Recognition: no theorem link
Language Models Don't Know What You Want: Evaluating Personalization in Deep Research Needs Real Users
Pith reviewed 2026-05-15 10:30 UTC · model grok-4.3
The pith
Personalization in deep research systems requires real-user evaluation because LLM judges miss key errors
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
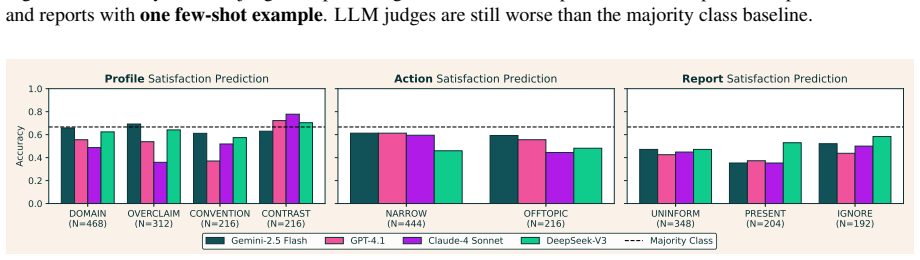
MySQA beats baselines when evaluated with synthetic users and LLM judges on metrics such as citations and personalized action following, yet the same system reveals nine distinct personalization errors during live user interviews that automated judges overlook, establishing that LLM-based evaluation fails to capture the aspects of personalization that real researchers value.
What carries the argument
MyScholarQA (MySQA), the agent that infers a user's research interests to propose actions and write customized reports, which demonstrates the gap between synthetic and real-user outcomes
If this is right
- Synthetic benchmarks with LLM judges produce inflated estimates of personalization quality compared with live user experience.
- Nine specific errors, including profile misalignment and report customization failures, remain invisible to current automated judges.
- Qualitative feedback from users yields concrete design lessons for building future deep research agents.
- Progress toward useful personalization cannot be measured reliably through synthetic protocols alone.
Where Pith is reading between the lines
- The same limitation likely applies to other LLM personalization domains such as recommendation or writing assistants, where proxy judges may hide real-user mismatches.
- Systems could embed continuous user feedback loops rather than one-time interviews to close the evaluation gap.
- Hybrid protocols that combine automated metrics with periodic real-user checks may prove more practical than pure reliance on either approach.
Load-bearing premise
The nine nuanced errors found in the real-user interviews represent the main personalization failures across deep research systems and cannot be captured even by improved LLM judges.
What would settle it
A new real-user study in which improved LLM judges detect every one of the nine error types without omission would falsify the central claim.
Figures












read the original abstract
Deep Research (DR) systems help researchers cope with ballooning publishing counts. Such tools synthesize scientific papers to answer research queries, but lack understanding of their users. We address this with MyScholarQA (MySQA), a personalized DR agent that: 1) infers a profile with a user's research interests; 2) proposes personalized actions for a user's input query; and 3) writes a multi-section report for the query that follows user-approved actions. We first test MySQA with NLP's standard protocol: we build a benchmark with synthetic users and LLM judges, where MySQA beats baselines in citation metrics and personalized action-following. However, we suspect this process does not cover all aspects of personalized DR users value, so we interview users in an online version of MySQA to unmask them. We reveal nine nuanced errors of personalized DR undetectable by our LLM judges, and we study qualitative feedback to form lessons for future DR design. In all, we argue for a pillar of personalization that easy-to-use LLM judges can lead NLP to overlook: real progress in personalization is only possible with real users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MyScholarQA (MySQA), a personalized deep research agent that infers user research profiles, proposes personalized actions for queries, and generates multi-section reports following user-approved actions. It first evaluates MySQA via a synthetic-user benchmark with LLM judges, where it outperforms baselines on citation metrics and personalized action-following. Real-user interviews then uncover nine nuanced personalization errors missed by the LLM judges, leading to the claim that real progress in personalization requires real users rather than easy-to-use LLM judges.
Significance. If the nine errors are shown to be representative and resistant to improved LLM evaluation protocols, the work would meaningfully advance evaluation practices in personalized NLP by demonstrating concrete limitations of synthetic benchmarks and highlighting the value of qualitative user studies for deep research systems. The identification of specific errors provides actionable lessons for DR design.
major comments (2)
- [Abstract and real-user study section] Abstract and real-user study: the central claim that 'real progress in personalization is only possible with real users' because the nine errors are 'undetectable by our LLM judges' rests on the specific judges and protocol in the synthetic benchmark. The manuscript does not report an ablation where the derived error taxonomy is incorporated into LLM judges (via rubrics, chain-of-thought, or stronger models) and re-tested on the real-user transcripts, leaving open whether the errors are inherently beyond LLM capture.
