Recognition: 2 theorem links
· Lean TheoremGLENN: Neural network-enhanced computation of Ginzburg-Landau energy minimizers
Pith reviewed 2026-05-15 08:26 UTC · model grok-4.3
The pith
Neural network approximates Ginzburg-Landau minimizers for ranges of kappa
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an unsupervised neural network can be trained to approximate Ginzburg-Landau energy minimizers with kappa as input, yielding results usable either directly or as initial guesses that enable classical finite element methods to converge to the true minimizer.
What carries the argument
The unsupervised deep Ritz-type neural network strategy that directly minimizes the Ginzburg-Landau energy as the loss, with kappa included as an input variable.
Load-bearing premise
That the unsupervised neural network training produces approximations accurate enough to serve either as standalone solutions or as reliable initial guesses from which the classical finite element minimization converges to the true minimizer for a wide range of kappa values.
What would settle it
Observing a kappa value where starting the classical minimization from the neural network approximation fails to reach the global energy minimum obtained by other reliable methods.
Figures
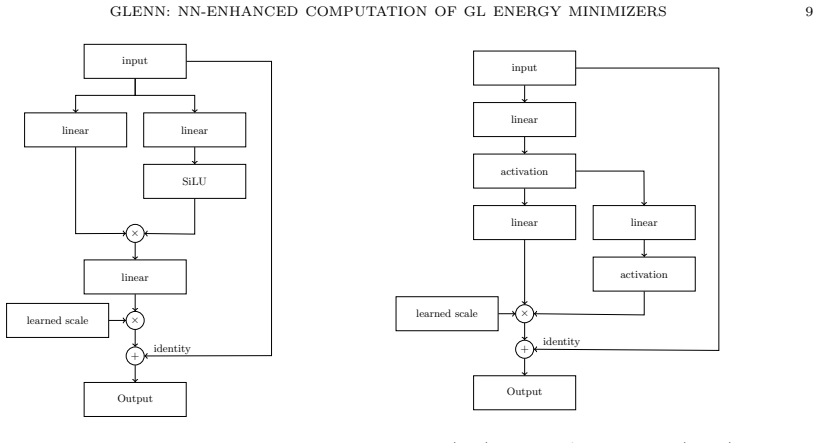




read the original abstract
In this work, we propose a neural network-enhanced finite element strategy to compute the minimizer of the Ginzburg-Landau energy based on an unsupervised deep Ritz-type strategy. We treat the parameter $\kappa$ as a variable input parameter to obtain possible minimizers for a large range of $\kappa$-values. This allows for two possible strategies: 1) The neural network may be extensively trained to work as a stand-alone solver. 2) Neural network results are used as starting values for a subsequent classical iterative minimization procedure. The latter strategy particularly circumvents the missing reliability of the neural network-based approach. Numerical examples are presented that show the potential of the proposed strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GLENN, a neural network-enhanced finite element strategy to compute minimizers of the Ginzburg-Landau energy based on an unsupervised deep Ritz-type method that takes the parameter κ as an input variable. It outlines two strategies: extensive training of the neural network to serve as a standalone solver, or using the neural network outputs as initial guesses for a subsequent classical iterative minimization procedure. Numerical examples are presented to illustrate the potential of the approach, particularly for circumventing reliability issues in the standalone neural network method.
Significance. If the hybrid strategy reliably produces initial guesses that converge to global minimizers across a wide range of κ (including regimes with highly non-convex energy landscapes), the work could provide a practical tool for exploring vortex configurations in the Ginzburg-Landau model. The unsupervised training with κ as input and the explicit fallback to classical minimization are pragmatic strengths that address known limitations of pure neural network approaches in non-convex variational problems.
major comments (2)
- [Numerical examples] Numerical examples section: no quantitative metrics (e.g., relative energy errors, L2 differences to reference solutions, or success rates in reaching the global minimizer) are reported for the neural-network-initialized classical minimization, nor are direct comparisons provided against standard initial data (constant or random fields) for κ values where direct minimization is known to fail.
- [Abstract and method] Abstract and §2 (method description): the central claim that neural network results serve as reliable starting values for classical minimization lacks any a priori error bound, basin-of-attraction analysis, or demonstration that the unsupervised Ritz loss approximation systematically lies inside the attraction basin of the global minimizer rather than a local vortex configuration.
minor comments (2)
- [Method] Clarify the precise form of the Ritz-type loss functional when κ is treated as a network input, including how the penalty terms for the constraint |u|=1 are discretized.
