Recognition: no theorem link
SegviGen: Repurposing 3D Generative Model for Part Segmentation
Pith reviewed 2026-05-15 09:25 UTC · model grok-4.3
The pith
Pretrained 3D generative models can be repurposed for 3D part segmentation by predicting part-specific colors on geometry-aligned voxels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
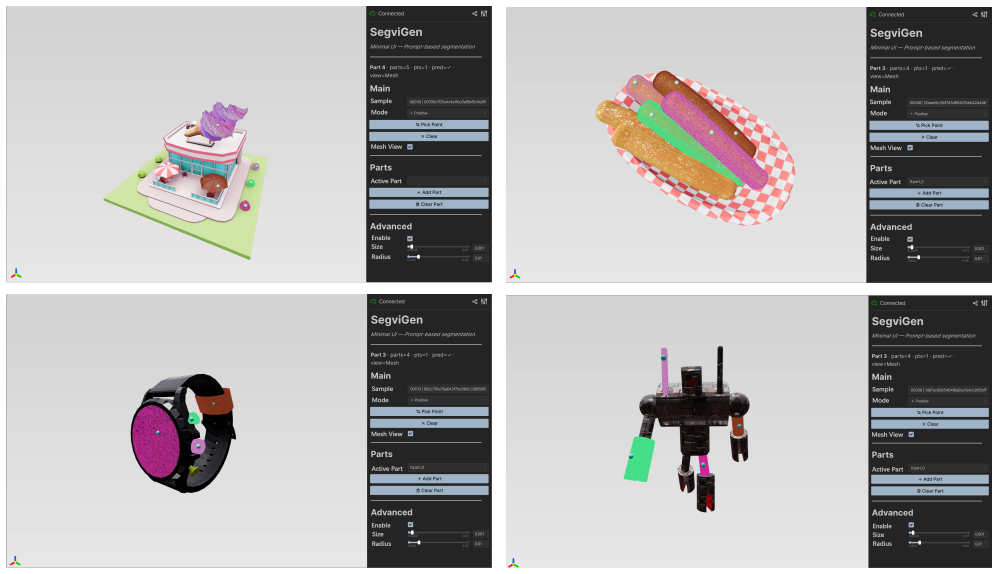
SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction, inducing segmentation from the structured priors already present in a pretrained 3D generative model; the same framework supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance.
What carries the argument
Part-indicative colorization prediction performed on geometry-aligned voxels, which extracts segmentation boundaries from the generative model's existing priors.
If this is right
- Interactive part segmentation accuracy rises 40 percent over prior state-of-the-art methods.
- Full segmentation accuracy rises 15 percent over prior state-of-the-art methods.
- The entire pipeline operates with only 0.32 percent of the labeled training data required by previous approaches.
- One model handles interactive segmentation, full segmentation, and 2D-guided segmentation without separate training runs.
Where Pith is reading between the lines
- The approach could be tested on generative models trained on different object categories to measure how much domain match between pretraining and target shapes affects boundary quality.
- Annotation budgets in robotics or augmented-reality pipelines could drop substantially if only a few dozen labeled examples suffice for new part vocabularies.
- Extending the voxel colorization step to time-varying 3D data might allow part tracking in dynamic scenes with the same low-label regime.
Load-bearing premise
The structured priors already learned by the 3D generative model can be aligned to actual part boundaries simply by training the model to predict colors on geometry-aligned voxels.
What would settle it
A controlled experiment in which the colorization prediction head is replaced by a random color assignment or by a non-pretrained encoder, with all other components held fixed, would show whether the performance gains disappear.
