Recognition: 1 theorem link
· Lean TheoremSpeak, Segment, Track, Navigate: An Interactive System for Video-Guided Skull-Base Surgery
Pith reviewed 2026-05-15 09:46 UTC · model grok-4.3
The pith
Surgeons can use speech on live video alone to segment instruments, track them, and guide skull-base surgery with 2.32 mm accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce a speech-guided embodied agent framework that integrates natural language interaction with real-time visual perception on live intraoperative video. The system performs interactive segmentation and labeling of the surgical instrument, uses the segmented instrument as a spatial anchor that is autonomously tracked, and thereby enables anatomical segmentation, interactive registration of preoperative 3D models, monocular video-based tool-pose estimation, and image guidance through real-time anatomical overlays. In three experimental trials the hybrid vision-based method produced a mean absolute tool-tip position error of 2.32 ± 1.10 mm in the camera frame together with yaw
What carries the argument
Interactive segmentation of the surgical instrument used as a spatial anchor for autonomous tracking and monocular pose estimation on live video.
If this is right
- Tool-tip position can be recovered to a mean absolute error of 2.32 mm in the camera frame.
- Inter-frame yaw and pitch propagation discrepancies remain at 0.18° and 0.21° on average.
- Tool segmentation and anatomy registration finish in approximately two minutes.
- Real-time anatomical overlays become available for image guidance without external trackers.
- Setup complexity is reduced relative to conventional optical-tracking workflows.
Where Pith is reading between the lines
- The same instrument-anchor approach could be applied to other endoscopic procedures that already rely on video as the primary view.
- Voice-driven task triggering may lower the need for assistants to operate separate navigation consoles.
- Performance under prolonged occlusion or rapid camera motion remains an open test that would directly affect clinical adoption.
- If the anchor remains stable, downstream monocular pose estimates could be chained to produce continuous 3-D guidance without recalibration.
Load-bearing premise
Interactive segmentation of the instrument remains reliable and subsequent tracking stays robust under real intraoperative conditions including variable lighting, blood, smoke, and tissue motion.
What would settle it
A recorded surgery sequence in which blood or smoke appears and the measured tool-tip position error exceeds 5 mm or tracking is lost for more than a few frames.
Figures











read the original abstract
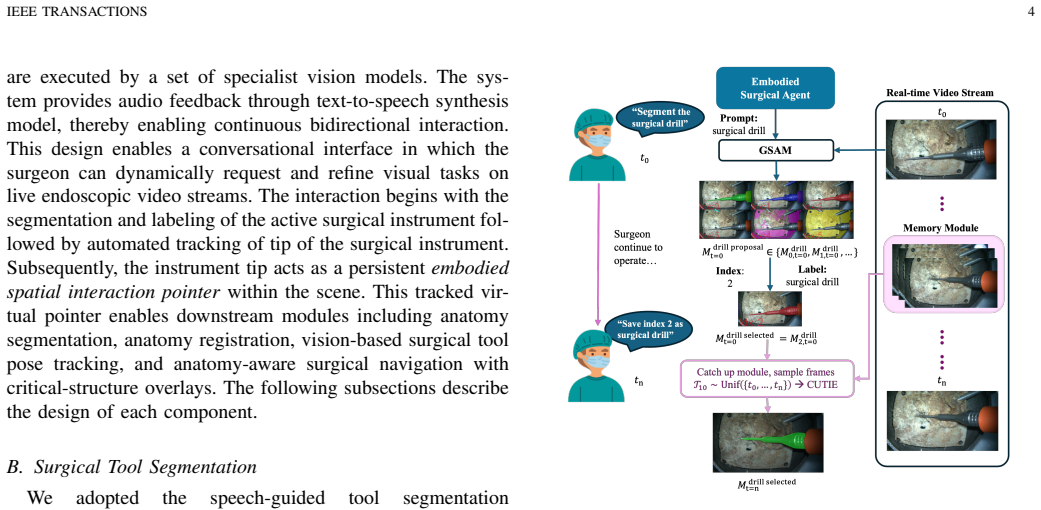
We introduce a speech-guided embodied agent framework for video-guided skull base surgery that dynamically executes perception and image-guidance tasks in response to surgeon queries. The proposed system integrates natural language interaction with real-time visual perception directly on live intraoperative video streams, thereby enabling surgeons to request computational assistance without disengaging from operative tasks. Unlike conventional image-guided navigation systems that rely on external optical trackers and additional hardware setup, the framework operates purely on intraoperative video. The system begins with interactive segmentation and labeling of the surgical instrument. The segmented instrument is then used as a spatial anchor that is autonomously tracked in the video stream to support downstream workflows, including anatomical segmentation, interactive registration of preoperative 3D models, monocular video-based estimation of the surgical tool pose, and image guidance through real-time anatomical overlays. We evaluate the proposed system in video-guided skull base surgery scenarios and benchmark its tracking performance against a commercially available optical tracking system. Across three experimental trials, the hybrid vision-based method achieved a mean absolute tool-tip position error of 2.32 Plus/Minus 1.10 mm in the camera frame, with inter-frame yaw and pitch propagation discrepancies of 0.18 Plus/Minus 0.25{\deg} and 0.21 Plus/Minus 0.30{\deg}, respectively. The system completes tool segmentation and anatomy registration within approximately two minutes, substantially reducing setup complexity relative to conventional tracking workflows. These results demonstrate that speech-guided