- [Numerical examples] Add a brief discussion of training stability and hyperparameter sensitivity, as these directly affect reproducibility of the initial-guess strategy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have carefully considered the major comments and provide point-by-point responses below. Revisions have been made to address the concerns regarding quantitative metrics and to clarify the scope of our claims.
read point-by-point responses
-
Referee: Numerical examples section: no quantitative metrics (e.g., relative energy errors, L2 differences to reference solutions, or success rates in reaching the global minimizer) are reported for the neural-network-initialized classical minimization, nor are direct comparisons provided against standard initial data (constant or random fields) for κ values where direct minimization is known to fail.
Authors: We agree that additional quantitative metrics would strengthen the presentation. In the revised manuscript, we have augmented the numerical examples section with relative energy errors with respect to reference solutions computed via classical methods with multiple initial guesses, L2 norm differences where applicable, and success rates in attaining the presumed global minimizer. Direct comparisons are now included against constant and random initial fields for κ values known to pose challenges for direct minimization, such as those leading to complex vortex lattices. These additions confirm the benefits of the neural network initialization. revision: yes
-
Referee: Abstract and §2 (method description): the central claim that neural network results serve as reliable starting values for classical minimization lacks any a priori error bound, basin-of-attraction analysis, or demonstration that the unsupervised Ritz loss approximation systematically lies inside the attraction basin of the global minimizer rather than a local vortex configuration.
Authors: The manuscript is focused on developing and demonstrating a practical computational strategy rather than providing theoretical guarantees. We do not claim a priori bounds or a full basin-of-attraction analysis, as these would require substantial additional theoretical developments that are beyond the paper's scope. Instead, we rely on comprehensive numerical experiments to show that the approach reliably converges to global minimizers. We have revised the abstract and Section 2 to explicitly state that the reliability is empirically observed and to discuss the limitations of the unsupervised Ritz method in non-convex settings without theoretical backing. revision: partial
Circularity Check
No circularity: standard deep Ritz NN for GL energy with hybrid FE fallback
full rationale
The paper's chain is the standard unsupervised deep Ritz minimization of the Ginzburg-Landau functional (with kappa as input parameter) followed by optional use of the NN output as an initial guess for classical finite-element iteration. No equation reduces the claimed minimizer to a quantity defined by the NN fit itself, no prediction is statistically forced by a subset fit, and no load-bearing step relies on self-citation or imported uniqueness theorems. The hybrid strategy explicitly acknowledges limited standalone reliability and defers to classical minimization, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Ginzburg-Landau energy functional admits a well-defined minimizer that can be approximated by finite element methods
- ad hoc to paper Unsupervised training via a Ritz-type loss can produce useful approximations to the energy minimizer
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a neural network-enhanced finite element strategy to compute the minimizer of the Ginzburg-Landau energy based on an unsupervised deep Ritz-type strategy... Neural network results are used as starting values for a subsequent classical iterative minimization procedure.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The loss functional for the GL problem reads E(u,A) := ∫_κmin^κmax κ Ê(u,A,κ) dκ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. A. Abrikosov. Nobel lecture: Type-II superconductors and the vortex lattice.Rev. Mod. Phys., 76(3,1):975– 979, 2004
work page 2004
-
[2]
J. Adler and O. ¨Oktem. Solving ill-posed inverse problems using iterative deep neural networks.Inverse Prob- lems, 33(12):124007, 24, 2017
work page 2017
- [3]
-
[4]
J. Ansel et al. PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation. In29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (ASPLOS ’24). ACM, Apr. 2024
work page 2024
-
[5]
I. A. Baratta et al. DOLFINx: The next generation FEniCS problem solving environment, Dec. 2023
work page 2023
-
[6]