- [Real-user study section] Real-user study section: the qualitative evidence identifies nine nuanced errors but does not report error frequencies across users, inter-rater reliability for error identification, or the exact number of participants and interview protocol details. This weakens the generalizability argument that these errors are representative of personalization failures across deep research systems.
minor comments (2)
- [Abstract] The abstract would benefit from briefly noting the scale of the user study (number of participants) to contextualize the nine errors.
- [Method section] Notation for MySQA components (profile inference, action proposal, report generation) could be more explicitly defined in the method section for clarity when comparing to baselines.
Simulated Author's Rebuttal
Thank you for the detailed and constructive feedback. We address each of the major comments below, proposing revisions to enhance the clarity and robustness of our claims regarding the necessity of real-user evaluations in personalized deep research systems.
read point-by-point responses
-
Referee: [Abstract and real-user study section] Abstract and real-user study: the central claim that 'real progress in personalization is only possible with real users' because the nine errors are 'undetectable by our LLM judges' rests on the specific judges and protocol in the synthetic benchmark. The manuscript does not report an ablation where the derived error taxonomy is incorporated into LLM judges (via rubrics, chain-of-thought, or stronger models) and re-tested on the real-user transcripts, leaving open whether the errors are inherently beyond LLM capture.
Authors: We appreciate this observation. Our initial evaluation followed the standard LLM judge protocol common in NLP research. To strengthen our central claim, we will perform the suggested ablation in the revision: we will integrate the nine-error taxonomy into the LLM judges via enhanced rubrics and chain-of-thought prompting, then re-evaluate the real-user transcripts. We will report the results to further substantiate whether these nuanced errors are detectable by improved LLM protocols. revision: yes
-
Referee: [Real-user study section] Real-user study section: the qualitative evidence identifies nine nuanced errors but does not report error frequencies across users, inter-rater reliability for error identification, or the exact number of participants and interview protocol details. This weakens the generalizability argument that these errors are representative of personalization failures across deep research systems.
Authors: We agree that these methodological details are important for assessing the generalizability of our findings. In the revised manuscript, we will expand the real-user study section to include error frequencies for each identified error, inter-rater reliability scores for the error coding process, the precise number of participants involved, and a comprehensive description of the interview protocol and error identification procedure. These additions will provide a more solid foundation for our arguments about the representativeness of the observed personalization errors. revision: yes
Circularity Check
No circularity; central claim rests on independent user interviews
full rationale
The paper's argument derives from two distinct empirical stages: (1) a synthetic benchmark where MySQA outperforms baselines on citation and action-following metrics judged by LLMs, and (2) separate real-user interviews that surface nine specific errors missed by the same LLM judges. The conclusion that 'real progress in personalization is only possible with real users' follows directly from the interview findings rather than reducing to any fitted parameter, self-definition, or self-citation chain. No equations, ansatzes, or uniqueness theorems are invoked; the evidence is externally grounded in transcribed user sessions and qualitative feedback.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real user interviews reveal personalization errors that are undetectable by LLM judges
Reference graph
Works this paper leans on
-
[1]
InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 735–744
Affective computational priming and creativity. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 735–744. Ting-Peng Liang, Hung-Jen Lai, and Yi-Cheng Ku
-
[2]
Towards personalized deep research: Benchmarks and evaluations.arXiv preprint arXiv:2509.25106, 2025
Personalized content recommendation and user satisfaction: Theoretical synthesis and empir- ical findings.Journal of Management Information Systems, 23(3):45–70. Yuan Liang, Jiaxian Li, Yuqing Wang, Piaohong Wang, Motong Tian, Pai Liu, Shuofei Qiao, Runnan Fang, He Zhu, Ge Zhang, et al. 2025. Towards personalized deep research: Benchmarks and evaluations....
-
[3]
InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–31
Ideasynth: Iterative research idea develop- ment through evolving and composing idea facets with literature-grounded feedback. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–31. Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, and Dong Yu. 2024. Infob...
-
[4]
Ai2 scholar QA: Organized literature synthesis with attribution. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 3: System Demonstrations), pages 513–523, Vienna, Austria. Association for Computa- tional Linguistics. Taylor Sorensen, Jared Moore, Jillian R. Fisher, Mitchell Gordon, Niloofar Mireshghallah...