embodied agents can provide accurate spatial guidance while improving workflow integration and enabling rapid deployment of video-guided surgical systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a speech-guided embodied agent framework for video-guided skull-base surgery that integrates natural language interaction with real-time visual perception on intraoperative video streams. The system performs interactive segmentation and labeling of the surgical instrument, uses it as a spatial anchor for autonomous tracking, anatomical segmentation, preoperative 3D model registration, monocular tool pose estimation, and real-time anatomical overlays. It reports a mean absolute tool-tip position error of 2.32 ± 1.10 mm and inter-frame yaw/pitch discrepancies of 0.18 ± 0.25° and 0.21 ± 0.30° from three experimental trials benchmarked against a commercial optical tracker, with setup completed in approximately two minutes.
Significance. If the reported accuracy holds under realistic intraoperative variability, the approach could meaningfully reduce hardware dependencies and setup time compared to conventional optical tracking systems by operating purely on video and speech. The direct empirical comparison to an external optical tracker provides a concrete, falsifiable baseline. However, the preliminary nature of the evaluation limits the strength of claims about workflow integration and reliability in live surgery.
major comments (2)
- [Evaluation] Evaluation section: Performance metrics are derived from only three experimental trials with no reported details on trial conditions, exclusion criteria, statistical analysis, success/failure rates, or robustness under variable lighting, blood, smoke, or tissue motion. This directly undermines extrapolation of the 2.32 ± 1.10 mm tool-tip error and sub-degree angular discrepancies to intraoperative use, as noted in the weakest assumption.
- [Methods] Methods section: The pipeline treats interactive segmentation as a reliable spatial anchor for all downstream tasks (tracking, registration, pose estimation), yet no quantitative metrics (e.g., Dice scores, failure rates, or inter-operator variability) are provided for the segmentation step itself.
minor comments (2)
- [Abstract] Abstract: Replace 'Plus/Minus' with the standard ± symbol and ensure consistent formatting for the angular units (e.g., °).
- [Abstract] Abstract: Clarify whether the reported 'inter-frame yaw and pitch propagation discrepancies' represent cumulative drift, per-frame error, or another quantity, and specify the reference frame.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important limitations in our preliminary evaluation. We agree that the current results are based on a small number of trials and will revise the manuscript to provide greater transparency on experimental details, limitations, and the segmentation component while maintaining the focus on the video-only, speech-guided approach.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: Performance metrics are derived from only three experimental trials with no reported details on trial conditions, exclusion criteria, statistical analysis, success/failure rates, or robustness under variable lighting, blood, smoke, or tissue motion. This directly undermines extrapolation of the 2.32 ± 1.10 mm tool-tip error and sub-degree angular discrepancies to intraoperative use, as noted in the weakest assumption.
Authors: We acknowledge that the evaluation is preliminary and limited to three controlled experimental trials. In the revised manuscript we will expand the Evaluation section to describe the trial conditions in detail, any exclusion criteria used, the statistical methods applied to the reported means and standard deviations, and observed success/failure rates. We will also add an explicit limitations paragraph stating that robustness to variable lighting, blood, smoke, or tissue motion was not tested and that the 2.32 mm accuracy applies only to the specific scenarios evaluated. These changes will prevent over-extrapolation while preserving the direct comparison to the optical tracker. revision: yes
-
Referee: [Methods] Methods section: The pipeline treats interactive segmentation as a reliable spatial anchor for all downstream tasks (tracking, registration, pose estimation), yet no quantitative metrics (e.g., Dice scores, failure rates, or inter-operator variability) are provided for the segmentation step itself.