Figures






read the original abstract
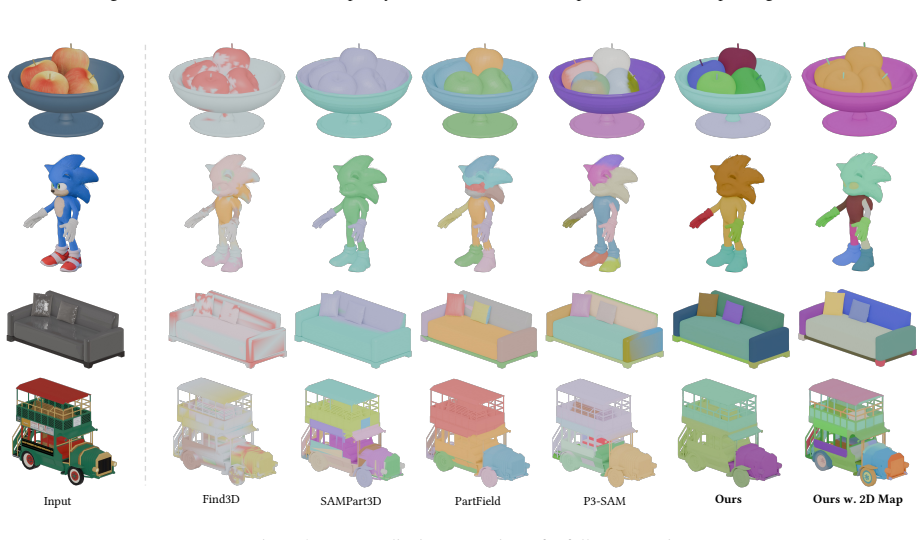
We introduce SegviGen, a framework that repurposes native 3D generative models for 3D part segmentation. Existing pipelines either lift strong 2D priors into 3D via distillation or multi-view mask aggregation, often suffering from cross-view inconsistency and blurred boundaries, or explore native 3D discriminative segmentation, which typically requires large-scale annotated 3D data and substantial training resources. In contrast, SegviGen leverages the structured priors encoded in pretrained 3D generative model to induce segmentation through distinctive part colorization, establishing a novel and efficient framework for part segmentation. Specifically, SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction. It supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance in a unified framework. Extensive experiments show that SegviGen improves over the prior state of the art by 40% on interactive part segmentation and by 15% on full segmentation, while using only 0.32% of the labeled training data. It demonstrates that pretrained 3D generative priors transfer effectively to 3D part segmentation, enabling strong performance with limited supervision. See our project page at https://fenghora.github.io/SegviGen-Page/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SegviGen, a framework that repurposes pretrained 3D generative models for 3D part segmentation by encoding a 3D asset and predicting part-indicative colors on active voxels of a geometry-aligned reconstruction. It unifies support for interactive part segmentation, full segmentation, and full segmentation with 2D guidance, claiming improvements of 40% over prior SOTA on interactive segmentation and 15% on full segmentation while using only 0.32% of labeled training data.
Significance. If the results hold under fair comparisons, the work demonstrates that structured priors from 3D generative models can transfer effectively to discriminative part segmentation with minimal supervision, offering a data-efficient alternative to distillation-based or large-scale annotation approaches in 3D vision.
major comments (2)
- [Method] The central mechanism (encoding followed by color prediction on active voxels of a geometry-aligned reconstruction) lacks any specification of voxel resolution, active-voxel selection criteria, or reconstruction artifacts. This detail is load-bearing for the claim that generative priors map to true part boundaries rather than voxel-grid geometry, as discretization could blur semantic edges and undermine the 40%/15% gains.
- [Experiments] No ablation is described that isolates the contribution of the colorization signal from underlying geometric cues in the reconstruction. Without this, the reported improvements with 0.32% labels cannot be confidently attributed to transfer of generative priors rather than mesh or voxel structure.
minor comments (1)
- [Abstract] The abstract references a project page for additional details, but the manuscript text provides no explicit statement on code or model release to support reproducibility of the quantitative claims.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. We will revise the manuscript to address the concerns raised regarding methodological details and experimental ablations. Our point-by-point responses are as follows.
read point-by-point responses
-
Referee: [Method] The central mechanism (encoding followed by color prediction on active voxels of a geometry-aligned reconstruction) lacks any specification of voxel resolution, active-voxel selection criteria, or reconstruction artifacts. This detail is load-bearing for the claim that generative priors map to true part boundaries rather than voxel-grid geometry, as discretization could blur semantic edges and undermine the 40%/15% gains.
