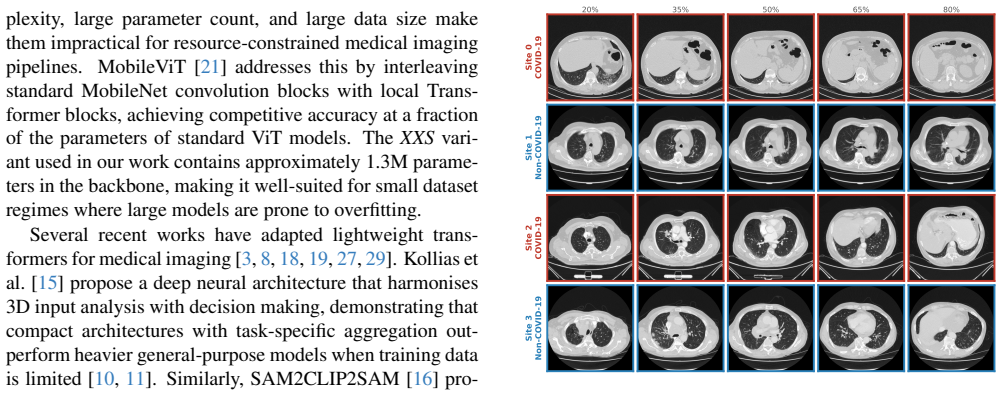
Automated diagnosis from chest computed tomography (CT) scans faces two persistent challenges in clinical deployment: distribution shift across acquisition sites and performance disparity across demographic subgroups. We address both simultaneously across two complementary tasks: binary COVID-19 classification from multi-site CT volumes (Task 1) and four-class lung pathology recognition with gender-based fairness constraints (Task 2). Our framework combines a lightweight MobileViT-XXS slice encoder with a two-layer SliceTransformer aggregator for volumetric reasoning, and trains with a KL-regularised Group Distributionally Robust Optimisation (Group DRO) objective that adaptively upweights underperforming acquisition centres and demographic subgroups. Unlike standard Group DRO, the KL penalty prevents group weight collapse, providing a stable balance between worst-case protection and average performance. For Task 2, we define groups at the granularity of gender class, directly targeting severely underrepresented combinations such as female Squamous cell carcinoma. On Task 1, our best configuration achieves a challenge F1 of 0.835, surpassing the best published challenge entry by +5.9. On Task 2, Group DRO with {\alpha} = 0.5 achieves a mean per-gender macro F1 of 0.815, outperforming the best challenge entry by +11.1 pp and improving Female Squamous F1 by +17.4 over the Focal Loss baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a KL-regularised Group Distributionally Robust Optimisation (Group DRO) method integrated with a MobileViT-XXS slice encoder and SliceTransformer for volumetric CT scan classification. It targets distribution shifts across acquisition sites and fairness across gender subgroups in two tasks: binary COVID-19 classification (Task 1) and multi-class lung pathology recognition (Task 2). The key innovation is the KL penalty to prevent group weight collapse in Group DRO, leading to reported F1 improvements of 0.835 on Task 1 (+5.9 over best challenge entry) and 0.815 mean per-gender macro F1 on Task 2 (+11.1 pp, with +17.4 on Female Squamous).
Significance. If the performance gains can be robustly attributed to the KL-regularised Group DRO rather than confounding factors like architecture choices, this work offers a promising direction for developing fair and robust models in medical imaging that balance worst-group performance with overall accuracy, potentially aiding clinical deployment across diverse sites and demographics.
major comments (2)
- [Abstract] The central claim that the KL penalty prevents group weight collapse while delivering worst-case protection is not supported by any reported analysis of group weights, ablation studies on the regularisation parameter α, or direct comparisons to unregularised Group DRO using the same MobileViT+SliceTransformer backbone. This verification is load-bearing for the attribution of the +17.4 pp Female Squamous F1 improvement and the overall +11.1 pp gain.