Authors: We agree that quantitative characterization of the interactive segmentation step would strengthen the paper. In revision we will expand the Methods section with a dedicated description of the speech-guided segmentation process, including how the surgeon verifies and corrects the output in real time. Because Dice scores and inter-operator variability were not collected in the original experiments, we will instead report any observed segmentation failures or corrections from the three trials and discuss the interactive verification as a built-in safeguard. This will be framed as a limitation with a note that future work will include formal segmentation metrics. revision: partial
Circularity Check
No circularity: purely empirical performance reporting with external benchmark
full rationale
The paper presents a system description and evaluates it through direct experimental trials benchmarked against a commercial optical tracker. No equations, parameter fitting, self-citations, or derivations are present that reduce any claimed result to its own inputs by construction. The reported tool-tip error and angular discrepancies are measured outcomes from three trials, not predictions derived from fitted models or prior self-referential claims. This is a standard empirical systems paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard computer-vision assumptions for segmentation and tracking hold under intraoperative video conditions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across three experimental trials, the hybrid vision-based method achieved a mean absolute tool-tip position error of 2.32 ± 1.10 mm in the camera frame, with inter-frame yaw and pitch propagation discrepancies of 0.18 ± 0.25° and 0.21 ± 0.30°, respectively.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. T. Meybodi, G. Mignucci-Jim ´enez, M. T. Lawton, J. K. Liu, M. C. Preul, and H. Sun, “Comprehensive microsurgical anatomy of the middle cranial fossa: Part I—Osseous and meningeal anatomy,”Frontiers in Surgery, vol. 10, 2023
work page 2023
-
[2]
Cai4cai: The rise of contextual artificial intelligence in computer-assisted interventions,
T. Vercauteren, M. Unberath, N. Padoy, and N. Navab, “Cai4cai: The rise of contextual artificial intelligence in computer-assisted interventions,” Proceedings of the IEEE, vol. 108, no. 1, pp. 198–214, 2019. IEEE TRANSACTIONS 13
work page 2019
-
[3]
Artificial intelligence and automation in endoscopy and surgery,
F. Chadebecq, L. B. Lovat, and D. Stoyanov, “Artificial intelligence and automation in endoscopy and surgery,”Nature Reviews Gastroenterology & Hepatology, vol. 20, no. 3, pp. 171–182, 2023
work page 2023
-
[4]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inICCV, 2023, pp. 4015–4026
work page 2023
-
[5]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yanet al., “Grounded sam: Assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Text prompt- able surgical instrument segmentation with vision-language models,
Z. Zhou, O. Alabi, M. Wei, T. Vercauteren, and M. Shi, “Text prompt- able surgical instrument segmentation with vision-language models,” NeurIPS, vol. 36, 2023
work page 2023
-
[7]
Video-instrument synergistic network for referring video instrument segmentation in robotic surgery,
H. Wang, G. Yang, S. Zhang, J. Qin, Y . Guo, B. Xu, Y . Jin, and L. Zhu, “Video-instrument synergistic network for referring video instrument segmentation in robotic surgery,”IEEE Transactions on Medical Imag- ing, 2024
work page 2024
-
[8]
Surgraw: Multi-agent workflow with chain-of-thought reasoning for surgical intelligence,
C. H. Low, Z. Wang, T. Zhang, Z. Zeng, Z. Zhuo, E. B. Mazomenos, and Y . Jin, “Surgraw: Multi-agent workflow with chain-of-thought reasoning for surgical intelligence,”arXiv preprint arXiv:2503.10265, 2025
-
[9]
Llava-surg: towards multimodal surgical assistant via structured surgical video learning,
J. Li, G. Skinner, G. Yang, B. R. Quaranto, S. D. Schwaitzberg, P. C. Kim, and J. Xiong, “Llava-surg: towards multimodal surgical assistant via structured surgical video learning,”arXiv preprint arXiv:2408.07981, 2024
-
[10]
Sufia: language-guided augmented dex- terity for robotic surgical assistants,
M. Moghani, L. Doorenbos, W. C.-H. Panitch, S. Huver, M. Azizian, K. Goldberg, and A. Garg, “Sufia: language-guided augmented dex- terity for robotic surgical assistants,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 6969–6976
work page 2024
-
[11]
Core challenges in embodied vision-language planning,