Authors: We agree with the referee that these implementation details are crucial for understanding the method and validating the claims. In the revised manuscript, we will expand the method section to include the voxel resolution of the reconstruction grid, the criteria for identifying active voxels (based on the generative model's occupancy output), and an analysis of how reconstruction artifacts are handled. This addition will clarify that the part boundaries are determined by the colorization signal rather than solely by the voxel discretization. revision: yes
-
Referee: [Experiments] No ablation is described that isolates the contribution of the colorization signal from underlying geometric cues in the reconstruction. Without this, the reported improvements with 0.32% labels cannot be confidently attributed to transfer of generative priors rather than mesh or voxel structure.
Authors: This is a fair criticism, and we will address it by adding a new ablation study in the experiments section. The ablation will evaluate a geometry-only baseline that relies solely on the reconstruction without the generative color prediction. By comparing this to the full SegviGen model, we aim to demonstrate the specific benefit of repurposing the 3D generative priors for part segmentation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents SegviGen as an empirical framework that repurposes an external pretrained 3D generative model via colorization prediction on geometry-aligned voxels. No equations, derivations, or self-citations are shown that reduce the claimed 40%/15% gains or 0.32% data efficiency to quantities fitted inside the paper by construction. The approach is described as leveraging independent structured priors from the pretrained model, with performance validated through experiments rather than self-referential definitions or fitted inputs renamed as predictions. This is a standard non-circular empirical repurposing result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained 3D generative models encode structured part priors that transfer to segmentation via colorization on geometry-aligned voxels.
Reference graph
Works this paper leans on
-
[1]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, 2021. 3
work page 2021
-
[3]
Meshxl: Neural coordinate field for generative 3d foundation models,
Sijin Chen, Xin Chen, Anqi Pang, Xianfang Zeng, Wei Cheng, Yijun Fu, Fukun Yin, Yanru Wang, Zhibin Wang, Chi Zhang, Jingyi Yu, Gang Yu, Bin Fu, and Tao Chen. Meshxl: Neural coordinate field for generative 3d foundation models,
-
[4]
A benchmark for 3d mesh segmentation
Xiaobai Chen, Aleksey Golovinskiy, and Thomas Funkhouser. A benchmark for 3d mesh segmentation. InSIGGRAPH, 2009. 2
work page 2009
-
[5]
Meshanything: Artist- created mesh generation with autoregressive transformers,
Yiwen Chen, Tong He, Di Huang, Weicai Ye, Sijin Chen, Jiaxiang Tang, Xin Chen, Zhongang Cai, Lei Yang, Gang Yu, Guosheng Lin, and Chi Zhang. Meshanything: Artist- created mesh generation with autoregressive transformers,
-
[6]
Ultra3d: Efficient and high- fidelity 3d generation with part attention, 2025
Yiwen Chen, Zhihao Li, Yikai Wang, Hu Zhang, Qin Li, Chi Zhang, and Guosheng Lin. Ultra3d: Efficient and high- fidelity 3d generation with part attention, 2025. 3
work page 2025
-
[7]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In arXiv, 2017. 2
work page 2017
-
[8]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13142–13153, 2023. 3
work page 2023
-
[9]
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Informa- tion Processing Systems, 36, 2024. 3
work page 2024
-
[10]
Geosam2: Unleashing the power of sam2 for 3d part segmentation
Ken Deng, Yunhan Yang, Jingxiang Sun, Xihui Liu, Yebin Liu, Ding Liang, and Yan-Pei Cao. Geosam2: Unleashing the power of sam2 for 3d part segmentation. InarXiv, 2025. 2
work page 2025
-
[11]
Tela: Text to layer-wise 3d clothed human generation