- [Experimental evaluation] The reported F1 scores (e.g., 0.835 on Task 1 and 0.815 on Task 2) are presented without error bars, statistical significance tests, or detailed experimental protocols including data splits and hyperparameter tuning procedures, making it impossible to assess the reliability and reproducibility of the claimed improvements over challenge baselines.
minor comments (1)
- [Abstract] The notation for the regularisation parameter is introduced as α = 0.5 without prior definition in the abstract, which could be clarified for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence and details will strengthen the manuscript. We address each major comment below and will revise the paper to incorporate the requested analyses and protocols.
read point-by-point responses
-
Referee: [Abstract] The central claim that the KL penalty prevents group weight collapse while delivering worst-case protection is not supported by any reported analysis of group weights, ablation studies on the regularisation parameter α, or direct comparisons to unregularised Group DRO using the same MobileViT+SliceTransformer backbone. This verification is load-bearing for the attribution of the +17.4 pp Female Squamous F1 improvement and the overall +11.1 pp gain.
Authors: We agree that the current manuscript lacks explicit verification of the KL penalty's effect on group weights and direct ablations. In the revised version we will add: (i) training curves and histograms of group weights with and without the KL term to demonstrate prevention of collapse; (ii) a full ablation table varying α ∈ {0, 0.1, 0.5, 1.0} on both tasks using the identical MobileViT-XXS + SliceTransformer backbone; and (iii) side-by-side results against unregularised Group DRO. These additions will directly support attribution of the reported gains, especially on the Female Squamous subgroup. revision: yes
-
Referee: [Experimental evaluation] The reported F1 scores (e.g., 0.835 on Task 1 and 0.815 on Task 2) are presented without error bars, statistical significance tests, or detailed experimental protocols including data splits and hyperparameter tuning procedures, making it impossible to assess the reliability and reproducibility of the claimed improvements over challenge baselines.
Authors: We acknowledge that the absence of variability measures and protocol details limits reproducibility assessment. The revised manuscript will include: standard deviations from five independent runs with different random seeds, statistical significance tests (paired t-tests) against the challenge baselines, and an expanded experimental section detailing site-stratified splits for Task 1, gender-and-class stratified splits for Task 2, the full hyperparameter search grid, and training schedules. These will appear in the main text with additional tables in the supplement. revision: yes
Circularity Check
No circularity: empirical results on held-out data independent of training objective
full rationale
The manuscript presents an empirical ML pipeline (MobileViT + SliceTransformer trained with KL-regularised Group DRO) and reports F1 metrics on two separate challenge tasks using held-out test data. No derivation, equation, or self-citation chain is shown that reduces the reported gains (+5.9 F1 on Task 1, +11.1 pp macro F1 on Task 2) to a quantity defined by the fitted α or by the objective itself. The KL penalty is described as preventing collapse, but its effect is measured externally rather than being tautological. All performance numbers are falsifiable on external benchmarks and do not collapse to the training inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- α =
0.5
axioms (1)
- domain assumption Group DRO with an added KL penalty on group weights prevents collapse while still up-weighting under-performing acquisition sites and demographic subgroups.