-
[5]
A Roadmap to Pluralistic Alignment
A roadmap to pluralistic alignment.ArXiv, abs/2402.05070. Neha Srikanth, Jordan Boyd-Graber, and Rachel Rudinger. 2026. Discotrace: Representing and com- paring answering strategies of humans and llms in information-seeking question answering. Chenkai Sun, Ke Yang, Revanth Gangi Reddy, Yi Fung, Hou Pong Chan, Kevin Small, ChengXiang Zhai, and Heng Ji. 202...
work page internal anchor Pith review arXiv 2026
-
[6]
InThe Thirteenth International Conference on Learning Representa- tions
Modeling future conversation turns to teach LLMs to ask clarifying questions. InThe Thirteenth International Conference on Learning Representa- tions. Weinan Zhang, Jun Wang, Bowei Chen, and Xiaoxue Zhao. 2013. To personalize or not: a risk manage- ment perspective.Proceedings of the 7th ACM con- ference on Recommender systems. Xiaolong Zhang, Yan Qu, C. ...
work page 2013
-
[7]
Citesense: supporting sensemaking of research literature. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’08, page 677–680, New York, NY , USA. Association for Computing Machinery. Yu Zhang, Jingwei Sun, Li Feng, Cen Yao, Mingming Fan, Liuxin Zhang, Qianying Wang, Xin Geng, and Yong Rui. 2024a. See widely, think wisely: ...
-
[8]
and CS-PaperSum (Liu et al., 2025b) datasets we build off of on are publicly accessi- ble and used within their intended use. To retrieve the full text of papers for offline experiments, we use an internal database to our organization that already collected them; in our interface to handle new papers, we use the Semantic Scholar Snippets API.15 Our datase...
work page 2026
-
[9]
A set of 5 research papers on semantic scholar (the paper URLs) that you feel best represent your research interests. These are likely pa- pers you have written, wish you had written, are relevant to a project you are working on, or have been highly influential to you as a researcher. Please make sure these are open- access PDFs! (i.e. the semantic schola...
-
[10]
These do not have to be about the papers you have selected
Three research queries that you would be in- terested in asking our Deep Research System. These do not have to be about the papers you have selected
-
[11]
Create a new Gmail account with the fol- lowing credentials: a) Username: [provided email], b) Password: [ anything ], c) Name: [ anything but your own name]. You do not need to use this email to join the Google Meet, but you will need it to log into our interface. You will use this account for both the pilot and any future tasks, and this will ensure no ...
work page 2025
-
[12]
LLMs Shallowly Know You
-
[13]
LLMs Are Shallow Simulators
-
[14]
LLM Judges Swim in Shallow Waters
-
[15]
LLM Judges Stay in the Shallow End
-
[16]
LLM Judges Don’t Take it Personally By displaying these candidate titles (actions), we hope you the reader can also meta-personalize this DR paper (report) for your specific preferences. Split # Queries Avg # Papers / Query Avg Query Length Avg Paper Length Total Instances Dev 281 2.81 17.42 5855.51 281 Test 291 2.91 13.10 5742.30 291 Table 5: Details of ...
work page 2025
-
[17]
Does this approach align with how you’d want personalization to work? Would it save you any time?
How important is it for you to understand and control how a model personalizes to you? Framework [walkthrough]: 1. Does this approach align with how you’d want personalization to work? Would it save you any time?
-
[18]
Why did you pick these papers? 4
What kinds of research tasks would you want to use this for? 3. Why did you pick these papers? 4. Besides your research papers, is there any other information you think would help the system understand you better? Profile Generation [walkthrough]: 1. Would you be open to opting-in for storing an editable version of this profile on MyScholarQA?
-
[19]
If improved, would you want to see this kind of profile for other researchers? Would you let other researchers see this profile of yourself?
-
[20]
Could you see this being useful in other applications beyond MyScholarQA? Plan + Response Generation [walkthrough]: 1. Did you like having the option to view and select potential ways to personalize the query? Would it save you time?
-
[21]
Which of the requirements did MyScholarQA do a good and bad job at following? Did any deviate from what you were expecting?
-
[22]
Did the highlights make it easier to tell where the model attempted to personalize? Would you like this highlighting to be more or less clear if it was built into the prototype? Conclusions: 1. After seeing this in practice, what do you like and dislike about the prototype? 2. Is there anything else we should note while building such a personalized system...