Junting Dong, Qi Fang, Zehuan Huang, Xudong Xu, Jingbo Wang, Sida Peng, and Bo Dai. Tela: Text to layer-wise 3d clothed human generation. InEuropean Conference on Com- puter Vision, pages 19–36. Springer, 2025. 3
work page 2025
-
[12]
From one to more: Contextual part latents for 3d gener- ation, 2025
Shaocong Dong, Lihe Ding, Xiao Chen, Yaokun Li, Yuxin Wang, Yucheng Wang, Qi Wang, Jaehyeok Kim, Chenjian Gao, Zhanpeng Huang, Zibin Wang, Tianfan Xue, and Dan Xu. From one to more: Contextual part latents for 3d gener- ation, 2025. 6
work page 2025
-
[13]
From one to more: Contextual part latents for 3d gener- ation, 2025
Shaocong Dong, Lihe Ding, Xiao Chen, Yaokun Li, Yuxin Wang, Yucheng Wang, Qi Wang, Jaehyeok Kim, Chenjian Gao, Zhanpeng Huang, Zibin Wang, Tianfan Xue, and Dan Xu. From one to more: Contextual part latents for 3d gener- ation, 2025. 3
work page 2025
-
[14]
Me- shart: Generating articulated meshes with structure-guided transformers, 2025
Daoyi Gao, Yawar Siddiqui, Lei Li, and Angela Dai. Me- shart: Generating articulated meshes with structure-guided transformers, 2025. 3
work page 2025
-
[15]
3d part seg- mentation via geometric aggregation of 2d visual features
Marco Garosi, Riccardo Tedoldi, Davide Boscaini, Massim- iliano Mancini, Nicu Sebe, and Fabio Poiesi. 3d part seg- mentation via geometric aggregation of 2d visual features. InarXiv, 2025. 3
work page 2025
-
[16]
Meshcnn: a network with an edge
Rana Hanocka, Amir Hertz, Noa Fish, Raja Giryes, Shachar Fleishman, and Daniel Cohen-Or. Meshcnn: a network with an edge. InACM, 2019. 2
work page 2019
-
[17]
Romero, Tsung-Yi Lin, and Ming-Yu Liu
Zekun Hao, David W. Romero, Tsung-Yi Lin, and Ming-Yu Liu. Meshtron: High-fidelity, artist-like 3d mesh generation at scale, 2024. 3
work page 2024
-
[18]
Zexin He, Tengfei Wang, Xin Huang, Xingang Pan, and Zi- wei Liu. Neural lightrig: Unlocking accurate object normal and material estimation with multi-light diffusion, 2024. 3
work page 2024
-
[19]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
work page 2020
-
[20]
LRM: Large Reconstruction Model for Single Image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[21]
Segment3d: Learning fine-grained class-agnostic 3d segmentation without manual labels
Rui Huang, Songyou Peng, Ayca Takmaz, Federico Tombari, Marc Pollefeys, Shiji Song, Gao Huang, and Francis Engel- mann. Segment3d: Learning fine-grained class-agnostic 3d segmentation without manual labels. InEuropean Confer- ence on Computer Vision, pages 278–295. Springer, 2024. 2
work page 2024
-
[22]
Stereo-gs: Multi-view stereo vision model for generalizable 3d gaussian splatting reconstruction,
Xiufeng Huang, Ka Chun Cheung, Runmin Cong, Simon See, and Renjie Wan. Stereo-gs: Multi-view stereo vision model for generalizable 3d gaussian splatting reconstruction,
-
[23]
Mv-adapter: Multi-view consistent image generation made easy.arXiv preprint arXiv:2412.03632, 2024
Zehuan Huang, Yuan-Chen Guo, Haoran Wang, Ran Yi, Lizhuang Ma, Yan-Pei Cao, and Lu Sheng. Mv-adapter: Multi-view consistent image generation made easy.arXiv preprint arXiv:2412.03632, 2024. 3
-
[24]
Epidiff: Enhancing multi-view synthesis via localized epipolar-constrained diffusion
Zehuan Huang, Hao Wen, Junting Dong, Yaohui Wang, Yangguang Li, Xinyuan Chen, Yan-Pei Cao, Ding Liang, Yu Qiao, Bo Dai, et al. Epidiff: Enhancing multi-view synthesis via localized epipolar-constrained diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 9784–9794, 2024. 3 11
work page 2024
-
[25]
Auto-Encoding Variational Bayes
Diederik P Kingma. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[26]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. InarXiv, 2023. 2, 3
work page 2023
-
[27]
Lin Li, Zehuan Huang, Haoran Feng, Gengxiong Zhuang, Rui Chen, Chunchao Guo, and Lu Sheng. V oxhammer: Training-free precise and coherent 3d editing in native 3d space.arXiv preprint arXiv:2508.19247, 2025. 8
-
[28]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In arXiv, 2022. 3
work page 2022
-
[29]
Weiyu Li, Jiarui Liu, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman: High-fidelity mesh generation with 3d native generation and interactive geometry refiner.arXiv preprint arXiv:2405.14979, 2024. 3