J. Francis, N. Kitamura, F. Labelle, X. Lu, I. Navarro, and J. Oh, “Core challenges in embodied vision-language planning,”Journal of Artificial Intelligence Research, vol. 74, pp. 459–515, 2022
work page 2022
-
[12]
Surgbox: Agent-driven oper- ating room sandbox with surgery copilot,
J. Wu, X. Liang, X. Bai, and Z. Chen, “Surgbox: Agent-driven oper- ating room sandbox with surgery copilot,” in2024 IEEE International Conference on Big Data (BigData). IEEE, 2024, pp. 2041–2048
work page 2024
-
[13]
Vs-assistant: versatile surgery assistant on the demand of surgeons,
Z. Chen, X. Luo, J. Wu, D. Chan, Z. Lei, J. Wang, S. Ourselin, and H. Liu, “Vs-assistant: versatile surgery assistant on the demand of surgeons,”arXiv preprint arXiv:2405.08272, 2024
-
[14]
Surgicalvlm-agent: Towards an interac- tive ai co-pilot for pituitary surgery,
J. Huang, R. He, D. Z. Khan, E. Mazomenos, D. Stoyanov, H. J. Marcus, M. J. Clarkson, and M. Islam, “Surgicalvlm-agent: Towards an interac- tive ai co-pilot for pituitary surgery,”arXiv preprint arXiv:2503.09474, 2025
-
[15]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Suet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inECCV. Springer, 2024, pp. 38–55
work page 2024
-
[16]
Surgical- SAM: Efficient class promptable surgical instrument segmentation,
W. Yue, J. Zhang, K. Hu, Y . Xia, J. Luo, and Z. Wang, “Surgical- SAM: Efficient class promptable surgical instrument segmentation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 6890–6898
work page 2024
-
[17]
Putting the object back into video object segmentation,
H. K. Cheng, S. W. Oh, B. Price, J.-Y . Lee, and A. Schwing, “Putting the object back into video object segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 3151–3161
work page 2024
-
[18]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafsonet al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Gsam+ cutie: Text-promptable tool mask annotation for endoscopic video,
R. D. Soberanis-Mukul, J. Cheng, J. E. Mangulabnan, S. S. Vedula, M. Ishii, G. Hager, R. H. Taylor, and M. Unberath, “Gsam+ cutie: Text-promptable tool mask annotation for endoscopic video,” inCVPR Workshop, 2024, pp. 2388–2394
work page 2024
-
[20]
Lisa++: An improved baseline for reasoning segmentation with large language model,
S. Yang, T. Qu, X. Lai, Z. Tian, B. Peng, S. Liu, and J. Jia, “Lisa++: An improved baseline for reasoning segmentation with large language model,”arXiv preprint arXiv:2312.17240, 2023
-
[21]
Tatoo: vision-based joint tracking of anatomy and tool for skull-base surgery,
Z. Li, H. Shu, R. Liang, A. Goodridge, M. Sahu, F. X. Creighton, R. H. Taylor, and M. Unberath, “Tatoo: vision-based joint tracking of anatomy and tool for skull-base surgery,”International journal of computer assisted radiology and surgery, vol. 18, no. 7, pp. 1303–1310, 2023
work page 2023
-
[22]
Zebrapose: Coarse to fine surface encoding for 6dof object pose estimation,
Y . Su, M. Saleh, T. Fetzer, J. Rambach, N. Navab, B. Busam, D. Stricker, and F. Tombari, “Zebrapose: Coarse to fine surface encoding for 6dof object pose estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6738–6748
work page 2022
-
[23]
Vision-based surgical tool pose estimation for the da vinci® robotic surgical system,
R. Hao, O. ¨Ozg¨uner, and M. C. C ¸ avus ¸o˘glu, “Vision-based surgical tool pose estimation for the da vinci® robotic surgical system,” in2018 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2018, pp. 1298–1305
work page 2018
-
[24]
M. K. Hasan, L. Calvet, N. Rabbani, and A. Bartoli, “Detection, seg- mentation, and 3d pose estimation of surgical tools using convolutional neural networks and algebraic geometry,”Medical Image Analysis, vol. 70, p. 101994, 2021
work page 2021
- [25]
-
[26]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 10 371–10 381
work page 2024
-
[27]
Epnp: An accurate o(n) so- lution to the pnp problem,
V . Lepetit, F. Moreno-Noguer, and P. Fua, “Epnp: An accurate o(n) so- lution to the pnp problem,” in2009 IEEE 12th International Conference on Computer Vision (ICCV). IEEE, 2009, pp. 1–8
work page 2009
-
[28]
Igev++: Iterative multi-range geometry encoding volumes for stereo matching,
G. Xu, X. Wang, Z. Zhang, J. Cheng, C. Liao, and X. Yang, “Igev++: Iterative multi-range geometry encoding volumes for stereo matching,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[29]
Foundationstereo: Zero-shot stereo matching,
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield, “Foundationstereo: Zero-shot stereo matching,”CVPR, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.