Reference graph
Works this paper leans on
-
[1]
Ebtesam Al-Mansor, Mohammed Al-Jabbar, Anis Ben Ishak, and S. Abdel-Khalek. Medical image edge detection in the framework of quantum representations.Alexandria Engi- neering Journal, 81:234–242, 2023. 2
work page 2023
-
[2]
A large imaging database and novel deep neural ar- chitecture for covid-19 diagnosis
Anastasios Arsenos, Dimitrios Kollias, and Stefanos Kol- lias. A large imaging database and novel deep neural ar- chitecture for covid-19 diagnosis. In2022 IEEE 14th Im- age, Video, and Multidimensional Signal Processing Work- shop (IVMSP), page 1–5. IEEE, 2022. 2
work page 2022
-
[3]
Light-weight vision transformer-based semantic segmentation for medical im- ages
Wen-Ling Chou, Guo-Shiang Lin, Ku-Yaw Chang, Sheng- Lei Yan, and Wei-Cheng Yeh. Light-weight vision transformer-based semantic segmentation for medical im- ages. In2025 IEEE International Conference on Advanced Visual and Signal-Based Systems (AVSS), pages 1–4, 2025. 3
work page 2025
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions (ICLR), 2021. 2
work page 2021
-
[5]
Peyman Mohajerin Esfahani and Daniel Kuhn. Data-driven distributionally robust optimization using the wasserstein metric.Mathematical Programming, 171:115–166, 2018. 2
work page 2018
-
[6]
Demetris Gerogiannis, Anastasios Arsenos, Dimitrios Kol- lias, Dimitris Nikitopoulos, and Stefanos Kollias. Covid- 19 computer-aided diagnosis through ai-assisted ct imaging analysis: Deploying a medical ai system. In2024 IEEE In- ternational Symposium on Biomedical Imaging (ISBI), pages 1–4. IEEE, 2024. 1, 2
work page 2024
-
[7]
Hao Guan and Mingxia Liu. Domain adaptation for medical image analysis: A survey.IEEE Transactions on Biomedical Engineering, 69(3):1173–1185, 2022. 1, 2
work page 2022
- [8]
-
[9]
Dimitrios Kollias, Athanasios Tagaris, Andreas Stafylopatis, Stefanos Kollias, and Georgios Tagaris. Deep neural archi- tectures for prediction in healthcare.Complex & Intelligent Systems, 4(2):119–131, 2018. 2
work page 2018
-
[10]
Dimitrios Kollias, N Bouas, Y Vlaxos, V Brillakis, M Se- feris, Ilianna Kollia, Levon Sukissian, James Wingate, and S Kollias. Deep transparent prediction through latent repre- sentation analysis.arXiv preprint arXiv:2009.07044, 2020. 3
-
[11]
Transpar- ent adaptation in deep medical image diagnosis
Dimitris Kollias, Y Vlaxos, M Seferis, Ilianna Kollia, Levon Sukissian, James Wingate, and Stefanos D Kollias. Transpar- ent adaptation in deep medical image diagnosis. InTAILOR, page 251–267, 2020. 3
work page 2020
-
[12]
Mia-cov19d: Covid-19 detection through 3-d chest ct image analysis
Dimitrios Kollias, Anastasios Arsenos, Levon Soukissian, and Stefanos Kollias. Mia-cov19d: Covid-19 detection through 3-d chest ct image analysis. InProceedings of the IEEE/CVF International Conference on Computer Vision, page 537–544, 2021. 1, 2
work page 2021
-
[13]
Ai-mia: Covid-19 detection and severity analysis through medical imaging
Dimitrios Kollias, Anastasios Arsenos, and Stefanos Kollias. Ai-mia: Covid-19 detection and severity analysis through medical imaging. InEuropean Conference on Computer Vi- sion, page 677–690. Springer, 2022. 2
work page 2022
-
[14]
Ai-enabled analysis of 3-d ct scans for diagnosis of covid-19 & its severity
Dimitrios Kollias, Anastasios Arsenos, and Stefanos Kollias. Ai-enabled analysis of 3-d ct scans for diagnosis of covid-19 & its severity. In2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICAS- SPW), page 1–5. IEEE, 2023. 1, 2
work page 2023
-
[15]
Dimitrios Kollias, Anastasios Arsenos, and Stefanos Kollias. A deep neural architecture for harmonizing 3-d input data analysis and decision making in medical imaging.Neuro- computing, 542:126244, 2023. 1, 3