-
[30]
Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner, 2025. 3
work page 2025
-
[31]
Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets, 2025
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, Xiao Chen, Feipeng Tian, Jianxiong Pan, Zeming Li, Gang Yu, Xiangyu Zhang, Daxin Jiang, and Ping Tan. Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets, 2025. 3
work page 2025
-
[32]
Triposg: High- fidelity 3d shape synthesis using large-scale rectified flow models, 2025
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, and Yan-Pei Cao. Triposg: High- fidelity 3d shape synthesis using large-scale rectified flow models, 2025. 3
work page 2025
-
[33]
arXiv preprint arXiv:2502.06608 (2025)
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.arXiv preprint arXiv:2502.06608, 2025. 3
-
[34]
End-to-end hu- man pose and mesh reconstruction with transformers
Kevin Lin, Lijuan Wang, and Zicheng Liu. End-to-end hu- man pose and mesh reconstruction with transformers. In CVPR, 2021. 2
work page 2021
-
[35]
Partcrafter: Structured 3d mesh generation via compositional latent diffusion transformers, 2025
Yuchen Lin, Chenguo Lin, Panwang Pan, Honglei Yan, Yiqiang Feng, Yadong Mu, and Katerina Fragkiadaki. Partcrafter: Structured 3d mesh generation via compositional latent diffusion transformers, 2025. 3
work page 2025
-
[36]
Part123: part-aware 3d reconstruction from a single-view image
Anran Liu, Cheng Lin, Yuan Liu, Xiaoxiao Long, Zhiyang Dou, Hao-Xiang Guo, Ping Luo, and Wenping Wang. Part123: part-aware 3d reconstruction from a single-view image. InACM SIGGRAPH 2024 Conference Papers, pages 1–12, 2024. 3
work page 2024
-
[37]
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Ji- ayuan Gu, and Hao Su. One-2-3-45++: Fast single im- age to 3d objects with consistent multi-view generation and 3d diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10072– 10083, 2024
work page 2024
-
[38]
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimiza- tion.Advances in Neural Information Processing Systems, 36, 2024. 3
work page 2024
-
[39]
Partfield: Learn- ing 3d feature fields for part segmentation and beyond
Minghua Liu, Mikaela Angelina Uy, Donglai Xiang, Hao Su, Sanja Fidler, Nicholas Sharp, and Jun Gao. Partfield: Learn- ing 3d feature fields for part segmentation and beyond. In ICCV, 2025. 3, 6, 9
work page 2025
-
[40]
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Gen- erating multiview-consistent images from a single-view im- age.arXiv preprint arXiv:2309.03453, 2023. 3
-
[41]
Wonder3d: Sin- gle image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Sin- gle image to 3d using cross-domain diffusion. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9970–9980, 2024. 3
work page 2024
-
[42]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. 6
work page 2019
-
[43]
P3-sam: Native 3d part segmentation
Changfeng Ma, Yang Li, Xinhao Yan, Jiachen Xu, Yunhan Yang, Chunshi Wang, Zibo Zhao, Yanwen Guo, Zhuo Chen, and Chunchao Guo. P3-sam: Native 3d part segmentation. InarXiv, 2025. 2, 3, 5, 6, 7, 9
work page 2025
-
[44]
Ziqi Ma, Yisong Yue, and Georgia Gkioxari. Find any part in 3d. InarXiv, 2025. 3, 6, 9
work page 2025
-
[45]
Lt3sd: Latent trees for 3d scene diffusion.arXiv preprint arXiv:2409.08215, 2024
Quan Meng, Lei Li, Matthias Nießner, and Angela Dai. Lt3sd: Latent trees for 3d scene diffusion.arXiv preprint arXiv:2409.08215, 2024. 3
-
[46]
Chang, Li Yi, Subarna Tripathi, Leonidas J
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. Partnet: A large- scale benchmark for fine-grained and hierarchical part-level 3d object understanding. InCVPR, 2019. 2
work page 2019
-
[47]
Maxime Oquab, Timoth ´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Rus- sell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang- Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nico- las Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patri...