M. Blum, C. D¨ oding, and P. Henning. Vortex-capturing multiscale spaces for the Ginzburg-Landau equation. Multiscale Model. Simul., 23(1):339–373, 2025
work page 2025
-
[7]
T. Chaumont-Frelet and P. Henning. The pollution effect for FEM approximations of the Ginzburg-Landau equation.Math. Comp., page 49pp., 2026. Online first
work page 2026
-
[8]
Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier. Language Modeling with Gated Convolutional Networks. 70:933–941, 06–11 Aug 2017
work page 2017
-
[9]
C. D¨ oding, B. D¨ orich, and P. Henning. A multiscale approach to the stationary Ginzburg–Landau equations of superconductivity. CRC 1173 Preprint 2024/21, Karlsruhe Institute of Technology, sep 2024
work page 2024
-
[10]
C. D¨ oding and P. Henning. The Ginzburg–Landau equations: Vortex states and numerical multiscale approxi- mations.ArXiv Preprint, 2511.19540, 2025
- [11]
-
[12]
B. D¨ orich and P. Henning. Error bounds for discrete minimizers of the Ginzburg–Landau energy in the high-κ regime.SIAM J. Numer. Anal., 62(3):1313–1343, 2024
work page 2024
-
[13]
Q. Du, M. D. Gunzburger, and J. S. Peterson. Analysis and approximation of the Ginzburg-Landau model of superconductivity.SIAM Rev., 34(1):54–81, 1992
work page 1992
-
[14]
Q. Du, M. D. Gunzburger, and J. S. Peterson. Modeling and analysis of a periodic Ginzburg-Landau model for type-II superconductors.SIAM J. Appl. Math., 53(3):689–717, 1993
work page 1993
- [15]
-
[16]
Q. Du, R. A. Nicolaides, and X. Wu. Analysis and convergence of a covolume approximation of the Ginzburg- Landau model of superconductivity.SIAM J. Numer. Anal., 35(3):1049–1072, 1998
work page 1998
-
[17]
W. E and B. Yu. The Deep Ritz Method: A Deep Learning-Based Numerical Algorithm for Solving Variational Problems.Commun. Math. Stat., 6(1):1–12, 2018
work page 2018
-
[18]
I. Goodfellow, Y. Bengio, and A. Courville.Deep Learning. MIT Press, 2016
work page 2016
- [19]
- [20]
-
[21]
D. P. Kingma and J. Ba. Adam: A Method for Stochastic Optimization. InInternational Conference on Learning Representations, 2014
work page 2014
-
[22]
Muon is Scalable for LLM Training
J. Liu et al. Muon is scalable for LLM Training.ArXiv Preprint, 2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
H. K. Onnes. Further experiments with liquid helium. c. on the change of electric resistance of pure metals at very low temperatures, etc. iv. the resistance of pure mercury at helium temperatures.Comm. Phys. Lab. Univ. Leiden, 120(120b), 1911
work page 1911
-
[24]
D. Peterseim, J.-F. Pietschmann, J. P¨ uschel, and K. Ruess. Neural network acceleration of iterative methods for nonlinear Schr¨ odinger eigenvalue problems.J. Comput. Appl. Math., 485:Paper No. 117414, 2026
work page 2026
-
[25]
E. Polak and G. Ribi` ere. Note sur la convergence de m´ ethodes de directions conjugu´ ees.Rev. Fran¸ caise Infor- mat. Recherche Op´ erationnelle, 3(16):35–43, 1969
work page 1969
- [26]
-
[28]
E. Sandier and S. Serfaty.Vortices in the magnetic Ginzburg-Landau model, volume 70 ofProgress in Nonlinear Differential Equations and their Applications. Birkh¨ auser Boston, Inc., Boston, MA, 2007
work page 2007
-
[29]
E. Sandier and S. Serfaty. From the Ginzburg-Landau model to vortex lattice problems.Comm. Math. Phys., 313(3):635–743, 2012
work page 2012
-
[30]
S. Serfaty. Stable configurations in superconductivity: uniqueness, multiplicity, and vortex-nucleation.Arch. Ration. Mech. Anal., 149(4):329–365, 1999
work page 1999
-
[31]
S. Serfaty and E. Sandier. Vortex patterns in Ginzburg-Landau minimizers. InXVIth International Congress on Mathematical Physics, pages 246–264. World Sci. Publ., Hackensack, NJ, 2010
work page 2010
-
[32]
N. Shazeer. GLU variants improve transformer.ArXiv Preprint, 2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[33]
H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, and H. Jegou. Going deeper with Image Transformers . In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 32–42, Los Alamitos, CA, USA, Oct. 2021. IEEE Computer Society
work page 2021
-
[34]
S. Venkataraman and B. Amos. Neural Fixed-Point Acceleration for Convex Optimization. In8th ICML Work- shop on Automated Machine Learning (AutoML), 2021
work page 2021
-
[35]
Fixup Initialization: Residual Learning Without Normalization
H. Zhang, Y. N. Dauphin, and T. Ma. Fixup initialization: Residual learning without normalization.ArXiv Preprint, 1901.09321, 2019. Institute for Applied and Numerical Mathematics, Karlsruhe Institute of Technology, 76149 Karl- sruhe, Germany Email address:{michael.crocoll,benjamin.doerich,roland.maier}@kit.edu Institute for Numerical Simulation, Universi...
work page internal anchor Pith review Pith/arXiv arXiv 1901
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.