work page 2023
-
[16]
Dimitrios Kollias, Anastasios Arsenos, James Wingate, and Stefanos Kollias. Sam2clip2sam: Vision language model for segmentation of 3d ct scans for covid-19 detection.arXiv preprint arXiv:2407.15728, 2024. 2, 3
-
[17]
Pharos-afe-aimi: Multi-source & fair disease diagnosis
Dimitrios Kollias, Anastasios Arsenos, and Stefanos Kollias. Pharos-afe-aimi: Multi-source & fair disease diagnosis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7265–7273, 2025. 1, 2, 5, 6
work page 2025
-
[18]
Chia-Ming Lee, Bo-Cheng Qiu, Ting-Yao Chen, Ming-Han Sun, Fang-Ying Lin, Jung-Tse Tsai, I-An Tsai, Yu-Fan Lin, and Chih-Chung Hsu. Multi-source covid-19 detec- tion via kernel-density-based slice sampling.arXiv preprint arXiv:2507.01564, 2025. 3, 5
-
[19]
Advancing lung disease diagnosis in 3d ct scans.arXiv preprint arXiv:2507.00993,
Qingqiu Li, Runtian Yuan, Junlin Hou, Jilan Xu, Yuejie Zhang, Rui Feng, and Hao Chen. Advancing lung disease diagnosis in 3d ct scans.arXiv preprint arXiv:2507.00993,
-
[20]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017. 2
work page 2017
-
[21]
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
Sachin Mehta and Mohammad Rastegari. Mobilevit: Light- weight, general-purpose, and mobile-friendly vision trans- former. InInternational Conference on Learning Represen- tations (ICLR), 2022. Also available as arXiv:2110.02178. 1, 3
work page internal anchor Pith review arXiv 2022
-
[22]
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst- case generalization. InInternational Conference on Learn- ing Representations (ICLR), 2020. 1, 2, 3, 4
work page 2020
-
[23]
An investigation of why overparameterization exacerbates spurious correlations
Shiori Sagawa, Aditi Raghunathan, Pang Wei Koh, and Percy Liang. An investigation of why overparameterization exacerbates spurious correlations. InInternational Confer- ence on Machine Learning (ICML), 2020. 2
work page 2020
-
[24]
Q. Wang, F. Liu, R. Zou, et al. Enhancing medical im- age object detection with collaborative multi-agent deep q- networks and multi-scale representation.EURASIP Journal on Advances in Signal Processing, 2023(132):1–18, 2023. 2
work page 2023
-
[25]
3d-2d medical image registration technology and its application development: a survey
Handan Xiao. 3d-2d medical image registration technology and its application development: a survey. InProceedings of the 2023 4th International Symposium on Artificial Intel- ligence for Medicine Science, page 95–100, New York, NY , USA, 2024. Association for Computing Machinery. 2
work page 2023
-
[26]
Jee Seok Yoon, Kwanseok Oh, Yooseung Shin, Maciej A. Mazurowski, and Heung-Il Suk. Domain generalization for medical image analysis: A review.Proceedings of the IEEE, 112(10):1583–1609, 2024. 2
work page 2024
-
[27]
Runtian Yuan, Qingqiu Li, Junlin Hou, Jilan Xu, Yuejie Zhang, Rui Feng, and Hao Chen. Multi-source covid-19 detection via variance risk extrapolation.arXiv preprint arXiv:2506.23208, 2025. 3, 5
-
[28]
Li Zhang, Xiaosong Wang, Dong Yang, Thomas Sanford, Stephanie Harmon, Baris Turkbey, Bradford J Wood, Hol- ger Roth, Berengere Aubert-Broche, D Louis Collins, et al. Generalizing deep learning for medical image segmentation to unseen domains via deep stacked transformation.IEEE Transactions on Medical Imaging, 39(7):2531–2540, 2020. 1, 2
work page 2020
- [29]
-
[30]
Zheyuan Zhang, Bin Wang, Lanhong Yao, Elif Keles, Debesh Jha, Matthew Antalek, Gorkem Durak, Alpay Mede- talibeyoglu, Concetto Spampinato, Baris Turkbey, Boqing Gong, and Ulas Bagci. Adverin: Monotonic adversarial in- tensity attack for domain generalization in medical image segmentation.Medical Image Analysis, 107:103848, 2026. 2
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.