work page 2023
-
[48]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 4195–4205,
-
[49]
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classifica- tion and segmentation. InarXiv preprint arXiv:1612.00593,
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Deocc-1-to-3: 3d de- occlusion from a single image via self-supervised multi-view diffusion, 2025
Yansong Qu, Shaohui Dai, Xinyang Li, Yuze Wang, You Shen, Liujuan Cao, and Rongrong Ji. Deocc-1-to-3: 3d de- occlusion from a single image via self-supervised multi-view diffusion, 2025. 3
work page 2025
-
[51]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, 12 Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InarXiv, 2021. 3
work page 2021
-
[52]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. In arXiv, 2024. 2, 3
work page 2024
-
[53]
L3dg: Latent 3d gaussian diffusion
Barbara Roessle, Norman M ¨uller, Lorenzo Porzi, Samuel Rota Bulø, Peter Kontschieder, Angela Dai, and Matthias Nießner. L3dg: Latent 3d gaussian diffusion. arXiv preprint arXiv:2410.13530, 2024. 3
-
[54]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[55]
George Tang, William Zhao, Logan Ford, David Benhaim, and Paul Zhang. Segment any mesh. InarXiv, 2025. 3
work page 2025
-
[56]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2025. 3
work page 2025
-
[57]
Efficient part-level 3d object generation via dual volume packing.arXiv preprint arXiv:2506.09980,
Jiaxiang Tang, Ruijie Lu, Zhaoshuo Li, Zekun Hao, Xuan Li, Fangyin Wei, Shuran Song, Gang Zeng, Ming-Yu Liu, and Tsung-Yi Lin. Efficient part-level 3d object generation via dual volume packing.arXiv preprint arXiv:2506.09980,
-
[58]
Efficient part-level 3d object generation via dual volume packing, 2025
Jiaxiang Tang, Ruijie Lu, Zhaoshuo Li, Zekun Hao, Xuan Li, Fangyin Wei, Shuran Song, Gang Zeng, Ming-Yu Liu, and Tsung-Yi Lin. Efficient part-level 3d object generation via dual volume packing, 2025. 3
work page 2025
-
[59]
Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material,
Tencent Hunyuan3D Team. Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material,
-
[60]
Partdistill: 3d shape part segmen- tation by vision-language model distillation
Ardian Umam, Cheng-Kun Yang, Min-Hung Chen, Jen-Hui Chuang, and Yen-Yu Lin. Partdistill: 3d shape part segmen- tation by vision-language model distillation. InarXiv, 2024. 3
work page 2024
-
[61]
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. Sv3d: Novel multi-view syn- thesis and 3d generation from a single image using latent video diffusion. InEuropean Conference on Computer Vi- sion, pages 439–457. Springer, 2025. 3
work page 2025
-
[62]
Partnext: A next-generation dataset for fine-grained and hierarchical 3d part understand- ing, 2025
Penghao Wang, Yiyang He, Xin Lv, Yukai Zhou, Lan Xu, Jingyi Yu, and Jiayuan Gu. Partnext: A next-generation dataset for fine-grained and hierarchical 3d part understand- ing, 2025. 2, 6
work page 2025
-
[63]
Llama-mesh: Uni- fying 3d mesh generation with language models, 2024
Zhengyi Wang, Jonathan Lorraine, Yikai Wang, Hang Su, Jun Zhu, Sanja Fidler, and Xiaohui Zeng. Llama-mesh: Uni- fying 3d mesh generation with language models, 2024. 3
work page 2024
-
[64]
Zhengyi Wang, Yikai Wang, Yifei Chen, Chendong Xi- ang, Shuo Chen, Dajiang Yu, Chongxuan Li, Hang Su, and Jun Zhu. Crm: Single image to 3d textured mesh with convolutional reconstruction model.arXiv preprint arXiv:2403.05034, 2024. 3
-
[65]
Octgpt: Octree-based multi- scale autoregressive models for 3d shape generation, 2025
Si-Tong Wei, Rui-Huan Wang, Chuan-Zhi Zhou, Baoquan Chen, and Peng-Shuai Wang. Octgpt: Octree-based multi- scale autoregressive models for 3d shape generation, 2025