work page 2011
-
[23]
**Topic expertise or interest** - What domains the researcher seems fluent in or newly exploring
-
[24]
**Familiarity with methods** - Implicit or explicit comfort with specific techniques or paradigms
-
[25]
**Distinguishing Focus:** What knowledge the researcher holds or lacks
**Awareness of prior work** - The breadth and specificity of citations or conceptual framing. **Distinguishing Focus:** What knowledge the researcher holds or lacks. </Knowledge> <Research Style> **Definition:** Inferences about *how the researcher prefers to conduct research*. This includes:
-
[26]
**Methodological preferences** - Use of qualitative, quantitative, computational, or hybrid approaches
-
[27]
**Types of research questions** - Empirical, theoretical, exploratory, evaluative, etc
-
[28]
**Distinguishing Focus:** How the researcher approaches doing research
**Study or experiment strategies** - How data is collected, analyzed, or operationalized. **Distinguishing Focus:** How the researcher approaches doing research. </Research Style> <Writing Style> **Definition:** Inferences about *how the researcher writes and explains ideas*. This includes:
-
[29]
**Argumentation and structure** - How ideas are developed, ordered, and emphasized
-
[30]
**Tone and voice** - Formality, assertiveness, didacticism, etc
-
[31]
**Explanation preferences** - Use of examples, metaphors, definitions, or technical language
-
[32]
**Distinguishing Focus:** How the researcher communicates in writing
**Stylistic quirks** - Repetition, narrative devices, or particular rhetorical habits. **Distinguishing Focus:** How the researcher communicates in writing. </Writing Style> <Positions> **Definition:** Inferences about *what the researcher believes or argues*. This includes:
-
[33]
**Claims and conclusions** - What stances are taken or avoided
-
[34]
**Normative views** - Ethical, political, or philosophical commitments evident in the writing
-
[35]
**Distinguishing Focus:** What positions the researcher is taking or signaling
**Arguments emphasized** - Which perspectives are advanced or critiqued. **Distinguishing Focus:** What positions the researcher is taking or signaling. </Positions> <Audience> **Definition:** Inferences about *who the researcher is writing for or trying to impact*. This includes:
-
[36]
**Assumed audience background** - What the researcher expects the reader to already know
-
[37]
**Stakeholder relevance** - Who is likely to be affected by or benefit from the work
-
[38]
**Distinguishing Focus:** Who the researcher is addressing or aiming to influence
**Audience alignment** - Whether the writing aligns with academic, practitioner, policy, or public communities. **Distinguishing Focus:** Who the researcher is addressing or aiming to influence. </Audience> Prompt D.3: Action Generation Prompt (§2.2) Here are a list of inferences about a user. The numbered inference is a high-level inference, while the su...
-
[39]
organization: outlines sections for the final response to include
-
[40]
Each personalization strategy should specify two requirements:
generation: produces text for each of these sections To help PersonalizedQA personalize responses based on the user’s profile, come up with a list of personalization strategies that the system should follow. Each personalization strategy should specify two requirements:
-
[41]
What kind of response the user will experience (Qualitative Personalization)
-
[42]
How the system should behave at each step (Implementation Personalization) The qualitative personalization label is based on how the response will be personalized to the user at a qualitative level: <qualitative personalization strategies> insert qualitative rubric </qualitative personalization strategies> The implementation personalization label is based...
-
[43]
**Conceptual scope** - Which concepts to emphasize, omit, or define
-
[44]
**Depth of explanation** - Whether to provide brief overviews (if the user is knowledgeable on the area) or in-depth knowledge (if the user is new to the field)
-
[45]
**Distinguishing Focus:** What content is covered and how deeply
**Terminology alignment** - Tailoring vocab to match the user’s disciplinary conventions. **Distinguishing Focus:** What content is covered and how deeply. </Content> <Explanation Style> **Definition:** Specifies *how the explanation for the information is communicated*. This can include:
-
[46]
**Explanatory style** - Empirical, intuitive, formal/mathematical, or example-led
-
[47]
**Cognitive structuring** - Layered explanations, definitions first vs. bottom-up learning
-
[48]
**Distinguishing Focus:** How the content is explained, formatted, and connected to other concepts
**Framing mechanisms** - Use of analogies, metaphors, or domain-specific language aligned with the researcher’s background. **Distinguishing Focus:** How the content is explained, formatted, and connected to other concepts. </Explanation Style> <Specificity> **Definition:** Clarifies and narrows the scope of the response to better match the researcher’s i...
- [49]
-
[50]
**Focusing by domain/task** - Aligning content to a subfield, methodology, or research phase
-
[51]
**Resolving underspecification** - Filling in implicit assumptions (e.g., assuming qualitative when not stated)
-
[52]
**Distinguishing Focus:** What exactly is meant or needed, and how to restrict the response to that
**Removing irrelevant scope** - Avoiding generalizations or adjacent topics not central to the task. **Distinguishing Focus:** What exactly is meant or needed, and how to restrict the response to that. </Specificity> <Usefulness> **Definition:** Shapes the response to be *actionable* or *instrumental* for the researcher’s goals or workflow. This can include:
-
[53]
**Direct application** - Helping write a section, implement a method, interpret results, etc
-
[54]
**Workflow integration** - Mapping content to stages of research or types of output
-
[55]
**Next steps** - Suggesting what to do with the information (e.g., adapt, cite, reframe, test)
-
[56]
**Decision support** - Helping choose between options, methods, or framings based on task-fit. **Distinguishing Focus:** How the information can be turned into research actions or outputs. </Usefulness> Prompt D.5: Action Implementation Categories <Search Add> **Definition:** Personalizes the search by **adding new terms or dimensions** to the original qu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.