work page 2025
-
[66]
Hao Wen, Zehuan Huang, Yaohui Wang, Xinyuan Chen, Yu Qiao, and Lu Sheng. Ouroboros3d: Image-to-3d gen- eration via 3d-aware recursive diffusion.arXiv preprint arXiv:2406.03184, 2024. 3
-
[67]
arXiv preprint arXiv:2405.20343 (2024)
Kailu Wu, Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan, and Kaisheng Ma. Unique3d: High-quality and efficient 3d mesh generation from a single image.arXiv preprint arXiv:2405.20343, 2024. 3
-
[68]
Dipo: Dual-state images controlled articulated object generation powered by diverse data, 2025
Ruiqi Wu, Xinjie Wang, Liu Liu, Chunle Guo, Jiaxiong Qiu, Chongyi Li, Lichao Huang, Zhizhong Su, and Ming-Ming Cheng. Dipo: Dual-state images controlled articulated object generation powered by diverse data, 2025. 3
work page 2025
-
[69]
arXiv preprint arXiv:2405.14832 (2024)
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, and Yao Yao. Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer. arXiv preprint arXiv:2405.14832, 2024. 3
-
[70]
Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention, 2025
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Yikang Yang, Yajie Bao, Jiachen Qian, Siyu Zhu, Xun Cao, Philip Torr, and Yao Yao. Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention, 2025. 3
work page 2025
-
[71]
Point transformer v2: Grouped vector atten- tion and partition-based pooling
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Heng- shuang Zhao. Point transformer v2: Grouped vector atten- tion and partition-based pooling. InNeurIPS, 2022. 2
work page 2022
-
[72]
Point transformer v3: Simpler, faster, stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xi- hui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler, faster, stronger. In CVPR, 2024
work page 2024
-
[73]
Towards large- scale 3d representation learning with multi-dataset point prompt training
Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, and Hengshuang Zhao. Towards large- scale 3d representation learning with multi-dataset point prompt training. InCVPR, 2024. 2
work page 2024
-
[74]
Zhennan Wu, Yang Li, Han Yan, Taizhang Shang, Weixuan Sun, Senbo Wang, Ruikai Cui, Weizhe Liu, Hiroyuki Sato, Hongdong Li, et al. Blockfusion: Expandable 3d scene gen- eration using latent tri-plane extrapolation.ACM Transac- tions on Graphics (TOG), 43(4):1–17, 2024. 3
work page 2024
-
[75]
Native and compact struc- tured latents for 3d generation
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, et al. Native and compact struc- tured latents for 3d generation. InarXiv, 2025. 3, 4, 6
work page 2025
-
[76]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21469–21480, 2025. 3
work page 2025
-
[77]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models.arXiv preprint arXiv:2404.07191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Sampro3d: Locating sam prompts in 3d for zero-shot instance segmentation
Mutian Xu, Xingyilang Yin, Lingteng Qiu, Yang Liu, Xin Tong, and Xiaoguang Han. Sampro3d: Locating sam prompts in 3d for zero-shot instance segmentation. InarXiv,
-
[79]
Ze- rops: High-quality cross-modal knowledge transfer for zero- shot 3d part segmentation
Yuheng Xue, Nenglun Chen, Jun Liu, and Wenyun Sun. Ze- rops: High-quality cross-modal knowledge transfer for zero- shot 3d part segmentation. InarXiv, 2025
work page 2025
-
[80]
Sam3d: Segment anything in 3d scenes
Yunhan Yang, Xiaoyang Wu, Tong He, Hengshuang Zhao, and Xihui Liu. Sam3d: Segment anything in 3d scenes. In arXiv, 2023. 3
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.